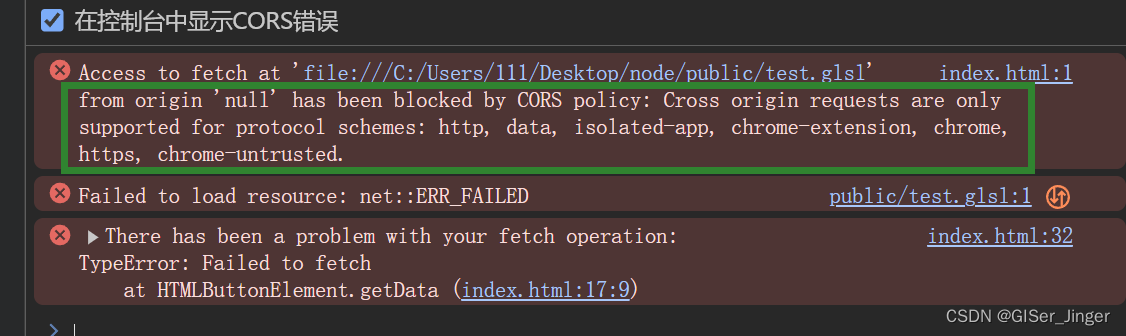
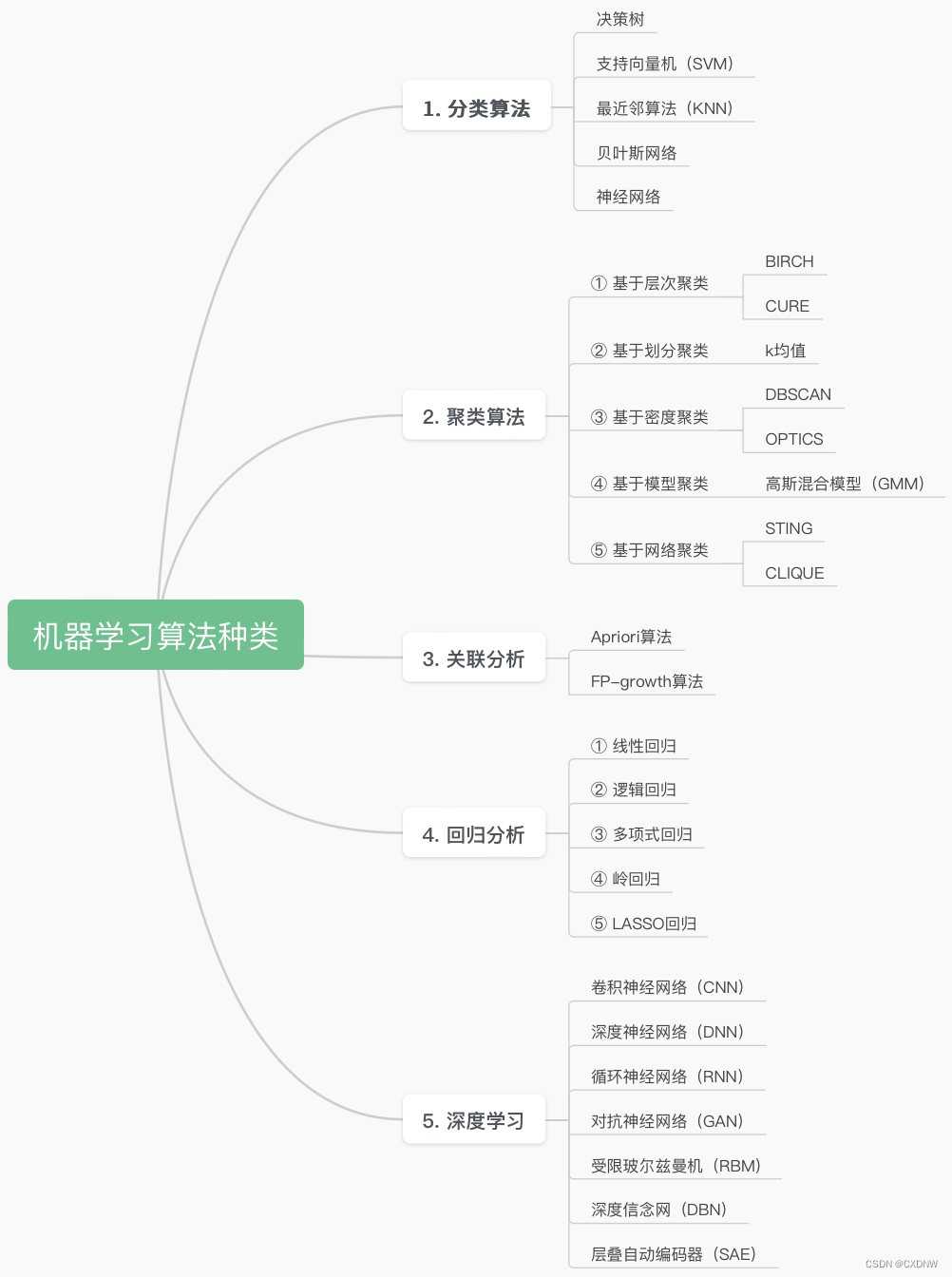
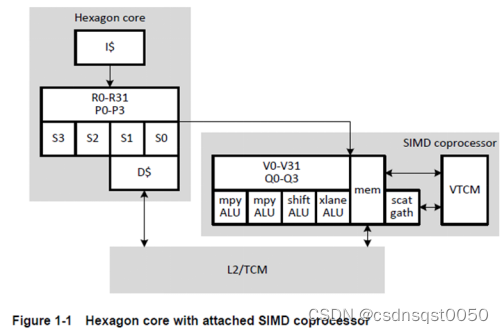
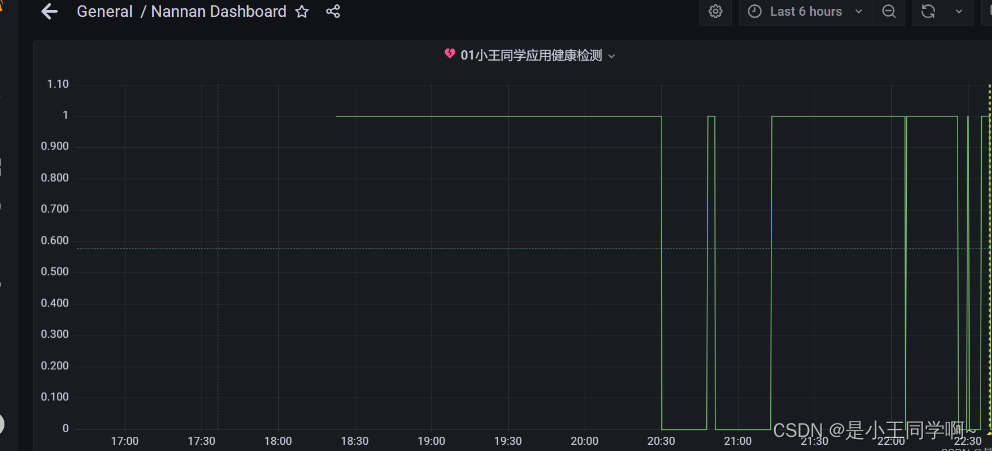
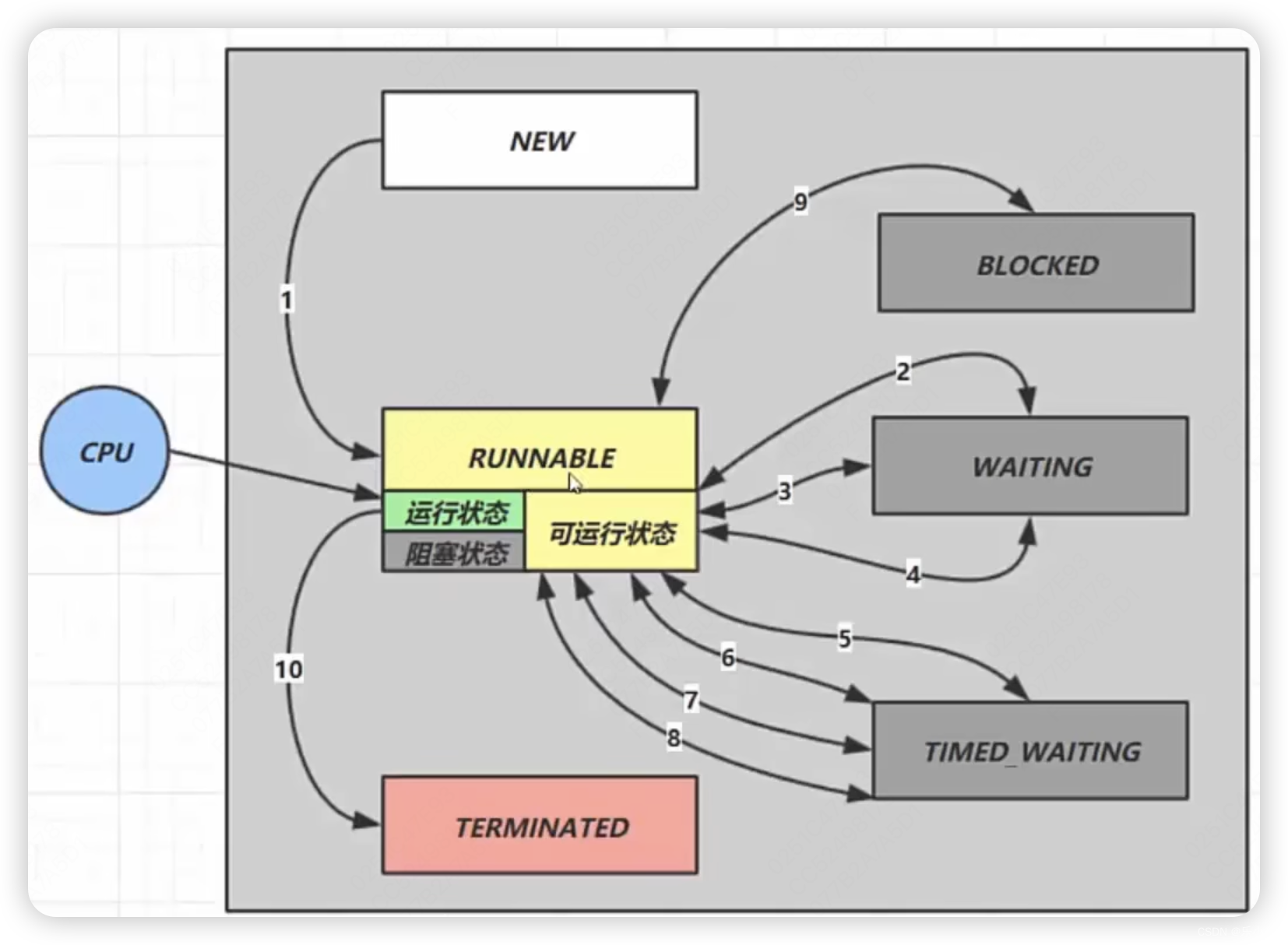
