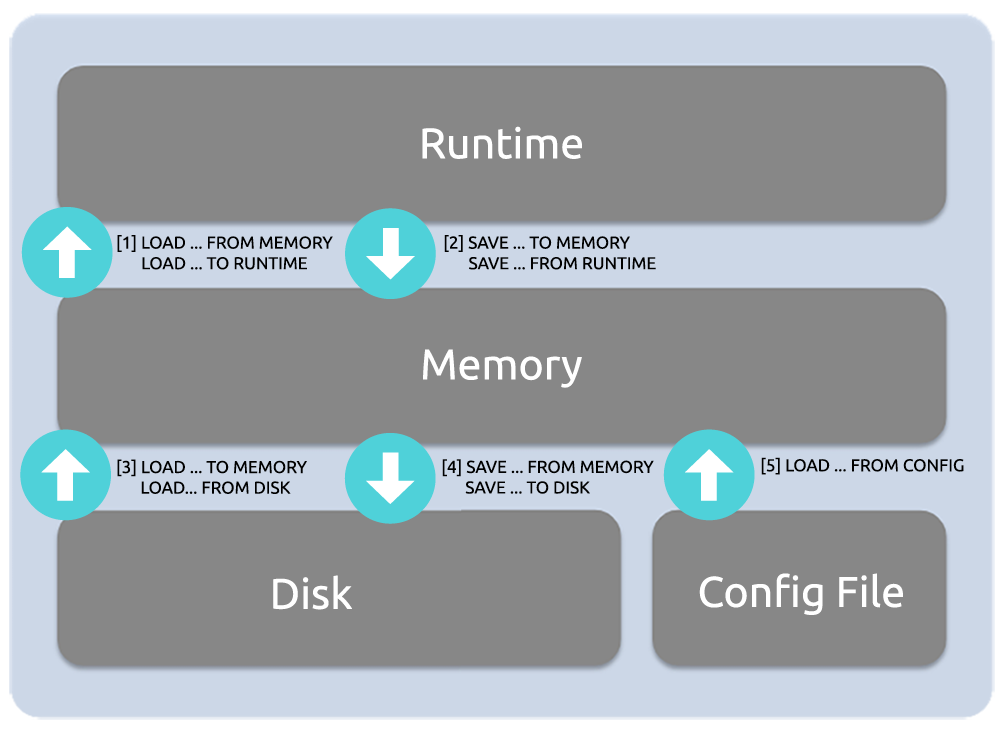
常用术语
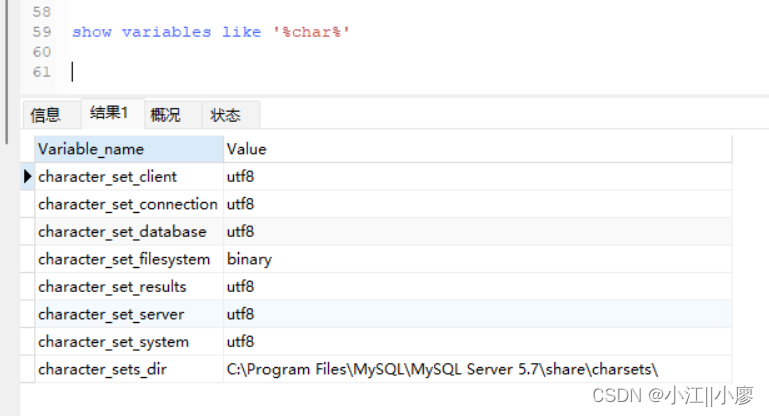
CR
CR–标准问题分类管理平台:由业务类型-角色-国家-品类-Page定义。
FAQ+SOP
FAQ是端上用户自助的第一道关口,在引导用户进行自助解决上起关键作用
SOP是指标准作业程序,客服SOP是针对用户遇到的具体问题场景,给客服提供智能的工作帮助指导,SOP加入 了大量的智能判责能力,客服无需手动去核查相关信息,大大简化了客服工单处理难度,可以非常明显的提高客服处理效率。
SDK
SDK是软件开发包,他包括一些第三方服务商提供的工具包
AnyCar
any car :在国外打车时只能选择一种车型,我们推出any car 可以在打车的时候让乘客选择多种车型
顶导
顶导是用来下发产品线信息给端上的,端上根据下发的产品线信息进行渲染 & 展示
顶导分为: 顶导分为:一级顶导(一级导航) 和 二级顶导(二级导航)
顶导仅针对乘客端,不针对司机端
一级顶导又名底导(底部导航),位于首页的底部,是端上所有流量进入各业务的入口。
若一级顶导下发出现问题,则可能造成对应的业务入口消失,导致端上的流量无法进入对应的业务,从而阻断了业务所有的后续流程。因此一级顶导影响面是非常大的。
一级顶导下发的数据可分为三大部分:
- 业务线入口数据 primaryMenu
- 小火苗数据 hotInfo
- 国家、城市、区县信息: countryId, cityId, countyId, countryIsoCode
groupId:业务线id、groupType:业务线类型、schema:业务线端跳转链接
端上根据 groupType唯一标识业务线,然后拉起对应的业务容器,找到对应的接入业务方,将schema丢给对应的接入业务方,接入业务方根据拿到的schema进行后续操作。
虽然groupType可以唯一标识业务线,但其粒度只到业务线。groupId的粒度更细,精确到了业务线 + 国家。例如不同国家的出行业务线,groupType相同,但groupId却不同
一级顶导的优点:
通过配置的方式,可以实现已注册业务线的开关城操作,无需进行代码上线
通过配置的方式,可以实现新业务线的注册和开国开城操作,无需代码上线
一级顶导的缺点:
跳转链接schema不支持业务方自定义,是按照一定规则生成。因此无法实现某个业务线想在schema中增加一些自己业务线独有的参数
一级导航不支持 二级产品线 or 业务线的SKU 作为一级导航的入口
对h5类型的业务线的开城支持不友好。(端业务线类型分为native 和 h5)
一级顶导承载的仅仅是各业务线的入口
而金刚位承载的不仅仅只是一级顶导各业务线的入口,还有各业务线内部的业务,例如:顶导二级产品线等
业务线
业务线:业务团队的概念,这个团队内部可能存在多个业务。例如出行业务线存在快车、优享,出租车,摩托车等多个业务
产品线:出行业务线内部存在多个业务,如快车、优享,出租车,摩托车等,每个业务都有一个独立的业务标识,这个标识叫做产品线
金刚位
金刚位有两种分类方式:按照业务类型 和 按照业务展示是否受下游控制
端上的业务分为两种类型:native 和 h5
金刚位优点:
通过配置化的方式实现金刚位业务单元的开关城操作,无需代码上线
各金刚位业务单元的跳转schema不再按照一定的规则生成,支持业务方自定义,更加灵活
支持业务线内部的子业务,如钱包的sku。后续还会支持顶导二级产品线,活动等业务
