ThreadPoolExecutor不多介绍,重点介绍ForkJoinPool,以及二者的区别
ForkJoinPool
ForkJoinPool 是 Java 7 引入的一种用于并行计算的框架,特别适合处理递归任务。它是 java.util.concurrent 包的一部分,基于工作窃取算法,可以充分利用多核处理器的并行能力。以下是 ForkJoinPool 的基本用法介绍。
基本概念
ForkJoinPool 基于两个核心操作:
- Fork:将任务拆分成更小的子任务并提交给线程池执行。
- Join:等待子任务完成并合并结果。
核心类
- ForkJoinPool:线程池实现,管理工作线程。
- ForkJoinTask:所有可以并行执行的任务的基类。
- RecursiveTask:用于有返回值的任务。
- RecursiveAction:用于没有返回值的任务。
示例用法
a. 计算斐波那契数列
我们来实现一个简单的斐波那契数列计算例子。
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
public class FibonacciTask extends RecursiveTask<Integer> {
private final int n;
public FibonacciTask(int n) {
this.n = n;
}
@Override
protected Integer compute() {
if (n <= 1) {
return n;
}
FibonacciTask f1 = new FibonacciTask(n - 1);
f1.fork(); // 异步执行
FibonacciTask f2 = new FibonacciTask(n - 2);
return f2.compute() + f1.join(); // 等待 f1 任务完成并获取结果
}
public static void main(String[] args) {
ForkJoinPool pool = new ForkJoinPool();
FibonacciTask task = new FibonacciTask(10);
int result = pool.invoke(task);
System.out.println("Fibonacci number is: " + result);
pool.shutdown();
}
}
b. 合并排序
下面是一个使用 ForkJoinPool 实现合并排序(Merge Sort)的例子。
import java.util.Arrays;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveAction;
public class MergeSortTask extends RecursiveAction {
private final int[] array;
private final int left;
private final int right;
public MergeSortTask(int[] array, int left, int right) {
this.array = array;
this.left = left;
this.right = right;
}
@Override
protected void compute() {
if (right - left < 2) {
return;
}
int mid = (left + right) / 2;
MergeSortTask leftTask = new MergeSortTask(array, left, mid);
MergeSortTask rightTask = new MergeSortTask(array, mid, right);
invokeAll(leftTask, rightTask);
merge(array, left, mid, right);
}
private void merge(int[] array, int left, int mid, int right) {
int[] temp = new int[right - left];
int i = left, j = mid, k = 0;
while (i < mid && j < right) {
temp[k++] = array[i] < array[j] ? array[i++] : array[j++];
}
while (i < mid) {
temp[k++] = array[i++];
}
while (j < right) {
temp[k++] = array[j++];
}
System.arraycopy(temp, 0, array, left, temp.length);
}
public static void main(String[] args) {
int[] array = {38, 27, 43, 3, 9, 82, 10};
ForkJoinPool pool = new ForkJoinPool();
MergeSortTask task = new MergeSortTask(array, 0, array.length);
pool.invoke(task);
System.out.println(Arrays.toString(array));
pool.shutdown();
}
}
使用建议
- 任务拆分的粒度:任务不宜拆分得过细,否则管理任务的开销会增加,反而降低性能。
- 异常处理:ForkJoinTask 提供了 completeExceptionally 方法来处理异常情况。
- 线程数设置:默认情况下,ForkJoinPool 会使用与处理器数量相同的线程数。你可以通过构造函数来调整线程数,例如 new ForkJoinPool(4)。
总结
ForkJoinPool 是一个强大的并行处理工具,适合用来处理需要递归分解的任务。通过合理地拆分任务和合并结果,可以充分利用多核处理器的并行能力,提高计算效率。
等待ForkJoinPool任务全部完成
要等待 ForkJoinPool 中的所有任务完成,有几种方法可供选择,具体取决于如何提交任务。以下是几种常见的方法:
1. 使用 invoke()
如果任务是通过 ForkJoinPool 的 invoke() 方法提交的,这个方法会阻塞当前线程,直到任务完成。
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
public class ForkJoinPoolExample {
static class MyRecursiveTask extends RecursiveTask<Integer> {
private final int workload;
MyRecursiveTask(int workload) {
this.workload = workload;
}
@Override
protected Integer compute() {
if (workload > 16) {
MyRecursiveTask subtask1 = new MyRecursiveTask(workload / 2);
