用 CPU 也能部署私有化大模型?
对,没错,只要你的电脑有个 8G 内存,你就可以轻松部署 Llama、Gemma、Qwen 等多种开源大模型。
非技术人员,安装 Docker、Docker-compose 很费劲?
不用,这些都不需要安装,就一个要求:有手就行~
今天主要为大家分享保姆级教程:如何利用普通个人电脑,本地私有化部署 Qwen 大模型。
一、Ollama 与 Qwen7B 安装和使用
(一)下载
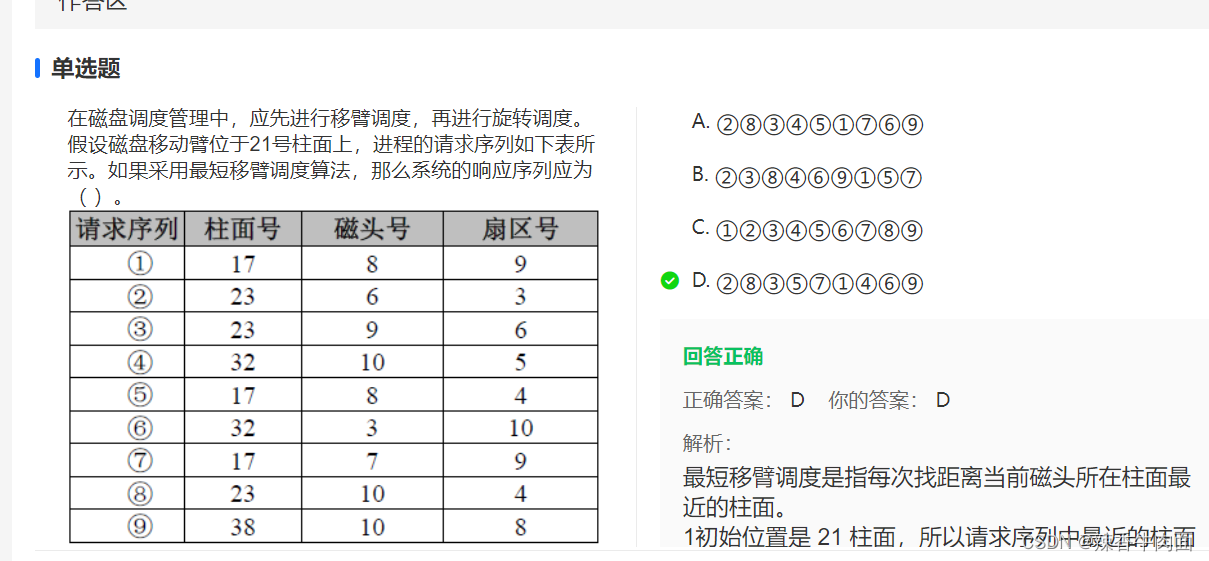
进入下载地址,目前支持 Mac、Windows、Linux 以及 docker 部署,本次演示,主要针对 Mac。
