前言
随着大数据时代的到来,处理和分析海量数据已成为企业和科研机构不可或缺的能力。Hadoop,作为开源的分布式计算平台,因其强大的数据处理能力和良好的可扩展性,成为大数据处理领域的佼佼者。本图文教程旨在帮助读者理解Hadoop集群的安装过程,并通过MapReduce应用实例,深入体验Hadoop在大数据处理中的强大功能。
在正式进入Hadoop集群安装之前,我们将简要介绍Hadoop的核心组件——HDFS(Hadoop Distributed File System)和MapReduce。HDFS提供了分布式存储能力,使得数据可以存储在集群中的多个节点上,从而实现高容错性和高吞吐量。而MapReduce则是一种编程模型,用于处理大规模数据集,其独特的“Map”和“Reduce”两个阶段使得数据处理任务可以并行执行,大大提高了处理效率。
通过本教程的学习,读者将能够掌握Hadoop集群的搭建方法,理解MapReduce编程模型的基本原理,并通过实际案例体验Hadoop在大数据处理中的强大能力。
安装OpenEuler系统
选择Installer oenEuler 20.03-LTS
选择默认磁盘分区

配置网络

选择ipv4 setting
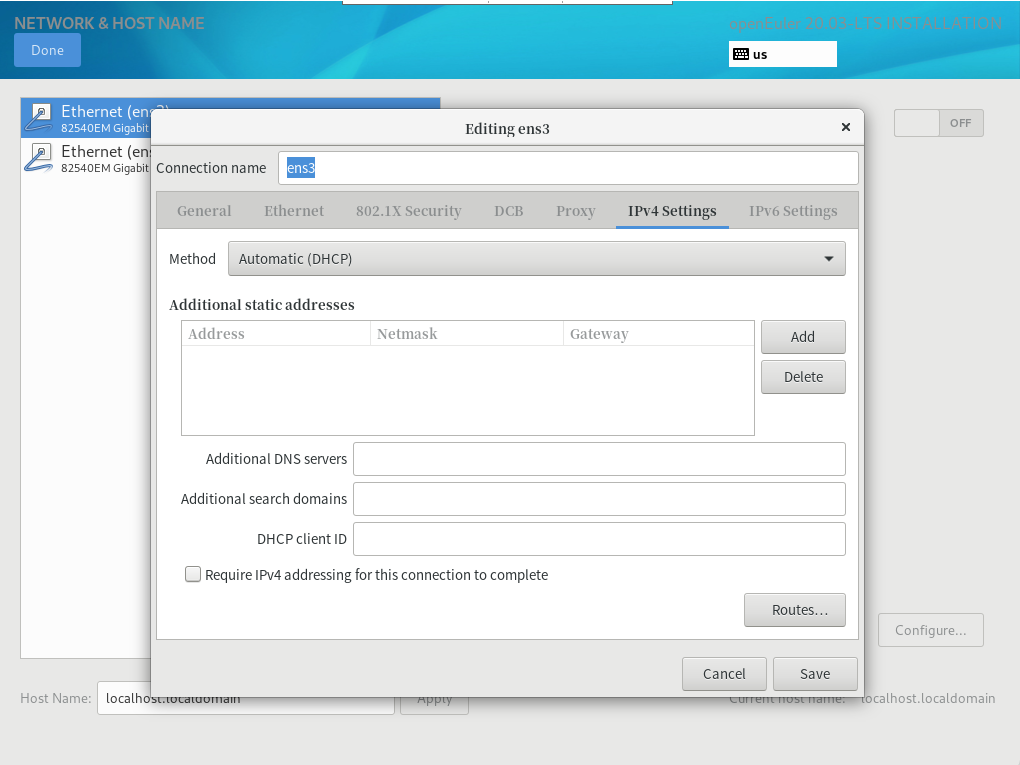
填写IP地址(手动配置地址必须遵守Vmware WorkStation的基本配置)

