目录
一、实验目的... 1
二、实验环境... 1
三、实验内容... 1
1)Python纵向柱状图实训... 1
2)Python水平柱状图实训... 3
3)Python多数据并列柱状图实训.. 3
4)Python折线图实训... 4
5)Python直方图实训... 5
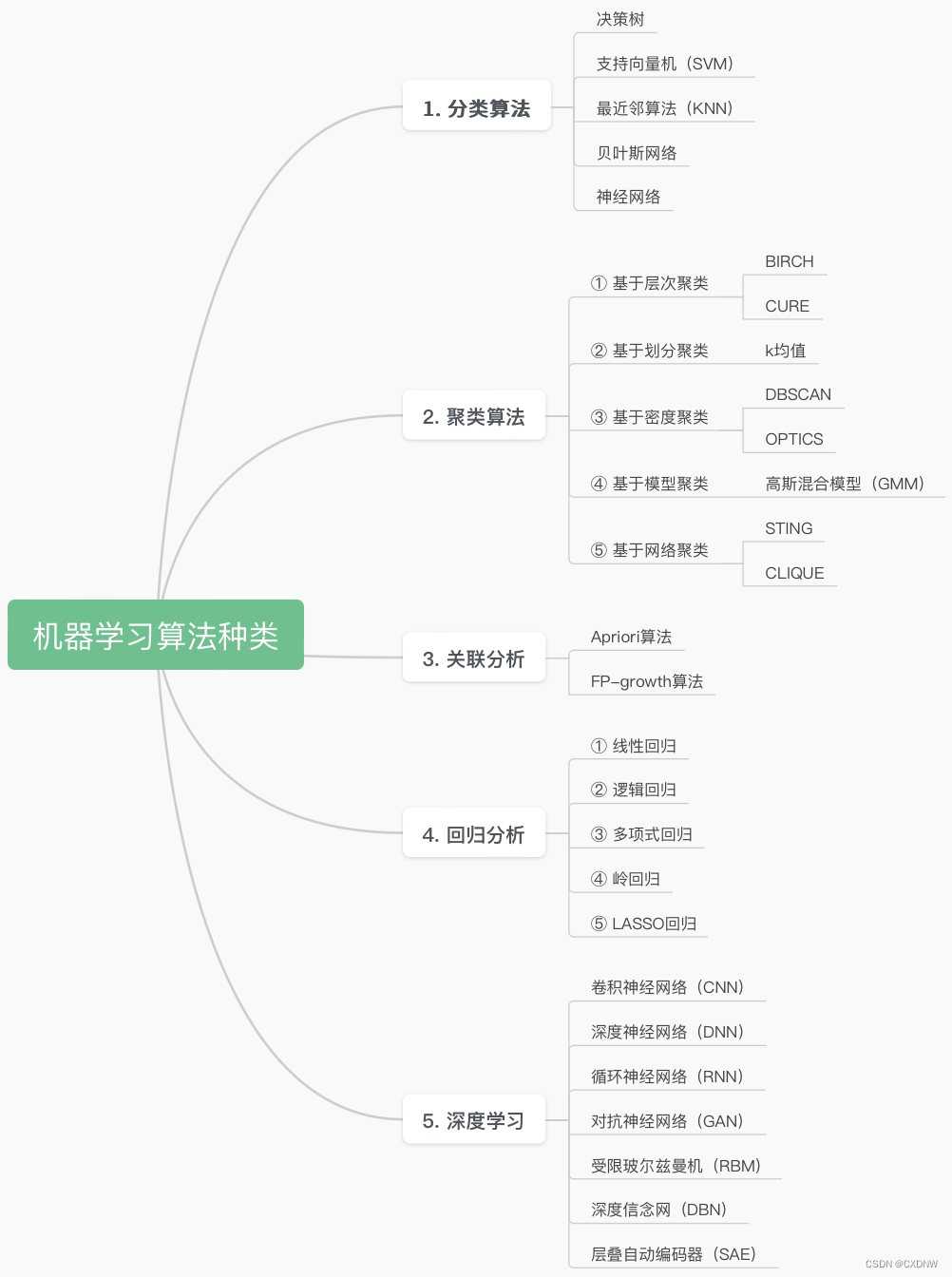
6)机器学习中的可视化应用... 6
四、思考问题... 8
五、总结与心得体会... 8
一、实验目的
掌握python工具,能够进行数据可视化;
掌握商业案例中的数据分析与数据可视化
二、实验环境
硬件: 微型图像处理系统,
包括: 主机, PC机;
操作系统: Windows 11
应用软件: Jupyter Notebook, pycharm
数字图像处理软件: Excel/Python
三、实验内容
1)Python纵向柱状图实训
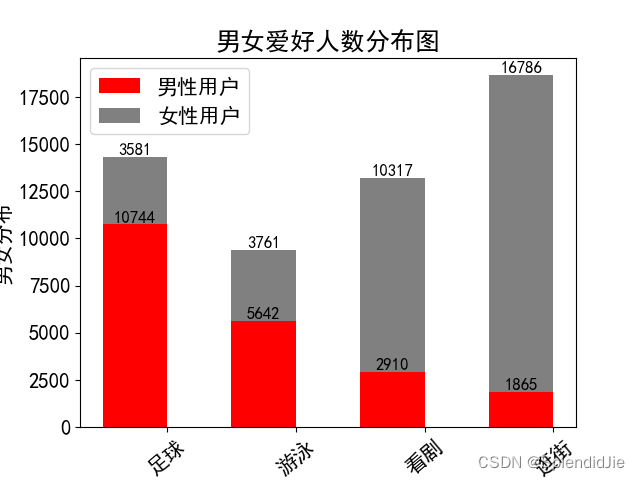
为了显示男女爱好的人数分布,本实验使用Python绘制纵向柱状图实现数据可视化。编写以下代码:
import as import as 'font' family ='SimHei' size =15 )" 男女爱好人数分布图 " # 图标题 14325 , 9403 , 13227 , 18651 ])0.75 , 0.6 , 0.22 , 0.1 ])1 -ratio)' 足球 ' ' 游泳 ' ' 看剧 ' ' 逛街 ' 0.5 len (x))color ='red' label =' 男性用户 ' bottom =men, color ='gray' label =' 女性用户 ' # 这一块可设置 bottom,top ,如果是水平放置的,可以设置 right 或者 left 。 ' 应用类别 ' ' 男女分布 ' 2 , x, rotation =40 )#bar 图上显示数字 for in zip (idx,men):0.05 , '%.0f' ha ='center' va = 'bottom' fontsize =12 )for in zip (idx,women,men):0.5 , '%.0f' ha ='center' va = 'bottom' fontsize =12 )
