https://github.com/quan-meng/gnerf
之前一直去复现这个代码总是文件不存在,我就懒得搞了(实际上是没能力哈哈哈) 最近突然想到这篇论文重新试试复现
一、按步骤创建虚拟环境安装各种依赖等
二、安装好之后下载数据,可以用Blender也可以下载DTU,将下载好的数据放在创建的data包里

三、运行(第一次复现的时候i就是卡在运行这一步,总是说文件不存在)
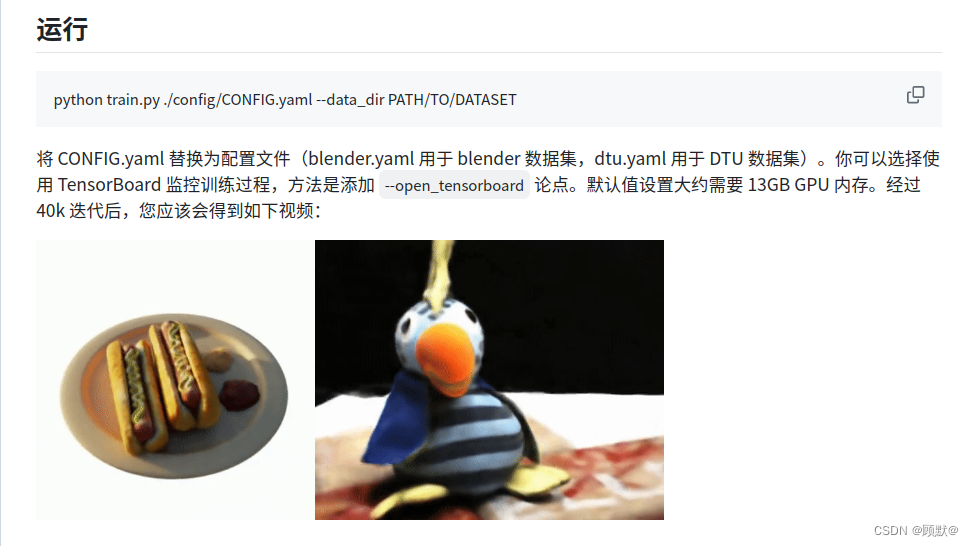
python train.py ./config/CONFIG.yaml --data_dir PATH/TO/DATASET
首先来解释一下这串代码的含义
python train.py是运行Python脚本的标准命令,train.py是训练的脚本文件,代码意思就是Python解释器执行当前目录下名为train.py的脚本
