前言:Hello大家好,我是小哥谈。为了实现电厂人员跌倒行为的实时检测,防止跌倒昏迷而无法及时发现并救援的事件发生,针对跌倒行为检测实时性以及特征提取能力不足的问题,提出了一种改进YOLOv5s的跌倒行为检测算法网络:在YOLOv5s模型中引入SKAttention注意力模块,使得网络可以自动地利用对分类有效的感受野捕捉到的信息,这种新的深层结构允许CNN在卷积核心上执行动态选择机制,从而自适应地调整其感受野的大小;同时结合ASFF自适应空间融合,并在其中充分利用不同特征,又在算法中引入权重参数,以多层次功能为基础,实现了水下目标识别精度提升的目标;加入空间金字塔池化结构SPPFCSPC,大幅缩短了推理时间。实验结果表明,相比于原始YOLOv5s,新网络在mAP平均精度均值方面提升了2.1%,查全率提升了16%;改进后的网络在感知细节和空间建模方面更加强大,能够更准确地捕捉到人 员跌倒的异常行为,检测效果有了显著提升。🌈
目录
🚀1.基础概念
🚀2.网络结构
🚀3.添加步骤
🚀4.改进方法
🍀🍀步骤1:common.py文件修改
🍀🍀步骤2:创建SKAttention.py文件
🍀🍀步骤3:yolo.py文件修改
🍀🍀步骤4:创建自定义yaml文件
🍀🍀步骤5:修改自定义yaml文件
🍀🍀步骤6:验证是否加入成功
🍀🍀步骤7:修改默认参数
🍀🍀步骤8:实际训练测试

🚀1.基础概念
YOLOv5在2020年对外公开,发行者是美国学者Alexey及其带领的团队,作为著名的实时对象识别网络模型,已经发行多个不同版本,如YOLOv5s、YOLOv5m、YOLOv5n、YOLOv5l、YOLOv5x等,其中相对优势较大的版本为YOLOv5s,因为其检测速度最快,同时模型网络较为简单,同时又能够实现模型权重最小,从而能够作为研究与开发的基础版本,为其他网络开发与扩大提供支撑。YOLOv5s网络可根据功能简单划分为:输入端、特征提取与融合网络、预测端。
SKAttention注意力机制:
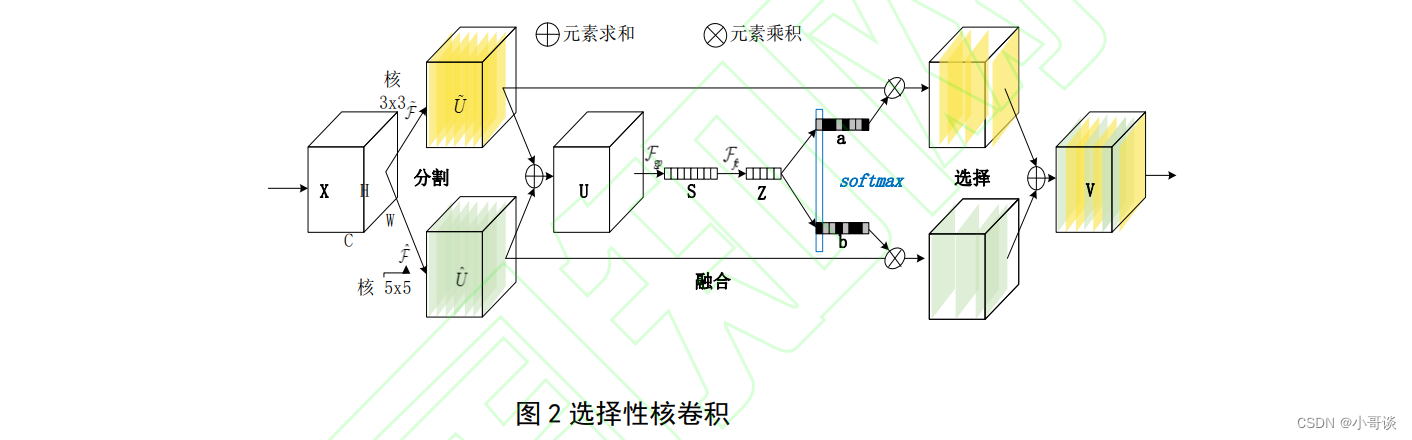
