有时候我们会发现系统中某个进程会突然挂掉,通过查看系统日志发现是由于 OOM机制 导致进程被杀掉。
今天我们就来介绍一下什么是 OOM机制 以及怎么防止进程因为 OOM机制 而被杀掉。
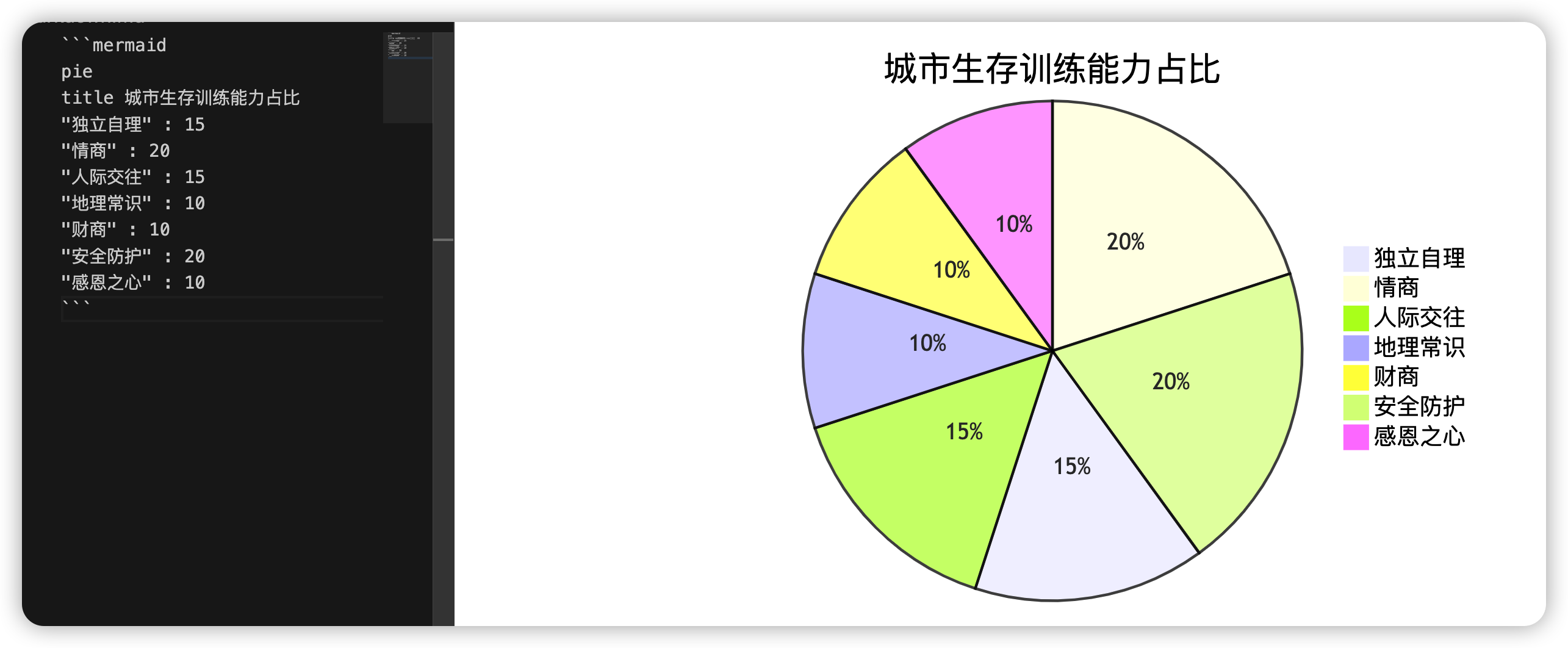
什么是OOM机制
OOM 是 Out Of Memory 的缩写,中文意思是内存不足。而 OOM机制 是指当系统内存不足时,系统触发的应急机制。
当 Linux 内核发现系统中的物理内存不足时,首先会对系统中的可回收内存进行回收,能够被回收的内存有如下:
- 读写文件时的页缓存。
- 为了性能而延迟释放的空闲 slab 内存页。
当系统内存不足时,内核会优先释放这些内存页。因为使用这些内存页只是为了提升系统的性能,释放这些内存页也不会影响系统的正常运行。
如果释放上述的内存后,还不能解决内存不足的情况,那么内核会如何处理呢?答案就是:触发 OOM killer 杀掉系统中占用内存最大的进程。如下图所示:
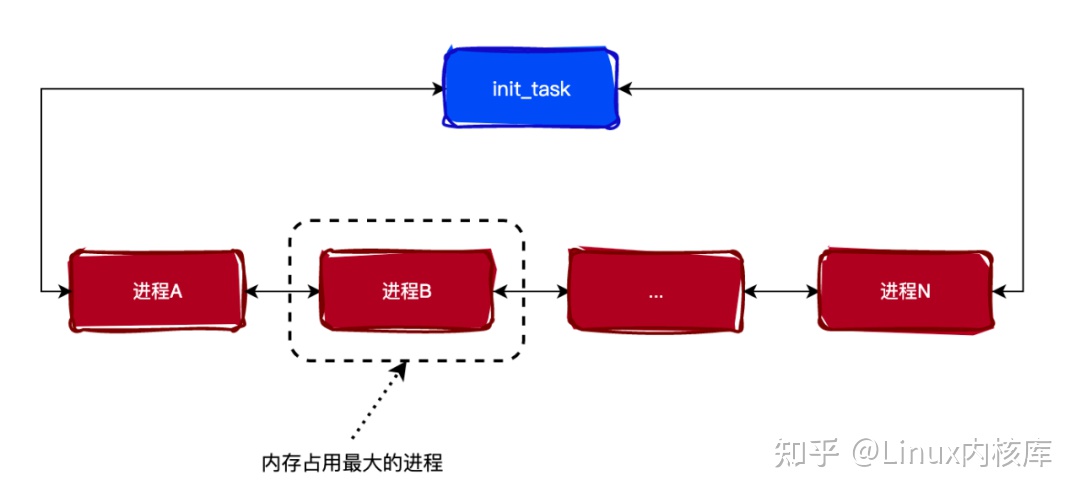
可以看出,OOM killer 是防止系统崩溃的最后一个手段,不到迫不得已的情况是不会触发的。
资料直通车:Linux内核源码技术学习路线+视频教程内核源码
学习直通车:Linux内核源码内存调优文件系统进程管理设备驱动/网络协议栈
OOM killer 实现
接下来,我们分析一下内核是如何实现 OOM killer 的。
由于在 Linux 系统中,进程申请的都是虚拟内存地址。所以当程序调用 malloc() 申请内存时,如果虚拟内存空间足够的话,是不会触发 OOM 机制的。
当进程访问虚拟内存地址时,如果此虚拟内存地址还没有映射到物理内存地址的话,那么将会触发 缺页异常。
在缺页异常处理例程中,将会申请新的物理内存页,并且将进程的虚拟内存地址映射到刚申请的物理内存。
