域名攻击发展
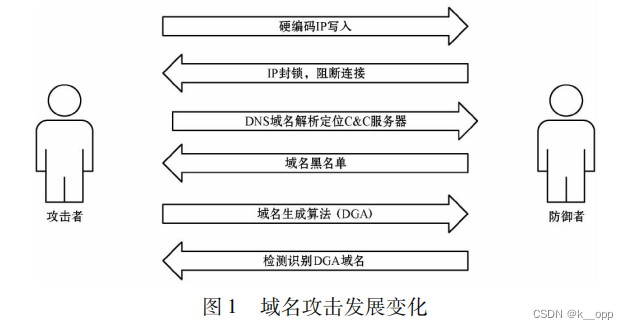
使用 DGA 的优势在于模糊了控制服务器的节点位置,该方法的灵活性还让网络安全管理员无法阻止所有可能的域名,并且注册一些域名对攻击者来说成本很低。利用 DGA 域名实施的攻击是网络安全中重要的攻击形式。因此,捕获由恶意软件生成的域名已成为信息安全的核心主题。
域名生成算法
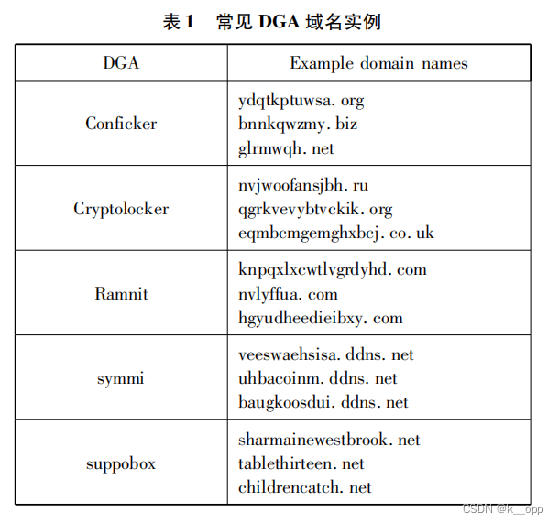
Conficker:使用Windows 操作系统软件中的缺陷和对管理员密码的字典攻击在形成僵尸网络时传播
CryptoLocker:它使用 DGA 从英文字母表 a ~ y 中随机选取生成字符串长度为 12 至 15 的二级域名,每周大约生成1000个域名。
Ramnit:DGA 使用随机数生成器首先通过均匀地选择 8 到 19 个字符之间的长度来确定第二级域的长度。接下来,DGA 通过从“a”到“x”统一选取字母来确定第二级域
symmi:通过当前的日期和编码常量,利用随机数生成器生成种子。它包含三级域名,在第三级域中,除字母“j”之外,从元音和辅音中随机交替的挑选字母,因此随后的字母总是来自其他字符类这样选取的字符组成的域名几乎是可读的。
Suppobox:利用英文单词列表,从英文单词列表中随机选择两个单词连接在一起生成恶意域名
DGA 域名检测的研究
基于特征提取的机器学习方法的检测
域名字符统计特征的检测
-
使用域名的bigram特征:Davuth等人通过分析域名的bigram(二元组)特征,利用人工设定的阈值过滤掉出现频率较低的bigram,然后使用支持向量机(SVM)分类器来检测随机域名。
-
分析IP地址的域名特征分布:Yadav等人通过观察同一组IP地址下所有域名的unigram(一元组)和bigram特征分布,寻找算法生成域名的固有模式,以此来检测DNS流量中的域名。
-
利用域名长度特征:Mowbray等人通过分析域名查询服务中不寻常的字符串长度分布来检测恶意域名。
-
基于随机森林的随机域名检测方法:王红凯等人提出了一种基于随机森林的随机域名检测方法,该方法通过人工提取的域名长度、域名字符信息熵分布、元音辅音比、有意义的字符比率等特征来构建随机森林模型进行训练和分类,实现对随机域名的检测。
-
使用域名的K-L距离、编辑距离、Jaccard系数作为特征向量:Agyepong等人利用算法生成域名与正常域名在字符分布上的差异,使用K-L距离、编辑距离、Jaccard系数作为特征向量来识别恶意域名。
-
使用分词算法扩展特征集:通过使用分词算法将域名分割成单个词,以此来扩展特征集的大小,提高检测恶意域名的能力。
DNS 流量信息的检测
-
fast-flux僵尸网络检测:文献[22]提出了一种基于fast-flux僵尸网络特征的检测方法,包括委托代理模式、恶意活动的执行者和硬件性能,用于实时检测Web服务是否被fast-flux僵尸网络托管。
-
Exposure系统:Bilge等人介绍了Exposure系统,它使用DNS分析技术来检测涉及恶意活动的域名,通过提取15个特征来描述DNS名称的不同属性及其查询方式。
-
Pleiades系统:Antonakakis等人设计了Pleiades系统,专注于检测DGA(域名生成算法)生成的域名。该系统利用DGA域名解析为C&C服务器地址较少的特点,通过统计学习技术构建模型,无需劳动密集型恶意软件逆向工程即可发现和建模新的DGA。
-
NXDOMAIN响应分析:文献[23][25]通过分析NXDOMAIN响应来检测DGA域名,这种方法不需要大规模部署DNS分析工具,但面临大规模真实DNS数据日志少、恶意域特征弹性和缺乏具体评估方案等挑战。
