目录
一、ELK/EFK简介
1.1 什么是ELK/EFK?
1.2 常见架构
1、Elasticsearch + Logstash + Kibana
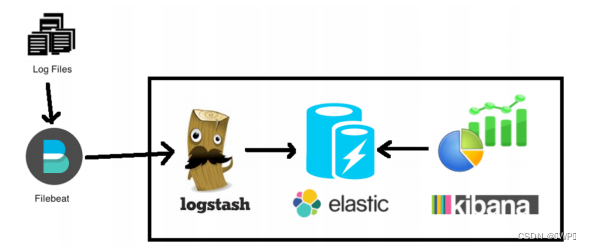
2、Elasticsearch + Logstash + Filebeat + Kibana
3、Elasticsearch + Logstash + Filebeat + Kibana + Redis
4、Elasticsearch + Fluentd + Filebeat + Kibana
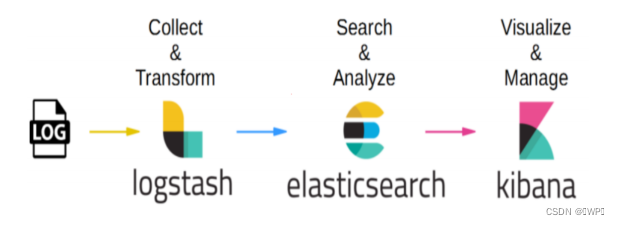
1.3 基本流程
二、ELK部署
2.1 环境准备
2.2 部署ElasticSearch集群环境
2.2.1 安装Elasticsearch
2.2.2 配置Elasticsearch集群
2.2.3 检查Elasticsearch集群
2.3 部署Redis+Keepalived高可用环境
2.4 部署Kibana及nginx代理访问环境
三、ELK日志收集
3.1 客户机日志收集操作(Logstash)
3.1.1 logstash 介绍
3.1.2 安装logstash
3.1.3 logStash配置语法
3.1.4 logstash插件
3.2 客户机日志收集操作(Filebeat)
3.2.1 安装 Filebeat
3.2.2 配置 Filebeat
一、ELK/EFK简介
1.1 什么是ELK/EFK?
ELK 是三个开源软件的缩写,分别表示: Elasticsearch , Logstash, Kibana , 它们都是开源软件。新增了一个FileBeat ,它是一个轻量级的日志收集处理工具 (Agent) , Filebeat 占用资源少,适合于在各个服务器上搜集日志后传输给Logstash ,官方也推荐此工具。Elasticsearch 是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful 风格接口,多数据源,自动搜索负载等。Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s 架构, client 端安装在需要收集日志的主机上, server 端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch 上去。Kibana 也是一个开源和免费的工具, Kibana 可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。从 ELK 到 EFK:由于logstash 内存占用较大,灵活性相对没那么好, ELK 正在被 EFK 逐步替代 . 其中本文所讲的 EFK 是Elasticsearch+Fluentd+Kafka。Kubernetes 中比较流行的日志收集解决方案是 Elasticsearch 、 Fluentd 和 Kibana ( EFK )技术栈,也是官方现在比较推荐的一种方案。Fluentd是一个收集日志文件的开源软件,目前提供数百个插件可用于存储大数据用于日志搜索,数据分析和存储。Fluentd 适用于以下场景。收集多台服务器的访问日志进行可视化在AWS 等云端使用 AutoScaling 时把日志文件收集至 S3( 需要安装插件 )收集客户端的信息并输出至Message Queue ,供其他应用处理
1.2 常见架构
1、Elasticsearch + Logstash + Kibana
2、Elasticsearch + Logstash + Filebeat + Kibana
3、Elasticsearch + Logstash + Filebeat + Kibana + Redis

这种架构,通过增加中间件来避免日志丢失。
4、Elasticsearch + Fluentd + Filebeat + Kibana

1.3 基本流程
下面以第三种架构为例,基本流程如下:
1 、 Logstash-Shipper 获取日志信息发送到 redis 。2 、 Redis 在此处的作用是防止 ElasticSearch 服务异常导致丢失日志,提供消息队列的作用。3 、 logstash 是读取 Redis 中的日志信息发送给 ElasticSearch 。4 、 ElasticSearch 提供日志存储和检索。5 、 Kibana 是 ElasticSearch 可视化界面插件。
二、ELK部署
2.1 环境准备
| 主机名 | IP地址 | 角色 |
| elk-node01 | 192.168.186.161 | es01,redis01 |
| elk-node02 | 192.168.186.162 | es02,redis02(vip:192.168.186.100) |
| elk-node03 | 192.168.186.163 | es03,kibana,nginx |
1、设置主机名和hosts解析
[root@elk-node01 ~]# cat >> /etc/hosts << EOF
192.168.186.161 elk-node01
192.168.186.162 elk-node02
192.168.186.163 elk-node03
EOF
cat >> /etc/hosts << EOF
192.168.186.161 elk-node01
192.168.186.162 elk-node02
192.168.186.163 elk-node03
EOF
[root@elk-node01 ~]# tail -3 /etc/hosts
192.168.186.161 elk-node01
192.168.186.162 elk-node02
192.168.186.163 elk-node032、时间同步
3、部署jdk
三台机器都部署jdk,建议内存3G以上
