文章目录
- 1 测试鉴别器
- 2 建立生成器
- 3 测试生成器
- 4 训练生成器
- 5 使用生成器
- 6 内存查看
上一节,我们已经建立好了模型所必需的鉴别器类与Dataset类。
使用PyTorch构建GAN生成对抗网络源码(详细步骤讲解+注释版)02 人脸识别 上
接下来,我们测试一下鉴别器是否可以正常工作,并建立生成器。
1 测试鉴别器
# 数据类建立
celeba_dataset = CelebADataset(r'F:\学习\AI\对抗网络\face-data\celeba_aligned_small.h5py')
celeba_dataset.plot_image(66)
# 鉴别器类建立
D = Discriminator()
D.to(device)
for image_data_tensor in celeba_dataset:
# real data
D.train(image_data_tensor, torch.cuda.FloatTensor([1.0]))
# fake data
D.train(generate_random_image((218,178,3)), torch.cuda.FloatTensor([0.0]))
此处我们调用了两个类,一个是celeba_dataset(Dataset)类,一个是D(Discriminator)类。两个类在博文的上篇中完成了定义。此处分别使用real数据与fake数据对模型进行训练。fake数据使用的是随机生成的不规则像素点,real数据使用的是真是人脸数据。
在使用GPU的情况,此处预计会消耗5分钟左右。
训练完成后,可以绘制损失值的变化以查看训练效果。
D.plot_progress()
plt.show()
2 建立生成器
生成器与鉴别器高度类似,仅网络的结构和训练部分略有不同。
网格结构选取的是输入层为100个节点,中间层为单层结构,包含3*10*10个节点,输出层为3 * 218 * 178。输出层是完全根据照片的像素格式来确定的,输入层与中间层可以根据经验进行修改与优化。各层之间均采用全连接的连接方式。相关部分的代码如下:
class Generator(nn.Module):
def __init__(self):
# 父类继承
super().__init__()
# 定义神经网络
self.model = nn.Sequential(
nn.Linear(100, 3 * 10 * 10),
nn.LeakyReLU(),
nn.LayerNorm(3 * 10 * 10),
nn.Linear(3 * 10 * 10, 3 * 218 * 178),
nn.Sigmoid(),