-
恶意域名检测技术的一般框架:文献[26-27]对近年来使用DNS数据的恶意域名检测技术的一般框架进行了分类,并提出了一些挑战,如特征弹性和缺乏评估方案。
-
实时检测方法:为了满足实时检测的要求,许多方法使用手工挑选的特征,如熵、字符串长度、元音比、辅音比等。机器学习模型,如随机森林分类器,也被用于提高检测率,但存在误报率较高和整体检测率低的问题。
-
僵尸网络检测的挑战:随着僵尸网络变得更加复杂和智能化,现有的检测方法面临挑战,包括网络流的部分特征无法完全表征僵尸网络的异常行为,以及攻击者可能设计新的DGA算法来绕过某些固定特征。
虽然在DNS流量分析领域取得了一定的进展,但恶意域名检测仍然面临实时性、准确性和对抗性等挑战。随着僵尸网络的不断进化,检测技术也需要不断更新以应对这些挑战。
基于无特征提取的深度学习方法的检测
RNN 在域名检测的应用
这段话主要讨论了循环神经网络(RNN)及其变体在域名检测领域的应用,以及它们在处理特定问题时的优势和挑战:
-
循环神经网络(RNN)的应用:RNN因其能够捕捉序列之间的时间关系,被用于自然语言处理任务。初期,RNN和递归神经网络被用来检测伪域名。
-
梯度消失问题:RNN在处理长序列时容易出现梯度消失问题,这限制了其学习长期依赖信息的能力。
-
LSTM的优势:LSTM通过增加状态信息解决了梯度消失问题,使其能够学习长期依赖信息,特别擅长文本和语音处理,因此在域名检测中得到了广泛应用。
-
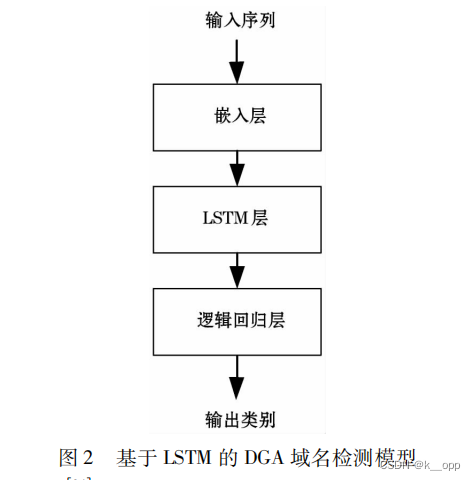
LSTM在DGA检测中的应用:Woodbridge等人利用LSTM实现对DGA的实时预测,无需上下文信息或手动创建的特征。模型框架包括嵌入层、LSTM层和逻辑回归分类器。
5. 深度学习方法的比较:Yu等人比较了基于特征的传统机器学习方法(如随机森林)和深度学习方法(如LSTM和CNN)。结果显示,CNN和LSTM在整体检测率上优于随机森林,但在个别DGA上表现不佳。检测率低或识别误差大的原因可能是数据不平衡和传统DGA与基于字典的DGA之间的样本分布偏差。Tran等人提出了改进的成本敏感的LSTM算法来解决DGA域名数据多类不平衡的问题,提高了准确率。
-
神经网络模型的比较:Vinayakumar等人比较了RNN、I-RNN、LSTM、CNN和CNN-LSTM等神经网络模型。结果显示,递归神经网络系列和混合网络(如CNN-LSTM)在检测率上表现优越。
-
深度学习方法的优势:深度学习方法具有捕获层次特征提取和序列输入中的长期依赖性的机制,这使得它们在DGA域名检测中表现出色。基于RNN的检测模型在高随机性DGA域名检测中准确率高,但在低随机性和基于字典的DGA域名识别率低,导致误报。因此,未来的主要发展方向是提高对低随机性和基于字典的DGA域名的识别能力。
GAN 在域名检测的应用
-
生成对抗网络(GAN)的基本概念:GAN是一种深度学习模型,它基于博弈论中的纳什均衡思想,通过生成器和鉴别器的相互学习来生成模拟数据。
-
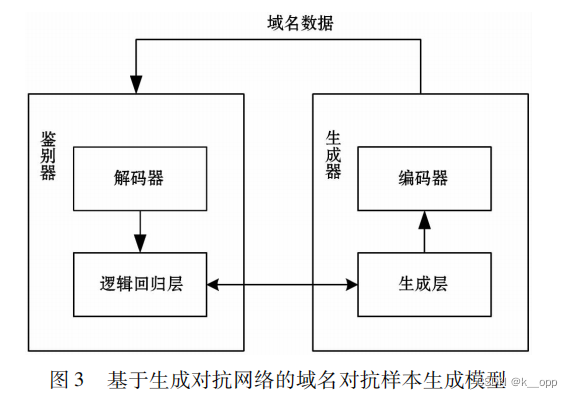
GAN在DGA域名生成中的应用:Anderson等人利用GAN的思想,构建了一种基于深度学习的DGA域名生成对抗样本方法。生成器学习生成越来越难以检测的域名,而检测器则通过更新参数提高检测能力。提出的GAN模型基于预先训练的自动编码器(编码器+解码器),自动编码器在Alexa的一百万个域名上进行训练,以生成更像真实域名的样本。然后,在GAN中重新组装编码器和解码器进行对抗训练。