./config/blender.yaml指定了配置文件的路径。这个YAML文件很可能包含了训练过程中需要的各种配置信息,比如模型架构、训练参数(学习率、批大小等)、优化器设置等。(注:一般会通过–config作为参数传递给脚本。虽然命令中没有直接写出–config,假设这里是省略了–config或使用了某个特定的参数名,如–cfg或直接在位置参数中指定))
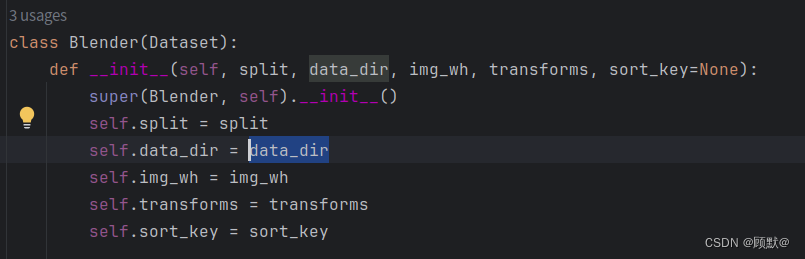
--data_dir PATH/TO/DATASET这里明确使用了–data_dir参数来指定数据集目录的路径。PATH/TO/DATASET应该被替换为您的实际数据集路径。
接下来修改一下代码,因为我下载的是blender数据集所以将数据集路径修改为./data/nerf_synthetic/lego,即数据集选择blender中的乐高数据
python train.py ./config/blender.yaml --data_dir ./data/nerf_synthetic/lego
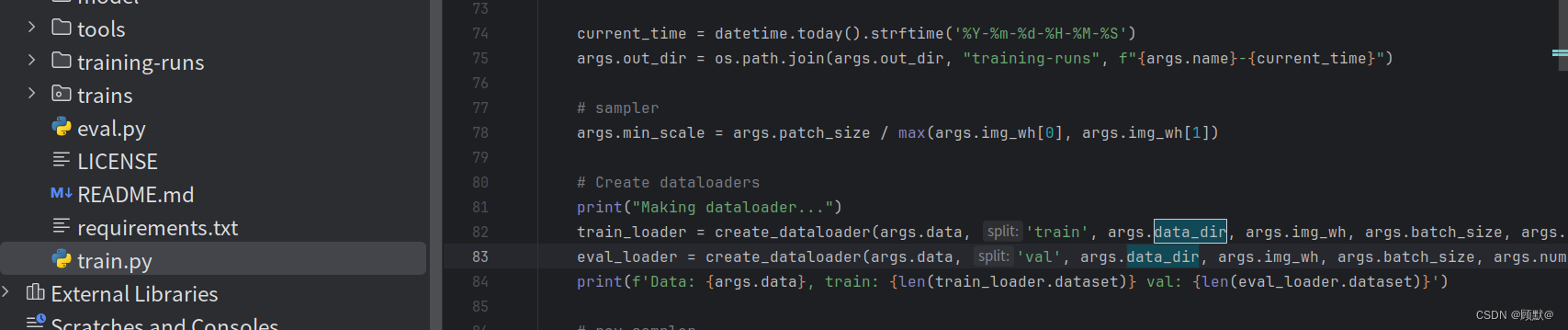