[root@elk-node01 ~]# rpm -ivh jdk-8u261-linux-x64.rpm
[root@elk-node01 ~]# java -version
java version "1.8.0_261"
Java(TM) SE Runtime Environment (build 1.8.0_261-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.261-b12, mixed mode)2.2 部署ElasticSearch集群环境
2.2.1 安装Elasticsearch
三台机器都部署
使用清华镜像源,本文安装7.2.0
# vim /etc/yum.repos.d/elk.repo
[elk]
name=elk 7.x
baseurl=https://mirrors.tuna.tsinghua.edu.cn/elasticstack/yum/elastic-7.x/
gpgcheck=0
安装:# yum install -y elasticsearch-7.2.02.2.2 配置Elasticsearch集群
elk-node01节点的配置
root@elk-node01 ~]# grep '^[a-Z]' /etc/elasticsearch/elasticsearch.yml
cluster.name: elk-node01
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 192.168.186.161
http.port: 9200
discovery.seed_hosts: ["elk-node01", "elk-node02","elk-node03"]
cluster.initial_master_nodes: ["elk-node01"]
node.master: true
node.data: false
node.ingest: false
node.ml: false
cluster.remote.connect: false安装**head插件**,在5.0版本之后不支持直接把插件包放入es安装目录的plugin目录下,需要单独安装。
1>安装环境支持,需要安装nodejs
[root@elk-node01 ~]# yum install -y nodejs npm
2>下载head插件
[root@elk-node01 elasticsearch]# cd /var/lib/elasticsearch/
[root@elk-node01 elasticsearch]# wget https://github.com/mobz/elasticsearch-head/archive/master.zip3>安装依赖包
[root@elk-node01 elasticsearch]# yum install openssl bzip2 unzip -y
下载运行head必要的文件(放置在文件夹/tmp下)
[root@elk-node01 elasticsearch]# cd /tmp
[root@elk-node01 tmp]# wget https://npm.taobao.org/mirrors/phantomjs/phantomjs-2.1.1-linux-x86_64.tar.bz2
用以下命令把下载到的包添加到npm cache目录中
\# npm cache add phantomjs
执行npm install,它便会使用本地缓存的xxx.tgz,而跳过下载过程。
npm安装卡时可以打开info level的log,命令如下
#npm config set loglevel info
解压master.zip
\# unzip master.zip
开始安装依赖:
[root@elk-node01 elasticsearch]# cd elasticsearch-head-master/
\# npm install
\# 直接使用npm安装时间久,依赖网络,替换为淘宝的cnpm
npm install -g cnpm --registry=https://registry.npm.taobao.org
\# 安装依赖
cnpm install在该文件中添加如下,务必注意不要漏了添加“,”号,这边的hostname:’*’,表示允许所有IP可以访问
options: {
port: 9100,
base: '.',
keepalive: true,
hostname: '*'
}
修改elasticsearch-head默认连接地址,将localhost改为本机IP
# vim _site/app.jsthis.base_uri = this.config.base_uri || this.prefs.get( "app-base_uri" ) ||"http://192.168.186.161:9200" ;
 5>修改elasticSearch配置文件并启动ElasticSearch
5>修改elasticSearch配置文件并启动ElasticSearch
[root@elk-node01 elasticsearch]# vim elasticsearch.yml
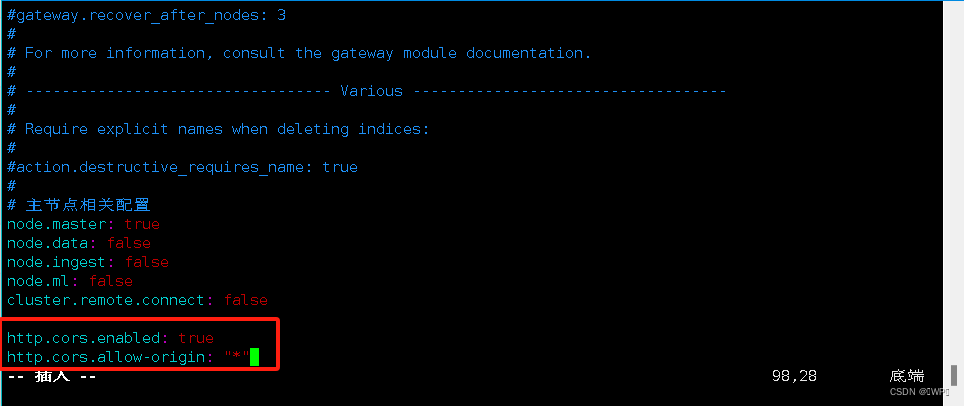
重启:
[root@elk-node01 elasticsearch]# systemctl restart elasticsearch
启动插件:# cd /var/lib/elasticsearch/elasticsearch-head-master/# nohup ./node_modules/grunt/bin/grunt server &
访问IP:9100就能看到我们集群信息

安装Bigdesk插件
1>下载
# cd /var/lib/elasticsearch/# yum install git -y# git clone https://github.com/hlstudio/bigdesk
2>启动web服务器,默认监听端口号8000,指定启动端口,并后台启动