下载地址:https://github.com/ollama/ollama
我已经为大家提前下载好了 Mac、Windows 的安装包,公众号回复 ollama 领取。
(二)安装 Ollama
1、下载到本地,并解压后,双击 Ollama 图标。
2、点击 Move to Applications ,按照建议,将其移动到应用程序文件夹下。

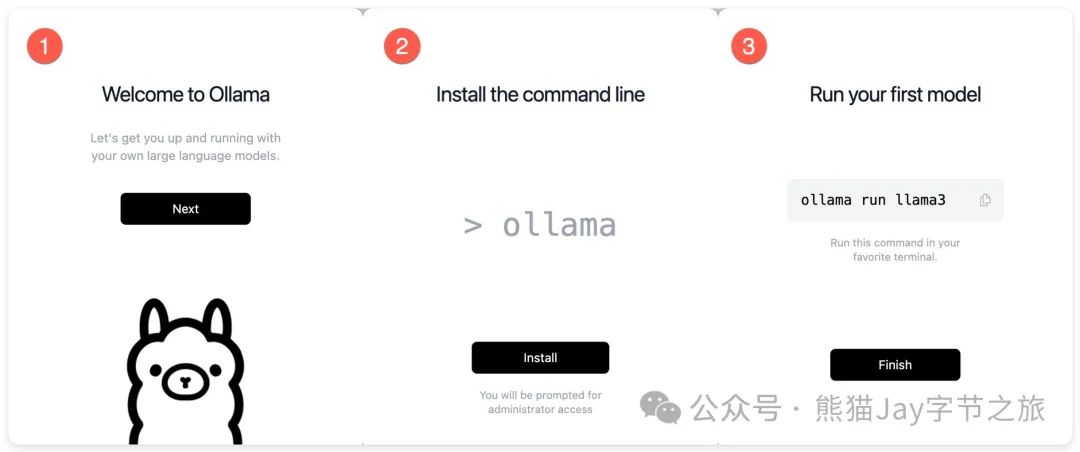
3、按照从左到右的顺序执行这三步。到这 Ollama 安装完成了。
(三)安装模型