这是一个典型的多模态问题,融合了CV与NLP的技术,计算机需要同时学会理解图像和文字。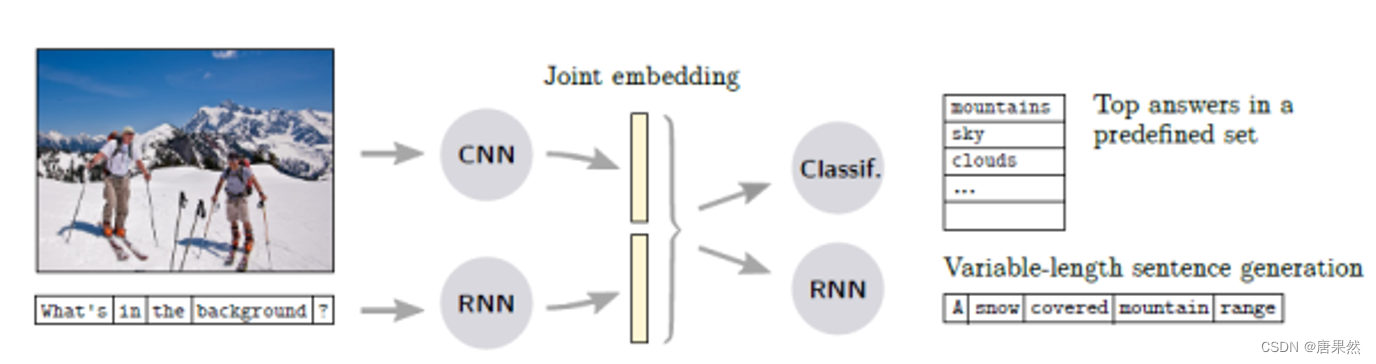
Joint embedding
首先,图像和问题分别由CNN和RNN进行第一次编码得到各自的特征,随后共同输入到另一个编码器中得到joint embedding,最后通过解码器输出答案。 值得注意的是,有的工作把VQA视为序列生成问题,而有的则把VQA简化为一个答案范围可预知的分类问题。在前者的设定下,解码器是一个RNN,输出长度不等的序列;后者的解码器则是一个分类器,从预定义的词汇表中选择答案。