# cd /var/lib/elasticsearch/bigdesk/_site# nohup python -m SimpleHTTPServer &此时通过访问 web 界面来监控我们的集群状态。http://IP:8000
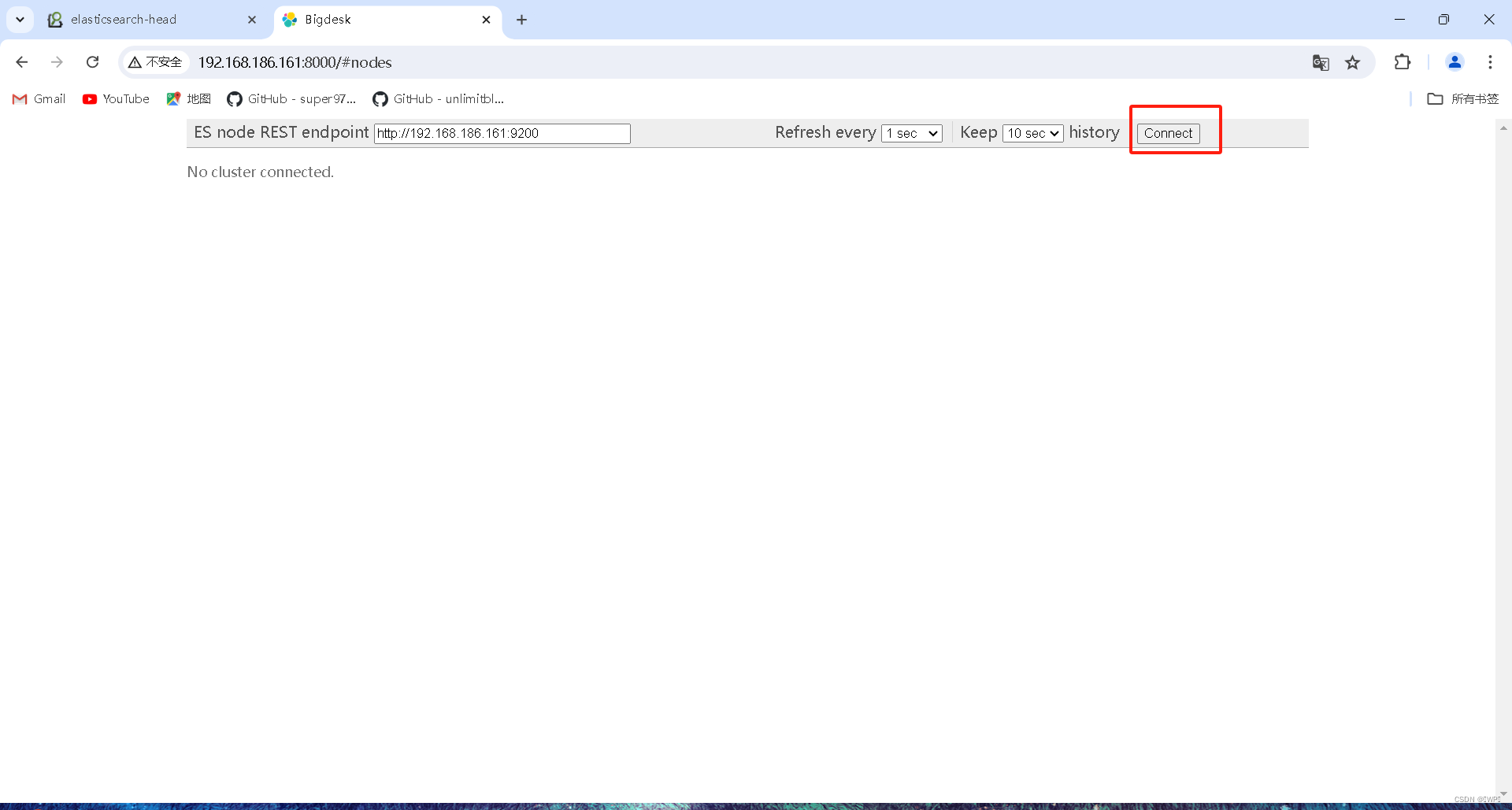
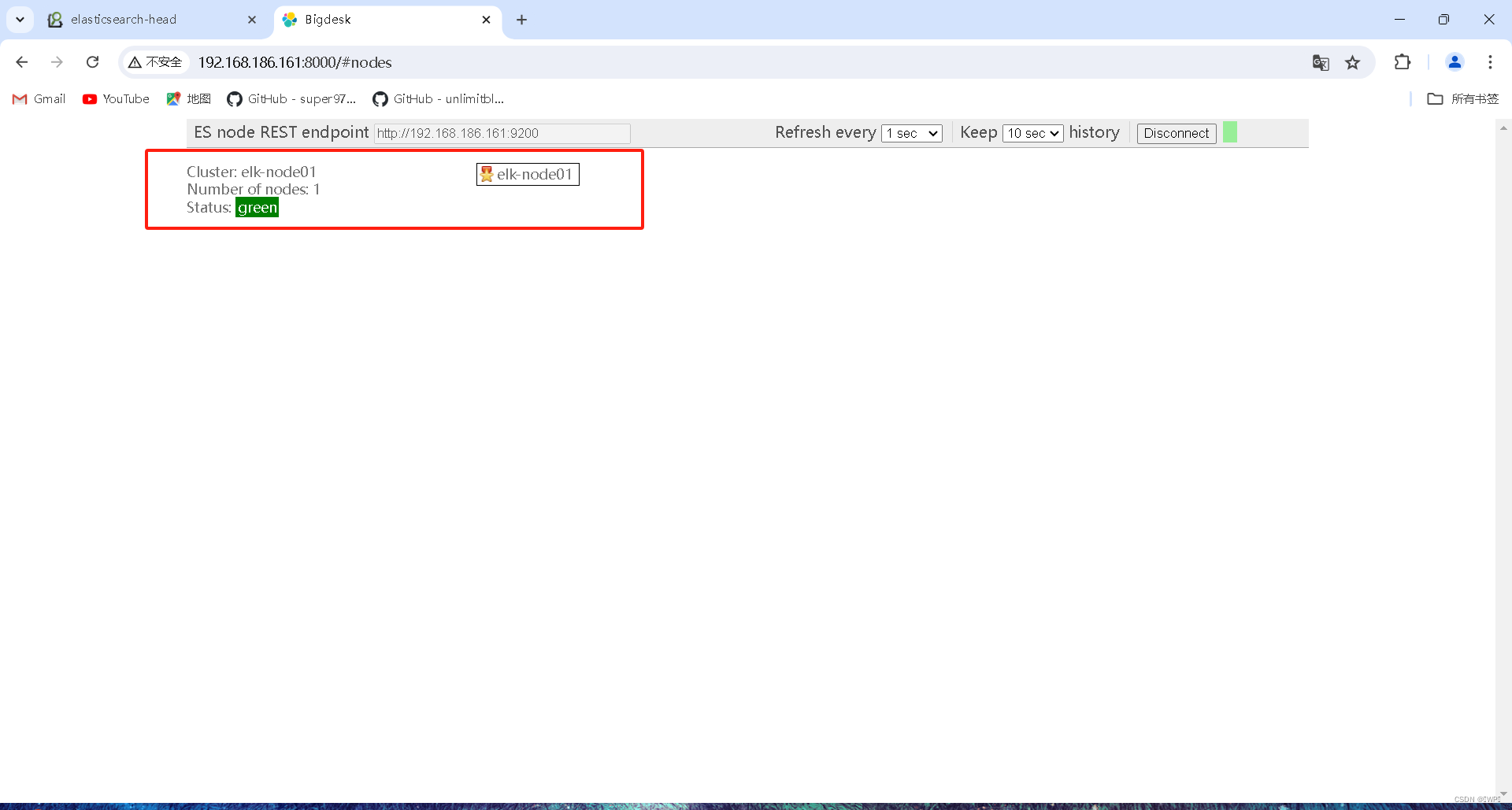
安装cerebro插件
1>下载cerebro插件:
git 项目: https://github.com/lmenezes/cerebro/releases# wget https://github.com/lmenezes/cerebro/releases/download/v0.8.3/cerebro- 0.8.3.tgz
2>上传到安装目录、解压:
# tar xf cerebro-0.8.3.tgz -C /var/lib/elasticsearch
# ln -s /var/lib/elasticsearch/cerebro-0.8.3 /var/lib/elasticsearch/cerebro
3>启动cerebro
# cd /var/lib/elasticsearch/cerebro
# nohup ./bin/cerebro &
/etc/rc.d/rc.local 添加以下内容:cd /var/lib/elasticsearch/elasticsearch-head-master/ && /usr/bin/nohup./node_modules/grunt/bin/grunt server &cd /var/lib/elasticsearch/bigdesk/_site && /usr/bin/nohup python -m SimpleHTTPServer &cd /var/lib/elasticsearch/cerebro && /usr/bin/nohup ./bin/cerebro &chmod + x /etc/rc.d/rc.local
注意:不添加执行权限,脚本等无法执行
[root@elk-node02 ~]# grep '^[a-Z]' /etc/elasticsearch/elasticsearch.yml
node.name: elk-node02
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 192.168.186.162
node.master: false
node.data: true
node.ingest: false
node.ml: false
cluster.remote.connect: false
[root@elk-node03 ~]# grep '^[a-Z]' /etc/elasticsearch/elasticsearch.yml
node.name: elk-node03
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 192.168.186.163
node.master: false
node.data: true
node.ingest: false
node.ml: false
cluster.remote.connect: falsesystemctl restart elasticsearchsystemctl enable elasticsearch
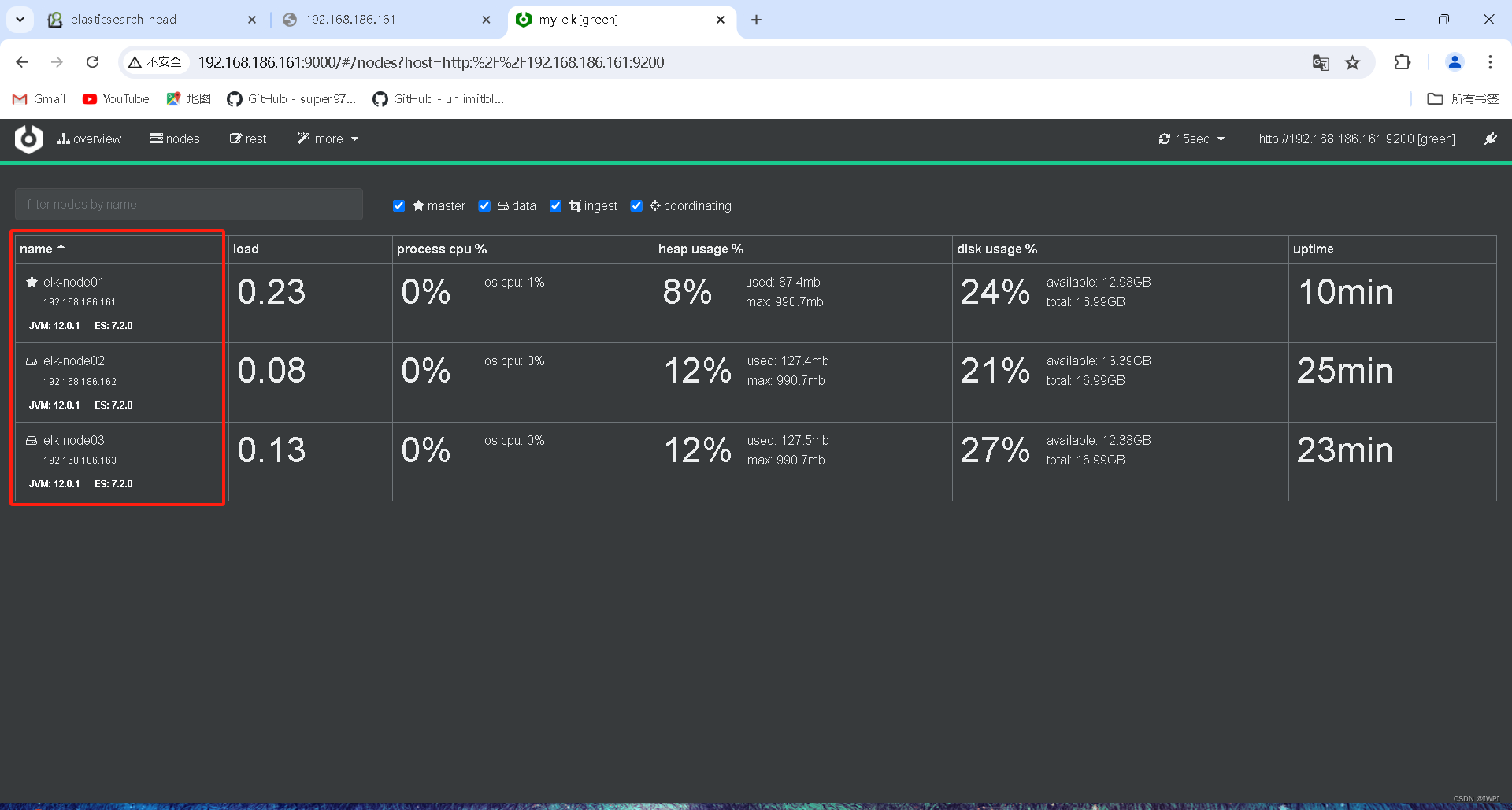
2.2.3 检查Elasticsearch集群
[root@elk-node01 cerebro]# curl -XGET '192.168.186.161:9200/_cluster/health?pretty'
{
"cluster_name" : "my-elk",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 2,
"active_primary_shards" : 0,
"active_shards" : 0,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
2>查看各个节点的信息
[root@elk-node01 cerebro]# curl -XGET '192.168.186.161:9200/_nodes/process?pretty'
{
"_nodes" : {
"total" : 3,
"successful" : 3,
"failed" : 0
},
"cluster_name" : "my-elk",
"nodes" : {
"7TbMO4r2SDWX8oty7YKwlw" : {
"name" : "elk-node03",
"transport_address" : "192.168.186.163:9300",
"host" : "192.168.186.163",
"ip" : "192.168.186.163",
"version" : "7.2.0",
"build_flavor" : "default",
"build_type" : "rpm",
"build_hash" : "508c38a",
"roles" : [
"data"
],
"attributes" : {
"xpack.installed" : "true"
},
"process" : {
"refresh_interval_in_millis" : 1000,
"id" : 1029,
"mlockall" : false
}
},
"Q02otdo6TlSm4i3paqcxlA" : {
"name" : "elk-node01",
"transport_address" : "192.168.186.161:9300",