对于h5类型的业务,支持效果更好,操作步骤更合理。
对于各金刚位业务单元,支持业务方自己控制该金刚位对哪些用户进行展示
金刚位的缺点:
目前来说,金刚位按照城市开城,每个城市一条配置,配置该城市所开的所有金刚位的信息(业务单元基本信息 + icon + 名称 + 副标题) ,存在两个问题:
金刚位业务单元信息依赖于配置填写,比较繁琐 (正常情况下一个金刚位业务单元的基本信息大部分都是固定的)
金刚位业务单元的icon信息在城市之间重复配置
目前金刚位的业务不支持按照国家开城,后续会评估是否支持
car_level
car_level:标识司机身份,由司机级别driver_grade 和 车辆级别 level两部分共同计算得出
例如: 巴西快车司机
司机级别driver_grade : 例如巴西快车司机
车辆级别 level:属于的产品线
receive_level => 司机可听单类型集合,例如国内快车司机:可以听 快车单 + 拼车单,国内出租车司机 只能听出租车单,不能听快车单等其他单
DDMQ:didi自己搭的MQ
elvish
elvish 只会给货币符号 + 货币数值
country(国家) 决定货币单位
locale (语言)决定货币单位的展现形式,例如 对于人民币, 中文展示: 元;英文展示: 羊
ps: 不会出现,在同一国家,不同语言展示不同的货币单位
l18N
l18N: internationalization 国际化 让产品具备一键切换的技术能力
110N
110N: localization 本地化 对产品进行配置,使之符合当地习惯、法律、法规
l18N 与 l10N 对比: 前者提供能力,是前提;后者提供资源,用到前者的能力
ICU4C
ICU4C:先来说下 ICU (International Component for Unicode) Unicode国际化组件 IBM公司与开源组织合作研究的ICU4J : ICU for jave
ICU4C: ICU for C/C++
帮助开发人员根据各地的风俗和语言习惯,实现对数字、货币、时间、日期、和消息格式化和解析,对字符串进行大小写转换、整理、搜索和排序之类的国际化操作
elvish = l18N 引入sdk包, sdk包主要依赖icu4c + 时区数据库
Fleet
Fleet: 车头管理
POPE
POPE: Person Oriented Promotion Engine—以人为本的推广引擎
CRM
CRM: Customer Relationship Management—客户关系管理
常用平台
粗略了解出行业务的框架构造:passport、长连接、订单系统、司机系统、账单系统、支付系统、调度引擎与其他模块
Passport
passport:是滴滴所有在线业务的账户系统,提供用户登录授权等功能。手机号在passport被映射成账户的唯一标识UID。
提供的功能:多元化登陆方式、账户自助管理、鉴权、获取账户信息
术语:role:标识用户的身份、source:解决多源登陆的问题,同源登陆会相互剔除,不同源登陆相互隔离,不会相互剔除、origin_id:标识品牌、appid:标识前端接入方、caller_id:标识后端的调用方、uid:用户账号的唯一标识,=origin_id+role+phone、pid:乘客id,=可以和uid转化、suid:uid的低48位、driverid:司机id,数值=uid、rnid/duid:解决不同业务线司机的证照不能打通的问题,一个自然人在滴滴系统只有一个rnid,一个手机号在滴滴系统只有一个duid,每个duid下面有多个uid、suuid:端上传给passport的设备号