为了使得网络可以自动地利用对分类有效的感受野捕捉到的信息,提出了一种新的深度结构,这种新的深层结构允许CNN在卷积核心上执行动态选择机制,从而自适应地调整其感受野的大小,称为“选择性核(Selective Kernel)”,它可以更好地捕捉复杂图像空间的多尺度特征,而不会像一般的CNN那样浪费大量的计算资源。SKN的另一个优点是它可以聚合深度特征,使它更容易理解,同时也允许更好的可解释性。灵感来自这样一个事实,即当我们看到不同大小和距离的物体时,视觉皮层神经元的感受域的大小会随着刺激而调整。具有不同核大小的几个点以这些点的信息为指导,并与SoftMax进行融合。
同时,为了能更好地增加网络的检测性能,现提出一个“选择核”,此(SK)卷积可以在原有的基础之上完成自动选择操作,提升了对输入数据提取的能力,使得网络神经元获 得在不同的复杂情况之下能够对射频大小自动调整的能力。具体地说,我们通过3个运算符 ——分割、融合和选择来实现SK卷积,如下图所示。
空间金字塔池化结构SPPFCSPC:
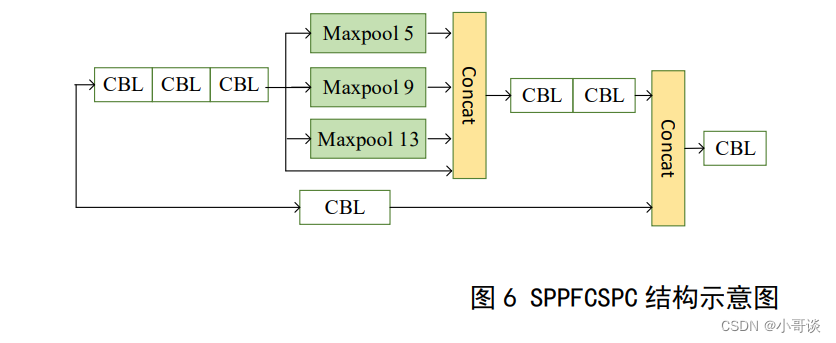
该结构是基于SPPF对SPP结构的改进,所以这里先对SPP模块结构进行说明。YOLO算法中的SPP结构如图所示。该模块将输入的原特征图按不同分块进行操作,然后将3个子图中每一个框的最大值取出,完成了最大池化(Maxpool),最后再将得出的不同特征图Concat叠加在一起。空间金字塔结构SPP的最早提出者为何凯,最初设计该结构的目标是为了解决输入图像的尺寸问题,在应用中发现其具有3个优点:首先,不需要提供输入变量,直接可以根据内部逻辑生成固定长度的输出;然后,使用了Maxpool的多尺度空间容器;最后,可以从不同尺度的特征图中提取特征信息,有效地提高了检测精度。

本文中引入的SPPFCSPC结构,其具体框架如下图所示,从实质上解析该机构,其是基于SPPF对SPP的优化版本,同时还将YOLOv7中的该结构的最大池化部分进行了一定调整,其中采用了多个小卷积核的级联处理方式。实验证实,如果参数集保持不变,推理时间将减少到SPPCPC的72.7%。