"host" : "192.168.186.161",
"ip" : "192.168.186.161",
"version" : "7.2.0",
"build_flavor" : "default",
"build_type" : "rpm",
"build_hash" : "508c38a",
"roles" : [
"master"
],
"attributes" : {
"xpack.installed" : "true"
},
"process" : {
"refresh_interval_in_millis" : 1000,
"id" : 41349,
"mlockall" : false
}
},
"76e52HahTWOLCv5daqpQ0Q" : {
"name" : "elk-node02",
"transport_address" : "192.168.186.162:9300",
"host" : "192.168.186.162",
"ip" : "192.168.186.162",
"version" : "7.2.0",
"build_flavor" : "default",
"build_type" : "rpm",
"build_hash" : "508c38a",
"roles" : [
"data"
],
"attributes" : {
"xpack.installed" : "true"
},
"process" : {
"refresh_interval_in_millis" : 1000,
"id" : 964,
"mlockall" : false
}
}
}
}
3>查看单个节点信息
[root@elk-node01 cerebro]# curl -XGET '192.168.186.162:9200/'
{
"name" : "elk-node02",
"cluster_name" : "my-elk",
"cluster_uuid" : "mDzG-BFlToOZfFALXi2epQ",
"version" : {
"number" : "7.2.0",
"build_flavor" : "default",
"build_type" : "rpm",
"build_hash" : "508c38a",
"build_date" : "2019-06-20T15:54:18.811730Z",
"build_snapshot" : false,
"lucene_version" : "8.0.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
4> 插件查看

Bigdesk插件

cerebro插件

2.3 部署Redis+Keepalived高可用环境
[root@elk-node01 ~] # yum install redis# vim /etc/redis.conf...bind 0 .0.0.0daemonize yesappendonly yes[root@elk-node01 ~] # systemctl restart redis[root@elk-node01 ~] # systemctl enable redis从 redis 比主配置多一行:slaveof 192 .168..186.161 6379
# yum install -y keepalived
1>主节点配置
[root@elk-node01 ~]# vim /etc/keepalived/keepalived.conf
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id redis-slave
vrrp_skip_check_adv_addr
vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_script chk_redis {
script "killall -0 redis-server"
interval 2
timeout 2
fall 3
}vrrp_instance redis {
state BACKUP
interface ens33
lvs_sync_daemon_interface ens33
virtual_router_id 202
priority 150
nopreempt
advert_int 1authentication {
auth_type PASS
auth_pass 1111
}virtual_ipaddress {
192.168.186.100
}track_script {
chk_redis
}notify_master "/etc/keepalived/scripts/redis_master.sh 127.0.0.1 192.168.186.162 6379"
notify_backup "/etc/keepalived/scripts/redis_backup.sh 127.0.0.1 192.168.186.162 6379"
notify_fault /etc/keepalived/scripts/redis_fault.sh
notify_stop /etc/keepalived/scripts/redis_stop.sh
}注意:主从节点需要安装 psmisc( 提供 killall 命令 )
2>从节点配置
[root@elk-node02~]# vim /etc/keepalived/keepalived.conf
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id redis-slave
vrrp_skip_check_adv_addr
vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}vrrp_instance redis {
state BCAKUP
interface ens33