Bff
bff是一个关于前后端接口调用的组件,他规定了接口传输的格式、配置等,数据经过bff来访问不同的接口
理解BFF的设计,没有bff时前端与后端的接口是直接进行调用的,不同模块之间调用的链路混杂容易代码耦合,使用bff可以具有结偶、鉴权、蓝绿发布、监控的能力,加强代码的稳定性。bff分为俩部分:halo与hubble,halo是BFF的入口模块,会将端上的聚合请求进行拆分,交给hubble处理;hubble是BFF的业务逻辑模块,承担接口的业务逻辑。
理解bff的接入标准,知道各个字段的含义与是否必传等;
理解bff的入参标准、请求头标准、返回值标准与错误码可能原因
ADG
ADG:是一个广告网关服务,目前资源分为业务、营销两种场景,统一有bff进行处理,我们使用ADG将整体的营销类的资源位流量的分发、决策、补偿能力从BFF剥离出来,并逐步向未来的广告系统网关进行集成。解决的是对整个营销类资源位的管控能力较弱、流量分散、投放效果数据不准确等问题。
目前需要ADG完成的主要目标:
BFF营销类资源位的流量分发、决策能力下沉到新的广告网关服务ADG中
收拢各类营销类资源位流量,并提供标准化的广告物料请求响应服务。
网关thing只要做俩部分内容:网关功能负责流量解析,分发到各引擎、合并等;引擎功能:计划召回、频控
接口设计:1. API入参:request是私参,common是公参,login是登陆信息 caller表示调用方、origin_id表示品牌、biz_type表示业务类型 2. API出参:单次出参、批次出参、错误码:原错误逻辑:10** 新增ADG错误逻辑:11**
整个执行流程:端上访问资源位—访问bff进行统一处理—转接到thing进行处理。整个资源位的处理流程:参数构建—流控处理—运营活动控制—流量分组—频率控制—并发请求—响应合并—埋点日志—后处理操作
资源位目前有俩套接口:thing和cherry。bff根据接口url配置的优先级来判断是走thing还是cherry
使用disf调用取代http调用,或者同时提供http调用和bff接口调用;
thing:有标准请求到接口和响应
cherry:使用adx标准化请求和响应
cherry包含的接口:getBubbleInfo、getBarInfo、getXbannerInfo、getXpanelInfo、getPopupInfo、getEstMessageInfo、getDriverBannerInfo
Disf
disf:服务治理平台,具有高时效、高可用、高性能、多语言的特点,也是上层业务和下层服务的中间连接层,有诸多的应用场景比如:弹性伸缩:上游服务快速感知到服务实例的变化,业务上云,环境隔离:哨兵压测。
disf: 滴滴服务发现。主要用于注册自己的服务,方便别人用dirpc的方式调动自己的服务
RPC
RPC:远程过程调用协议,让客户端在不知道调用细节的情况下,调用远程对象像调用本地对象一样
常用的RPC框架:Thrift、gRPC、Dubbo、Spring Cloud
Thrift:传输层:从网络中读取和写入数据,定义具体的网络传输协议
协议层:定义数据传输格式
处理层:封装具体的底层,Thrift是一个典型的CS(客户端/服务器)结构,客户端和服务端可以用不同的语言开发,需要使用一种中间语言来进行关联—IDL
服务层:提供具体的网络IO模型