如果在申请物理内存时,系统中的物理内存不足,那么内核将会回收一些能够被回收的文件页缓存。如果回收完后,物理内存还是不足的话,那么将会触发 swapping机制(如果开启了的话)。
swapping机制 会将某些进程不常用的内存页写入到交换区(硬盘分区或文件)中,然后释放掉这些内存页,从而达到缓解内存不足的情况。
如果通过上面的手段还不能解决内存不足的情况,那么内核将会调用 pagefault_out_of_memory() 函数来杀掉系统中占用物理内存最多的进程。
我们来看看 pagefault_out_of_memory() 函数的实现:
void pagefault_out_of_memory(void)
{
...
out_of_memory(NULL, 0, 0, NULL, false);
...
}可以看出,pagefault_out_of_memory() 函数最终会调用 out_of_memory() 来杀死系统中占用内存最多的进程。
我们继续来看看 out_of_memory() 函数的实现:
void out_of_memory(struct zonelist *zonelist, gfp_t gfp_mask, int order,
nodemask_t *nodemask, bool force_kill)
{
...
// 1. 从系统中选择一个最坏(占用内存最多)的进程
p = select_bad_process(&points, totalpages, mpol_mask, force_kill);
...
// 2. 如果找到最坏的进程,那么调用 oom_kill_process 函数杀掉进程
if (p != (void *)-1UL) {
oom_kill_process(p, gfp_mask, order, points, totalpages, NULL,
nodemask, "Out of memory");
killed = 1;
}
...
