参考链接:霹雳吧啦b站
主要参考了b站霹雳吧啦的视频《深度学习目标检测篇》。
目录
- 前言
- YOLOv3
- 网络结构
- YOLOv3 SPP
前言
YOLOv3的精度虽然已经过时,但思想仍旧值得学习,本帖记录所需所想的一些内容。
YOLOv3
网络结构
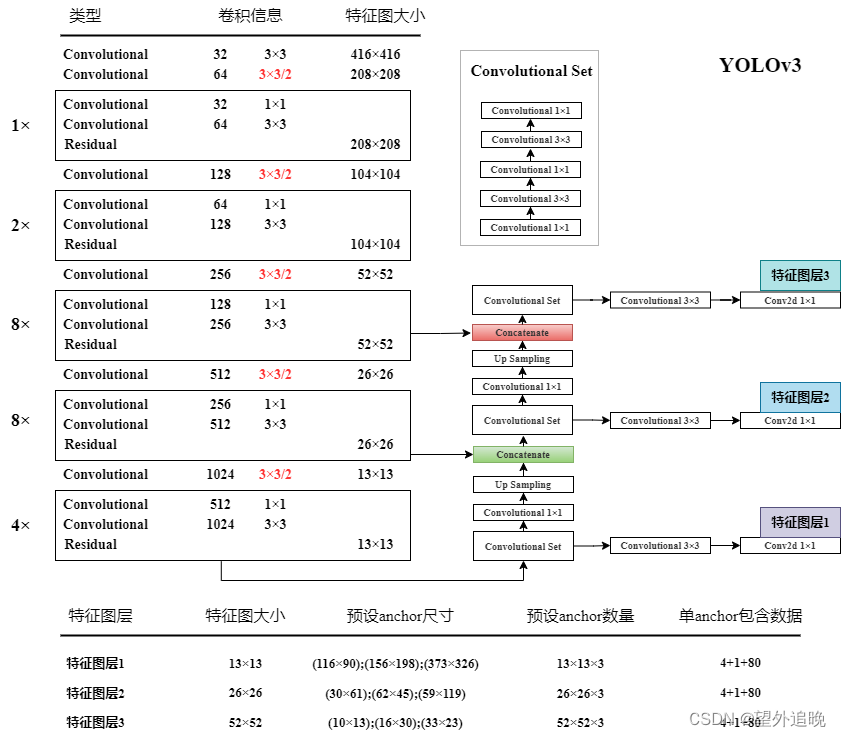
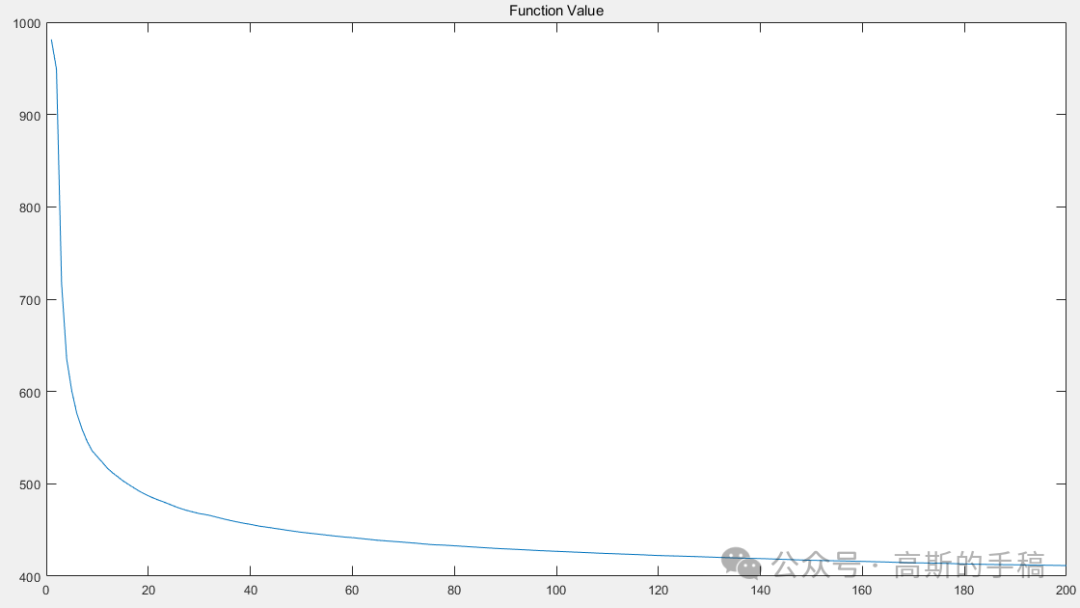
一共53层,利用了FPN特征金字塔结构,在不同的层进行预测,具体信息如图所示。
特征层预测目标框
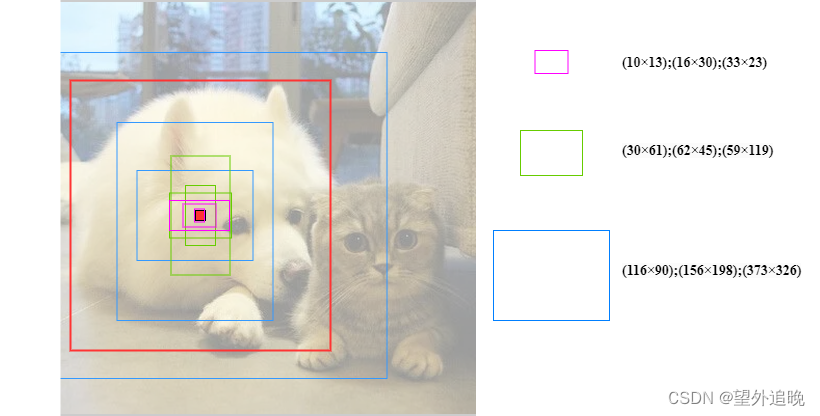
图中展示了
(
1
3
2
,
2
6
2
,
5
2
2
)
(13^2,26^2,52^2)
(132,262,522)三种特征图上的9种
anchor
\text{anchor}
anchor大小,红色为
GT
\text{GT}
GT框。一个
GT
\text{GT}
GT框由哪一个输出特征层进行预测,取决于当前层对应尺寸的
anchor
\text{anchor}
anchor与
GT
\text{GT}
GT的
IoU
\text{IoU}
IoU值,从图中可以看出,狗的目标框适合特征图层1(深层预测大目标)进行预测。
边界框预测回归
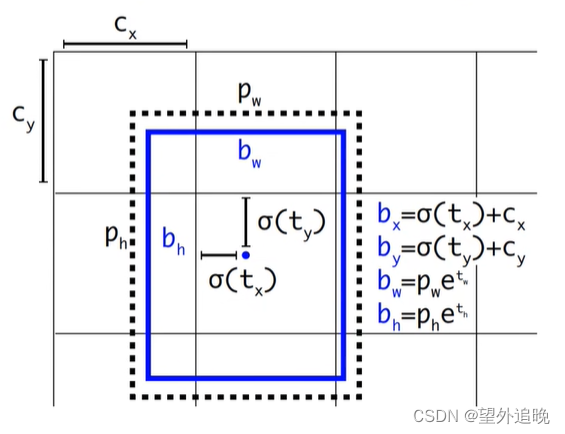
图中黑色的虚线框为
anchor
\text{anchor}
anchor模板,蓝色实线框为预测的目标框。
(
t
x
,
t
y
,
t
w
,
t
h
)
(t_x,t_y,t_w,t_h)
(tx,ty,tw,th)为
anchor
\text{anchor}
anchor预测的目标框的偏移量,利用这些偏移量我们最终可以得到预测的目标框的绝对坐标
(
b
x
,
b
y
,
b
w
,
b
h
)
(b_x,b_y,b_w,b_h)
(bx,by,bw,bh)。其中
σ
(
