赛题
2024中国高校计算机大赛 — 大数据挑战赛
经验分享
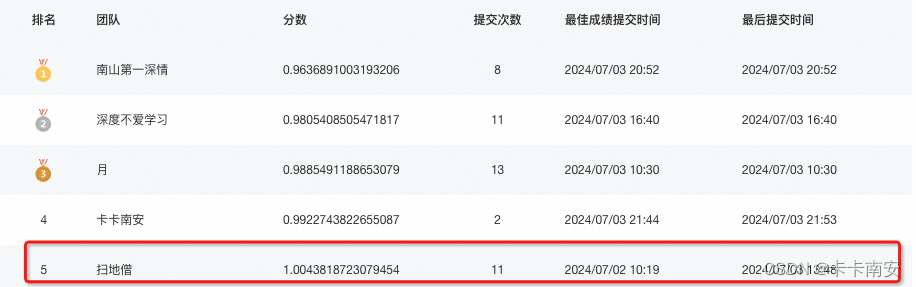
大家好,我是扫地僧团队的队长,以前参加这样打榜的比赛比较少,了解的打榜技巧不是太多,所以想从科研的角度给大家一点分享。
这次比赛主要从以下五个步骤进行:数据集构造👉Baseline选择👉模型优化👉模型调参👉模型集成
1. 数据集构造
官方已经给了数据集,可以尝试根据温度筛选出与中国温度类似的场站,但是不确定是否会有效果:
import numpy as np
import pandas as pd
import os
import matplotlib.pyplot as plt
root_path = '../dataset/global'
data_path = 'temp.npy'
data = np.load(os.path.join(root_path, data_path))
data_oneyear = data[:365*24,:,0]
df = pd.DataFrame(data_oneyear)
# 夏天平均温度大于15摄氏度
summer_df = df.iloc[4000:5500]
print(summer_df.shape)
summer_index = summer_df.mean(axis=0).apply(lambda x: x > 15)
summer_index = summer_index[summer_index].index.to_list()
print(len(summer_index))
# 冬天平均温度小于20摄氏度
winter_df = df.iloc[0:500]
print(winter_df.shape)
winter_index = winter_df.mean(axis=0).apply(lambda x: x < 20)
winter_index = winter_index[winter_index].index.to_list()
print(len(winter_index))
# 取两个表的交集
index = list(set(summer_index) & set(winter_index))
print(len(index))
# 取两个表的交集
index = list(set(summer_index) & set(north_index) & set(winter_index))
print(len(index))
# 筛选电站
root_path= '../dataset/global'
temp_path = 'temp.npy'
wind_path = 'wind.npy'
global_data_path = 'global_data.npy'
temp_data = np.load(os.path.join(root_path, temp_path))
wind_data = np.load(os.path.join(root_path, wind_path))
global_data = np.load(os.path.join(root_path, global_data_path))
print(temp_data.shape)
print(wind_data.shape)
print(global_data.shape)
temp_seleted = temp_data[:,index,:]
wind_seleted = wind_data[:,index,:]
global_seleted = global_data[:,:,:,index]
print(temp_seleted.shape)
print(wind_seleted.shape)
print(global_seleted.shape)
# 划分训练集和验证集
l = temp_seleted.shape[0]
train_size = int(l * 0.9)
temp_seleted_train = temp_seleted[:train_size,:,:]
wind_seleted_train = wind_seleted[:train_size,:,:]
global_seleted_train = global_seleted[:int(train_size/3),:,:]
temp_seleted_val = temp_seleted[train_size:,:,:]
wind_seleted_val = wind_seleted[train_size:,:,:]
global_seleted_val = global_seleted[int(train_size/3):,:,:]
print("train:",temp_seleted_train.shape,wind_seleted_train.shape,global_seleted_train.shape)
print("val:",temp_seleted_val.shape,wind_seleted_val.shape,global_seleted_val.shape)
# 保存训练集和验证集
if not os.path.exists(os.path.join('../dataset', 'seleted_global_train_val')):
os.makedirs(os.path.join('../dataset', 'seleted_global_train_val'))
selected_path = os.path.join('../dataset', 'seleted_global_train_val')
np.save(os.path.join(selected_path, 'temp_train.npy'), temp_seleted_train)
np.save(os.path.join(selected_path, 'temp_val.npy'), temp_seleted_val)
np.save(os.path.join(selected_path, 'wind_train.npy'), wind_seleted_train)
np.save(os.path.join(selected_path, 'wind_val.npy'), wind_seleted_val)
np.save(os.path.join(selected_path, 'global_train.npy'), global_seleted_train)
np.save(os.path.join(selected_path, 'global_val.npy'), global_seleted_val)
筛选后温度和风速形状如图所示:

2. Baseline选择
官方Baseline给的是iTransformer,关于iTransformer模型的解读请参考:【PaperInFive-时间序列预测】iTransformer:转置Transformer刷新时间序列预测SOTA(清华)