lvs_sync_daemon_interface ens33
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.186.100
}
track_script {
chk_redis
}notify_master "/etc/keepalived/scripts/redis_master.sh 127.0.0.1 192.168.186.161 6379"
notify_backup "/etc/keepalived/scripts/redis_backup.sh 127.0.0.1 192.168.186.161 6379"
notify_fault /etc/keepalived/scripts/redis_fault.sh
notify_stop /etc/keepalived/scripts/redis_stop.sh
}
# cat redis_master.sh#!/bin/bashREDISCLI = "redis-cli -h $1 -p $3 "LOGFILE = "/var/log/keepalived-redis-state.log"echo "[master]" >> $LOGFILEdate >> $LOGFILEecho "Being master...." >> $LOGFILE 2 >&1echo "Run SLAVEOF cmd ... " >> $LOGFILE$REDISCLI SLAVEOF $2 $3 >> $LOGFILE 2 >&1echo "SLAVEOF $2 cmd can't excute ... " >> $LOGFILEsleep 10echo "Run SLAVEOF NO ONE cmd ..." >> $LOGFILE$REDISCLI SLAVEOF NO ONE >> $LOGFILE 2 >&1# cat redis_backup.sh#!/bin/bashREDISCLI = "redis-cli"LOGFILE = "/var/log/keepalived-redis-state.log"echo "[BACKUP]" >> $LOGFILEdate >> $LOGFILEecho "Being slave...." >> $LOGFILE 2 >&1echo "Run SLAVEOF cmd ..." >> $LOGFILE 2 >&1$REDISCLI SLAVEOF $2 $3 >> $LOGFILEsleep 100exit 0# cat redis_fault.sh#!/bin/bashLOGFILE = "/var/log/keepalived-redis-state.log"echo "[fault]" >> $LOGFILEdate >> $LOGFILE# cat redis_stop.sh#!/bin/bashLOGFILE = "/var/log/keepalived-redis-state.log"echo "[stop]" >> $LOGFILEdate >> $LOGFILE
3>主从节点启动服务
# systemctl restart keepalived.service# systemctl enable keepalived.service
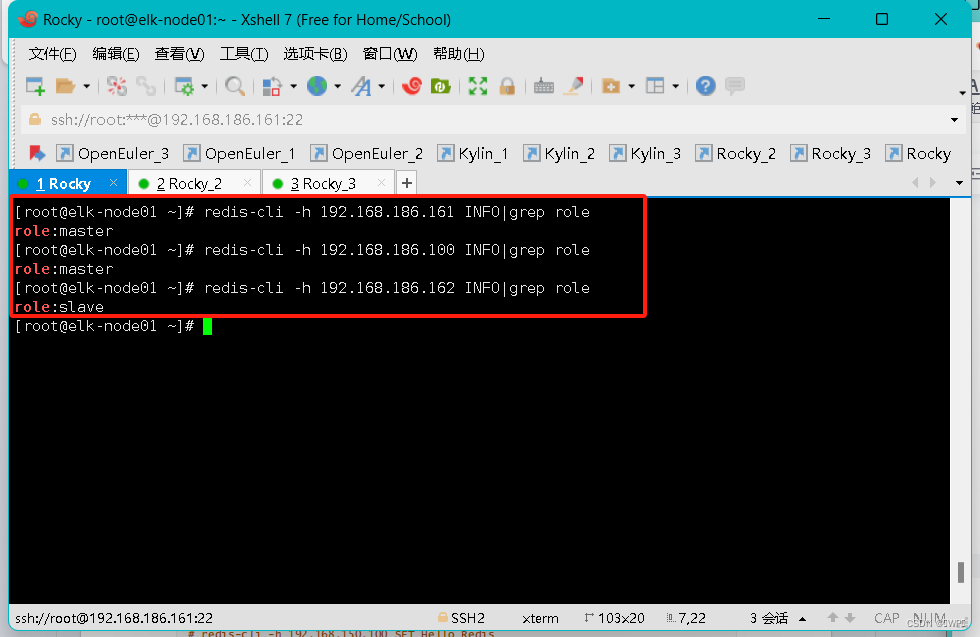
[root@elk-node01 ~]# redis-cli -h 192.168.186.161 INFO|grep role
role:master
[root@elk-node01 ~]# redis-cli -h 192.168.186.162 INFO|grep role
role:slave
[root@elk-node01 ~]# redis-cli -h 192.168.186.100 INFO|grep role
role:master
2>插入数据测试:
[root@elk-node01 ~]# redis-cli -h 192.168.186.100 SET Hello Redis
OK
[root@elk-node01 ~]# redis-cli -h 192.168.186.100 GET Hello
"Redis"
[root@elk-node01 ~]# redis-cli -h 192.168.186.161 GET Hello
"Redis"
[root@elk-node02 ~]# systemctl stop redi
[root@elk-node01 ~]# redis-cli -h 192.168.186.100 INFO|grep role
role:master
[root@elk-node01 ~]# redis-cli -h 192.168.186.161 INFO|grep role
role:master
[root@elk-node01 ~]# redis-cli -h 192.168.186.162 INFO|grep role
Could not connect to Redis at 192.168.186.162:6379: Connection refused
2.4 部署Kibana及nginx代理访问环境
[root@elk-node03 ~]# wget https://artifacts.elastic.co/downloads/kibana/kibana-7.2.0-x86_64.rpm[root@elk-node03 ~] # yum install kibana-7.2.0-x86_64.rpm
[root@elk-node03 ~]# vim /etc/cw-5601-kibana/kibana.ymlserver.port: 5601server.host: "0.0.0.0"
kibana.index: ".cw-kibana"
elasticsearch.hosts: ["http://192.168.186.161:9200"]