ASFF自适应空间融合:
在现有的对象识别算法中,最普通、最经典的体系结构为特征金字塔网络(FPN,feature pyramid network),其特点是利用了分别利用了高级、低级特征的不同特性,前者的语义信息,后者的细化融合。而前文提到的自适应空间特征融合(ASFF),其实质就是通过一定算法机制综合高级和低级特征特性,从而获得了不同层次的功能。基于上述分析,本文在YOLOv5s的适应性改进中融合了ASFF,利用其特性与优势,提高水下目标识别质量。FPN详细结构如图3所示,ASFF结构如图4所示。

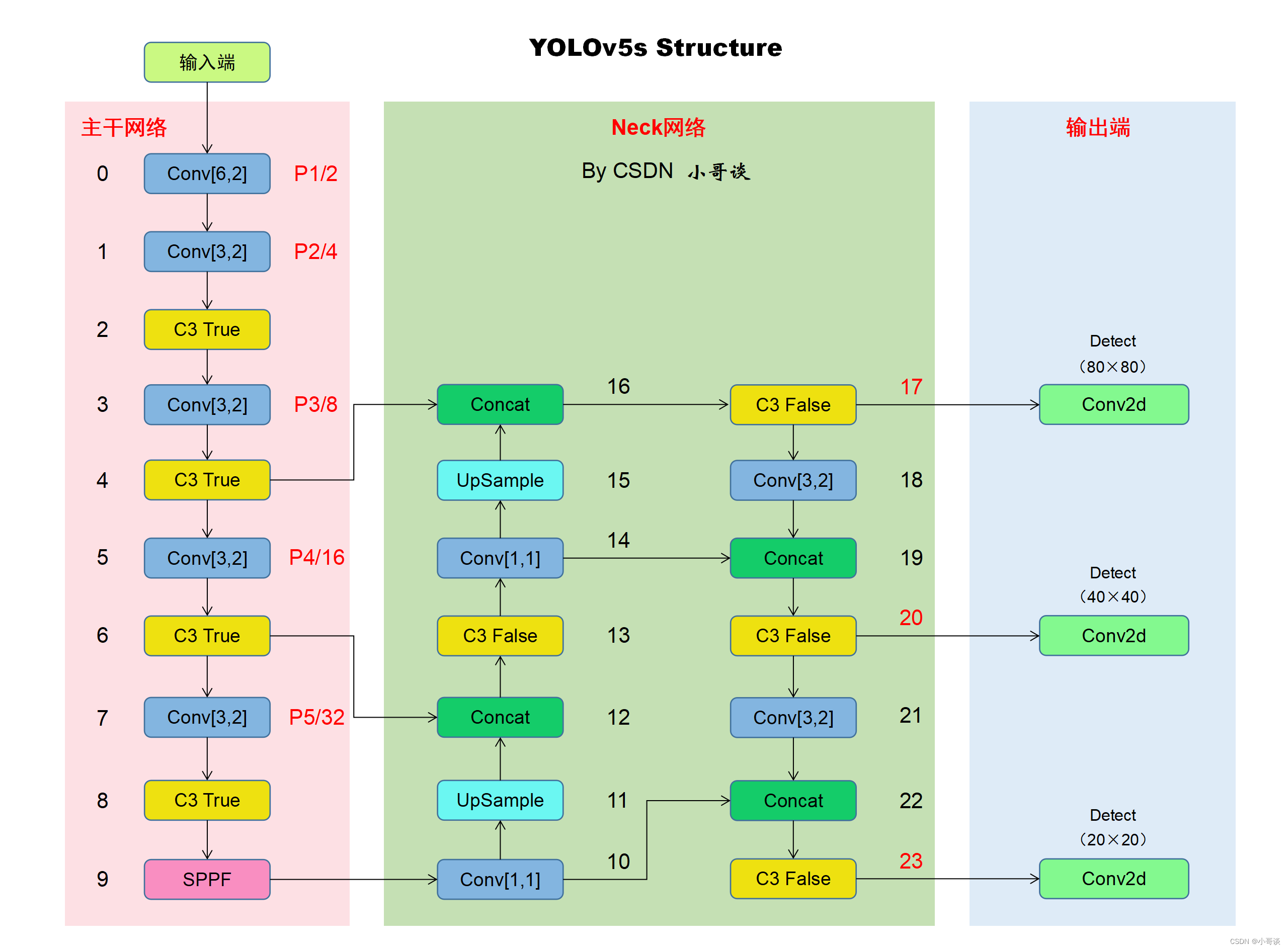
🚀2.网络结构
本文的改进是基于YOLOv5-6.0版本,关于其网络结构具体如下图所示:
本文对YOLOv5的改进是引入SKAttention注意机制 + 引入空间金字塔池化结构SPPFCSPC + 结合ASFF自适应空间融合,改进后的网络结构图具体如下图所示:

在论文中,改进后的结构图如下图所示:

🚀3.添加步骤
针对本文的改进,具体步骤如下所示:👇
步骤1:common.py文件修改
步骤2:创建SKAttention.py文件
步骤3:yolo.py文件修改
步骤4:创建自定义yaml文件
步骤5:修改自定义yaml文件
步骤6:验证是否加入成功
步骤7:修改默认参数
步骤8:实际训练测试
🚀4.改进方法
🍀🍀步骤1:common.py文件修改
在common.py中添加ASFF和SPPFCSPC模块代码,所要添加模块的代码如下所示,将其复制粘贴到common.py文件末尾的位置。
# ASFF模块代码
# By CSDN 小哥谈
def add_conv(in_ch, out_ch, ksize, stride, leaky=True):
"""
Add a conv2d / batchnorm / leaky ReLU block.