MyRecursiveTask subtask2 = new MyRecursiveTask(workload / 2);
invokeAll(subtask1, subtask2);
return subtask1.join() + subtask2.join();
} else {
return workload;
}
}
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
MyRecursiveTask task = new MyRecursiveTask(128);
int result = forkJoinPool.invoke(task); // 等待任务完成
System.out.println("Result: " + result);
}
}
2. 使用 submit() 和 join()
如果任务是通过 submit() 方法提交的,可以使用 join() 方法来等待任务完成。
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
import java.util.concurrent.ForkJoinTask;
public class ForkJoinPoolExample {
static class MyRecursiveTask extends RecursiveTask<Integer> {
private final int workload;
MyRecursiveTask(int workload) {
this.workload = workload;
}
@Override
protected Integer compute() {
if (workload > 16) {
MyRecursiveTask subtask1 = new MyRecursiveTask(workload / 2);
MyRecursiveTask subtask2 = new MyRecursiveTask(workload / 2);
invokeAll(subtask1, subtask2);
return subtask1.join() + subtask2.join();
} else {
return workload;
}
}
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
MyRecursiveTask task = new MyRecursiveTask(128);
ForkJoinTask<Integer> result = forkJoinPool.submit(task);
System.out.println("Result: " + result.join()); // 等待任务完成
}
}
3. 使用 awaitQuiescence()
如果有多个任务提交到 ForkJoinPool,可以使用 awaitQuiescence() 方法来等待线程池中的所有任务完成。
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
import java.util.concurrent.TimeUnit;
public class ForkJoinPoolExample {
static class MyRecursiveTask extends RecursiveTask<Integer> {
private final int workload;
MyRecursiveTask(int workload) {
this.workload = workload;
}
@Override
protected Integer compute() {
if (workload > 16) {
MyRecursiveTask subtask1 = new MyRecursiveTask(workload / 2);
MyRecursiveTask subtask2 = new MyRecursiveTask(workload / 2);
invokeAll(subtask1, subtask2);
return subtask1.join() + subtask2.join();
} else {
return workload;
}
}
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
forkJoinPool.submit(new MyRecursiveTask(128));
forkJoinPool.submit(new MyRecursiveTask(256));
// 等待所有任务完成
forkJoinPool.awaitQuiescence(1, TimeUnit.HOURS);
System.out.println("All tasks completed");
}
}
4. 使用 shutdown() 和 awaitTermination()
如果想要关闭 ForkJoinPool 并等待所有任务完成,可以使用 shutdown() 方法关闭线程池,然后使用 awaitTermination() 方法等待任务完成。
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
import java.util.concurrent.TimeUnit;
public class ForkJoinPoolExample {
static class MyRecursiveTask extends RecursiveTask<Integer> {
private final int workload;
MyRecursiveTask(int workload) {
this.workload = workload;
}
@Override
protected Integer compute() {
if (workload > 16) {
MyRecursiveTask subtask1 = new MyRecursiveTask(workload / 2);
MyRecursiveTask subtask2 = new MyRecursiveTask(workload / 2);
invokeAll(subtask1, subtask2);
return subtask1.join() + subtask2.join();
} else {
return workload;
}
}
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
forkJoinPool.submit(new MyRecursiveTask(128));
forkJoinPool.submit(new MyRecursiveTask(256));
// 关闭线程池并等待所有任务完成
forkJoinPool.shutdown();
try {
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
System.out.println("All tasks completed");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