# Kibana is served by a back end server. This setting specifies the port to use.
server.port: 5602server.host: "0.0.0.0"
kibana.index: ".zl-kibana"elasticsearch.hosts: ["http://192.168.186.161:9200"][root@elk-node03 ~]# egrep -v "#|^$" /etc/cw-5601-kibana/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://192.168.186.161:9200"]
kibana.index: ".cw-kibana"
[root@elk-node03 ~]# egrep -v "#|^$" /etc/zl-5602-kibana/kibana.yml
server.port: 5602
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://192.168.186.161:9200"]
kibana.index: ".zl-kibana"
提供服务脚本:
[root@elk-node03 ~]# cp -a /etc/systemd/system/kibana.service /etc/systemd/system/kibana_cw.service
[root@elk-node03 ~]# vim /etc/systemd/system/kibana_cw.service
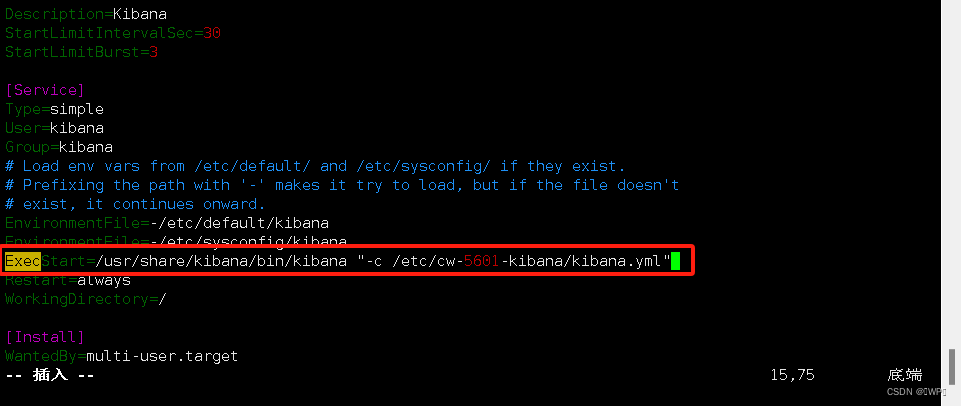
[root@elk-node03 ~]# cp -a /etc/systemd/system/kibana.service /etc/systemd/system/kibana_zl.service
[root@elk-node03 ~]# vim /etc/systemd/system/kibana_zl.service

启动服务:
systemctl daemon-reloadsystemctl start kibana_cw.service kibana_zl.servicesystemctl enable kibana_cw.service kibana_zl.service
查看:
[root@elk-node03 ~]# lsof -i :5601
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
node 11604 kibana 18u IPv4 185896 0t0 TCP *:esmagent (LISTEN)
[root@elk-node03 ~]# lsof -i :5602
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
node 11605 kibana 18u IPv4 186696 0t0 TCP *:a1-msc (LISTEN)
配置nginx的反向代理以及访问验证
# wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
# yum install nginx -y
配置虚拟主机:
[root@elk-node03 ~]# cat /etc/nginx/conf.d/cw_kibana.conf
server {
listen 15601;
server_name localhost;location / {
proxy_pass http://192.168.186.163:5601/;
auth_basic "Access Authorized";
auth_basic_user_file /etc/nginx/conf.d/cw_auth_password;
}
}
配置虚拟主机:
[root@elk-node03 ~]# cat /etc/nginx/conf.d/zl_kibana.conf
server {
isten 15602;
server_name localhost;location / {
proxy_pass http://192.168.186.163:5602/;
auth_basic "Access Authorized";
auth_basic_user_file /etc/nginx/conf.d/zl_auth_password;
}
}
设置验证文件
[root@elk-node03 ~]# htpasswd -c /etc/nginx/conf.d/cw_auth_password cwlog
New password:
Re-type new password:
Adding password for user cwlog[root@elk-node03 ~]# htpasswd -c /etc/nginx/conf.d/zl_auth_password zllog
New password:
Re-type new password:
Adding password for user zllog
启动nginx:
[root@elk-node03 ~]# nginx -t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
[root@elk-node03 ~]# systemctl restart nginx
[root@elk-node03 ~]# systemctl enable nginx
Created symlink /etc/systemd/system/multi-user.target.wants/nginx.service → /usr/lib/systemd/system/nginx.service.