-
对抗样本的验证:使用随机森林DGA分类器来验证生成的对抗样本的表现力,对抗样本表现良好,但实验对比较少,只验证了在随机森林模型上的检测效果。还有的采用了GAN的思想来生成恶意域名对抗样本,但编码器部分的设计有所不同,采用了基于Ascall编码方式的编解码器。
-
GAN的问题:GAN在处理离散数据(如序列数据)上存在问题,如生成器难以传递梯度更新,鉴别器难以评估完整的序列。因此由于域名数据的序列性,利用 GAN 生成域名数据应用上的研究较少。
-
GAN在僵尸网络检测中的应用:提出了一种基于GAN的僵尸网络检测增强框架,通过生成器连续生成“假”样本,扩展标记数量,以帮助原始模型进行僵尸网络检测和分类。
总结来说,这段话强调了GAN在域名检测领域的潜力,尤其是在生成对抗样本方面。然而,由于域名数据的序列性,GAN在这一领域的应用面临一些挑战。尽管如此,GAN在其他领域的成功应用表明,通过适当的改进和创新,GAN仍有可能在域名检测等领域发挥重要作用。
基于附加条件的深度学习方法的检测
-
深度学习检测方法的局限性:单纯的深度学习检测方法在应对越来越智能的DGA域名时表现不佳。
-
改进的LSTM模型:为了提高检测率,提出了结合注意机制的LSTM模型。该模型通过关注域名中更重要的子串来改善表达,尤其在检测长域名时表现出色,二元分类中的误报率和假负率分别降至1.29%和0.76%。
-
多字符随机性提取方法:提出了一种基于注意力机制的深度学习模型,并引入了一种多字符随机性提取方法,提高了识别低随机性DGA域名的有效性。
-
域名随机性的估计方法:通过词法分析和Web搜索来估计域名的随机性。但这种方法在处理短域名时存在局限性,可能会误判不包含在字典中的域名。
-
smash分数和新模型:提出了smash分数来评估DGA域名与英文单词的相似度,并设计了一种结合递归神经网络架构和域注册信息的新模型。该模型在检测某些看起来像自然域名的DGA家族时效果良好,但在检测那些看起来不像自然域名的DGA系列时表现不佳。
新的方向
这段话主要讨论了DGA(域名生成算法)域名变体的研究、恶意域名对抗样本的生成方法以及恶意域名检测模型的设计:
-
DGA域名变体的研究:DGA域名变体通常利用英语单词列表随机生成,以躲避基于字符特征的模型检测。尽管这些伪域名在马尔可夫模型或n-gram分布上与正常域名相似,但它们的长度和由几个无关单词拼凑的特点可以作为检测依据。通过观察这些域名可以看出域名的长度与正常域名相差较大,以及这些域名都是由几个毫无关联的单词拼凑而成,因此可以针对这两个角度对这类域名检测。
-
恶意域名对抗样本的生成方法:
- 一类生成方法是通过逆向工程破解DGA算法,但这种方法生成的域名具有固定模式,难以预测新的DGA变体。
- 另一类方法是使用生成对抗网络(GAN)生成对抗样本。文献[21]证明了GAN生成的对抗样本在模拟恶意域名数据和预测未知DGA家族方面有良好表现。然而,GAN在处理离散序列数据上存在挑战。
- 文献[50]提出的SeqGAN旨在解决GAN在离散数据处理上的问题,并在语言文本上表现不错。SeqGAN生成的域名对抗样本有望提高质量。
-
恶意域名检测模型的设计:
- 设计一个高效的检测模型是一个难点,因为伪域名越来越智能化,能够逃避一般神经网络模型的检测。
- 未来的发展方向包括设计既可以独立使用,也可以作为更大DGA检测系统一部分的模型,以及能够包含网络流量并应用于实时网络安全系统的模型。
[1]王媛媛,吴春江,刘启和,等.恶意域名检测研究与应用综述[J].计算机应用与软件,2019,36(09):310-316.