总结
- invoke() 方法适用于单个任务,调用后会阻塞直到任务完成。
- submit() 方法适用于单个任务,可以结合 join() 方法来等待任务完成。
- awaitQuiescence() 方法适用于多个任务,等待线程池中的所有任务完成。
- shutdown() 和 awaitTermination() 方法适用于关闭线程池并等待所有任务完成。
根据具体需求,选择合适的方法来等待 ForkJoinPool 中的任务全部完成。
ForkJoinPool与ThreadPool区别
ForkJoinPool 和 ThreadPoolExecutor 是 Java 中用于并发编程的两个不同类型的线程池,它们各有特点和适用场景。以下是它们之间的主要区别:
基本概念与用途
- ForkJoinPool:
- 基于工作窃取算法,适用于递归分治算法。
- 主要用于并行处理递归任务,如分治算法(Divide and Conquer)中的任务。
- 任务可以拆分成更小的子任务并行执行,然后合并结果。
- ThreadPoolExecutor:
- 基于普通的线程池模型,适用于独立的并发任务。
- 主要用于执行一组独立的、可能是相互依赖的任务。
- 任务之间通常是独立的,没有必要进一步拆分。
工作机制
- ForkJoinPool:
- 使用 ForkJoinTask 类及其子类 RecursiveTask 和 RecursiveAction。
- 任务可以调用 fork() 方法将子任务提交给池执行,调用 join() 方法等待子任务完成并合并结果。
- 工作窃取算法允许线程从其他线程的工作队列中窃取任务,提高了线程利用率。
- ThreadPoolExecutor:
- 使用 Runnable 或 Callable 接口。
- 提供了多种队列类型,如 LinkedBlockingQueue、SynchronousQueue、ArrayBlockingQueue 等。
- 提供了灵活的线程池配置,包括核心线程数、最大线程数、线程存活时间等。
使用场景
- ForkJoinPool:
- 适用于需要将任务拆分为多个子任务并行执行的场景,如排序算法(归并排序、快速排序)、并行计算(矩阵乘法、图算法)等。
- 特别适合需要递归地解决问题的场景。
- ThreadPoolExecutor:
- 适用于执行一组独立任务的场景,如处理并发请求、后台任务处理、定时任务等。
- 适合长时间运行的服务器应用,需要灵活管理线程池中的线程数和任务队列。
总结
- ForkJoinPool 适用于需要递归分治的任务,采用工作窃取算法,能够高效地并行处理任务。
- ThreadPoolExecutor 适用于一组独立的并发任务,提供了灵活的线程池配置和多种任务队列选择。
根据具体的应用场景和任务特性选择合适的线程池类型,以实现高效的并发处理。
监控
要监控 ForkJoinPool 线程池,可以通过以下几种方式:
- 自定义监控代码:编写自定义的监控代码来收集 ForkJoinPool 的状态信息,并将这些信息暴露为Actuator的自定义端点。
- 使用现有的监控工具:如JMX、Prometheus等,结合Spring Boot Actuator,通过自定义的指标暴露 ForkJoinPool 的状态。
方法1:自定义监控代码
首先,需要收集 ForkJoinPool 的状态信息。可以通过 ForkJoinPool 提供的一些方法来获取线程池的状态信息,如:getPoolSize(), getActiveThreadCount(), getQueuedTaskCount(), getStealCount()等。
以下是一个简单的示例,展示如何通过自定义Actuator端点来监控 ForkJoinPool:
- 创建一个类来获取 ForkJoinPool 的状态信息:
import java.util.concurrent.ForkJoinPool;
public class ForkJoinPoolMetrics {
private final ForkJoinPool forkJoinPool;
public ForkJoinPoolMetrics(ForkJoinPool forkJoinPool) {
this.forkJoinPool = forkJoinPool;
}
public int getPoolSize() {
return forkJoinPool.getPoolSize();
}
public int getActiveThreadCount() {
return forkJoinPool.getActiveThreadCount();
}
public long getQueuedTaskCount() {
return forkJoinPool.getQueuedTaskCount();
}
public long getStealCount() {
return forkJoinPool.getStealCount();
}
}
- 创建一个自定义的Actuator端点:
import org.springframework.boot.actuate.endpoint.annotation.Endpoint;
import org.springframework.boot.actuate.endpoint.annotation.ReadOperation;
import org.springframework.stereotype.Component;
@Component
@Endpoint(id = "forkJoinPool")
public class ForkJoinPoolEndpoint {
private final ForkJoinPoolMetrics forkJoinPoolMetrics;
public ForkJoinPoolEndpoint(ForkJoinPoolMetrics forkJoinPoolMetrics) {
this.forkJoinPoolMetrics = forkJoinPoolMetrics;
}
@ReadOperation
public ForkJoinPoolMetrics forkJoinPoolMetrics() {
return this.forkJoinPoolMetrics;
}
}
- 将自定义的监控端点添加到Spring配置中:
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.concurrent.ForkJoinPool;
@Configuration
public class ForkJoinPoolConfig {
@Bean
public ForkJoinPool forkJoinPool() {
return new ForkJoinPool();
}
@Bean
public ForkJoinPoolMetrics forkJoinPoolMetrics(ForkJoinPool forkJoinPool) {
return new ForkJoinPoolMetrics(forkJoinPool);
}
}
- 运行Spring Boot应用程序,并访问自定义的Actuator端点来查看 ForkJoinPool 的状态信息:
访问 http://localhost:8080/actuator/forkJoinPool 将会返回类似于以下的JSON数据:
{
"poolSize": 4,
"activeThreadCount": 2,
"queuedTaskCount": 10,
"stealCount": 100
}
方法2:使用现有的监控工具
如果你已经在使用像Prometheus或JMX这样的监控工具,可以将 ForkJoinPool 的状态信息暴露为自定义指标,然后通过这些工具进行监控。以下是一个示例,展示如何将 ForkJoinPool 的状态信息暴露为Prometheus的自定义指标:
- 添加Prometheus依赖:
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
- 创建一个自定义的Metrics绑定类:
import io.micrometer.core.instrument.MeterRegistry;
import io.micrometer.core.instrument.binder.MeterBinder;
import org.springframework.stereotype.Component;
import java.util.concurrent.ForkJoinPool;
@Component
public class ForkJoinPoolMetricsBinder implements MeterBinder {
private final ForkJoinPool forkJoinPool;
public ForkJoinPoolMetricsBinder(ForkJoinPool forkJoinPool) {
this.forkJoinPool = forkJoinPool;
}
@Override
public void bindTo(MeterRegistry meterRegistry) {
meterRegistry.gauge("forkJoinPool.poolSize", forkJoinPool, ForkJoinPool::getPoolSize);
meterRegistry.gauge("forkJoinPool.activeThreadCount", forkJoinPool, ForkJoinPool::getActiveThreadCount);
meterRegistry.gauge("forkJoinPool.queuedTaskCount", forkJoinPool, ForkJoinPool::getQueuedTaskCount);
meterRegistry.gauge("forkJoinPool.stealCount", forkJoinPool, ForkJoinPool::getStealCount);
}
}
- 配置Prometheus端点:
management:
endpoints:
web:
exposure:
include: prometheus
prometheus:
metrics:
export:
enabled: true
- 运行Spring Boot应用程序,并访问Prometheus端点 http://localhost:8080/actuator/prometheus,即可查看 ForkJoinPool 的指标。
监控数据分析
# HELP forkJoinPool_poolSize
# TYPE forkJoinPool_poolSize gauge
forkJoinPool_poolSize 8.0
# HELP forkJoinPool_stealCount
# TYPE forkJoinPool_stealCount gauge
forkJoinPool_stealCount 78.0
# HELP forkJoinPool_activeThreadCount
# TYPE forkJoinPool_activeThreadCount gauge
forkJoinPool_activeThreadCount 1.0
# HELP forkJoinPool_queuedTaskCount
# TYPE forkJoinPool_queuedTaskCount gauge
forkJoinPool_queuedTaskCount 0.0
- forkJoinPool_poolSize (8.0):
- 线程池大小是8。这意味着ForkJoinPool可以使用最多8个并行线程。
- forkJoinPool_stealCount (78.0):
- 任务窃取数是78。这表示有78次任务从一个线程窃取到另一个线程执行,这通常是线程池负载平衡机制的表现,意味着线程池在尝试保持工作均衡。
- forkJoinPool_activeThreadCount (1.0):
- 活动线程数是1。这表示当前只有一个线程在执行任务,而其他线程可能处于空闲状态。
- forkJoinPool_queuedTaskCount (0.0):
- 队列任务数是0。这表示没有待处理的任务,所有任务都已经被处理或正在处理。
调优建议
根据上述数据,我们可以推测:
- 当前任务负载可能较低,大部分时间只有一个线程在处理任务。
- 任务窃取发生了一些,但并不算非常多。
- 没有积压的任务。
以下是一些可能的调优建议:
- 增加任务负载:
- 如果 ForkJoinPool 使用率低是因为任务量少,可以尝试增加提交的任务数量。确保有足够的任务以充分利用线程池中的线程。
- 调整线程池大小:
- 当前线程池大小是8,但只有一个线程在活动,说明线程池可能过大。如果系统资源有限,可以适当减少线程池大小,以减少资源消耗。比如将 ForkJoinPool 的并行度设为 Runtime.getRuntime().availableProcessors()。
- 任务拆分策略:
- 检查任务拆分策略(任务分解为子任务的方式)。确保任务被有效地拆分,使得并行执行可以更均衡地分配给多个线程。如果任务拆分不均衡,可能导致一些线程没有足够的工作。
- 监控和动态调整:
- 实时监控 ForkJoinPool 的工作状态,根据实际负载动态调整线程池参数。例如,如果负载突然增加,可以临时增加线程池大小。
结论
根据当前监控数据,最主要的问题是线程池利用率低。通过增加任务负载、调整线程池大小和优化任务拆分策略,可以提高 ForkJoinPool 的利用率,使其更高效地处理并行任务。
队列
ForkJoinPool 内部管理工作队列的机制
1. ForkJoinWorkerThread 和 WorkQueue
每个 ForkJoinPool 由多个 ForkJoinWorkerThread 线程组成,每个线程都有一个对应的 WorkQueue。这些 WorkQueue 由 ForkJoinPool 管理,用于存储和调度任务。
- Common Pool:Java 提供了一个默认的 common pool,用于全局并行任务执行。它是通过 ForkJoinPool.commonPool() 获取的。
- Custom Pool:开发者可以创建自定义的 ForkJoinPool 实例,用于特定的并行任务。
2. WorkQueue 分配和管理