Args:
in_ch (int): number of input channels of the convolution layer.
out_ch (int): number of output channels of the convolution layer.
ksize (int): kernel size of the convolution layer.
stride (int): stride of the convolution layer.
Returns:
stage (Sequential) : Sequential layers composing a convolution block.
"""
stage = nn.Sequential()
pad = (ksize - 1) // 2
stage.add_module('conv', nn.Conv2d(in_channels=in_ch,
out_channels=out_ch, kernel_size=ksize, stride=stride,
padding=pad, bias=False))
stage.add_module('batch_norm', nn.BatchNorm2d(out_ch))
if leaky:
stage.add_module('leaky', nn.LeakyReLU(0.1))
else:
stage.add_module('relu6', nn.ReLU6(inplace=True))
return stage
class ASFF(nn.Module):
def __init__(self, level, rfb=False, vis=False):
super(ASFF, self).__init__()
self.level = level
# 特征金字塔从上到下三层的channel数
# 对应特征图大小(以640*640输入为例)分别为20*20, 40*40, 80*80
self.dim = [512, 256, 128]
self.inter_dim = self.dim[self.level]
if level==0: # 特征图最小的一层,channel数512
self.stride_level_1 = add_conv(256, self.inter_dim, 3, 2)
self.stride_level_2 = add_conv(128, self.inter_dim, 3, 2)
self.expand = add_conv(self.inter_dim, 512, 3, 1)
elif level==1: # 特征图大小适中的一层,channel数256
self.compress_level_0 = add_conv(512, self.inter_dim, 1, 1)
self.stride_level_2 = add_conv(128, self.inter_dim, 3, 2)
self.expand = add_conv(self.inter_dim, 256, 3, 1)
elif level==2: # 特征图最大的一层,channel数128
self.compress_level_0 = add_conv(512, self.inter_dim, 1, 1)
self.compress_level_1 = add_conv(256, self.inter_dim, 1, 1)
self.expand = add_conv(self.inter_dim, 128, 3, 1)
compress_c = 8 if rfb else 16 #when adding rfb, we use half number of channels to save memory
self.weight_level_0 = add_conv(self.inter_dim, compress_c, 1, 1)