查看地址配置信息
开始安装
配置root账户密码
置root账户密码
通过此部署依次部署4台,并通过ssh登录
为每一台配置yum源地址
cd /etc/yum.repos.d/
vi openEulerOS.repo
![]()
配置华为Yum源地址。
[openEuler-source]
name=openEuler-source
baseurl=https://repo.huaweicloud.com/openeuler/openEuler-20.03-LTS/source/
enabled=1
gpgcheck=1
gpgkey=https://repo.huaweicloud.com/openeuler/openEuler-20.03-LTS/source/RPM-GPG-KEY-openEuler
[openEuler-os]
name=openEuler-os
baseurl=https://repo.huaweicloud.com/openeuler/openEuler-20.03-LTS/OS/x86_64/
enabled=1
gpgcheck=1
gpgkey=https://repo.huaweicloud.com/openeuler/openEuler-20.03-LTS/OS/x86_64/RPM-GPG-KEY-openEuler
[openEuler-everything]
name=openEuler-everything
baseurl=https://repo.huaweicloud.com/openeuler/openEuler-20.03-LTS/everything/x86_64/
enabled=1
gpgcheck=1
gpgkey=https://repo.huaweicloud.com/openeuler/openEuler-20.03-LTS/everything/x86_64/RPM-GPG-KEY-openEuler
[openEuler-EPOL]
name=openEuler-epol
baseurl=https://repo.huaweicloud.com/openeuler/openEuler-20.03-LTS/EPOL/x86_64/
enabled=1
gpgcheck=0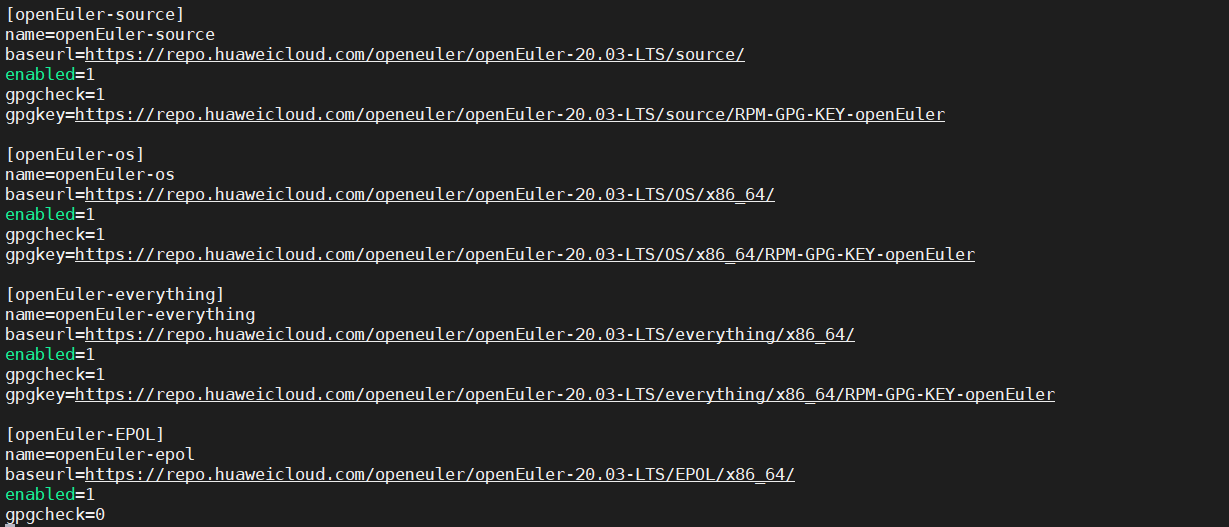
清楚现有并生成新的缓存

安装实验所需工具 vim tar (4台都安装)
yum install -y vim tar
基础配置
此部分配置Hadoop各节点使其符合软件安装的要求,内容比较多,除了教程中给出的步骤,如果是物理服务器等需要另外设置时间同步,因为华为云已经同步了时间,所以此处不加上相应的配置过程,如感兴趣,请自行查资料完成。下面操作以node01为例,进行相应的配置
1.1.1.1 修改主机名
注意:如果主机名不是对应的node01、node2、node3、node4,则需要分别将四个节点的主机名进行修改,四台均需要修改,此处以node01为例子。如果你在购买的时候已经设置好主机名,则不需要修改,可忽略此步骤。
方式一:使用hostname命令,直接命名主机名(但是此种设置重启后会变回原来的,可不操作):
> hostname node01
> bash方式二:修改/etc/hostname文件(修改好后重启,发生修改已生效):
> vim /etc/hostname# 修改完毕后,效果如下:
> cat /etc/hostname
node01
> reboot方式三(统一采用这种):此外,还有一种更加简便的办法,直接执行后就可以了,不需要重启:
> hostnamectl set-hostname node01
> bash以下是修改结果:



步骤 1 修改hosts配置文件
使用命令vim /etc/hosts,为node01-4四个节点增加内网IP与节点主机名的映射,确保各节点之间可以使用主机名作为通信的方式。
> vim /etc/hosts
# 需删除自己的主机名映射到127.0.0.1的映射,如node01为:
127.0.0.1 node01 node01
此行务必删除!
# 加入以下内容如下:(注意IP地址必须是自己的IP地址)
192.168.28.31 node01
192.168.28.32 node02
192.168.28.33 node03
192.168.28.34 node04呈现结果如下:




1.1.1.2 关闭防火墙
执行下面命令查看防火墙状态:
> systemctl status firewalld
如果发现默认是已经禁用的,所以不需要关闭了。如果是开启的,则需要在node01-4四个节点执行如下命令关闭防火墙:
> systemctl stop firewalld
> systemctl disable firewalld4个节点均执行此命令:




1.1.1.3 配置ssh互信
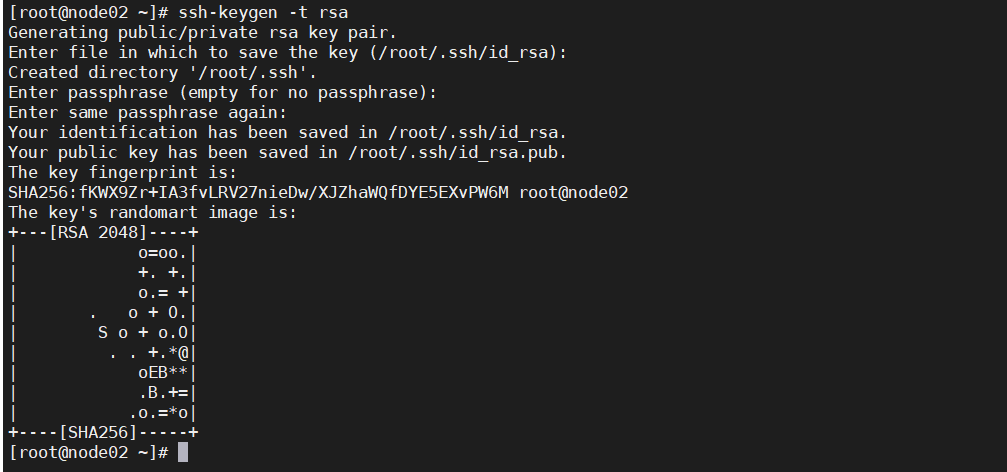
步骤 1 生成id_rsa.pub 文件
各节点执行 ssh-keygen -t rsa 命令后,连续回车三次后生成/root/.ssh/id_rsa.pub 文件



步骤 1 汇总id_rsa.pub
各个节点执行cat /root/.ssh/id_rsa.pub命令,我们需要将密钥进行汇总,思路是先将node2、node3、node4的密钥拷贝到node01,在node01进行汇总,然后将汇总好的文件分发到node2、node3、node4,这样的话,每个节点就有了彼此的密钥,达到互相免密码登录的效果。
将node2的密钥拷贝到node01(在node2执行):
> scp ~/.ssh/id_rsa.pub root@node01:~/.ssh/id2执行的时候可能输入“yes”,并且需要输入node01的服务器密码。

将node3的密钥拷贝到node01(在node3执行):
> scp ~/.ssh/id_rsa.pub root@node01:~/.ssh/id3执行的时候可能输入“yes”,并且需要输入node01的服务器密码。

将node4的密钥拷贝到node01(在node4执行):
> scp ~/.ssh/id_rsa.pub root@node01:~/.ssh/id4执行的时候可能输入“yes”,并且需要输入node01的服务器密码。

查看一下是否拷贝完成(在node01执行):
> ll ~/.ssh发现node2、node3、node4的密钥都拷贝到node01上了:

继续进行汇总:
> cd ~/.ssh
> cat id2 id3 id4 >> authorized_keys
此外,还要将node01的密钥也放进去:
> cat id_rsa.pub >> authorized_keys
查看汇总后的文件authorized_keys,发现已经有四台机器的密钥了:
> cat authorized_keys
最后,需要将此文件分发到node02、node03、node04:
> scp authorized_keys root@node02:~/.ssh/
> scp authorized_keys root@node03:~/.ssh/
> scp authorized_keys root@node04:~/.ssh/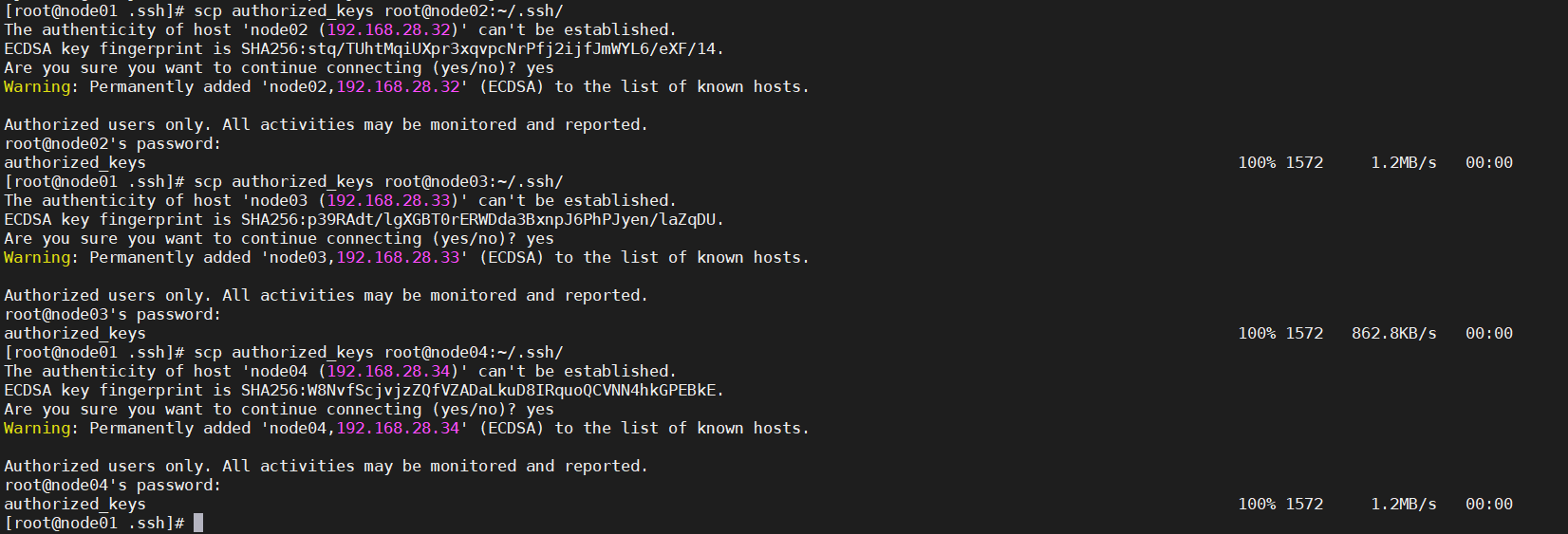
步骤 1 验证测试
每个节点分别 ssh node01~node4,选择 yes 后,确保能够互相免密码登录。
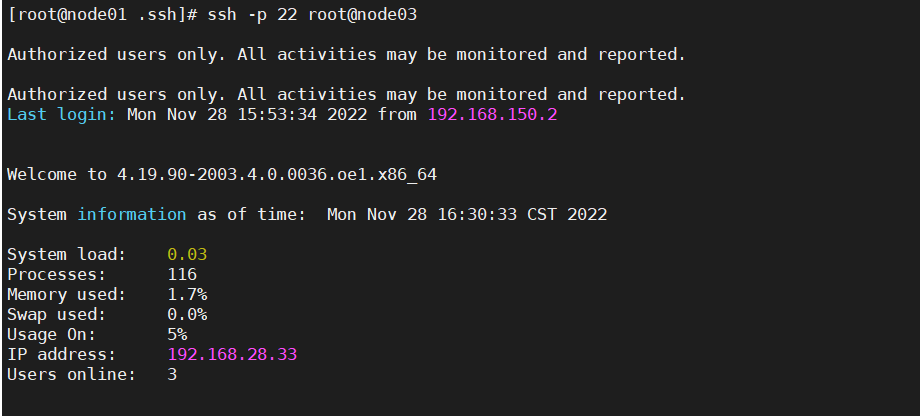
两两相互测试
步骤 1 安装JDK,在 node01~node04
1. 下载jdk8,或者通过上传本地安装文件
> wget https://mirrors.huaweicloud.com/java/jdk/8u192-b12/jdk-8u192-linux-x64.tar.gz (此次演示node01,02-04都需要执行)
(此次演示node01,02-04都需要执行)
2. 解压jdk
> mkdir –p /usr/lib/jvm/
> tar -zxvf jdk-8u192-linux-x64.tar.gz -C /usr/lib/jvm/
> mv /usr/lib/jvm/jdk1.8.0_192 /usr/lib/jvm/java![]()