ForkJoinPool 使用一个数组来存储所有的 WorkQueue。这个数组被称为 workQueues。不同类型的 ForkJoinPool 通过内部的索引和标记来区分和管理它们的 WorkQueue,避免冲突。
1. registerWorker 方法
在 registerWorker 方法中,WorkQueue 的索引通过以下代码计算:
int seed = ThreadLocalRandom.getProbe();
int id = (seed << 1) | 1;
- ThreadLocalRandom.getProbe() 返回一个线程特定的伪随机数(seed)。
- seed << 1 将这个随机数左移一位,相当于乘以 2,确保结果是偶数。
- | 1 将结果的最低位设置为 1,这将确保索引是一个奇数。
2. 为什么使用奇数索引
使用奇数索引有助于区分和管理不同类型的工作队列(common pool 和 custom pool):
- Common Pool:通常使用偶数索引,这样 common pool 的队列和 custom pool 的队列可以共存于同一个数组中而不会发生冲突。
- Custom Pool:使用奇数索引,这样可以确保 custom pool 的队列与 common pool 的队列分开,避免相互干扰。
示例代码解释
以下是完整的 registerWorker 方法及其上下文,帮助更好地理解其工作原理:
final void registerWorker(WorkQueue w) {
ReentrantLock lock = registrationLock;
ThreadLocalRandom.localInit();
int seed = ThreadLocalRandom.getProbe();
if (w != null && lock != null) {
int modebits = (mode & FIFO) | w.config;
w.array = new ForkJoinTask<?>[INITIAL_QUEUE_CAPACITY];
w.stackPred = seed; // stash for runWorker
if ((modebits & INNOCUOUS) != 0)
w.initializeInnocuousWorker();
int id = (seed << 1) | 1; // Ensure id is odd
lock.lock();
try {
int n = workQueues.length;
int k = id & (n - 1); // Ensure index within array bounds
// Locate an empty slot in workQueues
while (workQueues[k] != null)
k = (k + 2) & (n - 1); // Step by 2 to maintain odd indices
workQueues[k] = w;
w.poolIndex = k;
} finally {
lock.unlock();
}
}
}
总结
- 索引计算:seed << 1 | 1 确保了 id 是一个奇数,从而 workQueues 的索引也是奇数。
- 避免冲突:通过这种策略,custom pool 和 common pool 可以共享 workQueues 数组,而不会发生冲突。common pool 使用偶数索引,custom pool 使用奇数索引。
- 具体实现:通过步进 2 来寻找空槽,确保新注册的 WorkQueue 放在奇数位置。
这种设计确保了多线程环境下的高效、无锁并发任务处理,同时避免了不同类型的工作队列之间的相互干扰。
重点方法:canStop
方法逻辑
1. 初始化和主循环
outer: for (long oldSum = 0L;;) { // repeat until stable
- outer 标签用于外层循环的跳转。
- oldSum 初始化为 0,用于记录上一次的校验和(checksum)。
- 进入一个无限循环,该循环持续直到找到一个稳定状态或者确定池可以停止。
2. 初步检查
int md; WorkQueue[] qs; long c;
if ((qs = queues) == null || ((md = mode) & STOP) != 0)
return true;
- 获取工作队列数组 queues。
- 获取池的模式 mode。
- 如果工作队列数组为 null 或者池处于停止状态,直接返回 true,表示池可以停止。
if ((md & SMASK) + (int)((c = ctl) >> RC_SHIFT) > 0)
break;
- 获取控制状态 ctl。
- 检查池中的活动线程数是否大于 0,如果是,则跳出循环(池不能停止)。
3. 校验和初始化
long checkSum = c;
- 初始化 checkSum 为当前的控制状态 ctl。
4. 扫描工作队列
for (int i = 1; i < qs.length; i += 2) { // scan submitters
WorkQueue q; ForkJoinTask<?>[] a; int s = 0, cap;
if ((q = qs[i]) != null && (a = q.array) != null &&
(cap = a.length) > 0 &&
((s = q.top) != q.base || a[(cap - 1) & s] != null ||
q.source != 0))
break outer;
checkSum += (((long)i) << 32) ^ s;
}
- 以步长 2 遍历工作队列数组 qs 的奇数索引(这些索引对应于提交者队列)。
- 如果找到一个非空的工作队列 q 且该队列有任务待处理,则跳出外层循环,继续检查(池不能停止)。
- 更新 checkSum,累加当前索引 i 和队列状态 s 的异或值。
5. 检查校验和是否稳定
if (oldSum == (oldSum = checkSum) && queues == qs)
return true;
- 如果当前的校验和 checkSum 与上一次的 oldSum 相等且工作队列数组 qs 没有变化,返回 true,表示池可以停止。
- 更新 oldSum 为当前的 checkSum。
6. 循环结束检查
return (mode & STOP) != 0; // recheck mode on false return
- 如果循环结束且没有返回 true,再一次检查池的模式 mode 是否为停止状态。
- 返回模式检查结果。
总结
canStop 方法通过以下步骤确定 ForkJoinPool 是否可以停止:
- 检查工作队列数组是否为空或池是否处于停止状态。
- 检查活动线程数是否大于 0。
- 扫描工作队列,查看是否有任务待处理。
- 检查校验和是否稳定,确保没有新的任务被提交或队列发生变化。
- 返回池的最终停止状态。
这个方法确保在没有活动任务的情况下安全地停止 ForkJoinPool,避免任务未完成或资源被不当释放的情况。
注意
common线程池和custom线程池是独立的。如果common线程池中有任务待完成,这不会阻塞custom线程池的停止。canStop方法中的逻辑仅适用于当前的ForkJoinPool实例。
