多模态图像生成是内容创作领域的热点技术,尤其在媒体、艺术和元宇宙等领域。该技术旨在模拟人类的想象力,将视觉、文本和音频等多种模态属性相关联,以生成图像。早期的方法主要侧重于单一模态输入的图像生成,例如基于图像、文本或音频的生成。这些方法在处理现实世界中更复杂的模态输入时受到限制。
香港科技大学(广州)的研究团队提出了一种名为ImgAny的新型多模态图像生成框架。这一框架无需训练,能够从语言、音频到视觉等多种模态中生成高质量图像,包括图像、点云、热成像、深度和事件数据等。ImgAny通过模仿人类的认知过程,实现了模态间的整合与协调,生成视觉上吸引人的图像。

ImgAny
ImgAny是一个端到端的多模态生成模型,它能够接受多达七种不同模态的输入,包括语言、音频和五种视觉模态(图像、点云、热成像、深度和事件数据)。这一框架的设计灵感来源于人类的认知过程,通过在实体和属性两个层面上整合多种输入模态,实现了无需特定调整的生成过程。

ImgAny的整体框架由三个主要部分组成,整体来看ImgAny的框架设计允许它灵活地处理多种模态输入,并通过实体和属性的融合,生成在视觉上具有吸引力且与输入条件一致的图像。
-
Multi-modal Encoder(多模态编码器):
这是ImgAny框架的第一部分,负责从各种模态输入中提取特征。对于给定的n种模态,ImgAny包括n个编码器,用于提取多模态数据的特征。例如,如果输入包括文本、图像、音频等,每个模态都会有一个专门的编码器来处理并提取相应的特征。 -
Entity Fusion Branch(实体融合分支):
实体融合分支是框架的第二大组成部分,它的目的是确保输入和输出之间的一致性。这一分支通过使用外部的实体知识图谱来集成多模态表示中的实体特征。它首先基于WordNet构建一个实体知识图谱,然后使用文本编码器提取实体名词的特征。通过计算这些特征与多模态特征之间的余弦相似度,确定与多模态特征最相关的实体词,并将这些实体信息融合以形成生成图像的条件之一。 -
Attribute Fusion Branch(属性融合分支):
属性融合分支是框架的第三部分,它专注于合并来自所有输入模态的不同属性特征。与实体融合分支类似,属性融合分支也构建了一个属性知识图谱,但这里使用的是属性形容词。通过计算多模态特征的平均值与属性形容词特征之间的相似度,选择最相关的属性词,并提取相应的属性特征。这些属性信息随后被融合,形成生成图像的另一个条件。
实体融合分支是ImgAny中的一个关键创新点。这一分支的目的是保持输入和输出之间的一致性。通过构建一个基于WordNet的实体知识图谱,ImgAny能够提取与多模态特征最相关的实体词汇,并以此为基础生成实体特征。这些特征随后被用于计算实体基础的融合权重,并将多模态特征融合成实体基础的多模态特征。