View((218, 178, 3))
)
在进行损失计算时,我们将鉴别器的返回值作为实际输出,将torch.cuda.FloatTensor([1.0]作为目标输出,来计算损失。相关比分的代码如下:
class Generator(nn.Module):
def train(self, D, inputs, targets):
# 计算输出
g_output = self.forward(inputs)
# 将输出传至鉴别器
d_output = D.forward(g_output)
# 计算损失
loss = D.loss_function(d_output, targets)
对于生成器的完整代码,也将在文末进行提供。
3 测试生成器
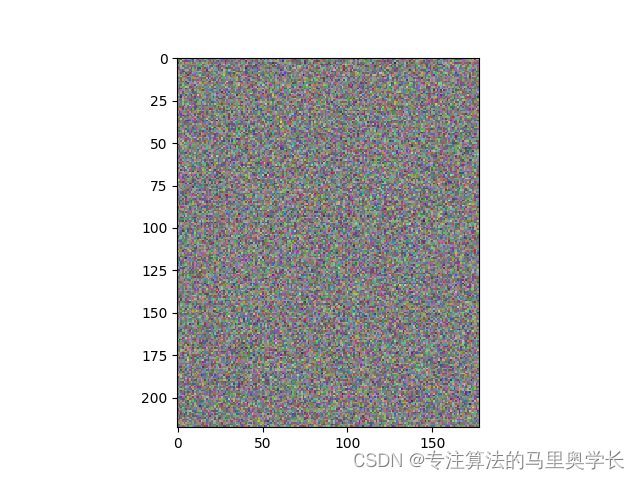
未经训练的生成器,应该具备生成类似雪花马赛克的随机图像能力。下面建立了一个生成器类,并用未经训练的生成器直接输出图像。
G = Generator()
G.to(device)
output = G.forward(generate_random_seed(100))
img = output.detach().cpu().numpy()
plt.imshow(img, interpolation='none', cmap='Blues')
plt.show()
如果代码运行正常,应得到类似下面的图象。
4 训练生成器
训练时,对数据集进行遍历,并且依次执行下面三步:
- 使用真实照片数据,对鉴别器进行训练,期望的鉴别器输出值为1;
- 使用生成器输出的fake数据,对鉴别器进行训练,期望的鉴别器输出值为0;
- 使用鉴别器的返回值,训练生成器,生成器所希望的鉴别器输出为1
具体代码如下:
for image_data_tensor in celeba_dataset:
# train discriminator on true
D.train(image_data_tensor, torch.cuda.FloatTensor([1.0]))
# train discriminator on false
# use detach() so gradients in G are not calculated
D.train(G.forward(generate_random_seed(100)).detach(), torch.cuda.FloatTensor([0.0]))
# train generator
G.train(D, generate_random_seed(100), torch.cuda.FloatTensor([1.0]))