因此当你请求java.util.concurrent.ForkJoinPool#awaitQuiescence想要等待所有任务完成时,一定要确认几个场景
- 通过ForkJoinWorkerThread线程调用awaitQuiescence,是否有任务被分配至默认的common pool。如果有,那么你有可能会看到,明明awaitQuiescence已经结束,为什么还会有ForkJoinTask执行,因为可能是common pool中有剩余任务。反之亦然
- 通过非ForkJoinWorkerThread线程调用awaitQuiescence(例如:main线程调用)
- ForkJoinTask中是否存在任务递归拆分,并且拆分后的线程fork后没有阻塞等待
- 线程池每次完成一次pollScan就会检查一次队列情况,检查到队列为空时,就会返回awaitQuiescence已完成
- 由于线程方法java.util.concurrent.ForkJoinPool#scan,是先将线程取出并将所在的slot设置为null成功后,再执行ForkJoinTask。此时正在执行的Worker如果继续fork任务,那么就会看到awaitQuiescence之后依然存在异步任务执行
- 这也正是我实际遇到的一个现象
如果ForkJoinTask内部java.util.concurrent.ForkJoinTask#fork正常会进入到custom pool,但是在awaitQuiescence调用时可能会由于是外部调用,走到java.util.concurrent.ForkJoinPool#externalHelpQuiescePool,队列中的任务通过java.util.concurrent.ForkJoinPool#pollScan扫描出来的ForkJoinTask此时可能会由外部线程执行(例如:main线程),导致将原custom pool中的任务转移到了common pool队列。反之common pool中的任务如果内部fork会再次进入custom pool
重点方法:await
简单总结下awaitQuiescence与awaitTermination
awaitTermination:是ExecutorService接口方法,如果是由common线程池调用,那么该方法与awaitQuiescence等同,否则就会进入休眠,知道所有任务完成时唤醒,或者超时
awaitQuiescence:是ForkJoinPool独有的,只要有一瞬间线程池没有队列积压,并且没有活跃线程,例如像下面四个线程:在休眠
"ForkJoinPool-1-worker-1" #38 daemon prio=5 os_prio=31 cpu=715.14ms elapsed=1160.62s tid=0x00007f825bcfe600 nid=0xff03 runnable [0x0000700009785000]
java.lang.Thread.State: RUNNABLE
at java.lang.Thread.sleep(java.base@17.0.4.1/Native Method)
at java.lang.Thread.sleep(java.base@17.0.4.1/Thread.java:337)
at java.util.concurrent.TimeUnit.sleep(java.base@17.0.4.1/TimeUnit.java:446)
at com.google.common.util.concurrent.Uninterruptibles.sleepUninterruptibly(Uninterruptibles.java:406)
at com.google.common.util.concurrent.RateLimiter$SleepingStopwatch$1.sleepMicrosUninterruptibly(RateLimiter.java:488)
at com.google.common.util.concurrent.RateLimiter.acquire(RateLimiter.java:307)
at com.google.common.util.concurrent.RateLimiter.acquire(RateLimiter.java:292)
at ....service.WebClientService.lambda$get$0(WebClientService.java:36)
at ....service.WebClientService$$Lambda$1706/0x000000080165ed08.get(Unknown Source)
at reactor.core.publisher.MonoDefer.subscribe(MonoDefer.java:45)
at reactor.core.publisher.FluxRetryWhen.subscribe(FluxRetryWhen.java:81)
at reactor.core.publisher.MonoRetryWhen.subscribeOrReturn(MonoRetryWhen.java:46)
at reactor.core.publisher.Mono.subscribe(Mono.java:4552)
at reactor.core.publisher.Mono.subscribeWith(Mono.java:4634)
at reactor.core.publisher.Mono.subscribe(Mono.java:4534)
at reactor.core.publisher.Mono.subscribe(Mono.java:4470)
at reactor.core.publisher.Mono.subscribe(Mono.java:4442)
at ....service.WebClientService.get(WebClientService.java:42)
at ....service.StockQuoteDataService.loadTaskConcurrent(StockQuoteDataService.java:156)
at ....task.LoadStockQuoteDataTask.compute(LoadStockQuoteDataTask.java:62)
at java.util.concurrent.RecursiveAction.exec(java.base@17.0.4.1/RecursiveAction.java:194)
at java.util.concurrent.ForkJoinTask.doExec$$$capture(java.base@17.0.4.1/ForkJoinTask.java:373)
at java.util.concurrent.ForkJoinTask.doExec(java.base@17.0.4.1/ForkJoinTask.java)
at java.util.concurrent.ForkJoinPool$WorkQueue.topLevelExec(java.base@17.0.4.1/ForkJoinPool.java:1182)