2、查看


三、ELK日志收集
3.1 客户机日志收集操作(Logstash)
3.1.1 logstash 介绍
Shipper :发送事件( events )至 LogStash ;通常,远程代理端( agent )只需要运行这个组件即可;Broker and Indexer :接收并索引化事件;Search and Storage :允许对事件进行搜索和存储;Web Interface :基于 Web 的展示界面
代理主机(agent host ):作为事件的传递者( shipper ),将各种日志数据发送至中心主机;只需运 行Logstash 代理( agent )程序;中心主机(central host ):可运行包括中间转发器( Broker )、索引器( Indexer )、搜索和存储器(Search and Storage )、 Web 界面端( Web Interface )在内的各个组件,以实现对日志数据的接收、处理和存储。
3.1.2 安装logstash
# yum install jdk-8u144-linux-x64.rpm# yum install logstash-7.2.0.rpm
[root@elk-node03 ~]# mkdir -p /usr/share/logstash/{etc,config,logs}
[root@elk-node03 ~]# cp /etc/logstash/log4j2.properties /usr/share/logstash/config/
[root@elk-node03 ~]# cp /etc/logstash/logstash.yml /usr/share/logstash/config/
[root@elk-node03 ~]# ln -sv /usr/share/logstash/bin/logstash /usr/bin/logstash
'/usr/bin/logstash' -> '/usr/share/logstash/bin/logstash'
# logstash -e 'input { stdin { } } output { stdout {} }'hello world
{
"host" => "elk-node03",
"@version" => "1",
"message" => "hello world",
"@timestamp" => 2024-07-02T06:32:51.307Z
}
将屏幕输入的字符串输出到elasticsearch服务中
[root@elk-node03 ~]# logstash -e 'input { stdin{} } output { elasticsearch { hosts =>
> ["192.168.186.161:9200"] }}'
输入:hello stash,然后在elasticsearch中查看logstash新加的索引
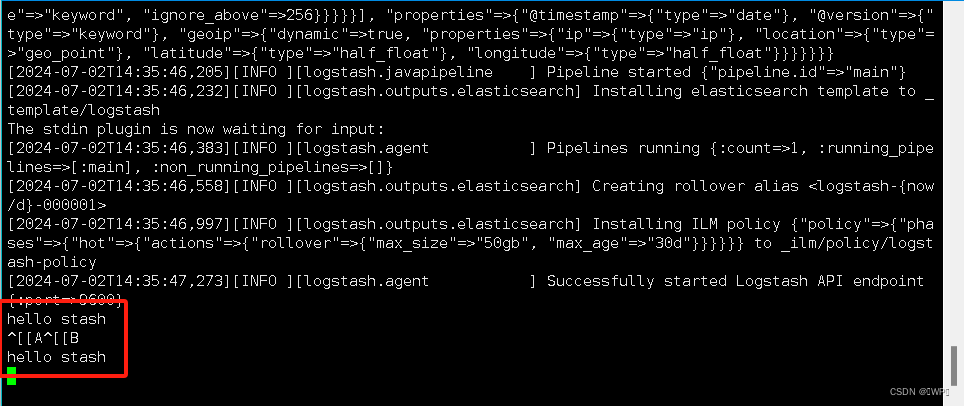
 LogStash启动慢解决:
LogStash启动慢解决:
[root@elk-node03 ~]# cat /proc/sys/kernel/random/entropy_avail
3521
# yum install http://rpmfind.net/linux/epel/7/x86_64/Packages/h/haveged-1.9.1-1.el7.x86_64.rpm[root@localhost ~] # systemctl start haveged[root@localhost ~] # systemctl status haveged
3.1.3 logStash配置语法

Logstash 用 {} 来定义区域。 区域内可以包括插件区域定义, 你可以在一个区域内定义多个插件。
input {stdin {}syslog {}}
数据类型
Logstash 支持少量的数据值类型:
bool : debug = > truestring : host = > "hostname"number : port = > 514array : match = > [ "datetime" , "UNIX" , "ISO8601" ]hash : options = > {key1 = > "value1" ,key2 = > "value2" }
表达式支持下面这些操作符:
== ( 等于 ), != ( 不等于 ), < ( 小于 ), > ( 大于 ), <= ( 小于等于 ), >= ( 大于等于 )=~ ( 匹配正则 ), !~ ( 不匹配正则)in ( 包含 ), not in ( 不包含 )and ( 与 ), or ( 或 ), nand( 非与 ), xor( 非或 )() ( 复合表达式 ), !() ( 对复合表达式结果取反 )
命令行参数
Logstash 提供了一个 shell 脚本叫 logstash 方便快速运行。 它支持以下参数: -e ,即执行--config 或 -f ,意即文件--configtest 或 -t ,意即测试--log 或 -l ,意即日志。
设置文件
从 Logstash 5.0 开始, 新增了 $LS_HOME/config/logstash.yml 文件, 可以将所有的命令行参数都通过 YAML 文件方式设置。 同时为了反映命令行配置参数的层级关系, 参数也都改成用:而不是-了。
3.1.4 logstash插件
input {file {path = > "/var/log/messages"type = > "syslog"}file {path = > "/var/log/apache/access.log"type = > "apache"}}收集文件的方式,可以使用数组方式或者用 * 匹配,也可以写多个 pathpath = > [ "/var/log/messages" , "/var/log/*.log" ]path = > [ "/data/mysql/mysql.log" ]
input {file {path = > [ "/var/log/*.log" , "/var/log/message" ]type = > "system"start_position = > "beginning"}}output 的 file 插件output {file {path = > ...codec = > line { format = > "custom format: %{message}" }}}
3.2 客户机日志收集操作(Filebeat)
Beats 是用于单用途数据托运人的平台。它们以轻量级代理的形式安装,并将来自成百上千台机器的数据发送到Logstash 或 Elasticsearch 。通俗地理解,就是采集数据,并上报到 Logstash 或 ElasticsearchBeats 对于收集数据非常有用。它们位于你的服务器上,将数据集中在 Elasticsearch 中, Beats 也可以发送到Logstash 来进行转换和解析。
3.2.1 安装 Filebeat
# yum install filebeat-7.2.0-x86_64.rpm
3.2.2 配置 Filebeat
inputs 支持的 type 有:logsdtinredisudptcpsyslogoutputs 支持的类型有:logstashelasticsearchkafkafileredisconsole