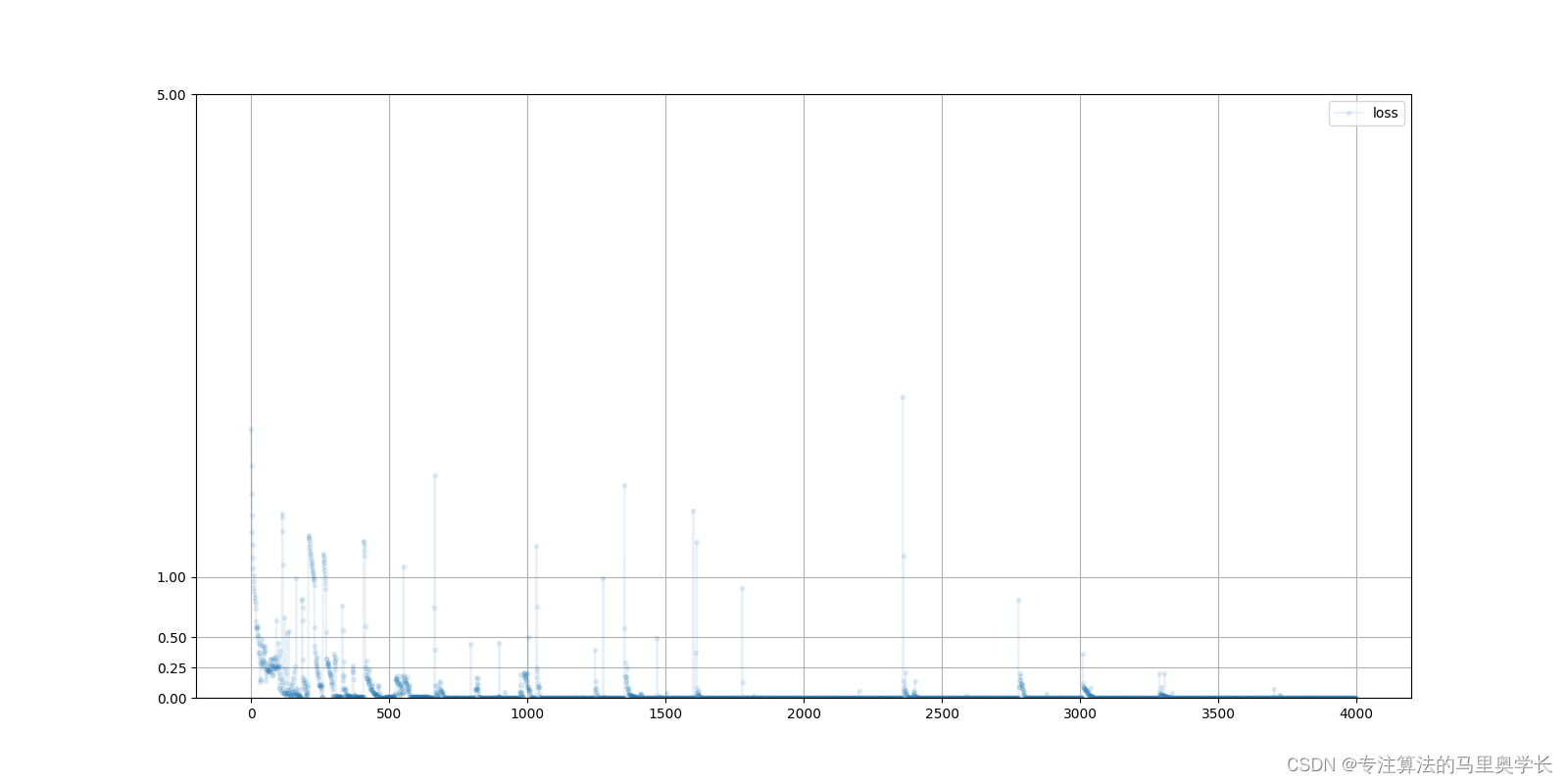
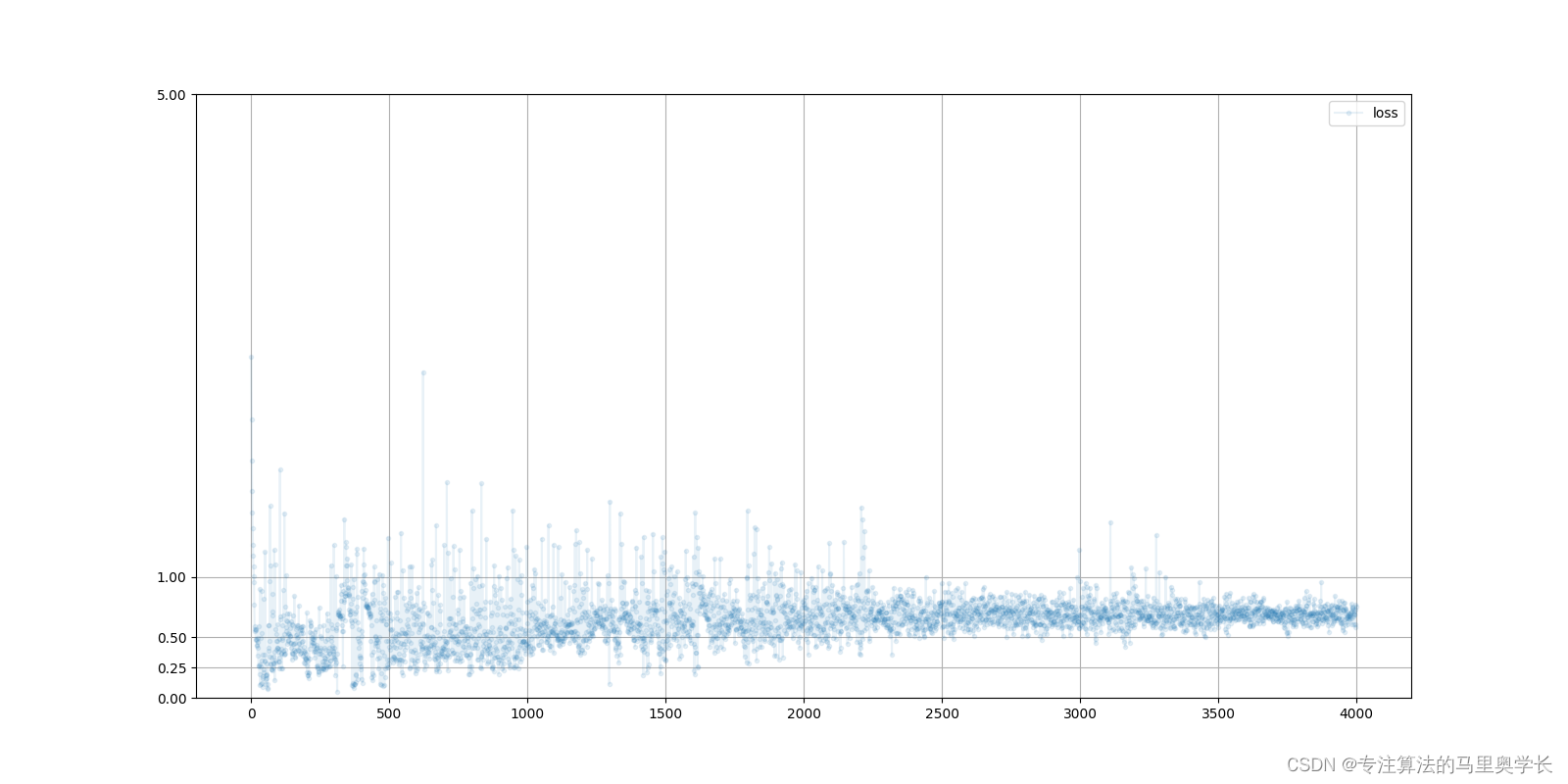
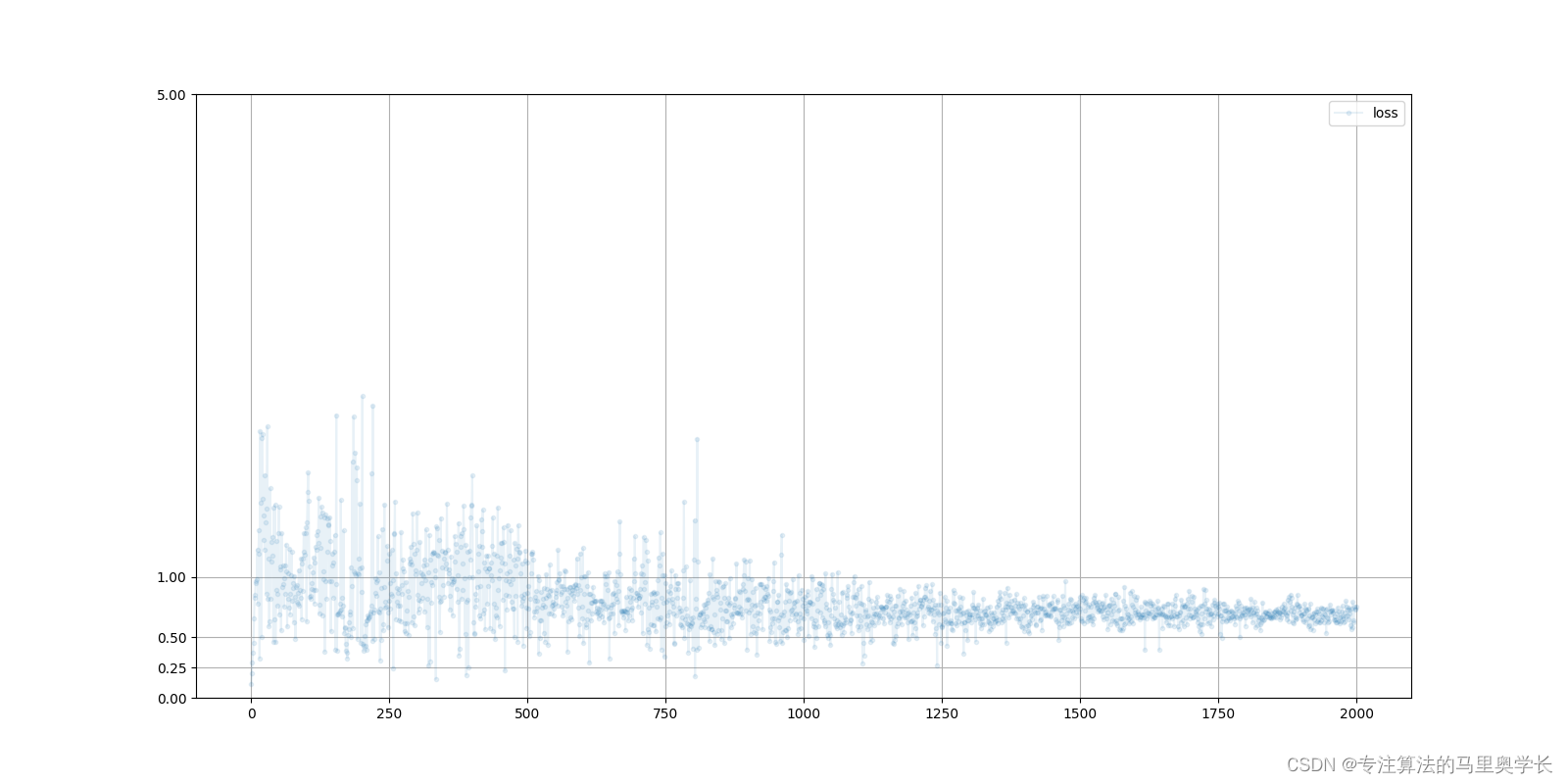
在训练后,可以分别查看鉴别器与生成器的损失变化曲线。
D.plot_progress()
G.plot_progress()
下图为鉴别器损失值变化曲线
下图为生成器损失值变化曲线
5 使用生成器

6 内存查看
最后可以查看一下本次训练的内存使用情况
(1)分配给张量的当前内存(输出单位是GB)
torch.cuda.memory_allocated(device) / (1024*1024*1024)
我的输出结果为:0.6999950408935547
(2)分配给张量的总内存(输出单位是GB)
torch.cuda.max_memory_allocated(device) / (1024*1024*1024)
我的输出结果为:0.962151050567627
(3)内存消耗汇总
print(torch.cuda.memory_summary(device, abbreviated=True))
输出结果如下:
|===========================================================================|
| PyTorch CUDA memory summary, device ID 0 |
|---------------------------------------------------------------------------|
| CUDA OOMs: 0 | cudaMalloc retries: 0 |
|===========================================================================|
| Metric | Cur Usage | Peak Usage | Tot Alloc | Tot Freed |
|---------------------------------------------------------------------------|
| Allocated memory | 733998 KB | 985 MB | 14018 GB | 14017 GB |
|---------------------------------------------------------------------------|
| Active memory | 733998 KB | 985 MB | 14018 GB | 14017 GB |
|---------------------------------------------------------------------------|
| GPU reserved memory | 1086 MB | 1086 MB | 1086 MB | 0 B |
|---------------------------------------------------------------------------|
| Non-releasable memory | 9426 KB | 12685 KB | 353393 MB | 353383 MB |
|---------------------------------------------------------------------------|
| Allocations | 68 | 87 | 2580 K | 2580 K |
|---------------------------------------------------------------------------|
| Active allocs | 68 | 87 | 2580 K | 2580 K |
|---------------------------------------------------------------------------|
| GPU reserved segments | 15 | 15 | 15 | 0 |
|---------------------------------------------------------------------------|
| Non-releasable allocs | 11 | 14 | 1410 K | 1410 K |
|---------------------------------------------------------------------------|
| Oversize allocations | 0 | 0 | 0 | 0 |
|---------------------------------------------------------------------------|
| Oversize GPU segments | 0 | 0 | 0 | 0 |
|===========================================================================|
代码文件:博客附件代码