作为国内的优质大模型,Qwen 对于中文的支持力度还是很强的,最终选择用它来试手。
大家也可以尝试选择自己喜欢的模型,比如 Llama3、Gemma 等等。
1、进入模型仓库
地址:https://ollama.com/library
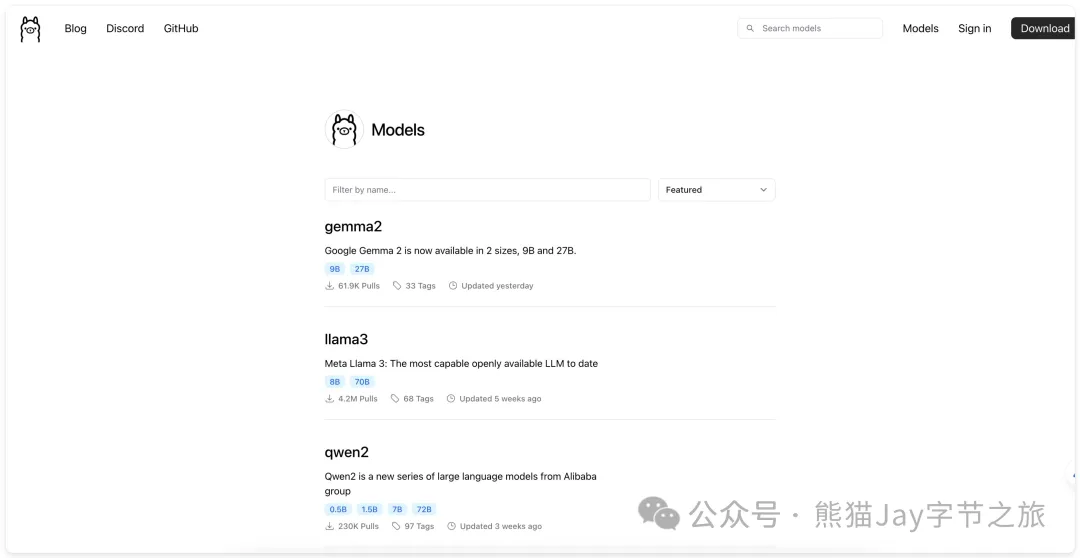
2、搜索对应模型。发现目前有 Qwen 0.5B ~ 110B 可供使用。
因为内存不够用,最终选择下载 Qwen:7b,大家可以按照自身硬件情况下载模型。
可以使用图中对应型号的命令,进行下载。7b 下载命令为:ollama run qwen:7b
