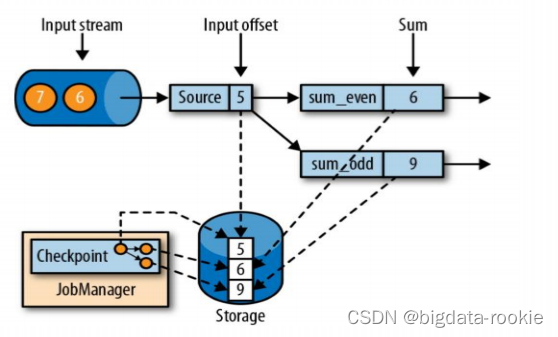
一致性检查点(checkpoint)
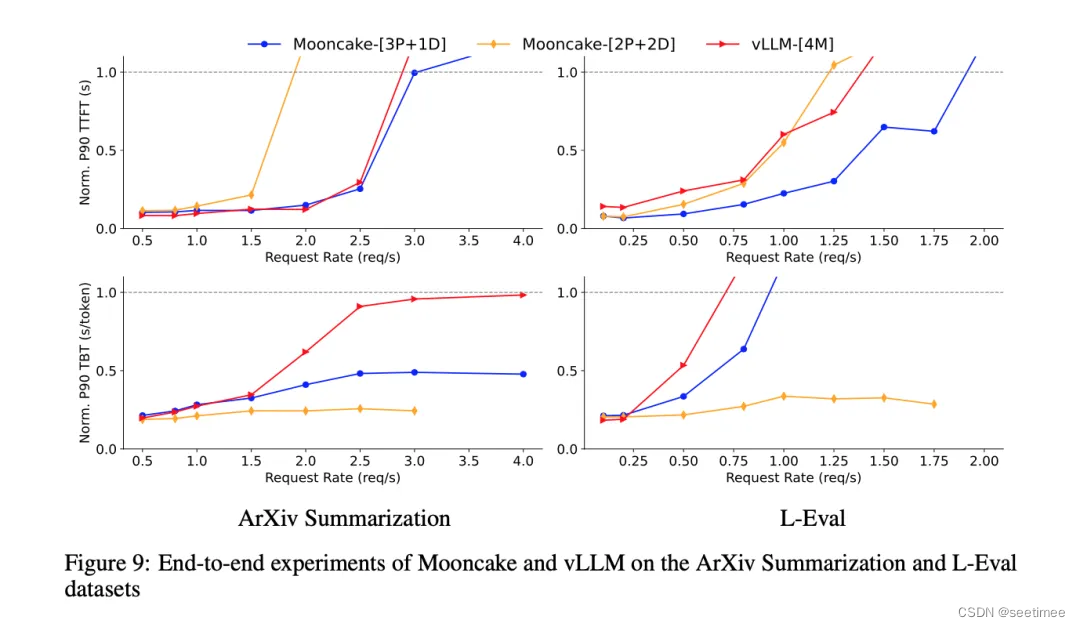
什么是 Checkpoint ?
- Flink 故障恢复机制的核心,就就是应用状态的一致性检查点;
- 有状态流应用的一直检查点,其实就是所有任务的状态,在某一时间点的一份拷贝(快照);这个时间点,应该是所有任务都恰好处理完一个相同的输入数据的时候;
Flink 做 checkpoint 时的具体过程
-
触发 checkpoint:
当 Flink 的 JobManager 发起一个 checkpoint 时,它会向所有的 TaskManager 发送一个 checkpoint barrier 。这个 barrier 包含全局唯一的 checkpoint ID; -
barrier 传播:
barrier 被插入到数据流中,它会随着数据流到达每一个算子实例。当一个算子接收到 barrier ,它会停止处理新的输入数据,直到所有的并行实例都接受到 barrier 并准备好进行 checkpoint; -
状态保存:
每个算子实例开始保存其当前的状态。状态会被序列化并通过网络传输到持久化的存储系统中,例如 HDFS; -
确认 checkpoint:
当所有算子实例完成状态保存并且确认状态已经被持久化后,它们会将确认消息发送回 JobManager 。JobManager 收集所有确认消息,一旦所有算子实例都确认了 checkpoint ,它就会标记 checkpoint 成功; -
清理失败的 checkpoint:
如果在 checkpoint 的过程中,任何一个算子实例失败或者超时没有响应,整个 checkpoint 将会被标记为失败。JobManager 会通知所有 TaskManager 清理失败的 checkpoint 相关的状态。并重新尝试下一个 checkpoint;
Flink 从 checkpoint 恢复时的具体过程
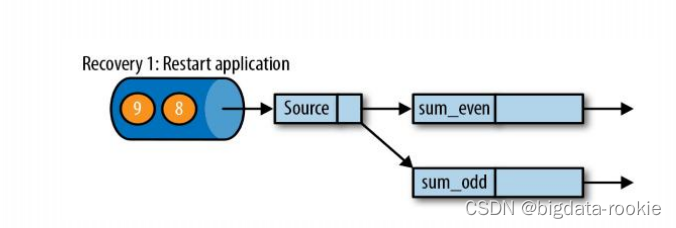
-
检查失败:
当 JobManager 或 TaskManager 发现某个任务失败时,它会触发恢复过程; -
选择 checkpoint:
JobManager 会选择一个最近的成功的 checkpoint 作为恢复点; -
恢复 TaskManager 状态:
Jobmanager 向失败的 TaskManager 发送恢复指令,指示它从特定的 checkpoint 恢复,TaskManager 接收到指令后,会加载对应的 checkpoint 的状态; -
重建拓扑和状态:
TaskManager 根据 checkpoint 中保存的状态重建任务的拓扑结构和状态。这意味着它会重新初始化所有算子实例,并从 checkpoint 加载状态数据; -
重放数据流:
一旦状态被恢复,TaskManager 开始重发数据流。对于有状态的算子,这意味着从 checkpoint 状态继续处理数据。对于无状态的算子,它们可以立即开始处理新的数据; -
确认恢复:
当所有失败的任务都被成功恢复后,JobManager 会确认恢复过程完成。此时,Flink 作业会从失败点继续运行,就像没发生过中断一样; -
更新状态后端:
在某些情况下,Flink 可能还需要更新状态后端的引用,确保所有任务指向最新的状态位置;