自学python如何成为大佬(目录):https://blog.csdn.net/weixin_67859959/article/details/139049996?spm=1001.2014.3001.5501
语法参考
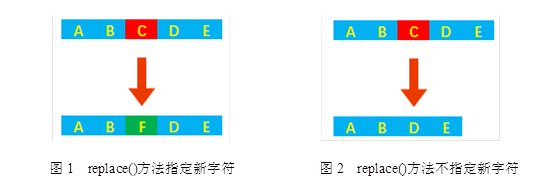
replace()方法用于将某一字符串中一部分字符替换为指定的新字符,如果不指定新字符,那么原字符将被直接去除,例如图1和图2所示的效果。
replace()方法的语法格式如下:
str.replace(old [, new [, count]])
l old:将被替换的子字符串。
l new:字符串,用于替换old子字符串。
l count:可选参数,表示要替换的次数,如果不指定该参数则替换所有匹配字符,而指定替换次数时的替换顺序是从左向右依次替换。
快用锦囊
锦囊1 替换字符串中指定的字符
使用replace()函数将字符串“www.risoft.com”中的“soft”替换为“book”,代码如下:
str1 = 'www.risoft.com'
print (str1.replace('soft', 'book'))
运行程序,输出结果为:
www.ribook.com
锦囊2 去除大段文本中的标点字符
经常在网上查阅资料,有时复制的网页内容中会夹杂一些乱七八糟的标点字符,如#、$、%、&、'、(、)、*、+、,等,那么此时可以使用replace()方法将这些标点字符去除,实际上就是将它们替换为空,代码如下:
import string
f = open('./tmp/test3.txt', 'r')
s=f.read()
for c in string.punctuation:
s=s.replace(c,'')
print(s)
上述代码中用到了string模块,该模块的punctuation属性包含了所有的标点字符。
运行程序,去除标点字符前后的效果如图3和图4所示

图3 原文

图4 去除标点字符后的效果
锦囊3 去除大段文本中的数字
当文本中存在一些无用的数字时,也可以使用replace()方法并结合string模块digits属性将这些数字去除,代码如下:
import string
f = open('./tmp/test4.txt', 'r')
s=f.read()
for c in string.digits:
s=s.replace(c,'')
print(s)
运行程序,去除标点字符前后的效果如图5和图6所示

图5 原文

图6 去除数字后的效果
锦囊4 身份证号中的重要数字用星号代替
身份证号或手机号等重要的数据不能随意传递,可以把其中的几个重要数字用星号代替,以起到保护隐私的作用,如图7所示。
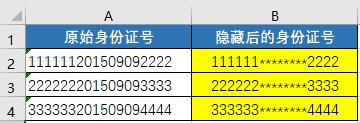
图7 身份证号中的重要数字用星号代替
说明:图中数据为随意编造做演示用,无具体含义。
下面使用replace()方法将身份证号中间8位替换为星号“*”,代码如下:
str1 = '333333201501012222'
s1=str1[6:14]
print (str1.replace(s1, '********'))
运行程序,输出结果为:
333333********2222
使用此方法还可以替换姓名、手机号等涉及隐私的内容。
锦囊5 仅显示字符串中的字母与数字
在一些应用软件中,经常会遇到要求用户仅输入字母和数字的情况。下面使用replace()方法对输入的内容自动过滤仅显示字符串中的字母和数字。例如,输入车号“888-吉A-UA561”将自动过滤汉字和特殊符号,仅显示“888AUA561”,代码如下:
str1=input('请输入车号:')
str2 = str1.lower(); #将大写字母转换为小写字母
temp= 'abcdefghijklmnopqrstuvwxyz0123456789'
for c in str2:
if not c in temp:
str1 = str1.replace(c,'');
print(str1)
运行程序,输出结果为:
请输入车号:888-吉A-UA561
888AUA561
锦囊6 删除任意位置的相同的字符
删除任意位置的相同的字符。例如,字符串中有多处包含了“\t”,下面使用replace()方法将所有“\t”删除,代码如下:
# 去除字符串中相同的字符
s = '\tmrsoft\t888\tbook'
print(s.replace('\t',''))
运行程序,输出结果为:
mrsoft888book
锦囊7 通过多次使用replace()方法删除多种特殊符号
通过多次使用replace()方法,将文本中的特殊字符,如“/”、“_”和“*”等删除,代码如下:
temp ='想做/ 兼_职/程序员_/ 的加我Q: 400*765@1066有,惊,喜,哦!!'
print(temp.replace(' ','').replace("*",'').replace('_','').replace('、','').replace('/','').replace(',',''))
运行程序,输出结果为:
想做兼职程序员的加我Q:400765@1066有惊喜哦!!
锦囊8 Python爬取文本用replace()方法替换p标签
通过Python爬取了“百度知道”中全国985院校有哪些的相关内容,但是文本中存在大量的p标签,例如,“<p>1. 清华大学(北京)</p><p>2. 北京大学(北京)</p><p>……”。下面使用replace()方法将标签“<p>”,将标签“</p>”替换成换行符“\n”,代码如下:
f = open('./tmp/text.txt', 'r') #打开文本
s=f.read()
s=s.replace('<p>','').replace('</p>','\n') #替换p标签
print(s,end='') #输出去掉空行
运行程序,处理前后的效果如图8、图9所示


![[图解]企业应用架构模式2024新译本讲解19-数据映射器1](https://img-blog.csdnimg.cn/direct/05e3e288c26f449382203e8ef47f3e68.png)