官方建议: 至少有 8 GB 可用内存来运行 7 B 型号,16 GB 来运行 13 B 型号,32 GB 来运行 33 B 型号。
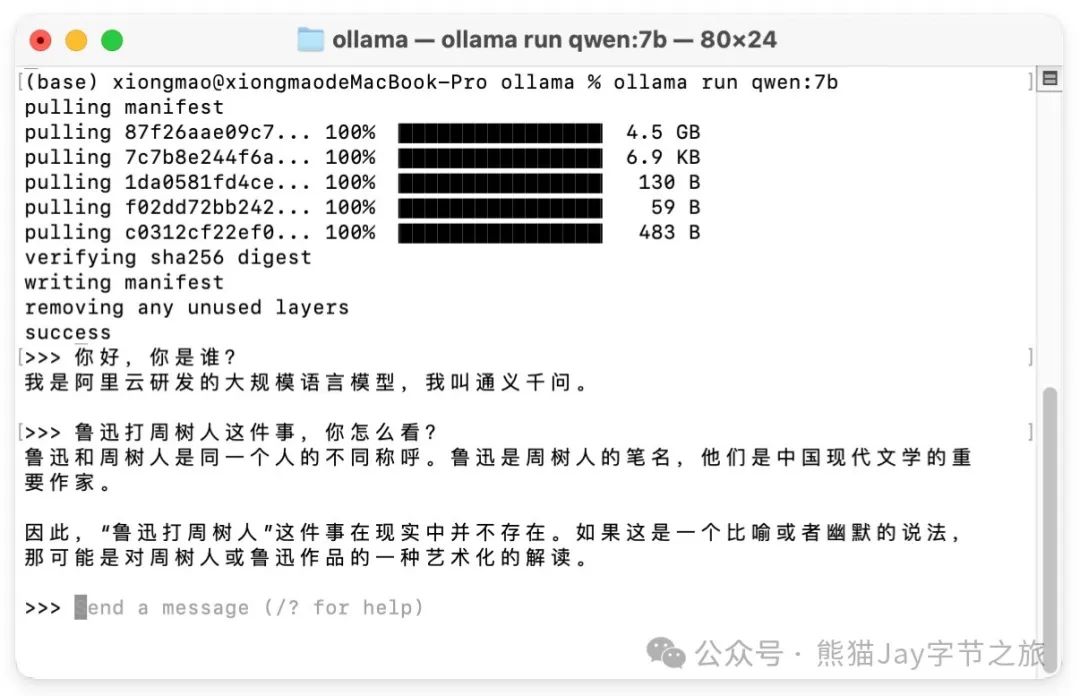
3、下载完成,开始对话,中文能力的确可以~
但是命令行对话总不是事儿啊,我们需要一个网页应用,这就得请出下一位主角:ChatGPT-Next-Web。
二、ChatGPT-Next-Web 安装和使用
(一)安装
进入 ChatGPT-Next-Web 仓库地址,选择对应版本下载。
