文章目录
- 一、位置编码
- 位置编码的原理
- 代码解释
- 二、多头注意力
- 三、前馈神经网络(FeedForward)和层归一化(NormLayer)
- FeedForward 模块
- 代码解析
- NormLayer 模块
- 代码解析
- 四、Encoder
- Encoder 类
- EncoderLayer 类
- 前向传播过程
- 五、Decoder
- Decoder 类
- DecoderLayer 类
- 前向传播过程
- 六、Transformer整体框架
- 参考资料
一、位置编码
位置编码(Positional Encoding)是Transformer模型中的一个重要组成部分,用于在序列数据中引入位置信息。由于Transformer模型本身不具备处理序列顺序的能力(因为它完全基于自注意力机制,没有递归或卷积结构),位置编码的引入使得模型能够利用序列的顺序信息。
位置编码的原理
位置编码通过在输入嵌入向量中添加一个与位置相关的向量来实现。具体来说,对于每个位置 ( pos ) 和每个维度 ( i ),位置编码向量 ( PE(pos, 2i) ) 和 ( PE(pos, 2i+1) ) 分别由以下公式计算:

代码解释
以下是 PositionalEncoder 类的详细解释:
import torch
import torch.nn as nn
import math
class PositionalEncoder(nn.Module):
def __init__(self, d_model, max_seq_len=80):
super().__init__()
self.d_model = d_model
# 创建一个常量 PE 矩阵
pe = torch.zeros(max_seq_len, d_model)
for pos in range(max_seq_len):
for i in range(0, d_model, 2):
pe[pos, i] = math.sin(pos / (10000**((2 * i) / d_model)))
pe[pos, i + 1] = math.cos(pos / (10000**((2 * (i + 1)) / d_model)))
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
# 使得单词嵌入表示相对大一些
x = x * math.sqrt(self.d_model)
# 增加位置常量到单词嵌入表示中
seq_len = x.size(1)
x = x + self.pe[:, :seq_len]
return x
-
初始化:
d_model:模型的维度。max_seq_len:序列的最大长度。pe:一个大小为(max_seq_len, d_model)的零矩阵,用于存储位置编码。
-
计算位置编码:
- 对于每个位置
pos和每个维度i,计算sin和cos值,并将其存储在pe矩阵中。 pe矩阵通过unsqueeze(0)增加一个批次维度,使其形状为(1, max_seq_len, d_model)。
- 对于每个位置
-
注册缓冲区:
self.register_buffer('pe', pe):将pe注册为一个缓冲区,这样它会在模型保存和加载时被保存,但不会被优化器更新。
-
前向传播:
x = x * math.sqrt(self.d_model):将输入嵌入向量x放大,以确保嵌入向量的值不会被位置编码淹没。x = x + self.pe[:, :seq_len]:将位置编码添加到输入嵌入向量中,其中seq_len是输入序列的实际长度。
二、多头注意力
多头注意力机制(Multi-Head Attention)是Transformer模型中的一个关键组件,用于处理序列数据,特别是在自然语言处理任务中。它的主要思想是将输入的查询(Query)、键(Key)和值(Value)通过多个独立的注意力头(Attention Heads)进行处理,然后将这些头的输出拼接起来并通过一个线性层进行整合。这种机制可以捕捉序列中不同位置的多种复杂关系。
以下是对多头注意力机制的详细解释:
-
初始化:
d_model:输入和输出的维度。heads:注意力头的数量。d_k:每个注意力头的维度,计算方式为d_model // heads。- 线性层:用于将输入的查询、键和值分别映射到
d_model维度。 - 丢弃层(Dropout):用于防止过拟合。
- 输出线性层:用于将拼接后的多头注意力输出映射回
d_model维度。
-
注意力计算:
attention方法计算注意力分数。首先,通过矩阵乘法计算查询和键的点积,然后除以sqrt(d_k)进行缩放,以防止梯度消失或爆炸。- 如果提供了掩码(mask),则将掩码中为0的位置对应的分数设置为一个非常小的值(如
-1e9),以确保这些位置在softmax后为0。 - 对分数进行softmax操作,使其成为一个概率分布。
- 应用丢弃层(Dropout)。
- 通过矩阵乘法将注意力分数与值相乘,得到加权的值。
-
前向传播:
- 对输入的查询、键和值分别进行线性变换,然后重塑为多头形式。
- 将这些张量进行转置,以便在注意力计算中正确对齐。
- 调用
attention方法计算多头注意力。 - 将多头注意力的输出进行转置和拼接,然后通过输出线性层进行整合。
以下是完整的代码实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class MultiHeadAttention(nn.Module):
def __init__(self, heads, d_model, dropout=0.1):
super().__init__()
self.d_model = d_model
self.d_k = d_model // heads
self.h = heads