at java.util.concurrent.ForkJoinPool.scan(java.base@17.0.4.1/ForkJoinPool.java:1655)
at java.util.concurrent.ForkJoinPool.runWorker(java.base@17.0.4.1/ForkJoinPool.java:1622)
at java.util.concurrent.ForkJoinWorkerThread.run(java.base@17.0.4.1/ForkJoinWorkerThread.java:165)
"ForkJoinPool-1-worker-2" #39 daemon prio=5 os_prio=31 cpu=612.67ms elapsed=1160.62s tid=0x00007f82627ffa00 nid=0xab03 waiting on condition [0x0000700009888000]
java.lang.Thread.State: WAITING (parking)
at jdk.internal.misc.Unsafe.park(java.base@17.0.4.1/Native Method)
- parking to wait for <0x000000070439c718> (a java.util.concurrent.ForkJoinPool)
at java.util.concurrent.locks.LockSupport.park(java.base@17.0.4.1/LockSupport.java:341)
at java.util.concurrent.ForkJoinPool.awaitWork(java.base@17.0.4.1/ForkJoinPool.java:1724)
at java.util.concurrent.ForkJoinPool.runWorker(java.base@17.0.4.1/ForkJoinPool.java:1623)
at java.util.concurrent.ForkJoinWorkerThread.run(java.base@17.0.4.1/ForkJoinWorkerThread.java:165)
"ForkJoinPool.commonPool-worker-1" #42 daemon prio=5 os_prio=31 cpu=580.50ms elapsed=1156.09s tid=0x00007f825f280200 nid=0x6c0f runnable [0x0000700007f3d000]
java.lang.Thread.State: RUNNABLE
at java.lang.Thread.sleep(java.base@17.0.4.1/Native Method)
at java.lang.Thread.sleep(java.base@17.0.4.1/Thread.java:337)
at java.util.concurrent.TimeUnit.sleep(java.base@17.0.4.1/TimeUnit.java:446)
at com.google.common.util.concurrent.Uninterruptibles.sleepUninterruptibly(Uninterruptibles.java:406)
at com.google.common.util.concurrent.RateLimiter$SleepingStopwatch$1.sleepMicrosUninterruptibly(RateLimiter.java:488)
at com.google.common.util.concurrent.RateLimiter.acquire(RateLimiter.java:307)
at com.google.common.util.concurrent.RateLimiter.acquire(RateLimiter.java:292)
at ....service.WebClientService.lambda$get$0(WebClientService.java:36)
at ....service.WebClientService$$Lambda$1706/0x000000080165ed08.get(Unknown Source)
at reactor.core.publisher.MonoDefer.subscribe(MonoDefer.java:45)
at reactor.core.publisher.FluxRetryWhen.subscribe(FluxRetryWhen.java:81)
at reactor.core.publisher.MonoRetryWhen.subscribeOrReturn(MonoRetryWhen.java:46)
at reactor.core.publisher.Mono.subscribe(Mono.java:4552)
at reactor.core.publisher.Mono.subscribeWith(Mono.java:4634)
at reactor.core.publisher.Mono.subscribe(Mono.java:4534)
at reactor.core.publisher.Mono.subscribe(Mono.java:4470)
at reactor.core.publisher.Mono.subscribe(Mono.java:4442)
at ....service.WebClientService.get(WebClientService.java:42)
at ....service.StockQuoteDataService.loadTaskConcurrent(StockQuoteDataService.java:156)
at ....task.LoadStockQuoteDataTask.compute(LoadStockQuoteDataTask.java:62)
at java.util.concurrent.RecursiveAction.exec(java.base@17.0.4.1/RecursiveAction.java:194)
at java.util.concurrent.ForkJoinTask.doExec$$$capture(java.base@17.0.4.1/ForkJoinTask.java:373)
at java.util.concurrent.ForkJoinTask.doExec(java.base@17.0.4.1/ForkJoinTask.java)
at java.util.concurrent.ForkJoinPool$WorkQueue.topLevelExec(java.base@17.0.4.1/ForkJoinPool.java:1182)
at java.util.concurrent.ForkJoinPool.scan(java.base@17.0.4.1/ForkJoinPool.java:1655)
at java.util.concurrent.ForkJoinPool.runWorker(java.base@17.0.4.1/ForkJoinPool.java:1622)