DiRPC:Didi Remote Procedure Call (简称DiRPC),滴滴远程过程调用。使用原生http/thrift/grpc作为远程过程调用能力的落地方案,聚焦于远程过程调用能力之上的业务场景。
具有一些基本能力:idl化:使用IDL来定义通用的服务接口,方便跨语言调用。负载均衡。服务发现:底层使用DiSF服务发现来获取服务提供方地址。故障摘除/恢复:DiRPC访问服务提供方某个地址失败次数达到健康阀值时,会自动摘除该故障地址,并发起主动探测,探活成功次数达到健康阀值时,自动恢复该地址。防雪崩:设置最小可用度(健康节点数量/所有节点数量),如果小于,则不再摘除故障节点,会有部分请求访问到故障节点,来保障下游不出现雪崩的情况。长连接。标准化日志、标准化监控、高级参数配置、动态参数配置、安全控制、Header透传。
dirpc: 通过disf调用下游服务
RPC 与 HTTP 的区别:
- 通信方式
- RPC:远程过程调用,是一种进程间通信方式。双方建立链接后,一个进程可以直接调用另一个进程的函数。
- HTTP:超文本传输协议,是一种客户端和服务器之间的请求-响应模式。客户端发送请求,服务器返回响应,两者连接后立即断开。
- 传输协议
- RPC:可以使用TCP或UDP作为传输协议。
- HTTP:使用TCP作为传输协议。
- 数据格式
- RPC:通常使用自定义的数据格式,比如XML、JSON等。
- HTTP:使用标准的MIME类型,如HTML、XML、JSON、图片等多种格式。
- 连接方式
- RPC:双方在通信期间会持续连接。
- HTTP:采用无连接的传输协议,每次连接后立即断开,下次通信需要重新建立连接。
- 应用场景
- RPC:适用于内部系统集成,提供服务的调用和响应。
- HTTP:适用于Web应用,网页访问和文件传输。
Apoloo
Apoloo—滴滴数据驱动转型的基石,Apollo是一个适用于多种场景的A/B实验与灰度发布、配置同步的平台,通过科学合理的AB实验数据辅助业务决策与效果分析,利用简单易用的灰度、配置功能提升开发效率,降低上线风险。
- Apollo Agent:负责实验(灰度,配置)在业务的主机(物理机或容器)上生效,一般线上机器都有安装Apollo Agent
- 灰度发布:灰度发布(或者灰度放量)是一种业内通用的规避版本迭代风险的手段, 它是一种通过选择目标流量,进行功能投放,通过持续观测数据逐步放量,直到全量部署的过程。相比传统发布模式,通过灰度发布可以找到容错度高、反馈意愿高的用户来尽早获取数据, 可以在问题到达所有用户之前及时止损,可以客观的比较新旧方案的受欢迎程度驱动正确的产品决策。灰度发布:分级发布,即分批次进行放量 不一次性在线上投入全部流量 流量的额度可以在灰度开关里面配置
- A/B测试:在发布流量时,把目标人群划分为A组和B组,A组应用老版本,B组体验新版本,通过观察数据来对产品进行改进
- 配置同步:应用项目中都会有一些配置信息,当需要在多个应用服务器中修改这些配置文件时,需要做到快速、简单、不停止应用服务器的方式修改并同步配置信息到所有应用中去。Apollo 配置服务能帮您集中管理所有应用环境中的配置,降低系统中管理配置的成本和因错误的配置变更带来可用性下降甚至发生故障的风险。
Apollo Agent
Apollo Agent:负责实验(灰度,配置)在业务的主机(物理机或容器)上生效,一般线上机器都有安装Apollo Agent
Apollo灰度发布与通常的按机器做小流量、分级发布是不同的。Apollo是将相同的代码部署到所有机器,通过代码里的if-else将新上线功能包起来,if里根据当前请求id,以及平台上配置的规则,决定是否走新的功能逻辑。而传统的按机器小流量发布是在小部分机器上部署一个不同的版本来达到这几台小流量机器的所有请求都走到新的功能逻辑的效果。