3. 配置环境变量
执行指令vim /etc/profile,编辑环境变量文件,在文件末尾添加下面内容
> vim /etc/profile
export JAVA_HOME=/usr/lib/jvm/java
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:%JAVA_HOME%/lib/dt.jar:%JAVA_HOME%/lib/tools.jar示例子如下:
![]()
使环境变量生效
> source /etc/profile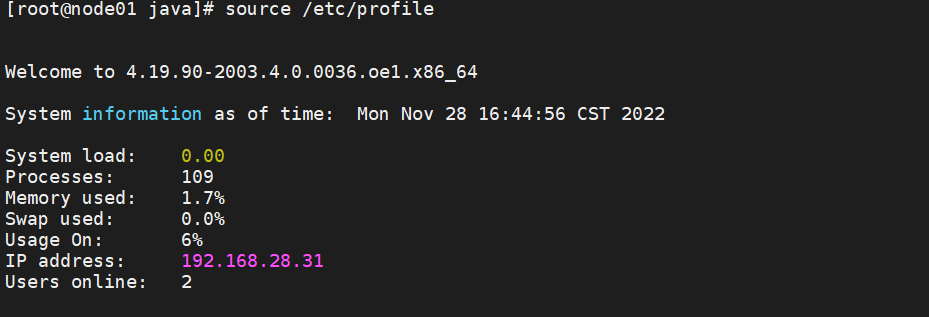
5. 验证java环境
> java –version
出现以下信息表示jdk安装成功
java version "1.8.0_192"
Java(TM) SE Runtime Environment (build 1.8.0_192-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.192-b12, mixed mode)




上面验证通过,下面的步骤可以不用执行
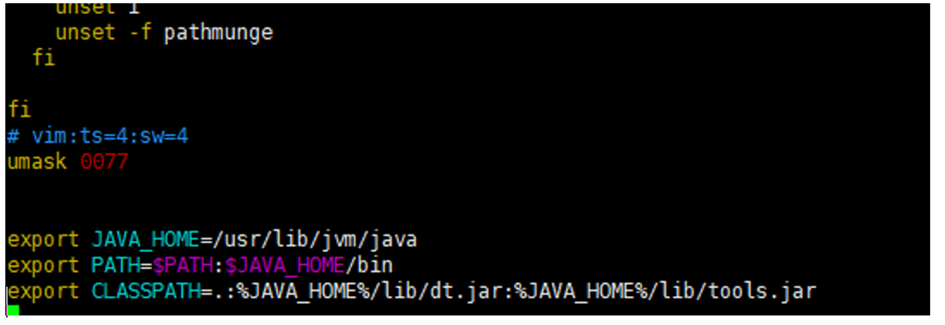
6. 环境变量拷至bashrc文件,使每次打开shell都生效,编辑/etc/bashrc,在文件末尾添加下面内容 (可选)
>vim /etc/bashrc
export JAVA_HOME=/usr/lib/jvm/java
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:%JAVA_HOME%/lib/dt.jar:%JAVA_HOME%/lib/tools.jar
1.1.1.4 创建必要的目录
> mkdir -p /home/modules/data/buf/
> mkdir -p /home/test_tools/
> mkdir -p /home/nm/localdir
注意:四台服务器都需要操作。
1.2.1 下载软件包
步骤 1 获取Hadoop软件包
在node01找到下载好的Hadoop软件包,放到home目录,或者从本地上传安装文件
> wget https://archive.apache.org/dist/hadoop/common/hadoop-2.8.3/hadoop-2.8.3.tar.gz

1.2.1 搭建Hadoop集群
1.2.1.1 查看解压目录
在node01上准备hadoop组件
> tar -zxvf hadoop-2.8.3.tar.gz -C /home/modules
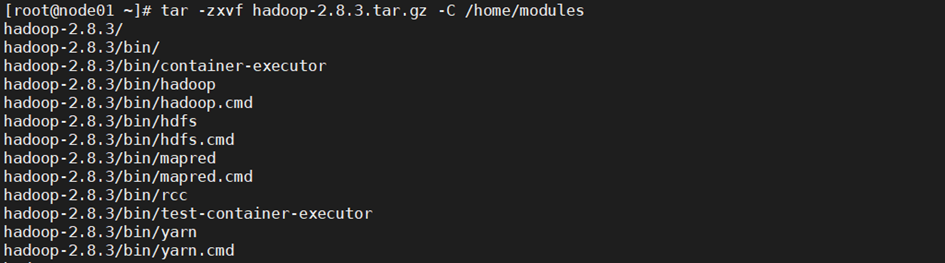
> ls /home/modules/ | grep hadoop
hadoop-2.8.3

1.2.1.2 修改配置文件
步骤 1 配置hadoop-env.sh
在node010上执行命令:
> vim /home/modules/hadoop-2.8.3/etc/hadoop/hadoop-env.sh
修改JAVA_HOME路径为ECS已经默认装好了JDK路径
export
=/usr/lib/jvm/java