x
)
\sigma(x)
σ(x)是
sigmoid
\text{sigmoid}
sigmoid函数,目的是将预测的偏移量缩放至0-1之间(相对坐标),这样可以将每个Grid Cell中预测的目标框的中心坐标限制在当前Cell中,加速网络收敛。
问题
Q:anchor对应预测的目标框偏移量是怎样计算出来的?
A:偏移量是连同目标置信度以及类别置信度(4+1+80)一同被网络的最后一层输出直接预测得到的。
YOLOv3 SPP
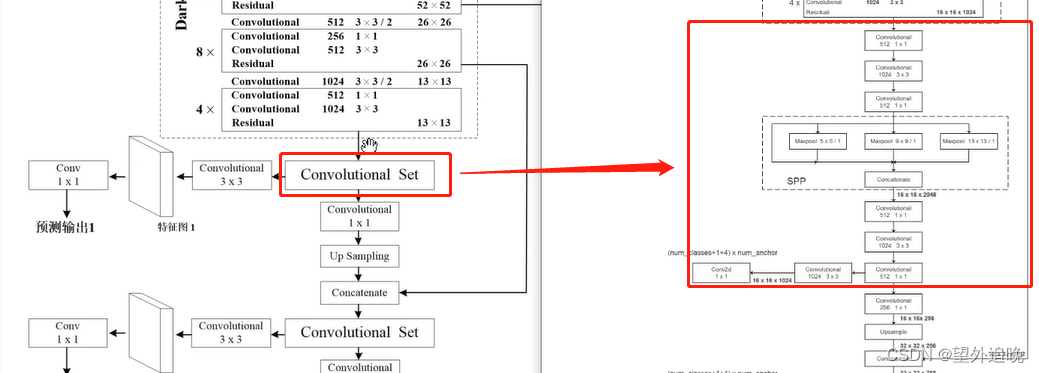
- mosaic数据增强:将多张图拼接到一张图上(label同步),增加了数据的多样性、目标个数(训练时增加了正样本个数),同时BN能一次性统计多张图片的参数。
正负样本匹配
- 假设 G T GT GT的中心点落在特征图的哪一个 c e l l cell cell内,哪一个 c e l l cell cell的3个 anchor \text{anchor} anchor就负责预测。首先一共会有 ( 16 × 16 + 32 × 32 + 64 × 64 ) × 3 = 16128 (16×16+32×32+64×64)×3=16128 (16×16+32×32+64×64)×3=16128个 anchor \text{anchor} anchor,即16128个样本。其中仅选取与 G T GT GT最大 I o U IoU IoU的 anchor \text{anchor} anchor当做正样本,又由于每个预测目标框根据计算的 I o U IoU IoU来确定由哪个尺度的特征图负责预测,则基本上相当于一个真实目标框对应一个正样本 anchor \text{anchor} anchor(由于 mosaic \text{mosaic} mosaic,单图目标数量还可以),所以一张图像的正样本一般只有十几个或几十个,而负样本大概有 1 0 4 − 1 0 5 10^4 - 10^5 104−105个。