# Create dataloaders
print("Making dataloader...")
train_loader = create_dataloader(args.data, 'train', args.data_dir, args.img_wh, args.batch_size, args.num_workers)
#调用了create_dataloader函数两次,分别用于创建训练数据加载器(train_loader)和评估(验证)数据加载器(eval_loader)
eval_loader = create_dataloader(args.data, 'val', args.data_dir, args.img_wh, args.batch_size, args.num_workers)
print(f'Data: {args.data}, train: {len(train_loader.dataset)} val: {len(eval_loader.dataset)}')
# args.data:数据集的类型或名称,这决定了要加载哪个数据集。
# 'train'或'val':指定数据加载器是用于训练集还是验证集。
# args.data_dir:数据集的存储目录。
# args.img_wh:图像的大小(宽度和高度),这通常用于预处理步骤,以确保所有输入图像都具有相同的尺寸。
# args.batch_size:每个批次中要加载的图像数量。
#args.num_workers:用于数据加载的并行工作进程数。
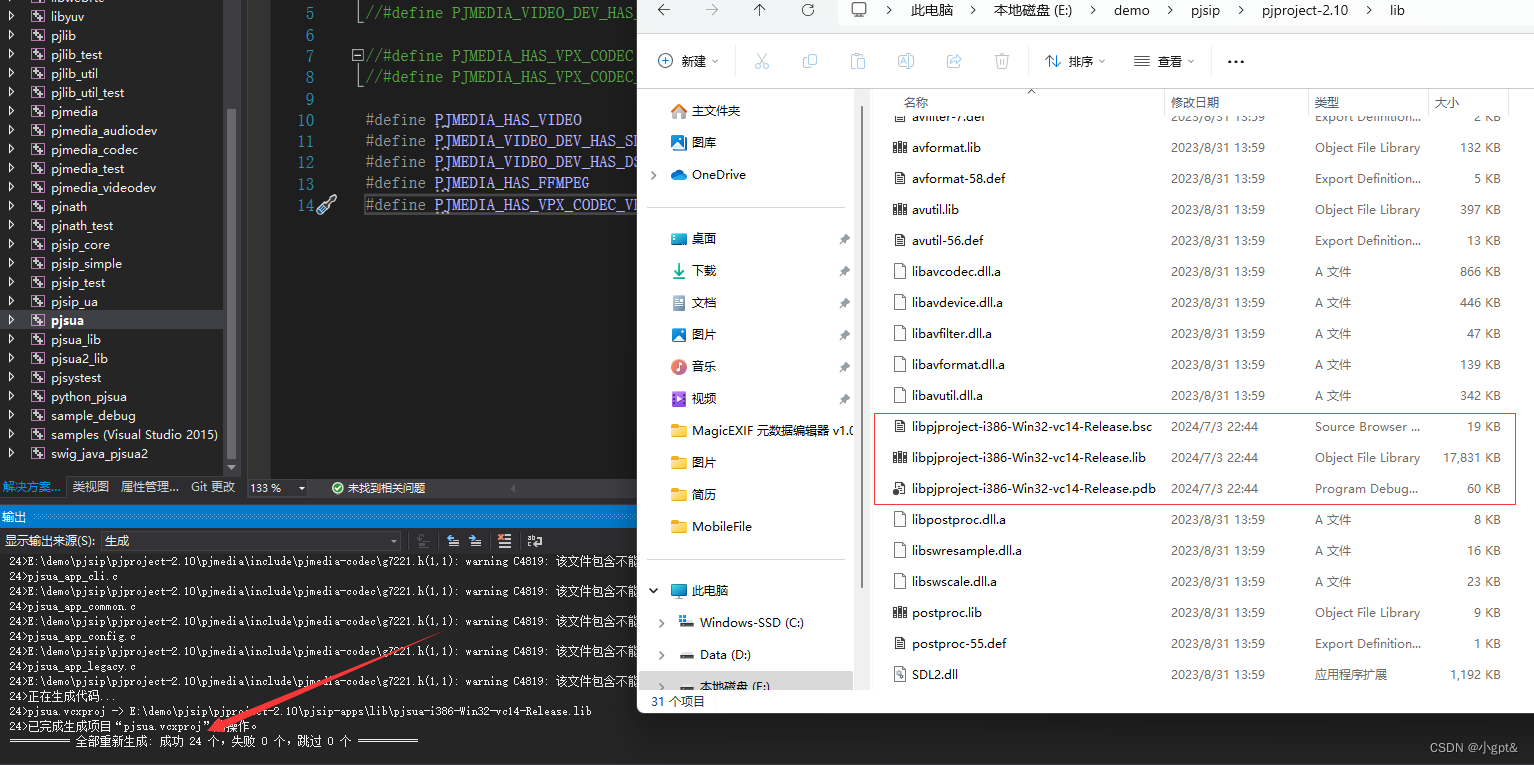
运行之后是下面这种情况
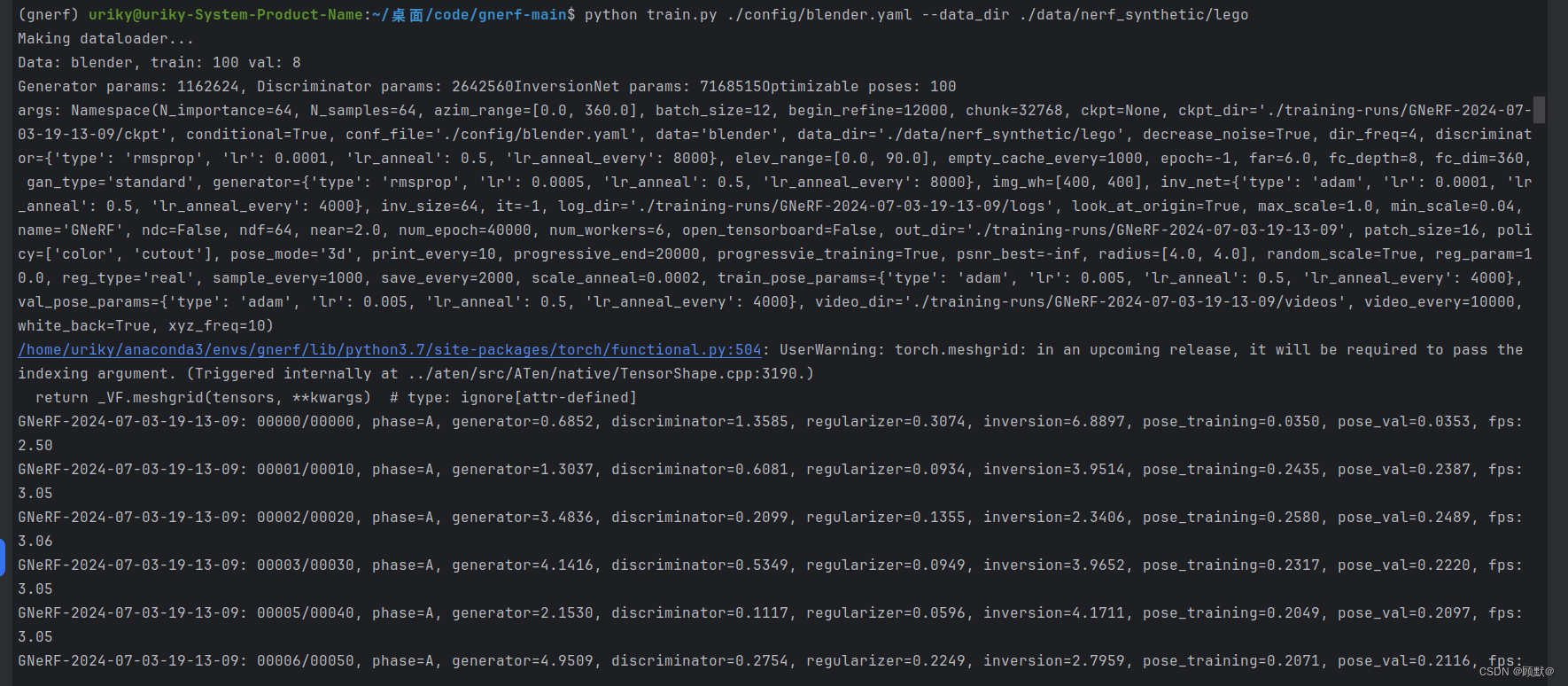
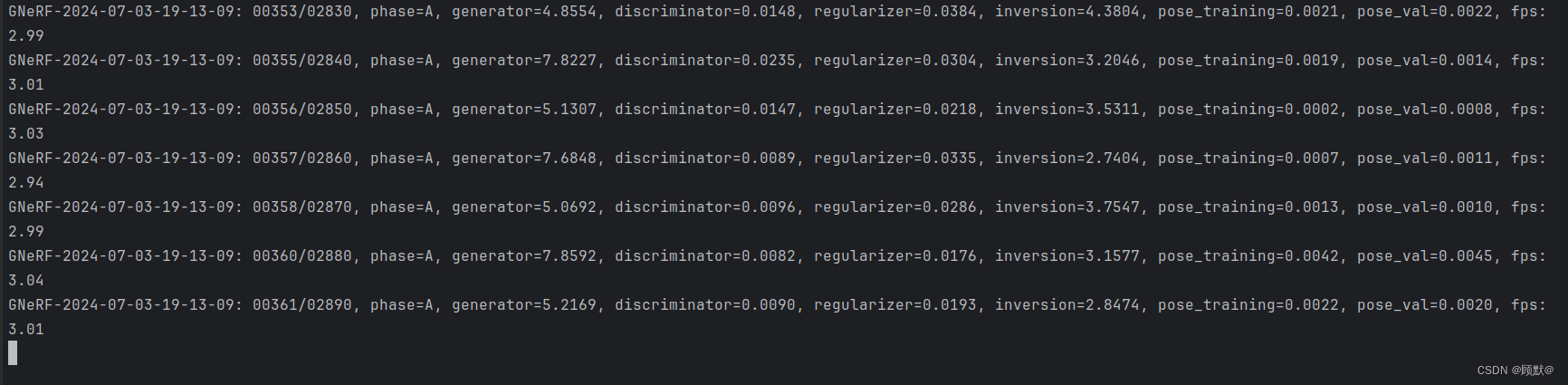
好几个小时了,结果大概明天或者更久才能出
四、总结:
一般遇见代码路径等需要修改的时候,可以多尝试一下修改代码,费时点的话就需要理解一下运行脚本