地址:https://github.com/ChatGPTNextWeb/ChatGPT-Next-Web/releases/tag/v2.12.4
我选择了 NextChat_2.12.4_universal.dmg
我已经为大家提前下载好了 Mac、Windows 安装包,公众号回复 ollama 领取。
下载完成后,可以直接安装,无需额外下载其他软件。
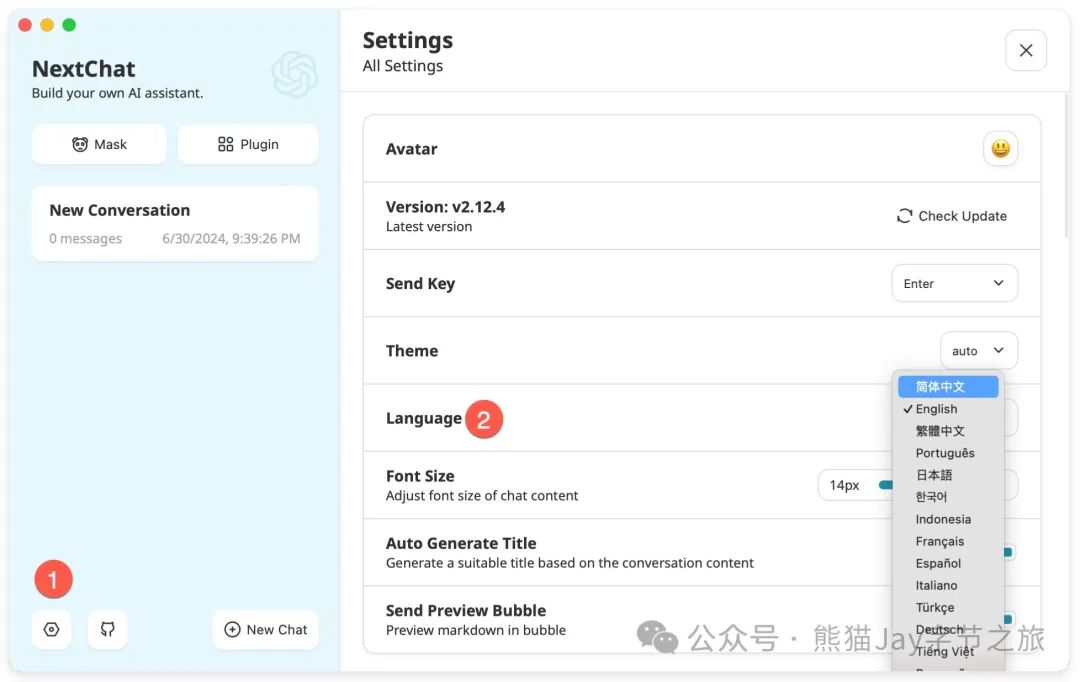
(二)设置语言(可选)
按需选择语言偏好。
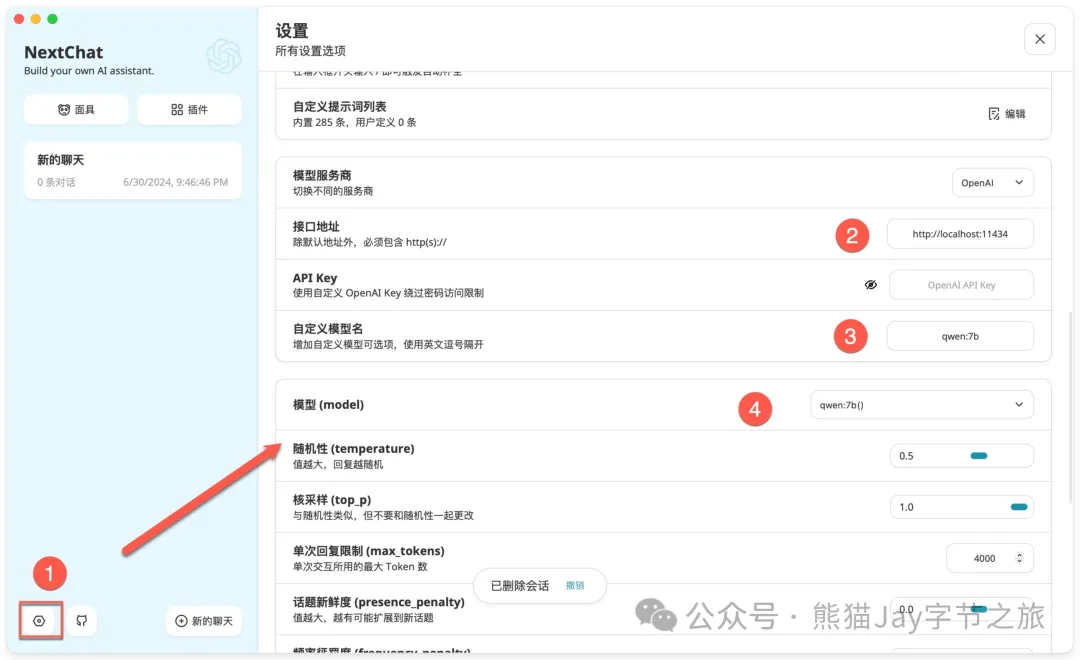
(三)配置
1、点击图标,进行配置页面。