self.weight_level_1 = add_conv(self.inter_dim, compress_c, 1, 1)
self.weight_level_2 = add_conv(self.inter_dim, compress_c, 1, 1)
self.weight_levels = nn.Conv2d(compress_c*3, 3, kernel_size=1, stride=1, padding=0)
self.vis= vis
def forward(self, x_level_0, x_level_1, x_level_2):
if self.level==0:
level_0_resized = x_level_0
level_1_resized = self.stride_level_1(x_level_1)
level_2_downsampled_inter =F.max_pool2d(x_level_2, 3, stride=2, padding=1)
level_2_resized = self.stride_level_2(level_2_downsampled_inter)
elif self.level==1:
level_0_compressed = self.compress_level_0(x_level_0)
level_0_resized =F.interpolate(level_0_compressed, scale_factor=2, mode='nearest')
level_1_resized =x_level_1
level_2_resized =self.stride_level_2(x_level_2)
elif self.level==2:
level_0_compressed = self.compress_level_0(x_level_0)
level_0_resized =F.interpolate(level_0_compressed, scale_factor=4, mode='nearest')
level_1_compressed = self.compress_level_1(x_level_1)
level_1_resized =F.interpolate(level_1_compressed, scale_factor=2, mode='nearest')
level_2_resized =x_level_2
level_0_weight_v = self.weight_level_0(level_0_resized)
level_1_weight_v = self.weight_level_1(level_1_resized)
level_2_weight_v = self.weight_level_2(level_2_resized)
levels_weight_v = torch.cat((level_0_weight_v, level_1_weight_v, level_2_weight_v),1)
levels_weight = self.weight_levels(levels_weight_v)
levels_weight = F.softmax(levels_weight, dim=1)
fused_out_reduced = level_0_resized * levels_weight[:,0:1,:,:]+\
level_1_resized * levels_weight[:,1:2,:,:]+\
level_2_resized * levels_weight[:,2:,:,:]
out = self.expand(fused_out_reduced)
if self.vis:
return out, levels_weight, fused_out_reduced.sum(dim=1)
else:
return out
# SPPFCSPC模块代码
# By CSDN 小哥谈
class SPPFCSPC(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5, k=5):
