目前,大模型落地的可靠方案还是以RAG(retrieval-augmented-generation,检索增强生成)为主,那么检索在大模型落地中就起着重要的作用。而稠密检索可以从语义层面找到与用户Query相关的文档片段,文本表征(Text Embedding)模型也就成为除大模型外的研究内容。
但也许有一些人存在疑惑,为了不用大模型作为文本表征模型呢?前两天就在知乎上刷到了这个问题,今天就来回答一下。

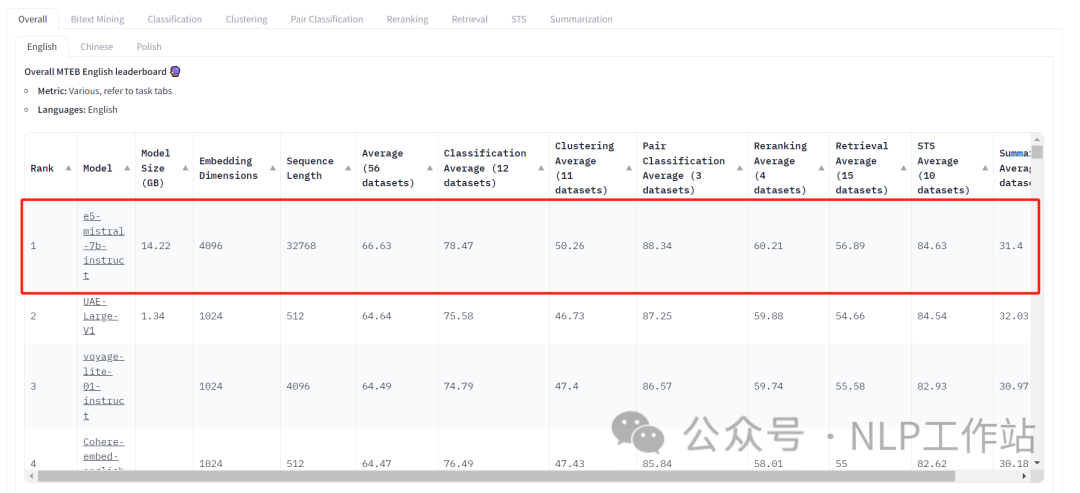
并且分享一篇前几天刚刚刷了MTEB-英文榜单的论文,《Improving Text Embeddings with Large Language Models》,即提高大模型的文本表征。
HF: https://huggingface.co/intfloat/e5-mistral-7b-instruct
Paper: https://arxiv.org/abs/2401.00368
为什么主流方法不用直接用大模型进行文本向量表征?
- 效果不理想。现在大模型的训练都是基于文本续写形式来训练的,损失函数主要预测下一个Token是否准确,而不是判断整个句子表征的好坏。因此直接用当前的大模型来对文本进行表征,效果并不理想。但如果将大模型以文本表征为目的的训练,也就用point-wise、pair-wise、list-wise等方法训练大模型,相信大模型文本向量表征一定更好。
之前也分享过一篇OpenAI以GPT3为底座训练的向量表征模型的论文-《基于对比学习的预训练文本&代码表征技术》,欢迎大家阅读。这也可能是现在openai向量接口为什么好的原因吧,内部可能就是用了更大参数的模型。
- 部署成本变高。越大的模型,部署的成本就越高,如果利用大模型进行向量表征,那么部署成本就是翻倍的。BGE等主流向量表征模型,一般都是110M-300M参数量,相较于现在的大模型来说都是极小模型,部署和推理成本都在可接受范围之内的。
- 向量表征模型对负例个数和难度都有一定的要求,当训练资源一定的情况下,模型太大,负例个数就会相对减少,可能负例减少带来的副作用比参数变大带来的好处要大。