运行结果如下,可以看出男性的爱好多数为足球和游泳,女生的爱好多数为看剧和逛街:
2)Python水平柱状图实训
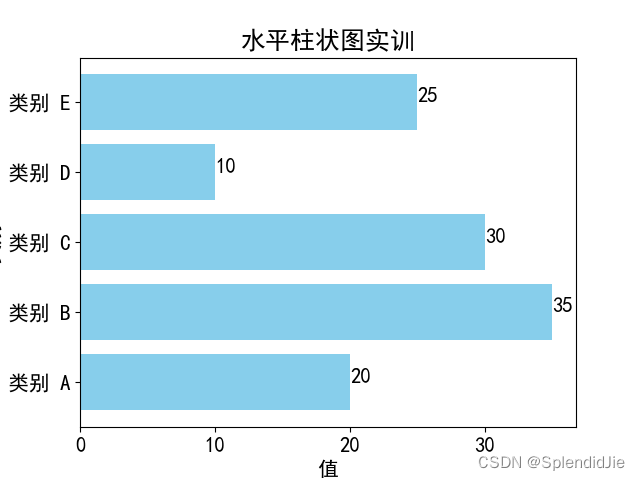
为了绘制水平柱状图,编写以下代码:
import as 'font' family ='SimHei' size =15 )# 假设我们有一组数据,表示不同的类别的值 ' 类别 A' ' 类别 B' ' 类别 C' ' 类别 D' ' 类别 E' 20 , 35 , 30 , 10 , 25 ]# 创建水平柱状图 color ='skyblue' # 添加标签和标题 ' 值 ' ' 类别 ' ' 水平柱状图实训 ' # 可选:显示每个条形上方的值 for in enumerate (values):str (value))# 显示图形
运行结果如下:
3)Python多数据并列柱状图实训
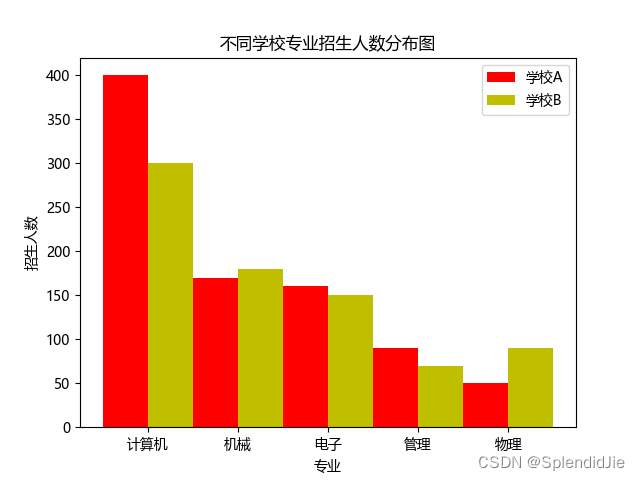
本实验展示了不同的专业在不同学校的招收人数分布图情况。编写以下代码:
import as import as 'font.sans-serif' 'Microsoft YaHei' # 设置字体 " 不同学校专业招生人数分布图 " # 图标题 5 )400 ,170 ,160 ,90 ,50 ]300 ,180 ,150 ,70 ,90 ]0.5 " 计算机 " " 机械 " " 电子 " " 管理 " " 物理 " color ="r" align ="center" label =" 学校 A" color ="y" align ="center" label =" 学校 B" " 专业 " " 招生人数 " 2 ,tick_label)
根据结果显示,学校a和学校b均在计算机专业招收人数最多,具体的情况如下图:
4)Python折线图实训
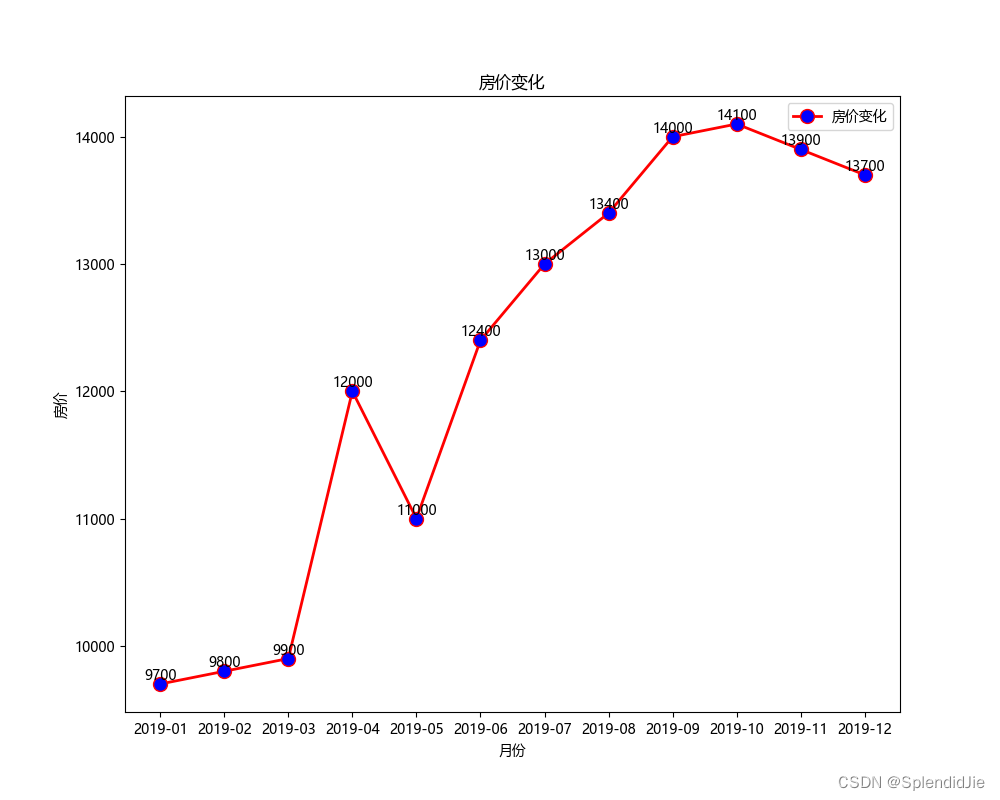
本实验绘制2019年1月~2019年12月的房价变化折线图,编写以下代码:
import matplotlib.pyplot as plt 'font.sans-serif'] =[ 'Microsoft YaHei'] # 设置字体 x1 = [ '2019-01', '2019-02', '2019-03', '2019-04', '2019-05', '2019-06', '2019-07', '2019-08', '2019-09', '2019-10', '2019-11', '2019-12'] 9700 , 9800 , 9900 , 12000 , 11000 , 12400 , 13000 , 13400 , 14000 , 14100 , 13900 , 13700 ] figsize =( 10 , 8 )) # 标题 plt.title( "房价变化") label = '房价变化', linewidth = 2 , color = 'r', marker = 'o', markerfacecolor = 'blue', markersize = 10 ) # 横坐标描述 plt.xlabel( '月份') # 纵坐标描述 plt.ylabel( '房价') for a, b in zip (x1, y1): ha = 'center', va = 'bottom', fontsize = 10 )
从结果可以看出,在2019年1月的时候房价最低,在2019年12月的时候,房价最高整体呈上升趋势,其中在2019年5月的时候下降。运行结果如下:
5)Python直方图实训
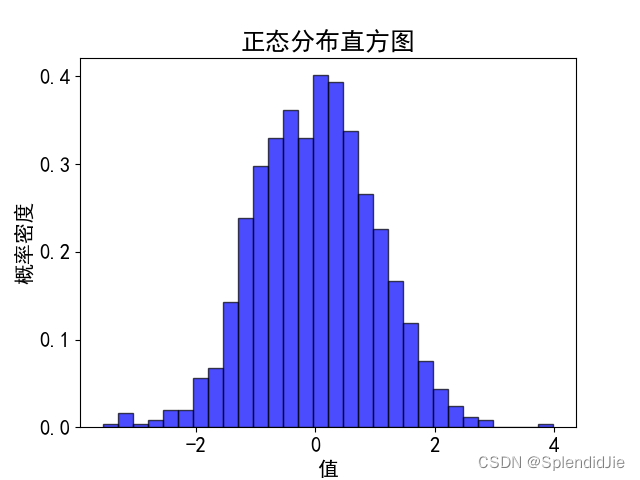
本实验绘制正态分布直方图,图的值表示当前值的概率密度,为了方便信息展示只展示-4到4的概率密度,编写以下代码:
import as import as 'font' family ='SimHei' size =15 )'axes.unicode_minus' False # 解决保存图像是负号 '-' 显示为方块的问题 # 生成一个随机样本数据集 # 假设我们有一个正态分布的随机样本 loc =0 , scale =1 , size =1000 )# 创建直方图 # bins 参数定义了直方图的箱数 # density 参数设置为 True ,可以展示概率密度而不是频率 bins =30 , density =True alpha =0.7 , color ='blue' edgecolor ='black' # 设置直方图的标题和坐标轴标签 ' 正态分布直方图 ' ' 值 ' ' 概率密度 ' # 可选:显示直方图的均值和标准差 60 , 0.0075 , f'Mean: { : .2f } ' 60 , 0.005 , f'Std Dev: { : .2f } ' # 显示图形
运行结果如下:
6)机器学习中的可视化应用
在机器学习中,可视化是一个重要的工具,它可以帮助我们理解数据的特征、模型的性能以及数据点之间的关系。以下是一个简单的 Python 代码示例,展示了如何在机器学习中应用可视化。
import as import as from import from import import as # 创建一个简单的二分类数据集 n_samples =100 , n_features =2 , n_redundant =0 , n_informative =2 ,random_state =1 , n_clusters_per_class =1 )# 使用逻辑回归模型 # 绘制决策边界 0 ].min() - 1 , X[:, 0 ].max() + 1 1 ].min() - 1 , X[:, 1 ].max() + 1 0.01 ),0.01 ))figsize =(10 , 6 ))alpha =0.4 )0 ], X[:, 1 ], c =y, s =20 , edgecolor ='k' 'Feature 1' 'Feature 2' 'Decision Boundary using Logistic Regression'
这段代码首先导入了所需的库,然后创建了一个简单的二分类数据集。接着,使用LogisticRegression模型进行拟合。
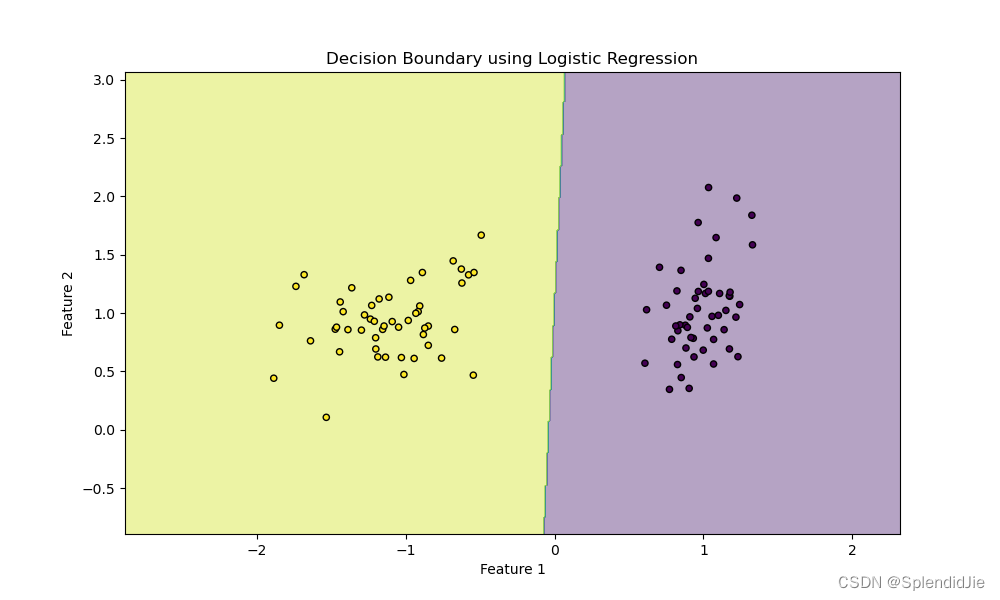
在绘制决策边界的部分,我们首先定义了x和y的最小值和最大值,然后创建了一个网格来覆盖整个数据点的范围。使用模型在这些网格点上的预测结果来填充这个区域,从而绘制出决策边界。