super(SPPFCSPC, self).__init__()
c_ = int(2 * c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(c_, c_, 3, 1)
self.cv4 = Conv(c_, c_, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
self.cv5 = Conv(4 * c_, c_, 1, 1)
self.cv6 = Conv(c_, c_, 3, 1)
self.cv7 = Conv(2 * c_, c2, 1, 1)
def forward(self, x):
x1 = self.cv4(self.cv3(self.cv1(x)))
x2 = self.m(x1)
x3 = self.m(x2)
y1 = self.cv6(self.cv5(torch.cat((x1, x2, x3, self.m(x3)), 1)))
y2 = self.cv2(x)
return self.cv7(torch.cat((y1, y2), dim=1))
🍀🍀步骤2:创建SKAttention.py文件
在源码根目录下创建SKAttention.py文件,代码如下:
import torch
from torch import nn
from collections import OrderedDict
# 定义SKAttention类,继承自nn.Module类
class SKAttention(nn.Module):
# 定义初始化函数,channel参数为输入的特征通道数,kernels参数为卷积核的大小列表,reduction参数为降维比例,group参数为卷积组数,L参数为维度
def __init__(self, channel=512, kernels=[1, 3, 5, 7], reduction=16, group=1, L=32):
super().__init__()
# 定义d参数,为L和channel除以reduction中最大值
self.d = max(L, channel // reduction)
# 定义一个nn.ModuleList,用于存放卷积层
# 在输入图像上使用不同大小的卷积核卷积,获得多个不同尺寸的特征图;
self.convs = nn.ModuleList([])
for k in kernels:
self.convs.append(
nn.Sequential(OrderedDict([ # 定义一个nn.Sequential,包含一个OrderedDict
('conv', nn.Conv2d(channel, channel, kernel_size=k, padding=k // 2, groups=group)),
('bn', nn.BatchNorm2d(channel)),
('relu', nn.ReLU())
]))
)
self.fc = nn.Linear(channel, self.d)
self.fcs = nn.ModuleList([])
for i in range(len(kernels)):
self.fcs.append(nn.Linear(self.d, channel))
self.softmax = nn.Softmax(dim=0)
def forward(self, x):
bs, c, _, _ = x.size()
conv_outs = []
### 对输入input进行分割。使用kernels参数指定的不同卷积核大小,使用同一组卷积参数,对这个input进行卷积操作,从而得到k个不同特征;
for conv in self.convs:
conv_outs.append(conv(x))
feats = torch.stack(conv_outs, 0) # k,bs,channel,h,w