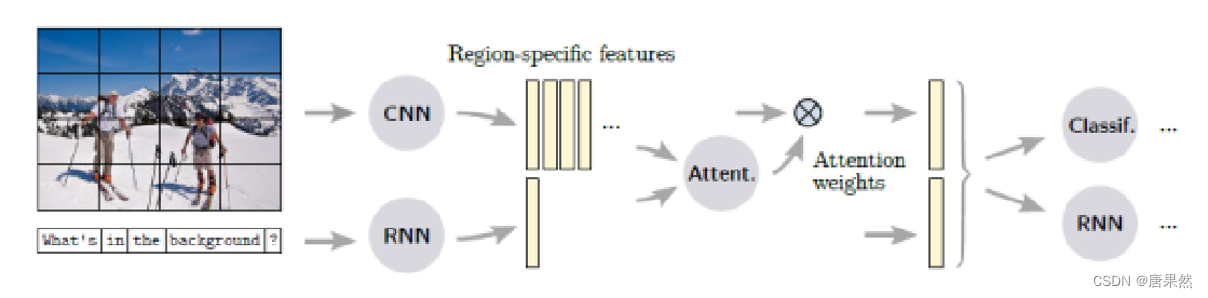
注意力机制
attention机制起源于机器翻译问题,目的是让模型动态地调整对输入项各部分的关注度,从而提升模型的“专注力”。而自从Xu等人将attention机制成功运用到Image Captioning中,attention机制在视觉任务中受到越来越多的关注,应用到VQA中也是再自然不过。上面就是将attention机制应用到上个方法中的示意图。
模型