2、输入接口地址:http://localhost:11434
3、自定义模型名:qwen:7b
4、模型(model):qwen:7b() ,注意该选项在最下方。
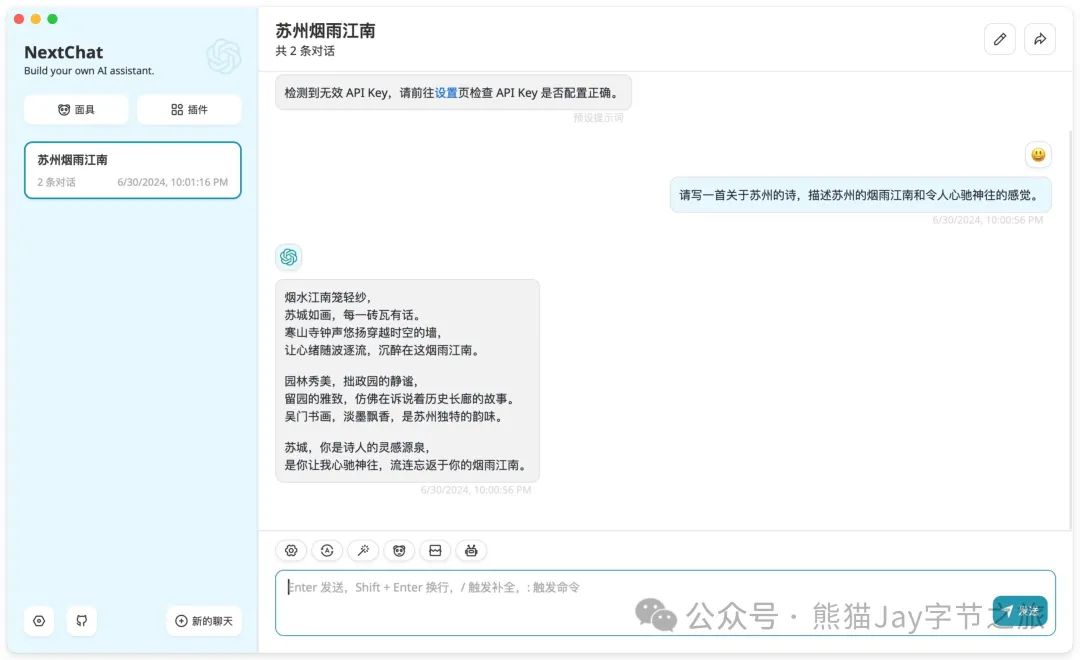
四)对话测试
1、普通对话
效果还不错。
2、面具对话
使用面具对话功能时,需要注意,软件模型忽略了自定义的 qwen:7b,每次利用面具对话时,需要重新选择模型。
2.1、没有选择模型时,则会出错。
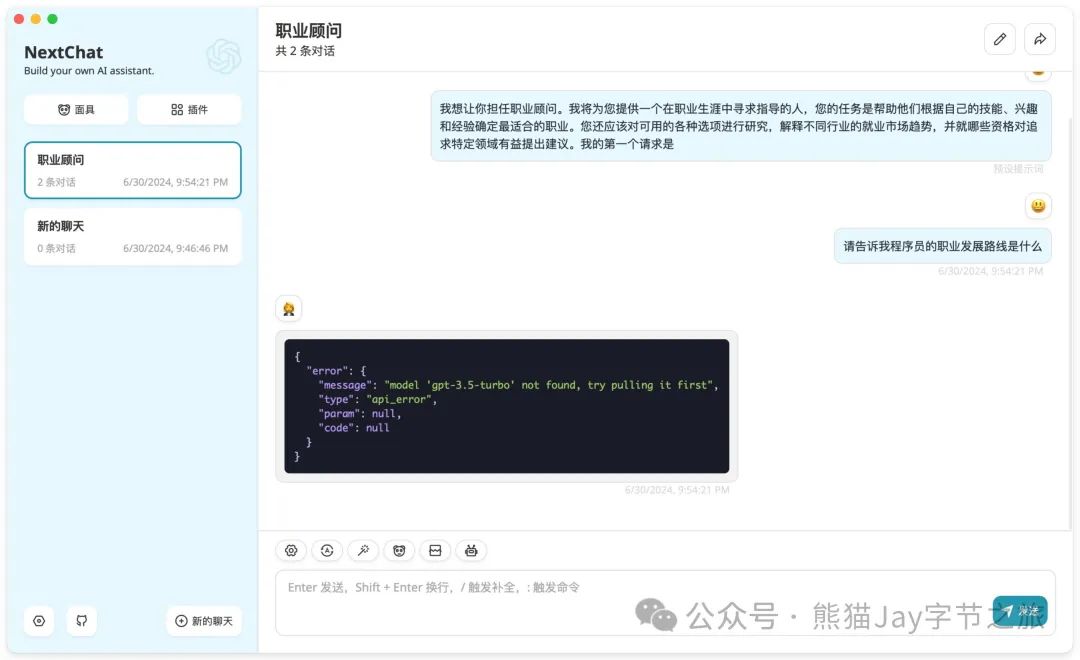