知乎:https://www.zhihu.com/question/637789621/answer/3351187000
提高大模型的文本向量表征
对于《Improving Text Embeddings with Large Language Models》一文总结就是以下几点:
- 构造高质量训练数据
- 文本向量表征时写好提示词
- 选对底座大模型
数据构造
数据构造方法一般根据已有文档生成查询Query、伪标签或者根据查询Query生成伪文档等,而本文直接挖掘大模型内部存储的知识内容,在不依赖已有文档或查询Query的情况下,生成文档片段和查询Query,因此可以生成更多样化的数据,如下图所示。
 利用GPT-4构造数据样例
利用GPT-4构造数据样例
数据构造两步走:
- 通过GPT4模型进行头脑风暴,生成固定个数的检索任务列表
- 通过GPT4模型根据上一步生成的任务定义、Query类型、Query长度、Query清晰度、文档片段长度、语言等生成具体示例。
并且在数据构造时,根据向量表征任务不同,划分为非对称任务和对称任务:
- 非对称任务:主要是查询Query和文档片段在语义上相关,但不是彼此之间不能释义(也就是相关但不等同)。并且根据查询Query和文档片段的长度,进一步分为短长匹配、长短匹配、短短匹配和长长匹配。
- 对称任务:主要是询Query和文档片段在语义相似,但表面表达不同,包括单语语义文本相似度(STS)和双语文本检索。
通过150个指令构造了500k个样本,涉及92种语言,其中25%数据由GPT-35-Turbo构造,75%数据由GPT-4构造,详细分布如下图所示。
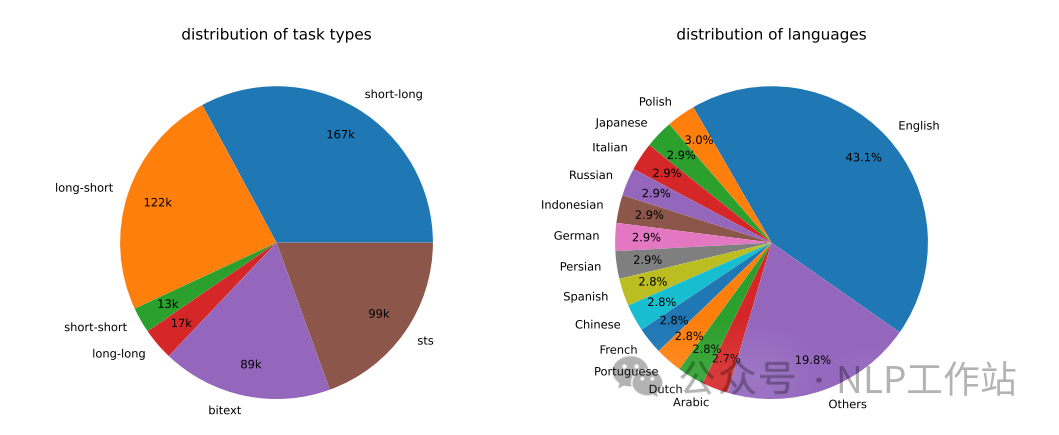 构造数据的任务类型和语言统计
构造数据的任务类型和语言统计
模型训练
模型在训练过程中,将数据末尾添加一个[EOS]标记,文本经过大模型后,将[EOS]标记对应的向量作为整个文本的句子向量。并采用InfoNCE作为损失函数,负例采用Batch内负例和一个难负例。