流量定义:对流量的处理是Apollo在线应用的核心逻辑,在某一时刻,被特定服务实例所处理的,通常情况下具有唯一标识和多种属性的实体。比如,在2016年10月1日12点12分12秒被专快api服务在gs-api-ct00.eb实例处理的,pid为xxx的打车用户,所在城市为北京,电话号码为13888888888.可以用kv集合来表示一份流量:
Apollo对流量的处理分为选取和分组两个阶段,如图:
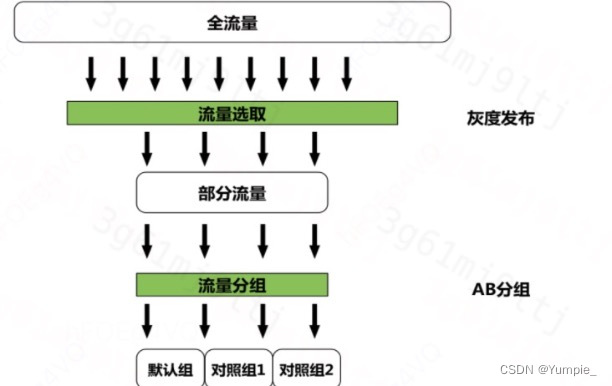
处理方式:通常有物理隔离和逻辑隔离两种,物理隔离是将不同版本部署在不同集群,这样可以减少对代码的侵入,但是不够灵活,也难以支持大量的灰发或者实验并发;逻辑隔离就是在代码里通过if else的方式对功能进行隔离,这种方式更为灵活,Apollo推荐的也是这种处理方式。
交互模型:用户先在平台创建开关(灰度或者实验标识),然后在业务代码中将流量交给Apollo 引擎(现在是sdk作为引擎)处理:
创建开关(规则):需要选择namespace,填写标识和描述。灰度可以根据【流量】【城市】【自定义条件】【自定义分组】进行分组
设置流量选取规则:灰度发布和实验都需要进行流量选取。通过点击添加人群开始配置。可以添加多个人群,人群和人群之间是或的关系,人群内部的条件之间是与的关系:
流量百分比条件:对流量里的"key"字段进行加盐hash分桶(所以传给Apollo的流量一定要有唯一标识,属性为"key",cpp和golang就是user构造函数的参数),一共1000桶, hash(idx, salt) % 1000 = m:
salt的取值为开关的名字,同一个id因为salt不一样hash结果也不同,所以同样是千分之100,不同的开关选取的流量其实是不同的。
基于属性匹配的条件:无论是Apollo预定义的city,app_version还是用户自定义的字段,Apollo都是通过将流量里对应字段的值取出来之后,再进行响应的计算,所以如果传给Apollo的流量里面没有对应的属性,即便在平台配置了也不会生效。(比如条件里配置了phone,但给Apollo的流量没有这个属性,则Apollo无法完成判断)
灰度开关
Apollo灰度开关 默认采用 lazy load机制, 不设置下发的机器节点,没法提前确定应该把灰度开关发送到那些机器上,只能在收到来自某台机器的请求是,才能明确将灰度开关发送到该机器上。所以第一次请求Apollo灰度开关可能会失败,多尝试几次就好了。
时间条件:可以通过起止日期(精确到分钟),工作日方式对流量进行控制,时间是指流量被Apollo处理的时间,不需要在流量里带上额外的属性。
Apollo在线架构的特点:流量压力大、可用性要求高、一致性要求高、稳定性要求高
完整链路为:platform配置开关,发布给distributor, distributor分发给各机房独立的zk,notifier服务通知agent监听指定的zk节点。业务方部署agent,集成sdk,初始访问时sdk在本地文件找不到开关配置,发请求给agent,agent监听本机房zk获取配置存到本地。
Apollo灰度开关: apollo灰度开关的大小,并不包括用户组当个用户组大小有限制(sdk调用限制为500K, http调用限制为150M);但是灰度开关对于 用户组的个数没有限制单个用户组大小过大,php的sdk性能会受较大影响,其他语言的sdk性能影响较小。 用户组个数不会影响sdk性能