at java.util.concurrent.ForkJoinWorkerThread.run(java.base@17.0.4.1/ForkJoinWorkerThread.java:165)
"ForkJoinPool.commonPool-worker-2" #43 daemon prio=5 os_prio=31 cpu=642.31ms elapsed=1155.96s tid=0x00007f8262b58200 nid=0x9d07 runnable [0x000070000947c000]
java.lang.Thread.State: RUNNABLE
at java.lang.Thread.sleep(java.base@17.0.4.1/Native Method)
- parking to wait for <0x00000007041cf858> (a java.util.concurrent.ForkJoinPool)
at java.lang.Thread.sleep(java.base@17.0.4.1/Thread.java:337)
at java.util.concurrent.TimeUnit.sleep(java.base@17.0.4.1/TimeUnit.java:446)
at com.google.common.util.concurrent.Uninterruptibles.sleepUninterruptibly(Uninterruptibles.java:406)
at com.google.common.util.concurrent.RateLimiter$SleepingStopwatch$1.sleepMicrosUninterruptibly(RateLimiter.java:488)
at com.google.common.util.concurrent.RateLimiter.acquire(RateLimiter.java:307)
at com.google.common.util.concurrent.RateLimiter.acquire(RateLimiter.java:292)
at ....service.WebClientService.lambda$get$0(WebClientService.java:36)
at ....service.WebClientService$$Lambda$1706/0x000000080165ed08.get(Unknown Source)
at reactor.core.publisher.MonoDefer.subscribe(MonoDefer.java:45)
at reactor.core.publisher.FluxRetryWhen.subscribe(FluxRetryWhen.java:81)
at reactor.core.publisher.MonoRetryWhen.subscribeOrReturn(MonoRetryWhen.java:46)
at reactor.core.publisher.Mono.subscribe(Mono.java:4552)
at reactor.core.publisher.Mono.subscribeWith(Mono.java:4634)
at reactor.core.publisher.Mono.subscribe(Mono.java:4534)
at reactor.core.publisher.Mono.subscribe(Mono.java:4470)
at reactor.core.publisher.Mono.subscribe(Mono.java:4442)
at ....service.WebClientService.get(WebClientService.java:42)
at ....service.StockQuoteDataService.loadTaskConcurrent(StockQuoteDataService.java:156)
at ....task.LoadStockQuoteDataTask.compute(LoadStockQuoteDataTask.java:62)
at java.util.concurrent.RecursiveAction.exec(java.base@17.0.4.1/RecursiveAction.java:194)
at java.util.concurrent.ForkJoinTask.doExec$$$capture(java.base@17.0.4.1/ForkJoinTask.java:373)
at java.util.concurrent.ForkJoinTask.doExec(java.base@17.0.4.1/ForkJoinTask.java)
at java.util.concurrent.ForkJoinPool$WorkQueue.topLevelExec(java.base@17.0.4.1/ForkJoinPool.java:1182)
at java.util.concurrent.ForkJoinPool.scan(java.base@17.0.4.1/ForkJoinPool.java:1655)
at java.util.concurrent.ForkJoinPool.runWorker(java.base@17.0.4.1/ForkJoinPool.java:1622)
at java.util.concurrent.ForkJoinWorkerThread.run(java.base@17.0.4.1/ForkJoinWorkerThread.java:165)
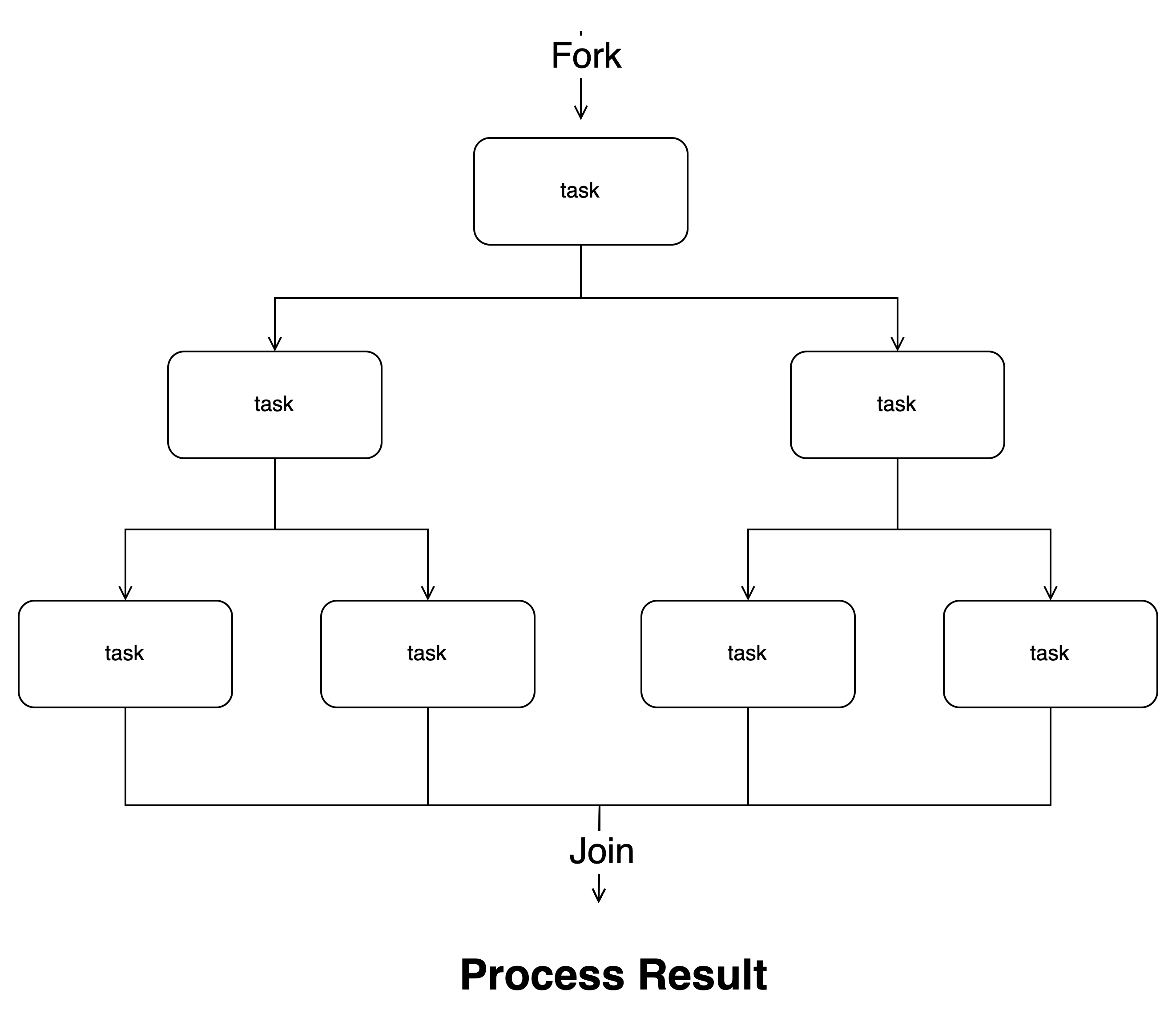
总结
如下图,每层task都可以异步执行,例如:最终切分出来的4个task任务可以异步并发执行,在其中一个任务完成后可以窃取其他队列任务继续工作,充分利用线程池资源。
例如案例中的斐波那契数列,线程池的异步任务数为1/2,因为每层都会拆分1个异步任务,一个任务同步等待,虽然只有1/2,但是当拆分的任务足够多时,那么线程池的资源依然可以得到充分利用
斐波那契数列任务的监控如下,可以看到8 core的线程全部被利用了起来
# HELP forkJoinPool_poolSize
# TYPE forkJoinPool_poolSize gauge
forkJoinPool_poolSize 8.0
# HELP forkJoinPool_stealCount
# TYPE forkJoinPool_stealCount gauge
forkJoinPool_stealCount 0.0
# HELP forkJoinPool_activeThreadCount
# TYPE forkJoinPool_activeThreadCount gauge
forkJoinPool_activeThreadCount 8.0
# HELP forkJoinPool_queuedTaskCount
# TYPE forkJoinPool_queuedTaskCount gauge
forkJoinPool_queuedTaskCount 39918.0