self.q_linear = nn.Linear(d_model, d_model)
self.v_linear = nn.Linear(d_model, d_model)
self.k_linear = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
self.out = nn.Linear(d_model, d_model)
def attention(self, q, k, v, d_k, mask=None, dropout=None):
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
mask = mask.unsqueeze(1)
scores = scores.masked_fill(mask == 0, -1e9)
scores = F.softmax(scores, dim=-1)
if dropout is not None:
scores = dropout(scores)
output = torch.matmul(scores, v)
return output
def forward(self, q, k, v, mask=None):
bs = q.size(0)
k = self.k_linear(k).view(bs, -1, self.h, self.d_k).transpose(1, 2)
q = self.q_linear(q).view(bs, -1, self.h, self.d_k).transpose(1, 2)
v = self.v_linear(v).view(bs, -1, self.h, self.d_k).transpose(1, 2)
scores = self.attention(q, k, v, self.d_k, mask, self.dropout)
concat = scores.transpose(1, 2).contiguous().view(bs, -1, self.d_model)
output = self.out(concat)
return output
转置操作 .transpose(1, 2) 是为了在多头注意力计算中正确对齐每个头的查询、键和值,指的是,矩阵计算在sequence_length, d_k这两个维度上进行。
三、前馈神经网络(FeedForward)和层归一化(NormLayer)
FeedForward 模块
FeedForward 模块是一个简单的前馈神经网络,通常紧跟在多头注意力机制之后。它由两个线性层和一个激活函数组成,中间包含一个丢弃层(Dropout)以防止过拟合。
代码解析
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff=2048, dropout=0.1):
super().__init__()
# d_ff 默认设置为 2048
self.linear_1 = nn.Linear(d_model, d_ff)
self.dropout = nn.Dropout(dropout)
self.linear_2 = nn.Linear(d_ff, d_model)
def forward(self, x):
x = self.dropout(F.relu(self.linear_1(x)))
x = self.linear_2(x)
return x
-
初始化:
d_model:输入和输出的维度。d_ff:中间层的维度,默认设置为 2048。dropout:丢弃层的丢弃率,默认设置为 0.1。self.linear_1:第一个线性层,将输入从d_model维度映射到d_ff维度。self.dropout:丢弃层,用于防止过拟合。self.linear_2:第二个线性层,将输入从d_ff维度映射回d_model维度。
-
前向传播:
self.linear_1(x):将输入x从d_model维度映射到d_ff维度。F.relu(self.linear_1(x)):应用 ReLU 激活函数。self.dropout(F.relu(self.linear_1(x))):应用丢弃层。self.linear_2(x):将输入从d_ff维度映射回d_model维度。
NormLayer 模块
NormLayer 模块是一个层归一化层,用于对输入进行归一化处理。层归一化通过对每个样本的所有特征进行归一化,使得每个样本的特征具有相同的均值和标准差。
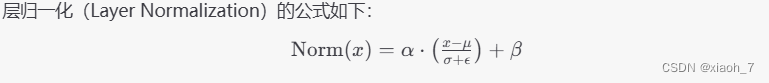
代码解析
class NormLayer(nn.Module):
def __init__(self, d_model, eps=1e-6):
super().__init__()
self.size = d_model
# 层归一化包含两个可以学习的参数
self.alpha = nn.Parameter(torch.ones(self.size))
self.bias = nn.Parameter(torch.zeros(self.size))
self.eps = eps
def forward(self, x):
norm = self.alpha * (x - x.mean(dim=-1, keepdim=True)) \
/ (x.std(dim=-1, keepdim=True) + self.eps) + self.bias
return norm
-
初始化:
d_model:输入和输出的维度。eps:一个很小的数,用于防止除零错误,默认设置为 1e-6。self.alpha:一个可学习的缩放参数,初始化为全1。self.bias:一个可学习的偏移参数,初始化为全0。
-
前向传播:
x.mean(dim=-1, keepdim=True):计算输入x在最后一个维度上的均值。x.std(dim=-1, keepdim=True):计算输入x在最后一个维度上的标准差。(x - x.mean(dim=-1, keepdim=True)) / (x.std(dim=-1, keepdim=True) + self.eps):对输入x进行归一化处理。self.alpha * ... + self.bias:应用可学习的缩放和偏移参数。
这两个模块在Transformer模型中通常一起使用,FeedForward 模块用于增加模型的非线性能力,而 NormLayer 模块用于稳定训练过程和加速收敛。
四、Encoder
这里的 Encoder 类是 Transformer 模型中的编码器部分。编码器的主要作用是将输入序列(例如一段文本)转换成一系列高维特征向量,这些特征向量可以被解码器用来生成输出序列。下面是对 Encoder 类及其组成部分的详细解释:
Encoder 类
Encoder 类是整个编码器的主要结构,它包含了以下几个部分:
-
嵌入层 (
self.embed):- 将输入的词汇索引序列(
src)转换为对应的词嵌入向量。每个词汇索引对应一个d_model维的向量。
- 将输入的词汇索引序列(
-
位置编码器 (
self.pe):- 由于 Transformer 模型没有递归和卷积结构,无法自然地利用序列的顺序信息。位置编码器通过在词嵌入向量中添加位置信息来解决这个问题。位置编码可以是固定的(如正弦和余弦函数),也可以是可学习的。
-
编码器层 (
self.layers):- 这是一个由
N个EncoderLayer组成的列表。每个EncoderLayer包含一个多头注意力机制和一个前馈神经网络,以及相应的归一化层和丢弃层。
- 这是一个由
-
归一化层 (
self.norm):- 在所有编码器层之后,对输出进行层归一化,以稳定训练过程。
class Encoder(nn.Module):
def __init__(self, vocab_size, d_model, N, heads, dropout):
super().__init__()
self.N = N
self.embed = nn.Embedding(vocab_size, d_model)
self.pe = PositionalEncoder(d_model)
self.layers = nn.ModuleList([EncoderLayer(d_model, heads, dropout) for _ in range(N)])
self.norm = NormLayer(d_model)
def forward(self, src, mask):
x = self.embed(src)
x = self.pe(x)
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
EncoderLayer 类
EncoderLayer 类是编码器的基本组成单元,每个 EncoderLayer 包含以下几个部分:
-
归一化层 (
self.norm_1和self.norm_2):- 在多头注意力机制和前馈神经网络之前,对输入进行层归一化。
-
多头注意力机制 (
self.attn):- 计算输入序列的自注意力表示。自注意力机制允许模型在处理每个位置的输入时,考虑到序列中所有其他位置的信息。
-
前馈神经网络 (
self.ff):- 一个简单的两层全连接神经网络,用于对每个位置的输入进行非线性变换。
-
丢弃层 (
self.dropout_1和self.dropout_2):- 在多头注意力机制和前馈神经网络的输出上应用丢弃操作,以防止过拟合。
class EncoderLayer(nn.Module):
def __init__(self, d_model, heads, dropout=0.1):
super().__init__()
self.norm_1 = NormLayer(d_model)
self.norm_2 = NormLayer(d_model)
self.attn = MultiHeadAttention(heads, d_model, dropout=dropout)
self.ff = FeedForward(d_model, dropout=dropout)
self.dropout_1 = nn.Dropout(dropout)
self.dropout_2 = nn.Dropout(dropout)
def forward(self, x, mask):
x2 = self.norm_1(x)
x = x + self.dropout_1(self.attn(x2, x2, x2, mask))
x2 = self.norm_2(x)
x = x + self.dropout_2(self.ff(x2))
return x
前向传播过程
-
嵌入和位置编码:
- 输入序列
src首先通过嵌入层转换为词嵌入向量,然后通过位置编码器添加位置信息。
- 输入序列
-
编码器层处理:
- 将添加了位置信息的词嵌入向量输入到第一个编码器层。每个编码器层的输出作为下一个编码器层的输入,依次经过所有
N个编码器层。
- 将添加了位置信息的词嵌入向量输入到第一个编码器层。每个编码器层的输出作为下一个编码器层的输入,依次经过所有
-
归一化:
- 在所有编码器层处理完毕后,对最终的输出进行层归一化。
五、Decoder
这个 Decoder 类是 Transformer 模型中的解码器部分。解码器的主要作用是生成输出序列,例如在机器翻译任务中,解码器负责生成目标语言的句子。下面是对 Decoder 类及其组成部分的详细解释:
Decoder 类
Decoder 类是整个解码器的主要结构,它包含了以下几个部分:
-
嵌入层 (
self.embed):- 将输入的目标语言词汇索引序列(
trg)转换为对应的词嵌入向量。每个词汇索引对应一个d_model维的向量。
- 将输入的目标语言词汇索引序列(
-
位置编码器 (