}out_of_memory() 函数的逻辑比较简单,主要完成两个事情:
- 调用 select_bad_process() 函数从系统中选择一个最坏(占用物理内存最多)的进程。
- 如果找到最坏的进程,那么调用 oom_kill_process() 函数将此进程杀掉。
从上面的分析可知,找到最坏的进程是 OOM killer 最为重要的事情。
那么我们来看看 select_bad_process() 函数是怎样选择最坏的进程的:
static struct task_struct *
select_bad_process(unsigned int *ppoints, unsigned long totalpages,
const nodemask_t *nodemask, bool force_kill)
{
struct task_struct *g, *p;
struct task_struct *chosen = NULL;
unsigned long chosen_points = 0;
...
// 1. 遍历系统中所有的进程和线程
for_each_process_thread(g, p) {
unsigned int points;
...
// 2. 计算进程最坏分数值, 选择分数最大的进程作为杀掉的目标进程
points = oom_badness(p, NULL, nodemask, totalpages);
if (!points || points < chosen_points)
continue;
...
chosen = p;
chosen_points = points;
}
...
return chosen;
}select_bad_process() 函数的主要工作如下:
- 遍历系统中所有的进程和线程,并且调用 oom_badness() 函数计算进程的最坏分数值。
- 选择最坏分数值最大的进程作为被杀掉的目标进程。
所以,计算进程的最坏分数值就是 OOM killer 的核心工作。我们接着来看看 oom_badness() 函数是怎么计算进程的最坏分数值的:
unsigned long
oom_badness(struct task_struct *p, struct mem_cgroup *memcg,
const nodemask_t *nodemask, unsigned long totalpages)
{
long points;
long adj;
// 1. 如果进程不能被杀掉(init进程和内核进程是不能被杀的)
if (oom_unkillable_task(p, memcg, nodemask))
return 0;
...
// 2. 我们可以通过 /proc/{pid}/oom_score_adj 文件来设置进程的被杀建议值,
// 这个值越小,进程被杀的机会越低。如果设置为 -1000 时,进程将被禁止杀掉。
adj = (long)p->signal->oom_score_adj;
if (adj == OOM_SCORE_ADJ_MIN) {
...
return 0;
}
// 3. 统计进程使用的物理内存数
points = get_mm_rss(p->mm)
+ atomic_long_read(&p->mm->nr_ptes)
+ get_mm_counter(p->mm, MM_SWAPENTS);
...
// 4. 加上进程被杀建议值,得出最终的分数值
adj *= totalpages / 1000;
points += adj;
return points > 0 ? points : 1;
}oom_badness() 函数主要按照以下步骤来计算进程的最坏分数值:
- 如果进程不能被杀掉(init进程和内核进程是不能被杀的),那么返回分数值为 0。
- 可以通过 /proc/{pid}/oom_score_adj 文件来设置进程的 OOM 建议值(取值范围为 -1000 ~ 1000)。建议值越小,进程被杀的机会越低。如果将其设置为 -1000 时,进程将被禁止杀掉。
- 统计进程使用的物理内存数,包括实际使用的物理内存、页表占用的物理内存和 swap 机制占用的物理内存。
- 最后加上进程的 OOM 建议值,得出最终的分数值。
通过 oom_badness() 函数计算出进程的最坏分数值后,系统就能从中选择一个分数值最大的进程杀死,从而解决内存不足的情况。
禁止进程被 OOM 杀掉
有时候,我们不希望某些进程被 OOM killer 杀掉。例如 MySQL 进程如果被 OOM killer 杀掉的话,那么可能导致数据丢失的情况。
那么如何防止进程被 OOM killer 杀掉呢?从上面的分析可知,在内核计算进程最坏分数值时,会加上进程的 oom_score_adj(OOM建议值)值。如果将此值设置为 -1000 时,那么系统将会禁止 OOM killer 杀死此进程。
例如使用如下命令,将会禁止杀死 PID 为 2000 的进程:
$ echo -1000 > /proc/2000/oom_score_adj这样,我们就能防止一些重要的进程被 OOM killer 杀死。