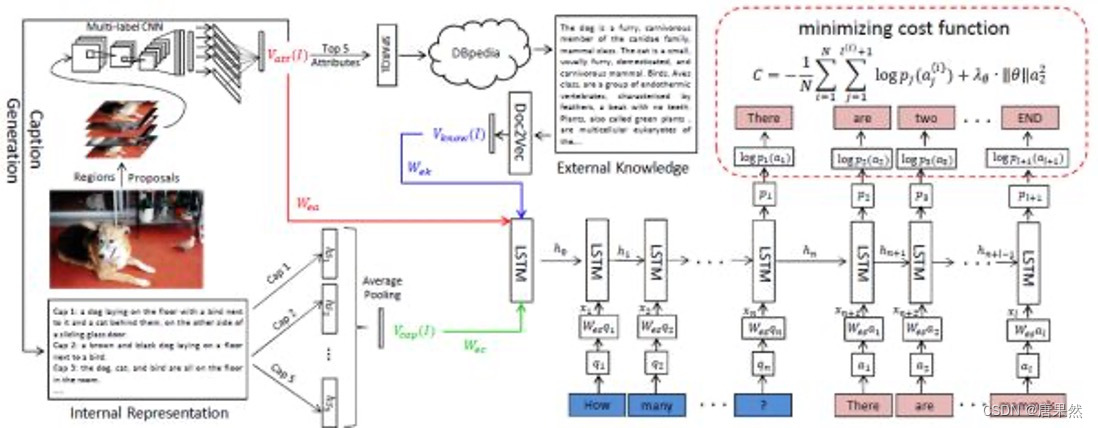
红色部分表示,对图像进行多标签分类,得到图像标签(attribute)。
蓝色部分表示,把上述图像标签中最明显的5个标签输入知识库DBpedia中检索出相关内容,然后利用Doc2Vec进行编码。
绿色部分表示,利用上述图像标签生成多个图像描述(caption),将这一组图像描述编码。
以上三项同时输入到一个Seq2Seq模型中作为其初始状态,然后该Seq2Seq模型将问题进行编码,解码出最终答案,并用MLE的方法进行