本文为【Mysql日志八股文合集(2)】初版,后续还会进行优化更新,欢迎大家关注交流~
大家第一眼看到这个标题,不知道心中是否有答案了?在面试当中,面试官经常对项目亮点进行深挖,来考察你对这个项目亮点的理解以及思考!这个时候,你如果可以回答出面试官的问题,甚至是主动说出自己的思考,那在面试中是大大加分的~

redo日志的格式
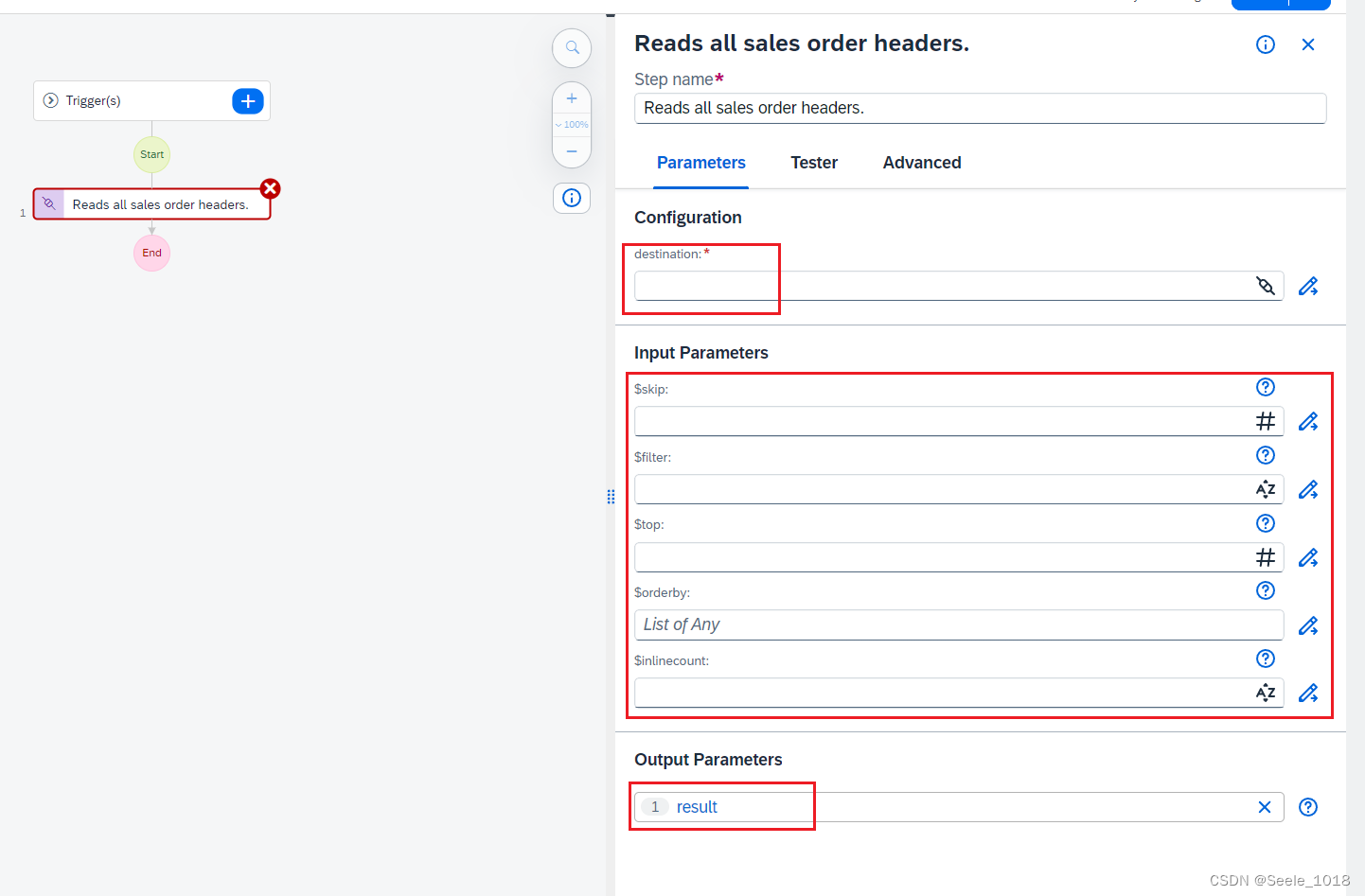
type:表示redo日志的类型
spaceID:表空间ID
page number:页号
data:redo日志的具体内容
mysql的事务执行成功的标志是什么
binlog成功写入就代表事务成功了。
redo log和binlog的作用
redo log是innodb提供的,为了确保事务的持久性。防止在发生故障后,有数据还未写入磁盘。
binlog是sql server提供的,为了主从复制。
讲一下redo log和binlog怎么保持一致性
先写redo log,然后redo log进入prepare状态并通知执行器,然后执行器写binlog,写完后,标志着事务成功了,然后将redo log commit。
mysql的redo log和checkpoint怎么搭配的
Checkpoints是一种保险措施,会定期或在空闲时触发。它将内存中的数据写回到磁盘,同时更新Redo Log,这样即使数据库崩溃,也能通过Redo Log来恢复数据。
Redo Log记录了修改,而Checkpoints保证这些修改被写回磁盘,以确保数据的持久性和恢复能力。
两阶段提交
当有数据修改时,会先将修改redo log cache和binlog cache然后在刷入到磁盘形成redo log file,当redo log file全都刷入到磁盘时(prepare 状态)和提交成功后才能将binlog cache刷入磁盘,当binlog全部刷新到磁盘后会记录一个xid,然后在relo log file上打上commit标志(commit阶段)。
脏页刷新
脏页指的是已被修改但尚未写入到持久存储(如磁盘)的内存页面。脏页刷新是将这些被修改的内存页面写入到持久存储的过程。
undoLog存在硬盘中还是内存中?undolog在内存中是怎么放的?对每个内存而言或者每个数据库连接而言?