A/B实验方法
A/B实验方法:
如何确定分流对象
分流对象是实验的每一个对象,是用来定义个体对象的途径。它可以是每一个人,也可以是每一个事件。在apollo的A/B实验里,分流单元的术语是keytype(在apollo实验配置和指标库里会出现)
乘客ID(passengerid )、司机ID(driver_id ):在实验进行期间将会处在一个固定的组。这种分流对象适用于需要对同一个司机做持续一致策略的实验。
订单ID(order_id)、冒泡ID(bubble_id):对于每一个订单,都需要重新判断它属于实验组还是对照组。这意味着用户不会获得一致的体验。 因此它适用于用户很难发现策略更改的实验场景,且更希望公平的避免由于人的因素导致的实验组和对照组差异的实验。
如何选择分流方式:
1.随机流量
2.Apollo按传入SDK的key做hash运算,然后根据hash值mod 100得到桶编号,流量选取N%,那么就是桶编号小于N的进入。这种算法保证了同一个key每次请求都进入相同的组,保证用户体验连续性。
3.时间片
Apollo流量划分方式:
1.随机分组
2.时间片轮转: 一天24个小时,其中选12个小时为实验组,另外12个小时3.为对照组
4.城市分片
由于滴滴的业务模式较为特殊,涉及乘客和司机两个市场,如果单纯将乘客随机分为实验组和对照组有可能会让分单策略较优的那一组抢占运力,造成另一组发出的订单应答率下降,特别是当运力不足的时候。因此将乘客随机分组会导致本应该独立的实验组和对照组之间变得并不独立,而分单策略较优的那一组的实验效果很可能被夸大为了减少实验组和对照组的策略之间的干扰,采用对按时间片轮转的方式做实验
实验防冲突:
同层试验:在确保试验之间互不干扰的前提下,建议您将这些试验建立在同一层,这样同一个用户只会进入该分层中的一个试验。客观来说,如果您不完全确认几个试验是否具有关联性,那么将多个试验建立在同一层则可以得到更加精准的试验结果。
分层试验:当确保不同实验之间互不干扰时,您可以选择分层试验。如果实验A和实验B使用不同的分层,则实验A和实验B均可分配最多100%的流量,此时同一个用户就有可能会进入不同层的多个试验。
这样,一方面您获得了更多的试验流量,另一方面,也可能因此消耗更多的账户资源。
Apollo实验域:
不同的app,或者不同的业务功能,同一流量,流入其中,完全不会相互影响
Apollo实验层:
官方文档; Apollo A/B 实验层域解释及全流量层整改方案
若一个代码地方想接两个实验,例如对在同一个城市 对顶导小火苗做实验,以及对首页样式做实验(sa首页 & 顶导首页), 这两个实验存在相互影响
可以共用同一个实验层,然后按比例划分进入的流量。例如进入该实验层 60%进入小火苗实验, 剩余的40%进入首页样式实验
则不会出现两个实验的流量存在交集,即不会出现 首页样式实验的对照组(展示顶导首页)的流量流入 顶导首页小火苗实验
注:但是同一域下,不同实验层的流量会存在交集。不同流量层表示测试的功能之间不会存在相互影响,即使不同层的同一个用户,依次进入不同流量层对应的实验,也不会影响实验结果

配置管理
应用业务场景动态推送:如何快速响应业务需求,降低开发成本,提高运营也是Apollo 配置服务的一大场景。
配置服务应用场景:
1.微服务应用架构下的配置管理
好处:
所有配置中心化,在应用众多的情况下配置管理变得更加方便。
所有配置不依赖应用发布,使得配置变更更加灵活。