场景1:输入为file,输出为console
[root@Filebeat filebeat]# vim file_console.yml
#============ Filebeat inputs ====================
filebeat.inputs:## 配置多个input
- type: log
enabled: true
paths:
## 配置多个log
- /tmp/echo1.log
- /tmp/echo2.log
- type: log
paths:
## 通配符
- /opt/*.log
#================ Console output ================
output.console:
pretty: true
测试:
[root@localhost filebeat]# filebeat -e -c file_console.yml
打开另一终端:给测试文件追加内容[root@localhost filebeat] # echo hello >> /tmp/echo1.log{
"@timestamp": "2024-07-02T07:17:05.552Z",
"@metadata": {
"beat": "filebeat",
"type": "_doc",
"version": "7.4.0"
},
"log": {
"offset": 6,
"file": {
"path": "/tmp/echo1.log"
}
},
"message": "hello",
"input": {
"type": "log"
},
"ecs": {
"version": "1.1.0"
},
"host": {
"name": "Filebeat"
},
"agent": {
"ephemeral_id": "1d365811-2178-4742-b26a-28307dad2bcc",
"hostname": "Filebeat",
"id": "88c4bee9-c823-406d-9341-3470ee4c6df6",
"version": "7.4.0",
"type": "filebeat"
}
}
场景2:输出为file
[root@Filebeat filebeat]# cat file_file.yml
filebeat.inputs:- type: log
enabled: true
paths:
- /tmp/echo1.logoutput.file:
path: /home/logstash/filename: filebeat_file_2_file_out
测试:
[root@localhost filebeat] # filebeat -e -c file_file.yml打开另一终端:给测试文件追加内容[root@localhost filebeat] # echo hello2 >> /tmp/echo1.log运行两次后查看:[root@Filebeat filebeat]# ll /home/logstash/
总用量 8
-rw------- 1 root root 420 7月 2 16:08 filebeat_file_2_file_out
-rw------- 1 root root 420 7月 2 15:21 filebeat_file_2_file_out.1
 场景3:输出为logstash
场景3:输出为logstash
[root@Filebeat filebeat]# cat file_logstash.yml
filebeat.inputs:- type: log
enabled: true
paths:
- /tmp/echo1.logoutput.logstash:
hosts: ["127.0.0.1:5054"]
logstash配置
[root@elk-node03 conf.d]# cat filebeat_in.conf
input {
beats {
port => 5054
}
}
output {
stdout {}
}
测试:三个终端
一个开启 filebeat : [root@localhost filebeat]# filebeat -e -c file_logstash.yml一个开启 logstash : [root@localhost conf.d]# logstash -f filebeat_in.conf另一个追加数据: # echo hello5 >> /tmp/echo1.log
{"message" = > "hello5" ,"ecs" = > {"version" = > "1.0.0"...},"input" = > {"type" = > "log"}}
场景4:输出为elasticsearch
[root@Filebeat filebeat]# cat file_elasticsearch.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /tmp/echo1.logoutput.elasticsearch:
hosts: ["192.168.186.161:9200","192.168.186.162:9200","192.168.186.163:9200"]
测试:
[root@localhost filebeat]# filebeat -e -c file_elasticsearch.yml
[root@localhost filebeat] # echo hello6 >> /tmp/echo1.log
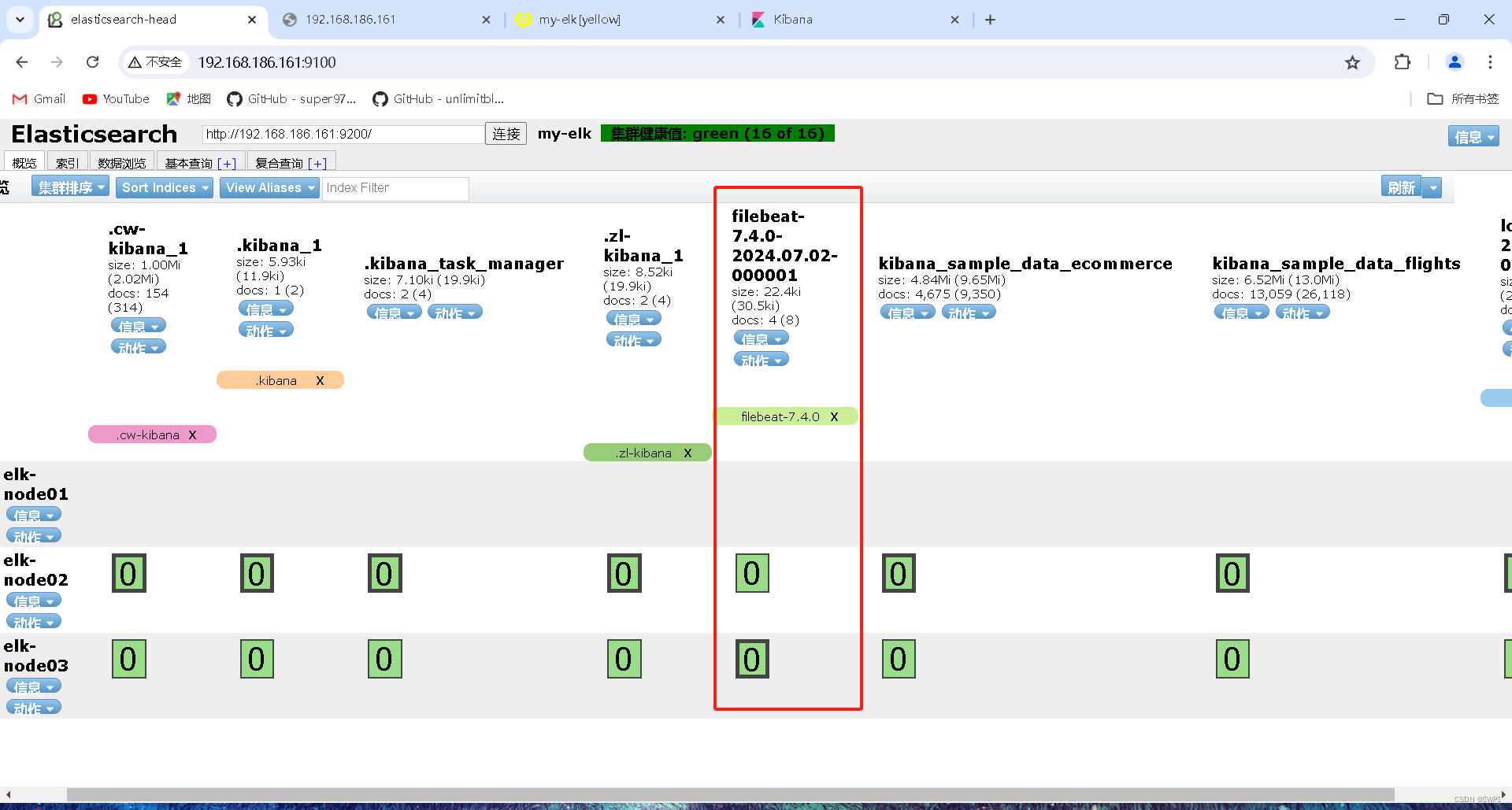 默认索引是:filebeat-
默认索引是:filebeat-
[root@Filebeat filebeat]# cat file_elasticsearch2.yml
setup.template.enabled: false
setup.template.name: 'demo_index'
setup.template.pattern: 'demo_index-*'
setup.ilm.rollover_alias: 'demo_index'
setup.template.overwrite: true
filebeat.inputs:- type: log
enabled: true
paths:
- /tmp/echo1.log
output.elasticsearch:
hosts: ["192.168.186.161:9200","192.168.186.162:9200","192.168.186.163:9200"]
index: "demo_index--%{[beat.version]}-%{+yyyy.MM}"



![[方法] 为Cinemachine添加碰撞器](https://img-blog.csdnimg.cn/direct/e4ab82a606ca4196b17a3dc7c77395f3.png)


![[激光原理与应用-96]:激光器研发与生产所要的常见设备(大全)与仪器(图解)](https://img-blog.csdnimg.cn/direct/8eb190c6f7594c50b437629dcfaa3158.png)