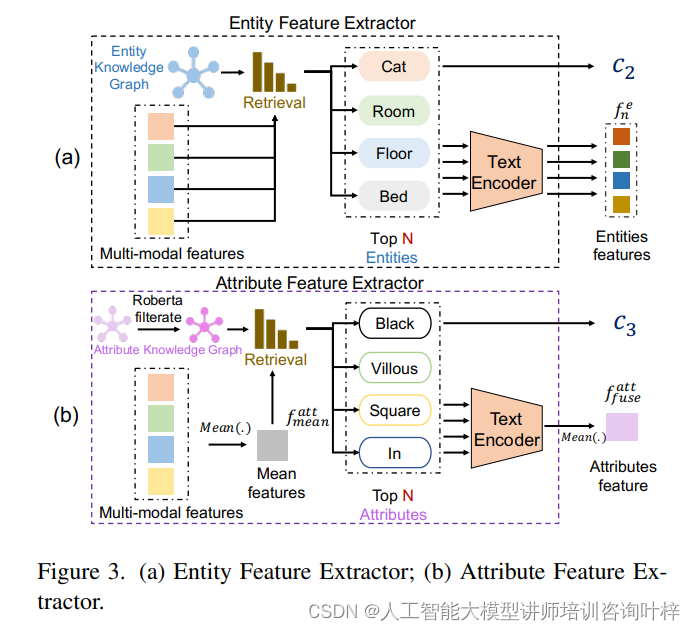
(b) 属性特征提取器: 展示了如何通过属性知识图谱提取和处理属性特征
与实体融合分支类似,属性融合分支旨在整合来自所有输入模态的不同属性特征。这一分支首先构建一个属性知识图谱,然后利用预训练的语言模型(如RoBERTa)来提取属性形容词的特征。通过计算多模态特征的平均值与属性形容词特征之间的余弦相似度,ImgAny能够检索出最相关的属性词汇,并据此提取属性特征和属性基础的融合权重,最终融合成属性基础的多模态特征。
ImgAny使用PointBind的多模态编码器作为其特征提取的基础。这些编码器能够处理包括图像、音频、文本等在内的不同模态的输入数据,并从中提取相应的特征表示。这些特征随后被用于实体融合分支和属性融合分支,这两个分支是ImgAny的关键创新点,它们分别负责处理实体和属性信息的融合。
实体融合分支利用了一个基于WordNet构建的实体知识图谱,通过计算多模态特征与知识图谱中实体的相似度,来确定与输入数据最相关的实体。属性融合分支则采用了一个属性知识图谱,它基于WordNet中的属性形容词,并通过预训练的语言模型(如RoBERTa)来辅助筛选和提取特征。
在特征融合之后,ImgAny使用了一个预训练的稳定扩散模型(Stable Diffusion V2.0)作为生成解码器。这个模型能够根据融合后的特征条件,迭代地从高斯噪声图像中去除噪声,逐步生成目标图像。值得注意的是,这个过程中Stable Diffusion的参数是被冻结的,这意味着ImgAny在生成图像时不需要进行额外的训练。
ImgAny的实现还考虑了效率和实用性。通过使用预训练的组件和冻结参数,ImgAny能够以较低的计算成本实现高质量的图像生成,这使得它在实际应用中更为可行。
实验
实验的比较方法包括CoDi和其他基线模型,如PointBind和Stable Diffusion。实验配置包括从文本、音频和图像的任意组合生成图像,以及从文本、音频、图像、点云、热成像、事件和深度的任意组合生成图像。使用的公共数据集包括Flickr-30K、ESC-50和FLIR V1等。
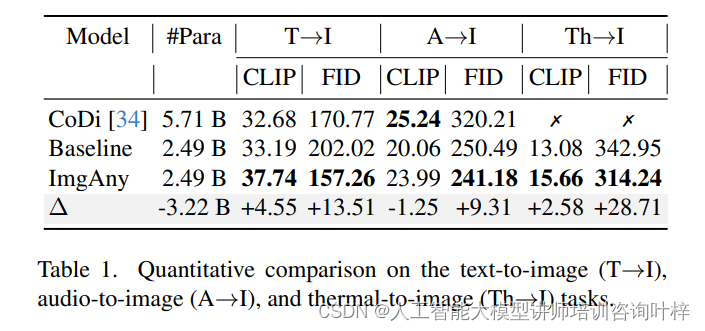
通过与CoDi和基线模型的比较,ImgAny在识别和解释输入模态的多样化语义内容方面表现出色。ImgAny能够保留关键对象和属性,准确复制输入多模态条件中的实体特征(例如狗的形状)和属性特征(例如毛色)。

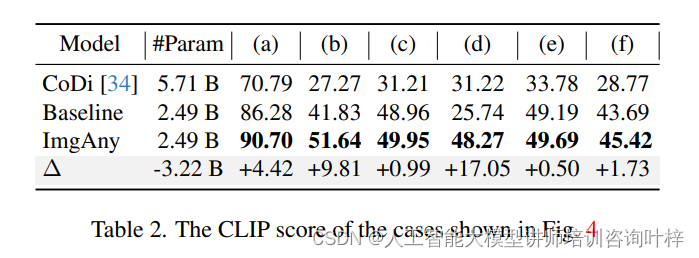
ImgAny展示了从热成像、点云和事件等与图像模态差异较大的输入生成图像的有效性。当处理具有五、六或七种模态的输入时,ImgAny在提取和保留多模态输入中的实体和属性特征方面表现出显著的能力。