可以关注近近两年开源的SOTA模型,这里分享一个Github,可以去上面找近年的SOTA模型:https://github.com/ddz16/TSFpaper
3. 模型优化
选好效果好的Baseline后就可以进行模型优化,比如iTransformer只建模了特征信息,那么可以在模型中补充对时序特征的建模,比如进行一些卷积操作,或者在时间维度上进行self-Attention,关于时间维度上的建模大家也可以参考SOTA论文,可以把不同论文里的模块进行一个融合,说不定会有好效果。
4. 模型调参
确定了模型结构后就可以进行模型超参数的调整,比如模型的维度和层数,学习率和batch size等,经过测试增加模型的dimention在一定程度上可以提高模型表现,但是增加层数好像效果不太明显。
学习率方面我初始值为0.01或0.005,每一轮除以2进行衰减。batch size我设为40960。
5. 模型集成
最后可以把不同特征的模型进行集成,比如可以把多个模型的结果取平均,或者可以在训练时采用Mixture of Expert的方式加权求和。
帮助代码
1. 模型测试
加在exp_long_term_forecasting.py里面:
def val(self, setting):
_, _, val_data, val_loader = self._get_data()
time_now = time.time()
criterion = self._select_criterion()
if self.args.use_amp:
scaler = torch.cuda.amp.GradScaler()
self.model.load_state_dict(torch.load(self.args.state_dict_path,map_location=torch.device('cuda:0')))
self.model.eval()
val_loss = []
for i, (batch_x, batch_y) in enumerate(val_loader):
batch_x = batch_x.float().to(self.device)
batch_y = batch_y.float().to(self.device)
# encoder - decoder
if self.args.use_amp:
with torch.cuda.amp.autocast():
if self.args.output_attention:
outputs = self.model(batch_x)[0]
else:
outputs = self.model(batch_x)
f_dim = -1 if self.args.features == 'MS' else 0
outputs = outputs[:, -self.args.pred_len:, f_dim:]
batch_y = batch_y[:, -self.args.pred_len:, f_dim:].to(self.device)
loss = criterion(outputs, batch_y)
print("\titers: {0} | loss: {2:.7f}".format(i + 1, loss.item()))
val_loss.append(loss.item())
else:
if self.args.output_attention:
outputs = self.model(batch_x)[0]
else:
outputs = self.model(batch_x)
f_dim = -1 if self.args.features == 'MS' else 0
outputs = outputs[:, -self.args.pred_len:, f_dim:]
batch_y = batch_y[:, -self.args.pred_len:, f_dim:].to(self.device)
loss = criterion(outputs, batch_y)
if (i + 1) % 50 == 0:
print("\titers: {0} | loss: {1:.7f}".format(i + 1, loss.item()))
val_loss.append(loss.item())
val_loss = np.average(val_loss)
print("Val Loss: {0:.7f}".format(val_loss))
return self.model
2. 验证集Dataloader
加在data_factory.py里面:
def data_provider(args):
Data = data_dict[args.data]
shuffle_flag = True
drop_last = False
batch_size = args.batch_size
train_data_set = Data(
root_path=args.root_path,
data_path=args.train_data_path,
global_path=args.train_global_path,
size=[args.seq_len, args.label_len, args.pred_len],
features=args.features
)
train_data_loader = DataLoader(
train_data_set,
batch_size=batch_size,
shuffle=shuffle_flag,
num_workers=args.num_workers,
drop_last=drop_last)
val_data_set = Data(
root_path=args.root_path,
data_path=args.val_data_path,
global_path=args.val_global_path,
size=[args.seq_len, args.label_len, args.pred_len],
features=args.features
)
val_data_loader = DataLoader(
val_data_set,
batch_size=int(batch_size/8),
shuffle=False,
num_workers=args.num_workers,
drop_last=drop_last)
return train_data_set, train_data_loader, val_data_set, val_data_loader
最后
希望大家以赛为友,共同进步,一起分享一些有用的小技巧。


![[OC]萝卜圈Python手动游戏](https://img-blog.csdnimg.cn/direct/f465468c04bc4ed6ba0141d3870bcbfc.png)