其中, 表示经过提示词改造的查询Query, 表示与查询Query相关的文档片段, 表示与查询Query无关的文档片段。 表示查询和文档片段 之间的匹配值,采用缩放的余弦相似度表示,缩放值 为超参数,默认为0.02。

模型在训练时,查询Query需要进行提示词改造,文档片段不做提示改造;并且不同数据集下,查询Query拼接的提示词内容不同,详细如下表所示。

当然,在模型预测时,不同评测榜单中的各个数据的提示词也略有不同,如下表所示。

模型训练过程中,采用DeepSpeed ZeRO-3 + Lora方式微调,基模采用mistral-7b模型,rank为16,训练参数共计42M,最大长度为512,批次为2048,学习率为1e-4,在32个V100上训练了18小时。
结果分析
模型在训练过程中,数据不仅涉及利用GPT4生成的数据,还包括:ELI5 、HotpotQA、FEVER、MIRACL、MSMARCO、NQ、NLI、SQuAD、TriviaQA、Quora Duplicate Questions、MrTyDi、DuReader和T2Ranking等多个数据集,共180万训练样本。
通过下表可以看到,在全量数据微调下,可以达到Sota的效果,即便是仅采用生成数据进行微调,效果也比较理想,说明生成数据很重要。

进行一些列的消融实验后,可以看出,基座模型的选择比较重要,选择Llama2-7B要比Mistral-7B低1.6%,说明底座模型越好,预训练数据效果越好,对文本向量表征模型效果越好。并且与上表进行对比,仅用msmarco数据效果为62.7%,用msmarco+构造数据效果为64.5%,进一步说明构造数据的重要性。

对于文本向量的选择,当选择平均池化和带权重平均时,都存在下过的下降,说明利用文本最后一个Token标记作为文本向量表征的效果较好。Lora的rank值选择不同时,效果也存在些许波动。并且发现,不在查询Query前加入提示词会有4.2%的下降,说明提示词很重要。
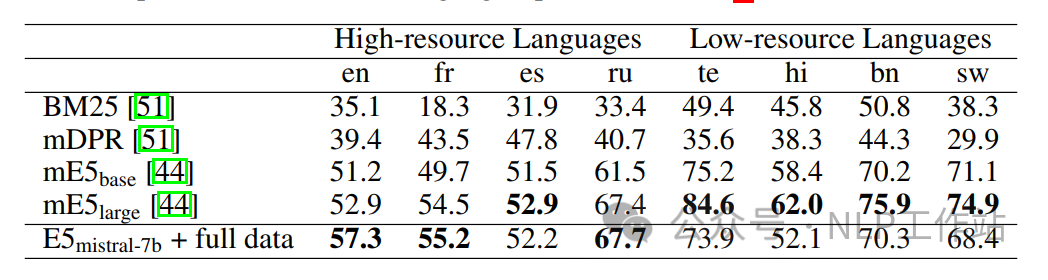
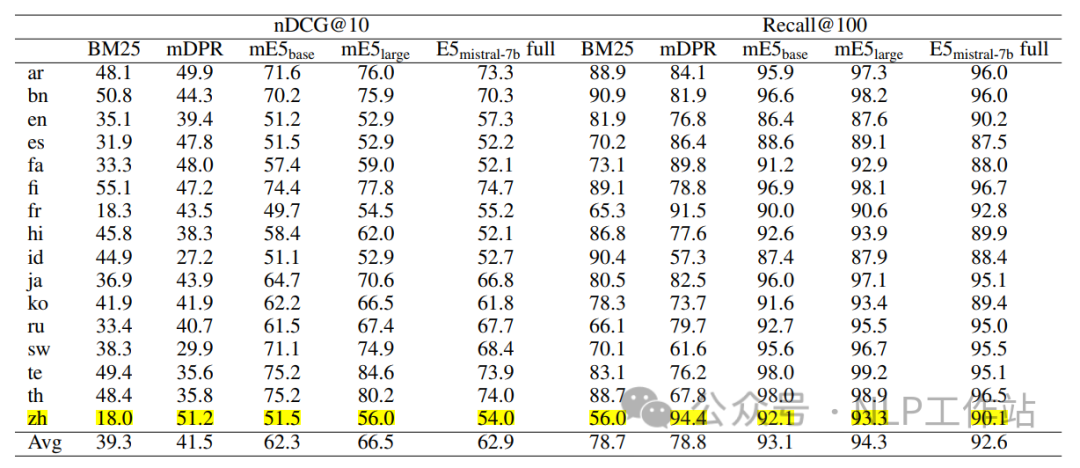
同时,对多语言表征进行了结果比较,发现模型在高资源语言下的效果比较理想,在少资源语言下的效果不理想,应该与底座模型Mistral-7B的预训练数据有关。
并且做了一个个性化密钥的检索试验,说明基于大模型的向量表征,虽然训练采用512作为最大长度,但可以将文本表征外推到4k。
 个性化密钥检索示意图
个性化密钥检索示意图

写在最后
E5-Misral-7B模型,即使在榜单上比BGE-large高了2个点,但在工业上并不是很实用。参数增加太多了,部署&推理成本也变高。那么是不是可以利用1-2B的大模型来进行向量表征呢?
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。