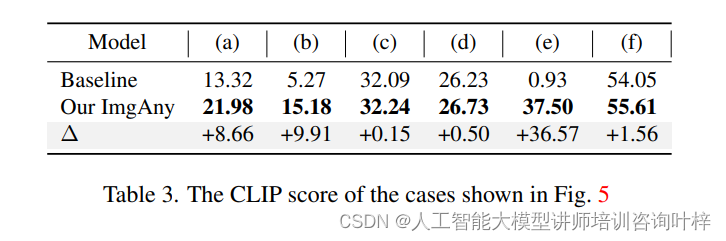
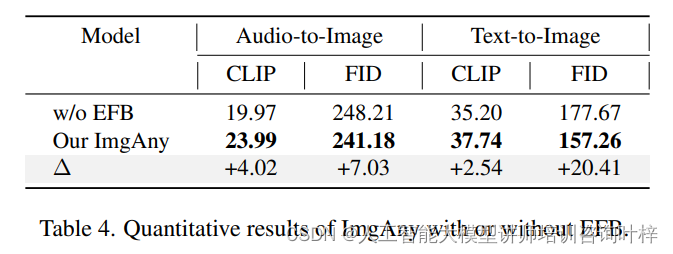
消融研究首先关注于实体融合分支(EFB)对ImgAny性能的影响。通过对比有无EFB的ImgAny在音频到图像和文本到图像生成任务上的表现,研究者发现EFB在保持生成图像中实体信息的一致性方面起着至关重要的作用。定量结果表明,缺少EFB的ImgAny在CLIP得分上平均下降了3.28%,在FID得分上平均下降了13.72%。此外,定性结果也显示了在多种输入模态下,EFB在提取实体特征方面的能力。

通过展示有无AFB的ImgAny生成的图像,可以观察到AFB在提取和保留属性特征方面的效果,例如狗的外貌、汽车的标志(奔驰)、消防车的状态和汽车的颜色(黄色)。定量的CLIP得分也显示了AFB在图像生成性能上的显著提升。

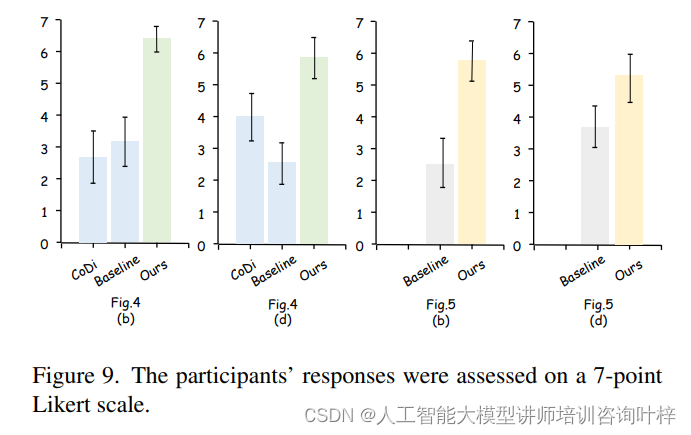
人类评估部分涉及了27名参与者,其中大多数是年轻人,年龄在18-34岁之间,性别分布相对均衡,且超过半数的参与者有AIGC模型的相关经验。评估任务要求参与者使用7点Likert量表对生成图像的推理一致性和生成质量进行评分。图像以随机顺序展示给参与者,以减少偏见。
人类评估的结果显示,所有参与者一致认为ImgAny生成的图像在推理一致性方面表现优异,平均得分超过5分,远高于CoDi和基线方法。ImgAny在不同样本间的得分波动较小,这表明其在模仿人类推理和创造力方面具有较高的稳定性和一致性。
实验证明ImgAny作为一种无需训练的图像生成方法,展现了对任意组合模态的适应性,以及在人类水平推理和创造力方面的能力。通过实体融合分支和属性融合分支的整合,ImgAny在视觉创作方面表现出色。
论文链接:https://arxiv.org/abs/2401.17664