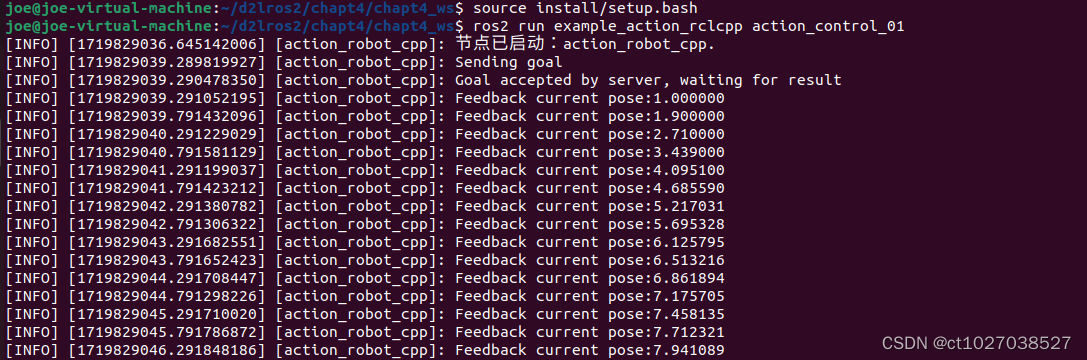
系统演示:
基于深度学习的水果蔬菜检测识别系统
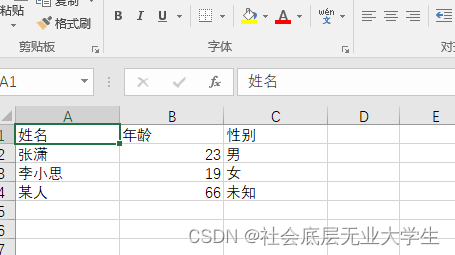
界面图:

技术组成:
-
深度学习模型(YOLOv8):
- YOLOv8是基于YOLO系列的目标检测模型,具有较快的检测速度和良好的准确率,适合于实时应用场景。它能够同时检测多个水果和蔬菜,识别它们的种类和位置。
-
Python编程语言:
- 整个系统的开发使用Python作为主要编程语言,利用其丰富的深度学习和图形用户界面(GUI)开发库。
-
PyQt5界面:
- 使用PyQt5库开发用户界面,提供直观的操作界面,用户可以通过界面上传图片或实时视频进行水果蔬菜的检测和识别。
-
数据集:
- 包含了大量标记好的水果和蔬菜图片数据集,用于训练和评估YOLOv8模型的性能。
-
训练代码:
- 提供了训练YOLOv8模型的代码,包括数据预处理、模型配置、训练过程和模型评估等步骤。训练过程可以在GPU加速下进行,以提高效率和速度。
功能分析:
-
对单张图片识别:用户可以通过界面上传一张图片,系统将使用预训练好的YOLOv8模型对图片中的水果和蔬菜进行识别。识别结果包括检测到的物体种类和它们的位置信息。
-
对一段视频进行识别:用户可以选择一个视频文件,系统将逐帧读取视频并利用YOLOv8模型进行物体检测。在视频中识别出的水果和蔬菜将被实时地标记和显示在界面上。
-
对一个文件夹下批量图片进行识别:用户可以指定一个包含多张图片的文件夹,系统将逐一读取每张图片并进行物体检测。每张图片的检测结果将被记录并可以保存到文件中或者在界面上展示。
-
对实时摄像头进行识别:系统支持连接实时摄像头,通过实时视频流进行水果和蔬菜的检测识别。检测结果可以在实时视频上实时标注,帮助用户快速获取当前场景中的信息。
界面参数设计介绍
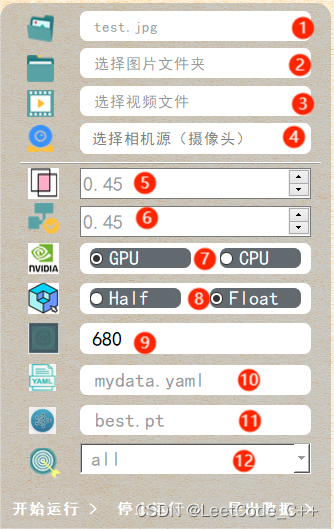
1、对单张图片识别:用户可以通过界面上传一张图片,系统将使用预训练好的YOLOv8模型对图片中的水果和蔬菜进行识别。识别结果包括检测到的物体种类和它们的位置信息。
2、对一个文件夹下批量图片进行识别:用户可以指定一个包含多张图片的文件夹,系统将逐一读取每张图片并进行物体检测。每张图片的检测结果将被记录并可以保存到文件中或者在界面上展示。
3、对一段视频进行识别:用户可以选择一个视频文件,系统将逐帧读取视频并利用YOLOv8模型进行物体检测。在视频中识别出的水果和蔬菜将被实时地标记和显示在界面上。
4、对实时摄像头进行识别:系统支持连接实时摄像头,通过实时视频流进行水果和蔬菜的检测识别。检测结果可以在实时视频上实时标注,帮助用户快速获取当前场景中的信息。
5、交并比阈值:在进行目标检测时,iou参数是一个非常重要的指标。只有当目标检测框的交并比大于该预设值时,检测结果才会被显示出来。这个阈值可以帮助我们过滤掉一些不必要的检测框,从而提高检测的准确率。
6、置信度阈值:在目标检测中,conf参数代表了检测出的目标的置信度。只有当这个置信度大于我们设置的阈值时,这个检测结果才会被显示出来。这个阈值可以帮助我们过滤掉一些不确定的检测结果,从而提高检测的可靠性。
7、显卡选择:在进行推理时,我们可以选择是否使用显卡。默认情况下,勾选了使用显卡的选项,因为显卡可以大大加快推理速度,提高效率。
8、半精度选择:启用半精度(FP16)推理,可以加快在支持FP16的GPU上的模型推理速度。虽然这种方式会对精度产生一定的影响,但是影响较小,因此默认不勾选(不适应半精度)。
9、图片推理尺寸:在推理时,我们可以将推理图片的尺寸固定为一个特定的值。这样可以保证推理的统一性,避免因为图片尺寸不同而导致的推理结果差异。
10、数据集的配置文件:数据集在训练时需要一个配置文件,通常是.yaml格式的。这个配置文件包含了数据集的详细信息,如图片的路径、标签等信息,对于训练过程至关重要。
11、训练好的模型:经过训练我们会得到多个模型,最终需要选择一个进行推理。我们会选择表现最优的那个模型,以保证推理的准确性。
12、类别名:该项目的所有类别名称,这对于后续查看某个特定类别提供了方便。通过类别名,我们可以快速定位到我们需要查看的类别,提高工作效率。