步骤 1 预配置core-site.xml
在node01上执行命令+
> vim /home/modules/hadoop-2.8.3/etc/hadoop/core-site.xml
在<configuration>与</configuration>之间填入以下内容,此为预配置,后期还要再修改,注意涉及到的主机名如果不同需要根据具体情况修改:
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/modules/hadoop-2.8.3/tmp</value>
</property>
<property>
<name>fs.obs.buffer.dir</name>
<value>/home/modules/data/buf</value>
</property>
<property>
<name>fs.obs.readahead.inputstream.enabled</name>
<value>true</value>
</property>
<property>
<name>fs.obs.buffer.max.range</name>
<value>6291456</value>
</property>
<property>
<name>fs.obs.buffer.part.size</name>
<value>2097152</value>
</property>
<property>
<name>fs.obs.threads.read.core</name>
<value>500</value>
</property>
<property>
<name>fs.obs.threads.read.max</name>
<value>1000</value>
</property>
<property>
<name>fs.obs.write.buffer.size</name>
<value>8192</value>
</property>
<property>
<name>fs.obs.read.buffer.size</name>
<value>8192</value>
</property>
<property>
<name>fs.obs.connection.maximum</name>
<value>1000</value>
</property>
<property>
<name>fs.obs.impl</name>
<value>org.apache.hadoop.fs.obs.OBSFileSystem</value>
</property>
<property>
<name>fs.obs.connection.ssl.enabled</name>
<value>false</value>
</property>
<property>
<name>fs.obs.fast.upload</name>
<value>true</value>
</property>
<property>
<name>fs.obs.socket.send.buffer</name>
<value>65536</value>
</property>
<property>
<name>fs.obs.socket.recv.buffer</name>
<value>65536</value>
</property>
<property>
<name>fs.obs.max.total.tasks</name>
<value>20</value>
</property>
<property>
<name>fs.obs.threads.max</name>
<value>20</value>
</property>效果如下:
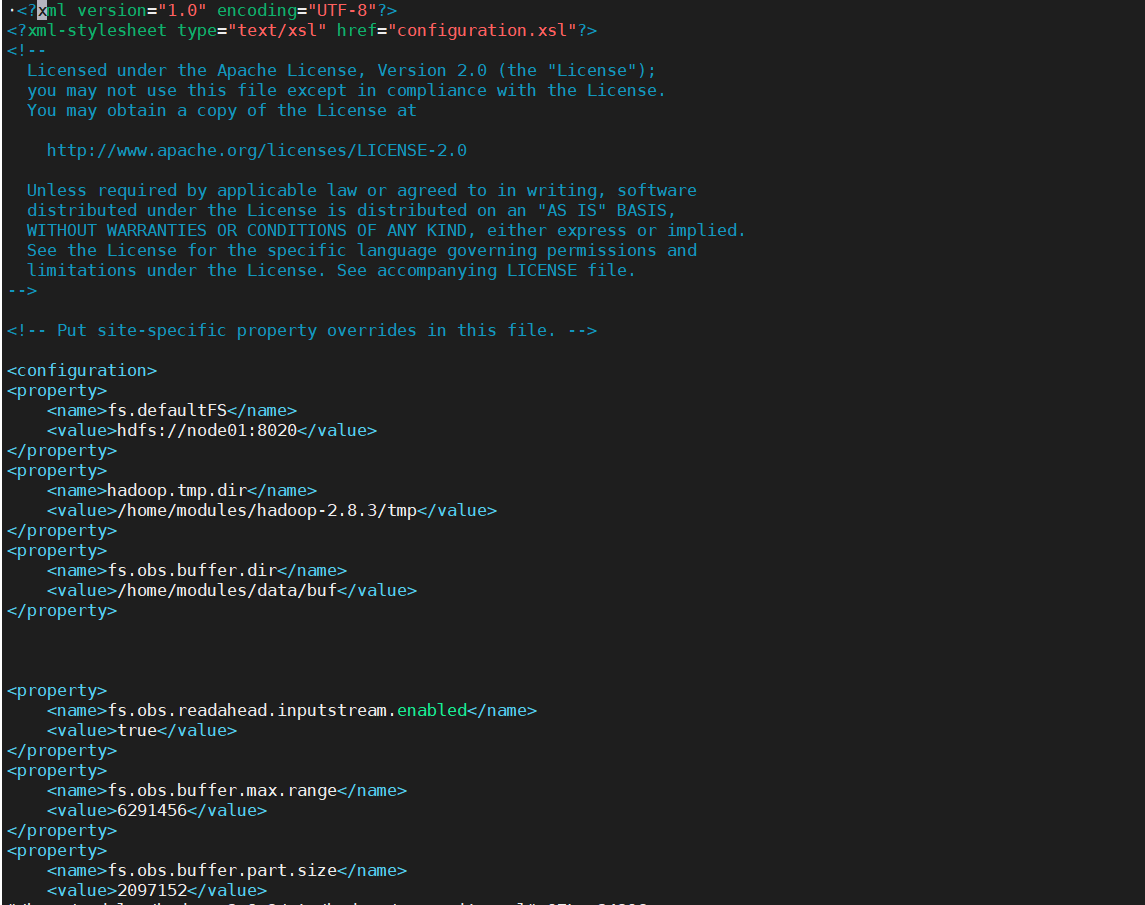
1.2.1.3 配置hdfs-site.xml
在node01上执行命令
> vim /home/modules/hadoop-2.8.3/etc/hadoop/hdfs-site.xml
在<configuration>与</configuration>之间内容替换如下:
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:50090</value>
</property>
<property>
<name>dfs.namenode.secondary.https-address</name>
<value>node01:50091</value>
</property>![]()