undolog 的存储位置:
- undolog 主要存储在磁盘上的表空间中,而不是内存中。
- 每个事务都会有自己的 undolog 记录,用于该事务的回滚操作
undolog 在内存中的存储方式:
- undolog 在内存中是以 undo 段的形式存在的。
- undo 段是 InnoDB 存储引擎中的一个重要组成部分,用于存储事务的 undo 信息。
- 每个数据库连接都会有自己的 undo 段,undo 段存储在 InnoDB buffer pool 的共享池中。
undolog都有那些参数?
undolog 的主要参数:
- innodb_undo_logs:控制 InnoDB 使用的 undo 日志的数量,默认为 128。
- innodb_undo_tablespaces:控制 undo 日志存储的表空间数量,默认为 2。
- innodb_undo_log_truncate:控制 undo 日志的自动截断功能。
- innodb_max_undo_log_size:控制单个 undo 日志的最大大小。
其他相关参数:
- innodb_rollback_segments:控制 InnoDB 中事务回滚段的数量。
- innodb_purge_threads:控制 InnoDB 后台 purge 线程的数量,用于清理 undo 日志。
redolog、undolog、binlog、relaylog作用、写入时机?如何保证断电数据一致
各种日志的作用和写入时机:
- redolog(redo log): 记录数据页修改情况,用于事务的持久化和crash recovery,在事务commit时写入
- undolog(undo log): 记录数据修改前的值,用于事务回滚,在事务开始时写入
- binlog: 记录数据库的变更操作,用于主从复制和数据恢复,在事务commit时写入
- relaylog: 从库上的binlog,记录从库接收的主库binlog事件
为了保证断电数据一致性:
- 先写redolog, 再写binlog。redolog保证事务ACID,binlog用于备份和复制
- 系统崩溃时,先通过redolog进行crash recovery,然后再应用binlog进行数据恢
undolog 日志越来越大,怎么解决
- 可以通过定期执行OPTIMZE TABLE来回收undolog空间
- 对于大事务,可以考虑使用SAVEPOINT来减少undolog
binlog什么时候写入
binlog的写入时机:
- 事务commit时才会写入binlog,保证atomicity
- 对于DDL语句,在执行完成后会立即写入binlog
现在有100条数据,我改变表的结构增加一个一段,binlog有什么变化?
- 增加一个字段,会产生一条ALTER TABLE语句写入binlog
binlog支持哪几种数据类型
- binlog支持MySQL支持的所有数据类型
Binlog什么情况下会产生?
- DML(INSERT/UPDATE/DELETE)语句
- DDL(CREATE/ALTER/DROP)语句
- 存储过程/函数的调用
- 触发器的执行
Binlog事件驱动模型有什么坏处?
- 吞吐量相对较低,因为需要频繁地写入binlog
- 对于大事务,可能会产生较大的binlog文件,同步效率降低
怎么实现主从同步插件?
(参考binlog)
实现主从同步的典型方式是使用MySQL的复制功能。主库将数据变更记录到binlog日志中,从库通过读取主库的binlog日志来同步数据。这个过程主要包括以下步骤:
-
- 主库开启binlog日志记录
- 从库配置连接主库,并开启复制线程读取主库的binlog
- 从库将读取的binlog事件应用到自己的数据库中
binlog逐条执行会有什么问题?
binlog逐条执行的问题是速度较慢,因为需要单独执行每条SQL语句。解决方法是可以将binlog日志批量执行,即一次性执行多个事件,提高同步效率
binlog怎么防止数据丢失
为了防止数据丢失,可以采取以下措施:
-
- 配置双向或多源复制,互为主从
- 开启binlog的GTID模式,可以实现故障切换时的数据一致性
- 周期性备份binlog日志,并定期校验备份数据
binlog日志监听具体怎么实现
binlog日志监听可以通过访问MySQL的复制接口实现,例如使用MySQL Replication Connector API。这样可以监听binlog事件,并作相应的同步处理
在同步binlog的时候主库是一个时间,从库是一个时间,底层是怎么解决的?/ 同一个sql主库和从库是不一致的,binlog是怎么让他们同步的?/ 主库生成的sql和从库生成的sql不一定一致,mysql有没有做过什么处理?
主从时钟不一致问题,MySQL的复制功能会自动处理。从库在应用binlog事件时,会根据事件的时间戳来执行,而不是按照从库的系统时间。对于主从SQL不一致的情况,MySQL复制也有相应的机制来处理,例如使用statement based或row based复制等。
持久化先提交redolog还是binlog
通常是先提交redolog,再记录binlog。
后期新的八股文合集文章会继续分享,感兴趣的小伙伴可以点个关注~
更多精彩内容以及免费资料请关注公众号:绝命Coding








![Linux[高级管理]——Squid代理服务器的部署和应用(反向代理详解)](https://img-blog.csdnimg.cn/direct/bc4e327b85534edb9af8560428086a59.png)