Apollo 配置服务支持分级发布和回滚,使得配置的变更发布在微服务架构下变得更加安全。
2.分布式架构下的服务治理:
好处:
良好的性能,通过采用配置推送的方式来监听服务治理信息,对性能几乎无影响。
相关的服务治理信息可以秒级推送到,响应时间迅速。
当限流降级错推以后还可以通过秒级配置回滚来恢复状态。
国际化多语言参数管理:
1)配置通道:对于有复杂业务需求的场景,业务方通常需要定制符合业务需求的页面和操作流程,此时可以把 apollo 配置服务作为一个配置通道。业务定制UI,apollo配置通道负责把配置数据下发到业务机器,并提供SDK供使用方读取配置。
2)可视化配置:一些由运营、PM等非技术人员操作的配置,需要一个可视化页面来降低操作成本。 apollo 配置服务提供模板配置功能,由业务方根据业务需求开发配置模板,生成可视化配置表单,非技术人员根据表单进行配置。
优势:多级缓存,数据容灾
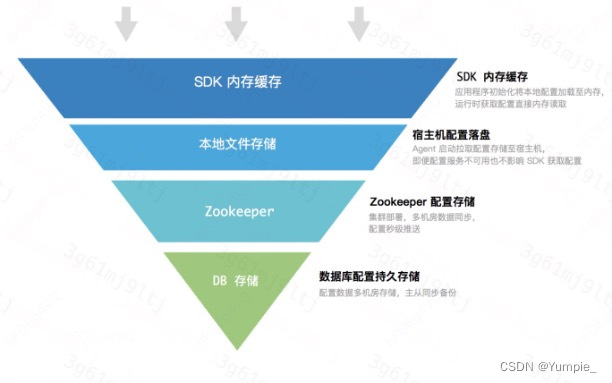
分级发布,配置逐步生效针对不同集群,支持差异化配置
四个维度的优先级:country > product_id> city_id> county_id
配置优先级:实验配置> 短期配置> 长期配置
Apollo灰度开关 默认采用 lazy load机制, 不设置下发的机器节点,没法提前确定应该把灰度开关发送到那些机器上,只能在收到来自某台机器的请求是,才能明确将灰度开关发送到该机器上。
所以第一次请求Apollo灰度开关可能会失败,多尝试几次就好了。
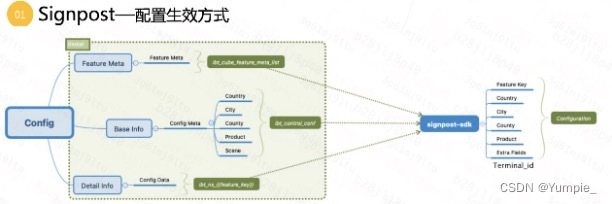
Signpost
signpost:作为业务线开城配置平台,投放的配置维度为:国家 + 城市 + 区县 + 产品线
signpost:功能投放平台
功能投放平台关注的点就是 配置 或者说是更方便的修改使用对应的配置
目前实现配置的几种方式:
1.直接修改代码,重新编译、重新部署
2.逻辑+配置的方式,仅需修改/替换配置 当前要实现的
提出了功能投放平台(signpost)这个概念:例如以price_model作为一个功能feature/ability,以国家(country_code)、城市(city_id)、区县(county_id)、产品线(product_id)为四个维度,进行配置的差异化
odin
odin:代码上线+监控平台
监控的一些主要指标:能耗、温度、CPU使用率、GPU使用率、内存总量、内存剩余量、内存使用量、进程内存占用
odin节点分为: PGSC
P: product 包含多个group
G: group: 服务组:包含多个service, 注:一个group可以包含多个group
S: service 服务,示例:cube
C: cluster 机器集群
服务回滚
快速回滚:回滚到部署前的状态
发单回滚:回滚到某一指定的版本
geofence
geofence:地理围栏系统,给业务提供了地理围栏的平台化管理体验,创建围栏通常是运营在可视化平台上创建需要的围栏,以及对围栏进行使用状态管理,并实时生效到线上服务,然后业务研发通过调用geofence服务判定坐标点是否命中指定的围栏。
在创建围栏的时候,需要选择此围栏所属的产品线和用途;产品线和用途是用来对围栏做业务上的隔离,以免在围栏判定的时候互相产生影响。
围栏的业务隔离是通过“产品线”+“用途” = groupid的方式实现的, 在围栏判定的时候,需要指定groupid,围栏判定服务只会返回命中此groupid下的围栏id列表.