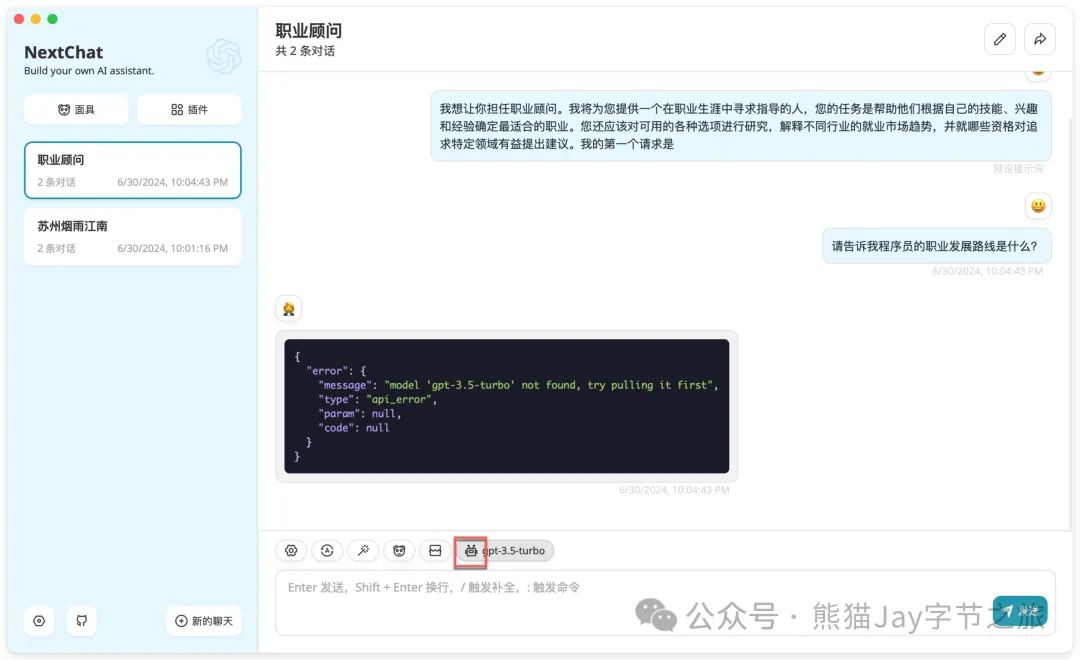
2.2、点击图标,并选择正确的模型。
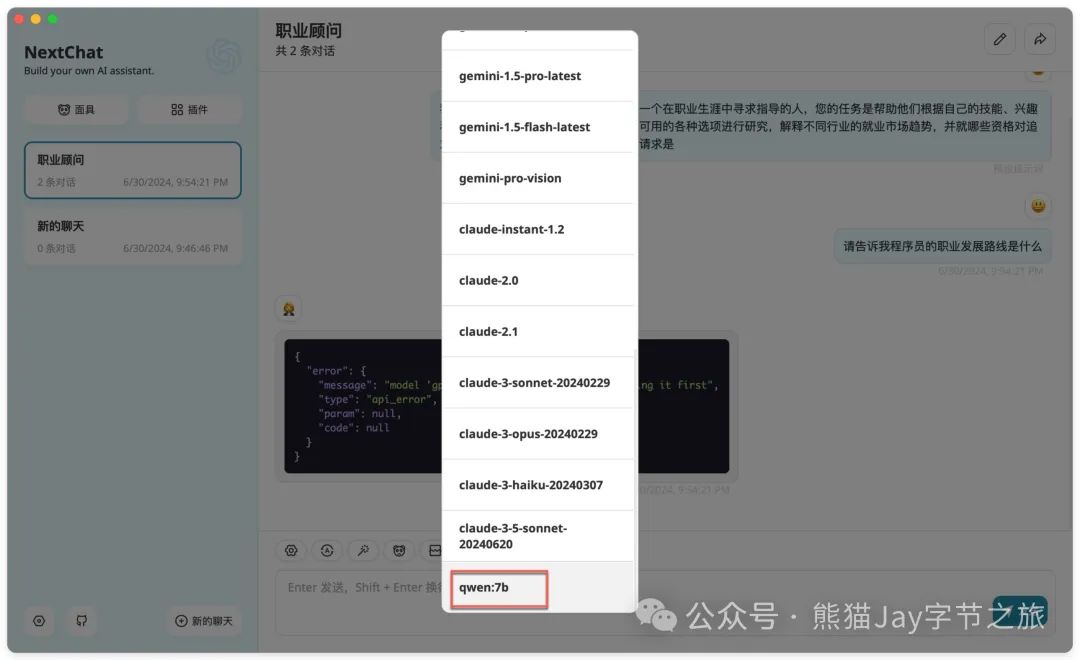
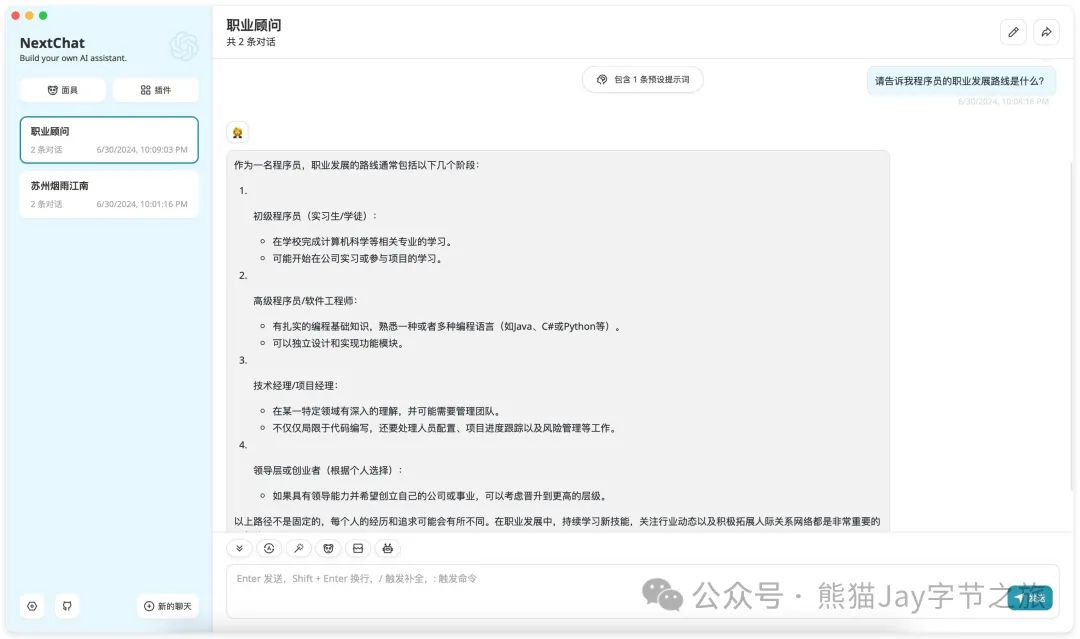
2.3、对话显示成功。
三、总结
没有消费级的 GPU,竟然都可以拥有自己的本地大模型。
部署过程基本上没有卡点,一台普通的 Mac 就能搞定,太香了~
想学习什么,欢迎留言告诉我。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。