废话不多说 直接上代码
import re
import os
import pymongo
import uuid
import bson
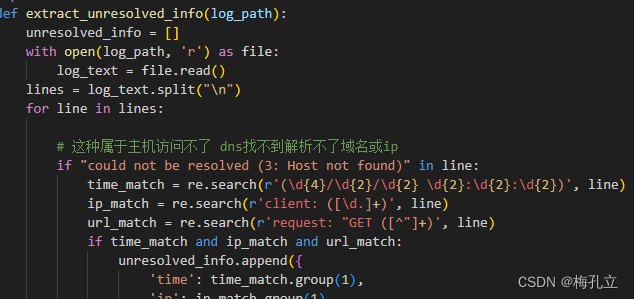
def extract_unresolved_info(log_path):
unresolved_info = []
with open(log_path, 'r') as file:
log_text = file.read()
lines = log_text.split("\n")
for line in lines:
# 这种属于主机访问不了 dns找不到解析不了域名或ip
if "could not be resolved (3: Host not found)" in line:
time_match = re.search(r'(\d{4}/\d{2}/\d{2} \d{2}:\d{2}:\d{2})', line)
ip_match = re.search(r'client: ([\d.]+)', line)
url_match = re.search(r'request: "GET ([^"]+)', line)
if time_match and ip_match and url_match:
unresolved_info.append({
'time': time_match.group(1),
'ip': ip_match.group(1),
'url': url_match.group(1).replace(" HTTP/1.1",""),
'type': '1'
})
# 这种属于域名或ip访问不了 请求对方失败超时了 dns是能解析域名或者ip的
if "upstream timed out (110: Connection timed out) while connecting to upstream" in line:
time_match = re.search(r'(\d{4}/\d{2}/\d{2} \d{2}:\d{2}:\d{2})', line)
ip_match = re.search(r'client: ([\d.]+)', line)
url_match = re.search(r'request: "GET ([^"]+)', line)
if time_match and ip_match and url_match:
unresolved_info.append({
'time': time_match.group(1),
'ip': ip_match.group(1),
'url': url_match.group(1).replace(" HTTP/1.1",""),
'type': '2'
})
# 清空日志内容
with open(log_path, 'w') as file:
file.write('')
return unresolved_info
# 连接 MongoDB 并存储数据
client = pymongo.MongoClient("mongodb://xxx:xxxx@127.0.0.1:27017/xxxxxx")
db = client["xxxxxx"] #数据库名称
collection = db["xxxxxx"] # 表名称
log_path = "/usr/local/nginx/logs/error.log" #nginx 日志分析日志地址
lists = extract_unresolved_info(log_path)
for line in lists:
# 这里插入id的时候使用 uuid并且是str类型 要不然删不了
line['_id'] = str(uuid.uuid4())
collection.insert_one(line)
# 插入完成后断开连接
client.close()
在这里插入代码片
然后就已经实现了获取日志 并且插入到mongodb里面啦