我们的BBF层很多时候会作为中间层处理后端到前端的数据,当然大部分时候都只是作为请求 / 响应的数据组装中心,但是有一个插件是怎么都绕不过去的:Log4js。
内部我们在Node层打印了很多日志。结果这周仔细分析了一下服务器处理请求到响应的中间耗时,发现log4js高居榜首。稍微有一点难蚌就是说。
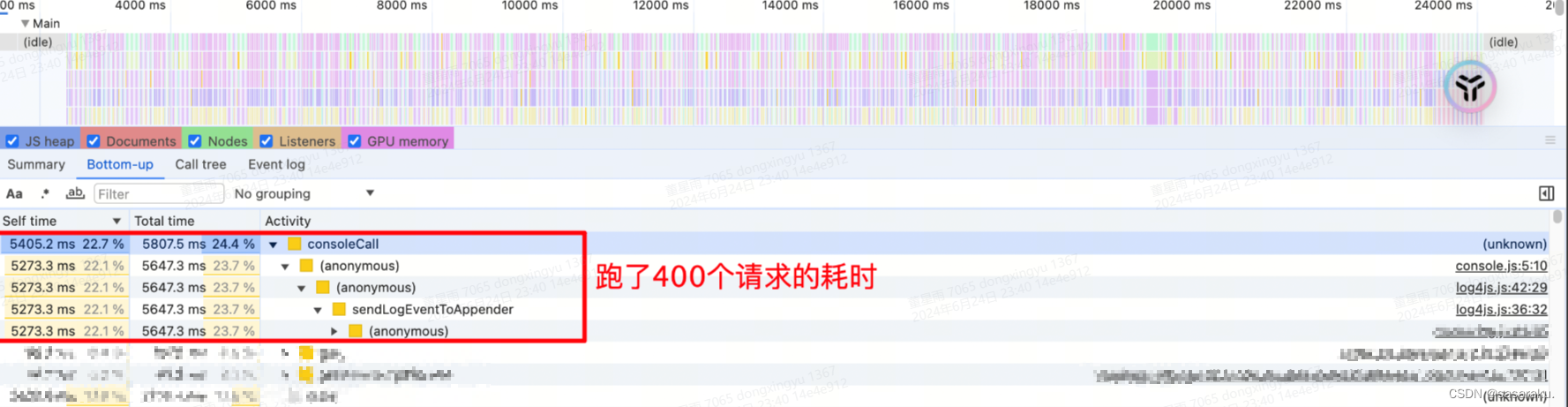
经过揣摩推测,可能是因为日志内容需要写入文件,其中存在IO开销,而且日志请求量很大,导致了程序阻塞。
方案一:批处理,批量写入
使用bufferSize属性,但是跑过命令后发现并没有明显改善,不知为何。

方案二:日志移交工作线程处理
使用worker_threads创建子线程,其实并没有做什么额外处理,只是子线程中初始化log4js的包,并且接收日志消息发送。
主线程中监听子线程的error / exit事件并且重启 / 错误处理。
大概如下:
// 主线程
const { Worker } = require('worker_threads');
const worker = new Worker(path.join(__dirname, '../worker/loggerWorker.js'));
worker.on('error', (err) => {
console.error('【logger worker error】', err);
});
// 工作线程结束时的相关处理
worker.on('exit', (code) => {
console.error(`【logger worker exit】${code}`);
if (code !== 0) {
// 异常退出
// 重试
} else {
// 正常退出
}
});
子线程loggerWorker
// loggerWorker.js
const { parentPort } = require('worker_threads');
const log4js = require('log4js');
// 配置 log4js
log4js.configure({
// ... 日志配置
});
// 使用 log4js 的 logger
const logger = log4js.getLogger();
// 接收来自主线程的消息
parentPort.on('message', (msg) => {
logger[msg.level] ('msg.data 要发送的消息')
});
工作线程的相关问题记录
1. worker_threads和child_process、cluster区别在哪里。
worker_threads、child_process 和 cluster 在 Node.js 中都提供了在多个 CPU 核心上运行代码的能力,但它们的工作方式和使用场景有所不同。
worker_threads
一般而言我们项目中使用的线程都是这个类型。
适合需要执行计算密集型任务且希望避免进程间通信开销的场景。
例如,在后台执行 CPU 密集型任务,或者在处理图像、执行大量的数学计算时,使用 worker_threads 可以在不同的线程中并行处理以提高效率。
worker_threads 模块允许 Node.js 程序创建一个工作线程池并分派任务给线程来执行。与 child_process 不同的是,worker_threads 使用同一进程的不同线程来运行代码,并且这些线程可以共享某些资源(例如 TypedArray 数据)。
child_process
child_process 模块允许 Node.js 程序异步地产生新的进程,并与它们进行通信。使用 child_process 可以执行系统命令、运行其他应用或者运行另外的 Node.js 进程。它适用于需要与操作系统交互或运行不同程序的场景。
常用于需要新的进程环境(例如执行不同程序或需要完全隔离的环境)的场景。例如,如果需要在 Node.js 应用程序中执行一个 Python 脚本,你可以使用 child_process.spawn 来启动一个新的 Python 进程并运行这个脚本。
child_process 提供了几种创建子进程的函数,包括:
exec:用于执行命令,缓冲输出到内存,适用于输出量不大的场合。spawn:用于执行命令,以流的形式提供输出,适用于输出量大的场合。execFile:类似exec,但直接执行文件而不是通过 shell,安全性更高。fork:专门用于运行 Node.js 模块,它在父子进程之间建立了一个通信管道,便于消息传递。
cluster
适用于希望扩展网络服务的性能的场景。
cluster 模块允许简单地创建共享单个服务器端口的 Node.js 进程的子进程(称为工作进程)。当 Node.js 运行在多核处理器的机器上时,使用 cluster 可以让不同的工作进程运行在不同的 CPU 核心上,从而更好地利用多核资源。
例如,如果你有一个Node.js的HTTP服务器,并且你想让它能够在多核服务器上运行,那么你可以使用 cluster 模块轻松地创建多个工作进程,每个进程都监听相同的端口,以便于分摊请求负载。
2. 使用worker_threads如何传递共享数据、如何资源上锁等处理。
Node.js中有几种方式来实现线程共享资源的保护和上锁,以及进程间共享资源的保护和上锁。
1. worker_threads
在使用worker_threads模块时,我们可以创建多线程,这些线程可以共享部分资源。例如,SharedArrayBuffer允许多个worker共享同一内存。然而,分享资源需要注意同步问题和并发访问问题。
为了保护共享资源,可以使用Atomics API来进行上锁和同步操作。Atomics提供了一系列原子操作来确保在多个线程读写共享内存时的正确性。使用原子操作可以确保一个时间点只有一个线程在修改共享资源,这样可以防止竞态条件和数据不一致。
-
workerData
可以在初始化创建线程时传入,工作线程通过引入workerData对象拿到传递的数据使用。(类似环境变量?) -
SharedArrayBuffer:
在worker中创建一个可以被多个线程共享的内存区域。通过使用SharedArrayBuffer和类型化数组(Int32Array)来实现的。