最后,使用plt.scatter绘制了原始数据点,并用不同的颜色表示不同的类别。plt.contourf用于绘制决策边界的填充图。运行结果如下:
四、思考问题
Python软件功能强大,除了上述要实现的功能,大家可以自己进行扩展。
五、总结与心得体会
在完成上述的可视化制作实验后,我有以下几点心得体会:
理解数据分布:通过制作直方图和折线图,我更好地理解了数据的分布情况和随时间的变化趋势。直方图特别适合展示连续数据的分布,而折线图则能够清晰地展示数据随时间的变化。 比较不同类别:纵向柱状图和水平柱状图都是比较不同类别之间数值大小的有效工具。我学会了如何根据需要选择使用纵向或水平柱状图,这取决于我希望强调的信息和图表的布局。 并列柱状图的挑战:在制作多数据并列柱状图时,我意识到需要仔细选择颜色和标签,以确保每个数据集都能被清晰地区分和理解。 技术实现:通过这些实验,我加深了对matplotlib和seaborn库的了解,学会了如何使用这些工具来创建各种图表。我也认识到了代码的可读性和模块化设计的重要性,这使得代码更易于维护和更新。 数据可视化的重要性:我了解到,良好的数据可视化可以帮助观众快速抓住数据的关键信息。图表的清晰度和准确性对于有效传达分析结果至关重要。 机器学习可视化的洞察:在机器学习项目中,可视化不仅用于展示数据,还可以用于展示模型的决策过程,如决策边界。这有助于理解模型是如何工作的,以及它在特定情况下可能的优缺点。 迭代与改进:在实验过程中,我学会了如何根据反馈不断迭代和改进我的图表。一个好的图表往往需要多次修改,包括调整颜色、字体大小、标签和布局。 工具的局限性:我也意识到了可视化工具的局限性。例如,某些类型的数据或分布可能不适合用柱状图或直方图来展示。因此,选择最合适的图表类型来传达特定的信息是一项重要的技能。 注释和解释:我学会了在图表中添加适当的注释和解释,这对于使图表自解释非常重要。这包括轴标签、图例、标题和任何必要的文本说明。 未来方向:最后,我意识到数据可视化是一个不断发展的领域,总有新的技术和方法出现。我计划继续学习,以便能够利用最新的工具和技术来提高我的可视化技能。 通过这些实验,我不仅提升了我的技术技能,而且对如何有效地传达数据信息有了更深刻的理解。这些经验对我的数据科学职业生涯将是宝贵的资产。