groupid组合规则:
产品线编号小于10时,groupid 为产品线编号和用途编号的拼接。 例:产品线-快车(编号为2),用途-限行限号配置(编号为13),groupid为213
产品线编号大于等于10时,groupid为9000000 + 产品线编号 X 1000 + 用途编号。例:产品线-顺风车(编号为22),用途-火车站围栏(编号为54),groupid为 9000000+ 22 * 1000 + 54 = 9022054
围栏:我的理解是为了能够实现区域化投放;因为我们在投放计划的时候通常是按照国家-城市的维度来投放的,想要批量投放比较麻烦,使用围栏 可以一次性投放计划到围栏所在的区域,围栏的业务隔离是通过产品线+用途来实现的
围栏2.0将围栏的前端以及后端都进行了升级改造,目标是打造一个功能完备,体验良好的围栏工具平台,提高运营同学在围栏使用过程中的效率。
用户在地图上可以画围栏,每个围栏有个fence_id 对应,但是每个fence_id有一个groupId归属 (表示该围栏的应用场景)
例如:不用用户全选了地图上同一个区域,则会生成两个不同的fence_id。若这两个围栏用处相同,则归属于同一个groupId;若这两个围栏用处不同,则归属于不同的groupId
常用框架
SA
出现的原因
1.竞品Grab和Uber使用SA后显著提升用户在全平台的留存和交易达成率
2.自身对于出行业务人群的统计显示:用户在多业务中的频次都高于单业务用户
3.调研显示:Google调研和我们自己在墨西哥的调研都显示大多数人多SA的出现很感兴趣,而且预测SA会提升18%的交易达成率
目标:
借助出行业务的流量扶持快速发展外卖业务,让外卖业务成为第二大业务模块
1.问题:
1).往业务结果看,除了 DAU,有没有可能往前多走一步,直接影响外卖 GMV?
2).在 DAU 层面,有哪些产品功能组合,怎么保证它们是最优组合?
3).有哪些可能产生负向的用户场景?我们的预判和应对?
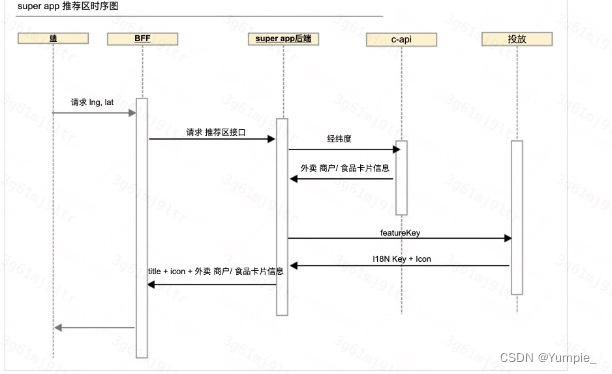
SA首页的组成部分
- 顶部公共区,用于承载“情感化消息”、“搜索”以及扫码入口
- 金刚位区,是首页的核心区域,承载需要在首页透出的各种业务、优惠、活动、券等等内容,使用出行的流量为其他业务导流,金刚位是跳转的入口,通过点击金刚位图标来跳转到其他的业务
- 出行卡片,包括地图、where to等出行相关的内容
- 全局消息区,内容包括出行、外卖未支付订单提醒、进行中订单提醒等等
- 个性推荐区,用于做定向导流用,例如外卖的套餐、商家等导流
- 全局蒙层:用于对不同类型的用户做不同的新手教育
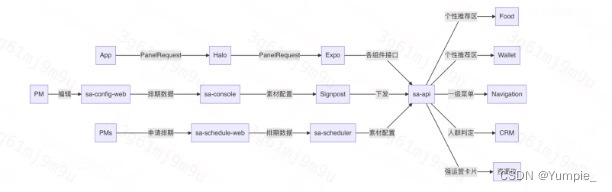
Super App后端的组成部分
- sa-api,负责对端提供数据,并管理下游服务的接入以及标准协议的制定
- sa-console,运营配置系统,基于signpost的基础上,对PM提供金刚位、运营卡片、个性推荐区等等相关的样式、数据来源的配置
- sa-scheduler,首页资源排期系统,用于对金刚位、运营卡片以及个性推荐区等位置进行占用排期,提升运营效率
其他
对内的外卖接口:c-api
首页蒙层接口:crm
业务卡片接口:mgm
fermion框架
fermion框架包括
echo
orm => xorm
redis
log
http
validator (入参校验器) 基于https://github.com/go-playground/validator.git
接入inrouter的原因: 为了使用inrouter的限流。
nuwa框架
nuwa框架,类似于ssm框架:

controller 定义接口路由、models 相当于logic层、dao:相当于数据库操作层
常用应用
Flex
flex:是为了与Indriver竞争而推出的新产品,乘客可以选择一个价钱发起订单选择自己的司机 司机可以查看订单价格是否合适选择接单与否 选择自己的乘客,是一种与快车计费规则(起步价+按时计费/按距离计费)不同的产品
99
99专门负责巴西的业务
didi_au
didi_au专门负责澳大利亚的业务
didi_global
didi_global用来负责其他国家的业务,具体的划分标准好像是按照使用的语言来划分的