文章目录
- 前言:
- 今日所学:
- 1. Common Transforms
- 2. Vision Transforms
- 3. Text Transforms
前言:
我们知道在进行神经网络训练的时候,通常要将原始数据进行一系列的数据预处理操作才会进行训练,所以MindSpore提供了不同类型的数据变换方式。本节主要通过了对mindspore.dataset所提供的不同类型的Transforms进行了数据变换的讲解。
其中包括了Common Transforms、Vision Transforms、Text Transforms这三个主要部分,分别讲述了这些的Transformers的知识以及应用。我所学到的内容如以下笔记所示:
今日所学:
1. Common Transforms
mindspore.dataset.transforms模块支持一系列通用Transforms,本届主要以Compose为例来介绍。
Compose接收一个数据增强操作序列,然后将其组合成单个数据增强操作。本节中主要基于Mnist数据集来演示,我所整理后的整体演示代码如下:
import numpy as np
from PIL import Image
from download import download
from mindspore.dataset import transforms, vision, text
from mindspore.dataset import GeneratorDataset, MnistDataset
# Download data from open datasets
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)
train_dataset = MnistDataset('MNIST_Data/train')
image, label = next(train_dataset.create_tuple_iterator())
print(image.shape)
composed = transforms.Compose(
[
vision.Rescale(1.0 / 255.0, 0),
vision.Normalize(mean=(0.1307,), std=(0.3081,)),
vision.HWC2CHW()
]
)
train_dataset = train_dataset.map(composed, 'image')
image, label = next(train_dataset.create_tuple_iterator())
print(image.shape)
得到结果如下:

2. Vision Transforms
mindspore.dataset.vision模块包含了针对一系列图像数据的Transforms
,本节主要讲解了Rescale、Normalize和HWC2CHW变换。其中Rescale用于调整图像像素值的大小、Normalize用于对于图像进行归一化、HWC2CHW用于转换图像格式,我整合后的代码以及运行结果如下:
import numpy as np
from PIL import Image
from download import download
from mindspore.dataset import transforms, vision, text
from mindspore.dataset import GeneratorDataset, MnistDataset
random_np = np.random.randint(0, 255, (48, 48), np.uint8)
random_image = Image.fromarray(random_np)
print(random_np)
#Rescale
rescale = vision.Rescale(1.0 / 255.0, 0)
rescaled_image = rescale(random_image)
print(rescaled_image)
#Normalize
normalize = vision.Normalize(mean=(0.1307,), std=(0.3081,))
normalized_image = normalize(rescaled_image)
print(normalized_image)
#HWC2CHW
hwc_image = np.expand_dims(normalized_image, -1)
hwc2chw = vision.HWC2CHW()
chw_image = hwc2chw(hwc_image)
print(hwc_image.shape, chw_image.shape)
得到结果如下:

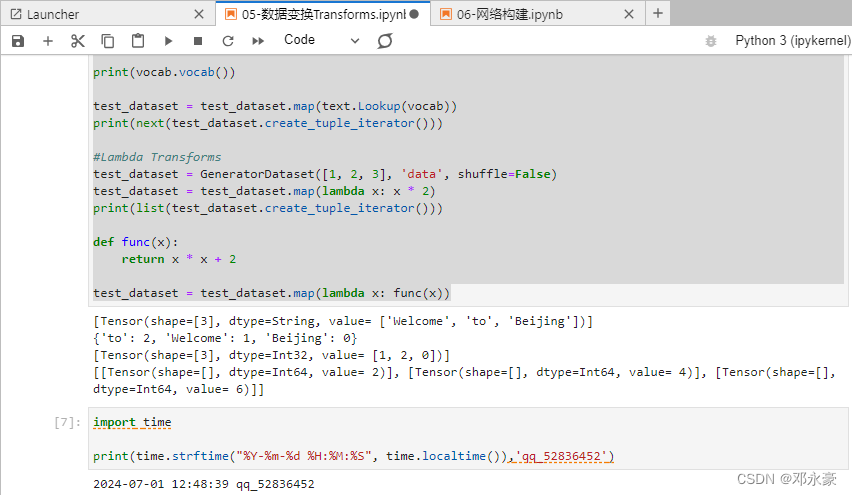
3. Text Transforms
mindspore.dataset.text模块主要针对文本数据进行相关的分词构建词表。转index等操作。其中主要讲了PythonTokenizer和Lookup与Lambda Transforms,分别起分词操作、映射变换与加载Lambda函数,他们的事例代码如下:
import numpy as np
from PIL import Image
from download import download
from mindspore.dataset import transforms, vision, text
from mindspore.dataset import GeneratorDataset, MnistDataset
texts = ['Welcome to Beijing']
test_dataset = GeneratorDataset(texts, 'text')
#PythonTokenizer
def my_tokenizer(content):
return content.split()
test_dataset = test_dataset.map(text.PythonTokenizer(my_tokenizer))
print(next(test_dataset.create_tuple_iterator()))
#Lookup
vocab = text.Vocab.from_dataset(test_dataset)
print(vocab.vocab())
test_dataset = test_dataset.map(text.Lookup(vocab))
print(next(test_dataset.create_tuple_iterator()))
#Lambda Transforms
test_dataset = GeneratorDataset([1, 2, 3], 'data', shuffle=False)
test_dataset = test_dataset.map(lambda x: x * 2)
print(list(test_dataset.create_tuple_iterator()))
def func(x):
return x * x + 2
test_dataset = test_dataset.map(lambda x: func(x))
得到结果如下:

以上就是今天我所学习的内容啦~