1.2.1.4 配置yarn-site.xml
在node01上执行命令
> vim /home/modules/hadoop-2.8.3/etc/hadoop/yarn-site.xml
在<configuration>与</configuration>之间内容替换如下:
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
<description>表示ResourceManager安装的主机</description>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>node01:8032</value>
<description>表示ResourceManager监听的端口</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>为map reduce应用打开shuffle 服务</description>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/home/nm/localdir</value>
<description>表示nodeManager中间数据存放的地方</description>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>3072</value>
<description>表示这个NodeManager管理的内存大小</description>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>2</value>
<description>表示这个NodeManager管理的cpu个数</description>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
<description>不检查每个任务的物理内存量</description>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>不检查每个任务的虚拟内存量</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>为map reduce应用打开shuffle 服务</description>
</property>![]()

1.2.1.5 配置mapred-site.xml
在node01上执行命令:
> cp /home/modules/hadoop-2.8.3/etc/hadoop/mapred-site.xml.template /home/modules/hadoop-2.8.3/etc/hadoop/mapred-site.xml![]()
然后编辑复制出来的配置文件:
vim /home/modules/hadoop-2.8.3/etc/hadoop/mapred-site.xml
在<configuration>与</configuration>之间内容替换如下:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
<property>
<name>mapred.task.timeout</name>
<value>1800000</value>
</property>
1.2.1.6 配置slaves
在node01节点配置从节点,删掉里面的localhost,配置上从节点(node02、node03、node04)
> vim /home/modules/hadoop-2.8.3/etc/hadoop/slaves
# 删掉里面的localhost,添加以下内容
node02
node03
node04
1.2.1.7 分发组件
在 node01 执行如下命令,将 hadoop-2.8.3 目录拷贝到其他各个节点的/home/modules/下
> for i in {02..04};do scp -r /home/modules/hadoop-2.8.3 root@node${i}:/home/modules/;done
二选一
scp -r /home/modules/hadoop-2.8.3 root@node02:/home/modules/
scp -r /home/modules/hadoop-2.8.3 root@node03:/home/modules/
scp -r /home/modules/hadoop-2.8.3 root@node04:/home/modules/
等待几分钟拷贝完毕后,在 node02~node04 节点执行如下命令检查是否复制成功
> ls /home/modules/ | grep hadoop


1.2.1.8 添加并校验环境变量
在 node01~node04,执行下面命令添加环境变量:
> vim /etc/profile
# 添加内容为:
export HADOOP_HOME=/home/modules/hadoop-2.8.3
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HADOOP_CLASSPATH=/home/modules/hadoop-2.8.3/share/hadoop/tools/lib/*:$HADOOP_CLASSPATH注意:请在末尾添加!
在 node01~node4,执行如下命令,使环境变量生效:
> source /etc/profile
此处以node01为例子
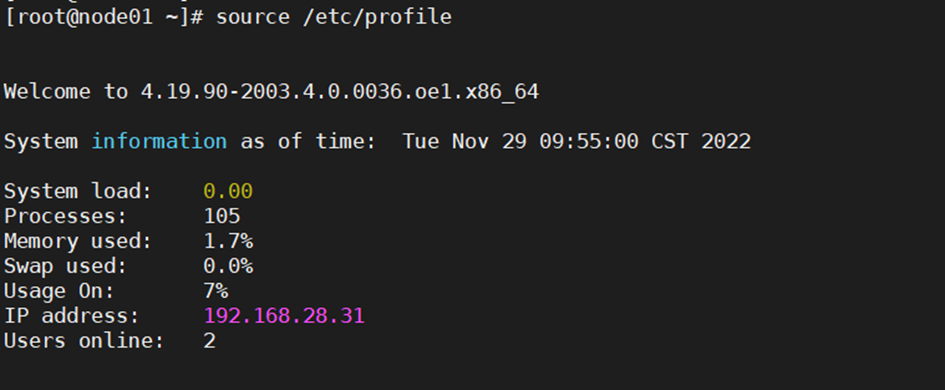
在 node01~node4,执行如下命令,校验环境变量:
> echo $HADOOP_HOME
显示如下内容则为配置正确:

1.2.1.9 初始化namenode
在 node01上执行如下命令,初始化 Namenode:
> hdfs namenode -format

1.3.1 启动Hadoop集群
步骤 1 在node01节点执行以下命令:
> start-dfs.sh ; start-yarn.sh
返回信息中有以下内容,表示hadoop集群启动成功:
Starting namenodes on [node01]
Starting secondary namenodes [node01]
starting yarn daemonshi
1.3.2 验证Hadoop状态
步骤 1 使用jps命令在node01-4中查看Java进程
在node01中可以查看到 NameNode,SecondaryNameNode,ResourceManager
进程,在node2-4中可以查看到 NodeManager 和 Datanode 进程,表示hadoop集群状态正常。
> jps
1538 WrapperSimpleApp
5732 SecondaryNameNode
5508 NameNode
6205 Jps
5918 ResourceManager

> jps
3026 Jps
2740 DataNode
1515 WrapperSimpleApp
2862 NodeManager
步骤 3 访问,可以登录Namenode的Web界面:
http://namenodeip:50070
访问Yran界面:

1.4.1 使用Hadoop统计以下表格人名字的出现次数
首先找到hadoop自带worldcount jar包示例的路径
创建数据文件夹,以及输出文件夹

编辑输入数据:
![]()
具体输入的数据听从老师安排

将本地准备的输入文件上传到hdfs中:
![]()
查看文件

执行MapReduce
hadoop jar hadoop-mapreduce-examples-2.8.3.jar wordcount /data/wordcount /output/wordcountresult
查看结果:jps
hadoop fs -text /output/wordcountresult/part-r-00000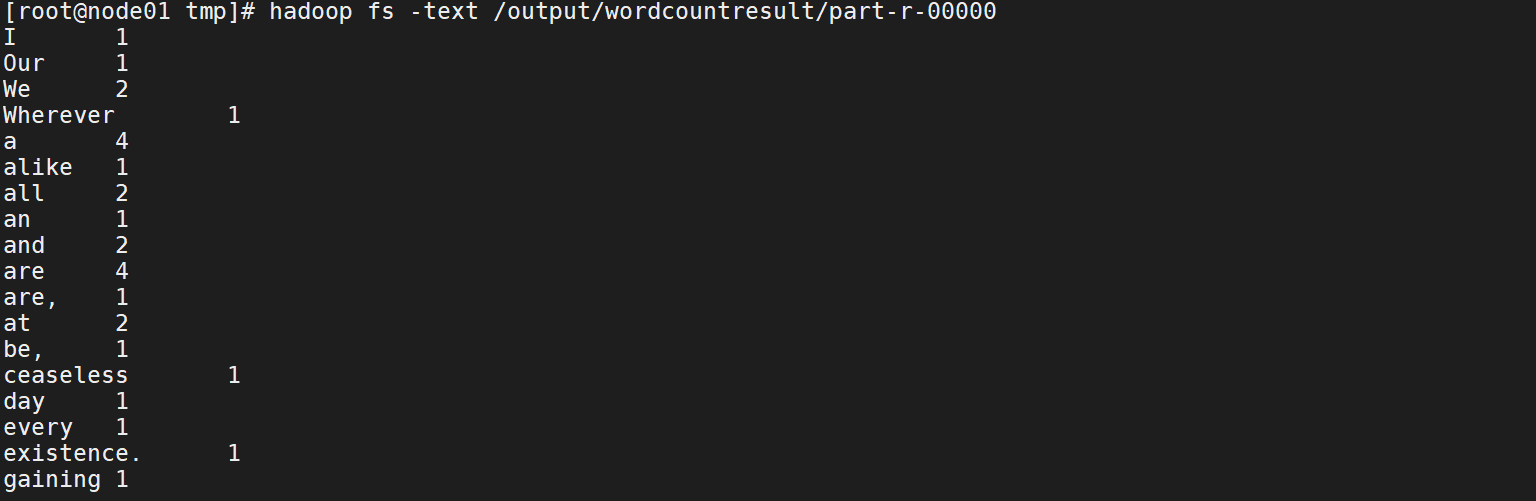
结尾
经过前面的学习,相信读者已经对Hadoop集群的安装和MapReduce应用有了深入的了解。Hadoop作为一个开源的分布式计算平台,为大数据处理提供了强大的支持。通过本教程的学习,读者可以搭建起自己的Hadoop集群,并尝试使用MapReduce处理大规模数据集。当然,Hadoop的功能远不止于此,它还有更多的高级特性和应用场景等待我们去探索。希望本教程能够为您在大数据处理领域的学习和实践提供一些帮助。