### fuse融合层 将这k个特征直接相加,得到融合特征U
U = sum(conv_outs) # bs,c,h,w
### reduction channel 降维层 将这个融合特征U的每一个通道求平均值,得到降维的特征S,然后进行全连接运算
S = U.mean(-1).mean(-1) # bs,c
Z = self.fc(S) # bs,d
### calculate attention weight
weights = []
# 对于这个降维后的特征S,使用多个不同的全连接层fcs,
for fc in self.fcs:
weight = fc(Z)
weights.append(weight.view(bs, c, 1, 1)) # bs,channel
# 把降维后的特征S转换为各个不同卷积核大小特征的权重,
attention_weughts = torch.stack(weights, 0) # k,bs,channel,1,1
attention_weughts = self.softmax(attention_weughts) # k,bs,channel,1,1
### fuse 将权重与特征叠加求和,得到最终的融合特征V
V = (attention_weughts * feats).sum(0)
return V
if __name__ == '__main__':
input = torch.randn(50, 512, 7, 7)
se = SKAttention(channel=512, reduction=8)
output = se(input)
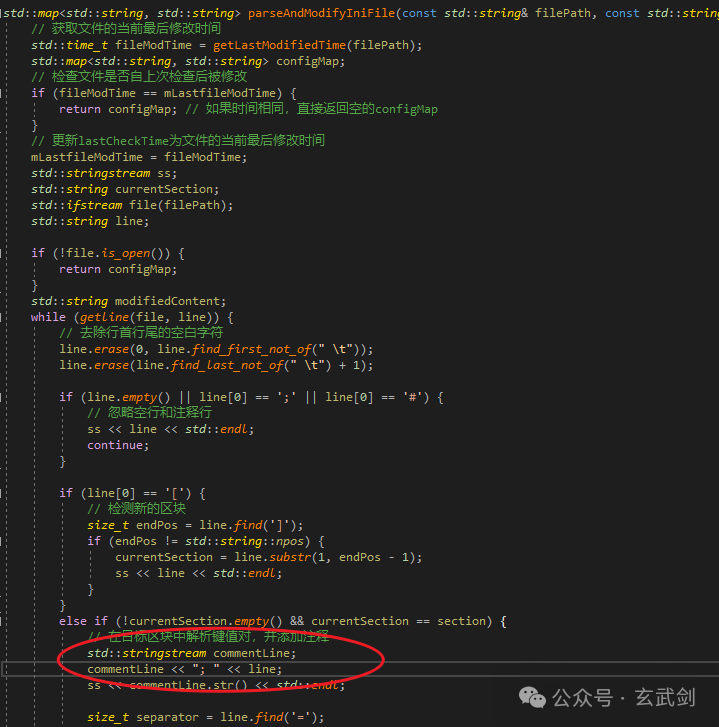
print(output.shape)🍀🍀步骤3:yolo.py文件修改
首先,在下图所示位置加入代码:
# By CSDN 小哥谈
class ASFF_Detect(Detect):
# ASFF model for improvement
def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer
super().__init__(nc, anchors, ch, inplace)
self.nl = len(anchors)
self.asffs = nn.ModuleList(ASFF(i) for i in range(self.nl))
self.detect = Detect.forward
def forward(self, x): # x中的特征图从大到小,与ASFF中顺序相反,因此输入前先反向
x = x[::-1]
for i in range(self.nl):
x[i] = self.asffs[i](*x)
return self.detect(self, x[::-1])具体添加位置如下图所示:

然后,针对ASFF模块进行修改。
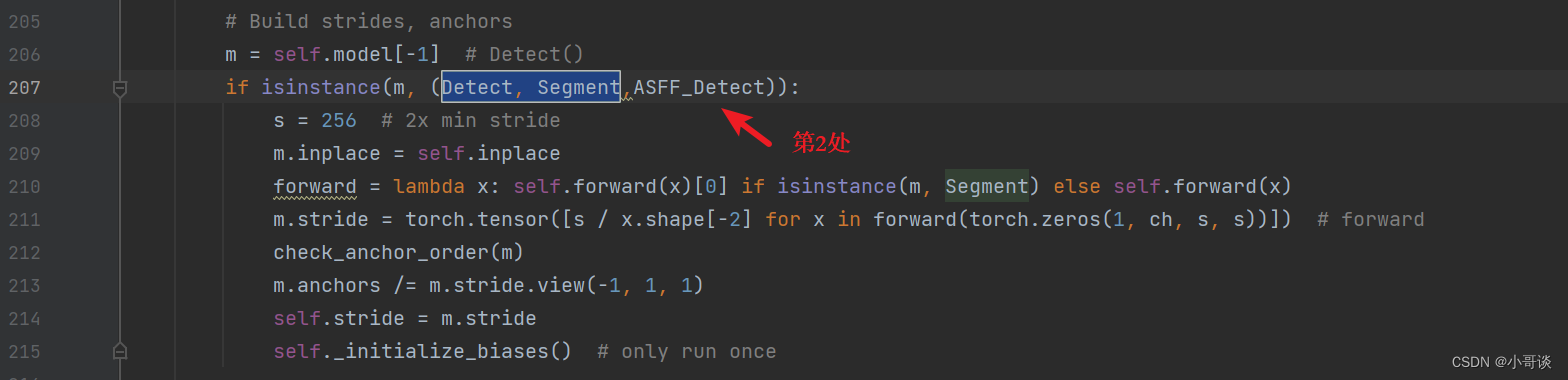
采用Ctrl + F进行搜索Detect, Segment,可以看到共有三处。

分别在其后加入ASFF_Detect。关于这三处修改如下图所示:


最后,在yolo.py文件中找到parse_model函数,在下图中所示位置添加SPPFCSPC,并且添加下列代码:
# ---------------start-----------------
elif m is SKAttention:
c1, c2 = ch[f], args[0]
if c2 != no:
c2 = make_divisible(c2 * gw, 8)
args = [c1, *args[1:]]
# ----------------end------------------具体添加位置如下图所示:

🍀🍀步骤4:创建自定义yaml文件
在models文件夹中复制yolov5s.yaml,粘贴并重命名为:yolov5s_ASFF.yaml。具体如下图所示:

🍀🍀步骤5:修改自定义yaml文件
本步骤是修改yolov5s_ASFF.yaml,根据改进后的网络结构图进行修改。
修改后的完整yaml文件如下所示:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# By CSDN 小哥谈
# Parameters
nc: 2 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SKAttention, [1024]],
[-1, 1, SPPFCSPC, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 15], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 11], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[18, 21, 24], 1, ASFF_Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
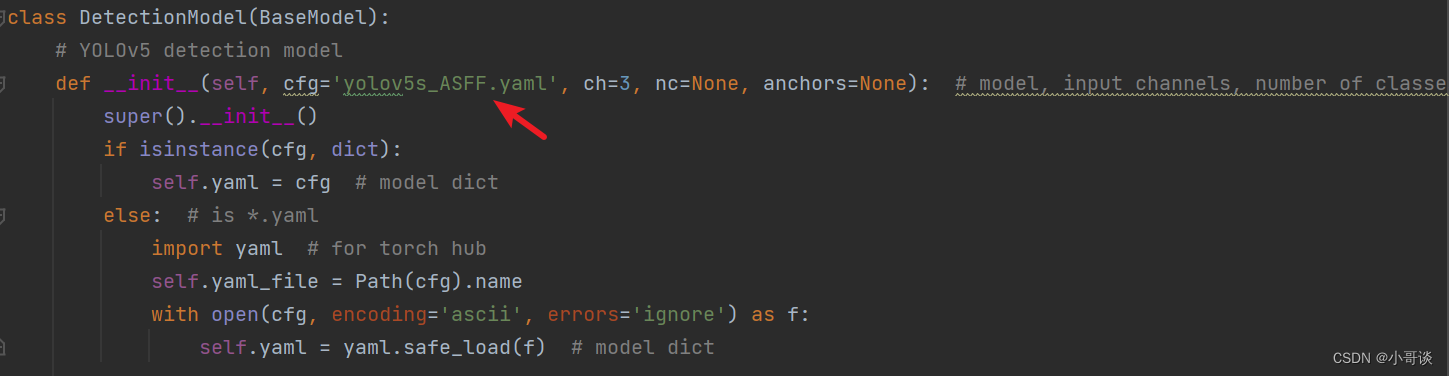
🍀🍀步骤6:验证是否加入成功
在yolo.py文件里,将配置改为我们刚才自定义的yolov5s_ASFF.yaml。
修改1,位置位于yolo.py文件165行左右,具体如图所示:
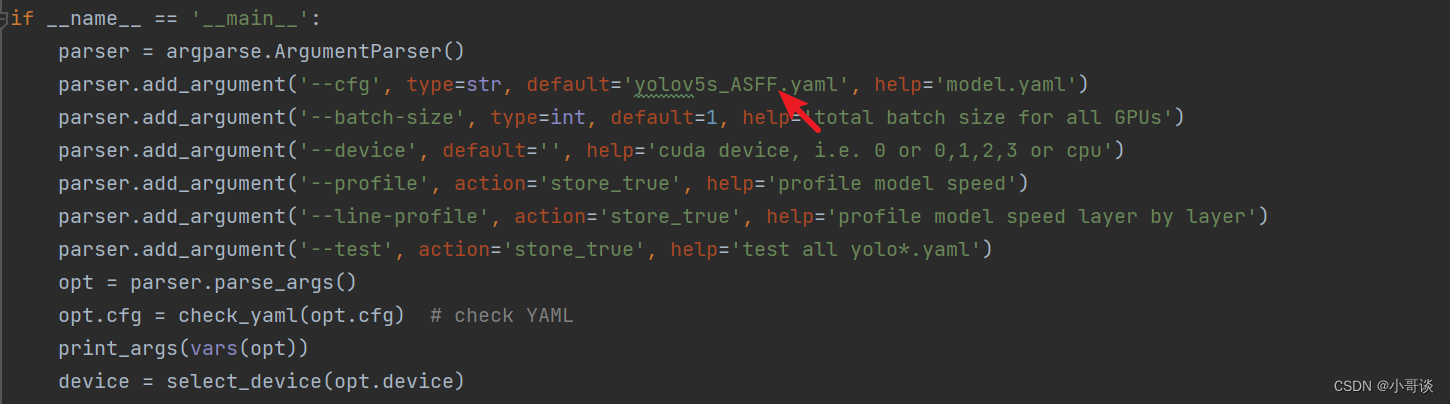
修改2,位置位于yolo.py文件363行左右,具体如下图所示:
配置完毕之后,点击“运行”,结果如下图所示:

由运行结果可知,与我们前面更改后的网络结构图相一致,证明添加成功了!✅
参数量对比:
yolov5s.yaml:214 layers, 7235389 parameters, 7235389 gradients, 16.6 GFLOPs
yolov5s_ASFF.yaml:271 layers, 40990552 parameters, 40990552 gradients, 47.0 GFLOPs
🍀🍀步骤7:修改默认参数
在train.py文件中找到parse_opt函数,然后将第二行 '--cfg' 的default改为 ' models/yolov5s_ASFF.yaml ',然后就可以开始进行训练了。🎈🎈🎈

🍀🍀步骤8:实际训练测试
在本步骤中,parse_opt函数中的参数'--weights'采用的是yolov5s.pt,'--data'所采用的是helmet.yaml(作者提前创建的安全帽佩戴检测地址及分类信息,同学可自定义),然后设置'--epochs'为100轮。相关参数设置完毕后,点击运行train.py文件,没有发生报错,模型正常训练,具体如下图所示:👇

说明:后期实际训练时,根据论文所设置的指标进行训练,上述只是进行测试。
结束语:
本文分析主要是立足实时监测个人跌倒行为的相关研究,对人群中跌倒行为检测中出现的一些问题进行了阐述。基于YOLOv5s网络,参考已有成果,对其进行了优化和改进,在其中加入注意力模块,从而提高了感知分类信息的利用质量和效率,这种结构特性能够为CNN卷积核提供优化路径,实现动态选择,丰富了神经元的功能区间,使其能够根据多尺度的输入信息进行动态且即时性的感受野的区间调整;此外,也加入了自适应空间融合ASFF,其支持了权重参数学习,因此能够实现多特征融合,并结合层次函数,实现算法优化,提高目标识别准确性;从本文实验结果来看,利用改进的YOLOv5s,进行设计和开发的跌倒检测算法在实验中得到了正向反馈,在查准率、查全率和平均精度均值等维度上都有较好表现。本文之后将完善数据集,并不断加入新检测场景,以继续对该算法进行进一步完善。
说明:
本节课根据文章《基于改进YOLOv5s的跌倒行为检测》进行代码实现。
作者:朱正林、钱予阳、马辰宇、王悦炜、史腾
期刊:计算机测量与控制 ISSN 1671-4598,CN 11-4762/TP