SharedArrayBuffer(4)代表了一个可以在多个线程之间共享的固定大小的二进制数据缓存区。这个共享内存buffer的大小是4字节。SharedArrayBuffer不能直接读写,而是需要通过类型化数组或者DataView对象来操作其中的数据。 -
Int32Array
Int32Array会把之前创建的共享内存buffer作为底层存储结构。它是一种类型化数组,用于表示一个32位整数数组。由于每个Int32元素占用4字节,共享内存也只有4字节,因此这个特定的Int32Array只能包含一个整数元素。
可以在一个worker线程中修改sharedArray中的元素,然后该修改会立即对主线程或其他worker线程可见。这允许多个线程能够同时读写相同的数据,从而实现了线程间的并发操作。
- Atomics
Atomics是一个全局对象,提供了一组静态方法来进行原子操作。这些方法可以在SharedArrayBuffer的视图(如Int8Array,Uint8Array,Int16Array,Uint16Array,Int32Array等)上执行,确保了在多线程环境中对共享内存的读写操作是原子性的,也就是说,这些操作是不可中断的,保证了线程安全。
-
Atomics.add(typedArray, index, value)
对位于typedArray[index]的元素执行原子加法操作。 -
Atomics.load(typedArray, index)
对位于typedArray[index]的元素执行原子读取操作。 -
Atomics.store(typedArray, index, value)
对位于typedArray[index]的元素执行原子存储操作。 -
Atomics.exchange(typedArray, index, value)
对位于typedArray[index]的元素执行原子交换操作。
const { Worker, isMainThread, parentPort, WorkerData, Atomics, SharedArrayBuffer } = require('worker_threads');
// 主线程
const sharedBuffer = new SharedArrayBuffer(4); // 创建一个共享内存Buffer
const sharedArray = new Int32Array(sharedBuffer); // 创建TypedArray来操作共享内存
const worker = new Worker(__filename, {
workerData: sharedBuffer
});
Atomics.store(sharedArray, 0, 1); // 在位置0写入1
console.log('The initial value is:', Atomics.load(sharedArray, 0));
worker.on('message', () => {
console.log('The value now is:', Atomics.load(sharedArray, 0));
});
// 子线程
const { workerData } = require('worker_threads');
const sharedArray = new Int32Array(workerData);
Atomics.add(sharedCArray, 0, 1); // 原子操作添加
parentPort.postMessage('Worker completed');
2. cluster
当使用cluster模块时,主进程可以创建多个工作进程,这些工作进程可以共享同一个TCP服务器绑定的端口。但是,工作进程之间的内存资源是隔离的,他们无法直接共享内存资源。
进程间通信(IPC)通常是通过父进程与子进程之间传递消息来实现的。如果需要在多个工作进程之间共享资源,通常是通过外部的存储(例如Redis、数据库等)来实现的。
// 在 cluster 模式下使用消息传递示例
const cluster = require('cluster');
const http = require('http');
const numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
console.log(`Master ${process.pid} is running`);
// 添加需要共享的资源
let sharedResource = { ... };
// Fork workers.
for (let i = 0; i < numCPUs; i++) {
const worker = cluster.fork();
// 发送共享资源给每个worker
worker.send({ sharedResource });
}
cluster.on('exit', (worker, code, signal) => {
console.log(`worker ${worker.process.pid} died`);
});
} else {
process.on('message', (msg) => {
// 接收共享资源
console.log('Worker received message:', msg);
});
http.createServer((req, res) => {
res.writeHead(200);
res.end('hello world\n');
}).listen(8000);
console.log(`Worker ${process.pid} started`);
}
3. child_process
child_process模块允许你创建子进程,并与之通信。与cluster模块类似,子进程的内存也是隔离的,资源共享需要通过IPC来实现。
你可以使用child_process.fork()来创建子进程,并通过process.send()和child.on('message', callback)进行父子进程间通讯。
总结
在Node.js中,实现不同线程或进程间的资源共享和上锁,通常需要针对场景选择合适的机制。worker_threads提供了共享内存和原子操作,而cluster和child_process主要依靠消息传递和外部存储解决资源共享问题。记住多线程和多进程编程都需要考虑同步和竞态条件等问题,合理设计代码以确保线程安全和数据的一臀性。