self.pe):- 由于 Transformer 模型没有递归和卷积结构,无法自然地利用序列的顺序信息。位置编码器通过在词嵌入向量中添加位置信息来解决这个问题。位置编码可以是固定的(如正弦和余弦函数),也可以是可学习的。
-
解码器层 (
self.layers):- 这是一个由
N个DecoderLayer组成的列表。每个DecoderLayer包含两个多头注意力机制和一个前馈神经网络,以及相应的归一化层和丢弃层。
- 这是一个由
-
归一化层 (
self.norm):- 在所有解码器层之后,对输出进行层归一化,以稳定训练过程。
class Decoder(nn.Module):
def __init__(self, vocab_size, d_model, N, heads, dropout):
super().__init__()
self.N = N
self.embed = nn.Embedding(vocab_size, d_model)
self.pe = PositionalEncoder(d_model)
self.layers = nn.ModuleList([DecoderLayer(d_model, heads, dropout) for _ in range(N)])
self.norm = NormLayer(d_model)
def forward(self, trg, e_outputs, src_mask, trg_mask):
x = self.embed(trg)
x = self.pe(x)
for layer in self.layers:
x = layer(x, e_outputs, src_mask, trg_mask)
return self.norm(x)
DecoderLayer 类
DecoderLayer 类是解码器的基本组成单元,每个 DecoderLayer 包含以下几个部分:
-
归一化层 (
self.norm_1,self.norm_2,self.norm_3):- 在多头注意力机制和前馈神经网络之前,对输入进行层归一化。
-
丢弃层 (
self.dropout_1,self.dropout_2,self.dropout_3):- 在多头注意力机制和前馈神经网络的输出上应用丢弃操作,以防止过拟合。
-
多头注意力机制 (
self.attn_1,self.attn_2):self.attn_1是自注意力机制,计算输入序列的自注意力表示。自注意力机制允许模型在处理每个位置的输入时,考虑到序列中所有其他位置的信息。self.attn_2是编码器-解码器注意力机制,允许解码器在生成每个位置的输出时,考虑到编码器的输出(即源语言的上下文信息)。
-
前馈神经网络 (
self.ff):- 一个简单的两层全连接神经网络,用于对每个位置的输入进行非线性变换。
class DecoderLayer(nn.Module):
def __init__(self, d_model, heads, dropout=0.1):
super().__init__()
self.norm_1 = NormLayer(d_model)
self.norm_2 = NormLayer(d_model)
self.norm_3 = NormLayer(d_model)
self.dropout_1 = nn.Dropout(dropout)
self.dropout_2 = nn.Dropout(dropout)
self.dropout_3 = nn.Dropout(dropout)
self.attn_1 = MultiHeadAttention(heads, d_model, dropout=dropout)
self.attn_2 = MultiHeadAttention(heads, d_model, dropout=dropout)
self.ff = FeedForward(d_model, dropout=dropout)
def forward(self, x, e_outputs, src_mask, trg_mask):
x2 = self.norm_1(x)
x = x + self.dropout_1(self.attn_1(x2, x2, x2, trg_mask))
x2 = self.norm_2(x)
x = x + self.dropout_2(self.attn_2(x2, e_outputs, e_outputs, src_mask))
x2 = self.norm_3(x)
x = x + self.dropout_3(self.ff(x2))
return x
前向传播过程
-
嵌入和位置编码:
- 输入序列
trg首先通过嵌入层转换为词嵌入向量,然后通过位置编码器添加位置信息。
- 输入序列
-
解码器层处理:
- 将添加了位置信息的词嵌入向量输入到第一个解码器层。每个解码器层的输出作为下一个解码器层的输入,依次经过所有
N个解码器层。 - 在每个解码器层中,首先进行自注意力机制计算,然后进行编码器-解码器注意力机制计算,最后进行前馈神经网络计算。
- 将添加了位置信息的词嵌入向量输入到第一个解码器层。每个解码器层的输出作为下一个解码器层的输入,依次经过所有
-
归一化:
- 在所有解码器层处理完毕后,对最终的输出进行层归一化。
六、Transformer整体框架
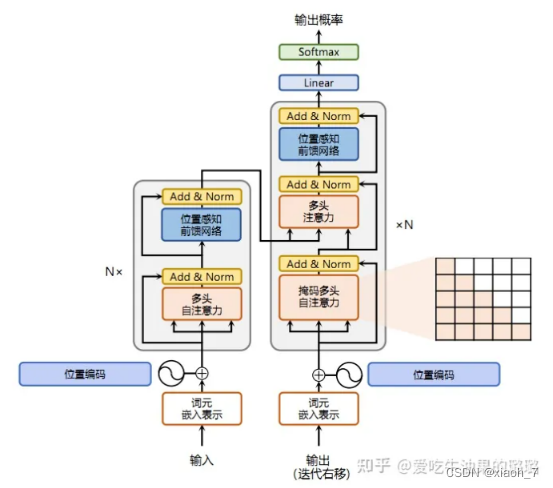
class Transformer(nn.Module):
def __init__(self, src_vocab, trg_vocab, d_model, N, heads, dropout):
super().__init__()
self.encoder = Encoder(src_vocab, d_model, N, heads, dropout)
self.decoder = Decoder(trg_vocab, d_model, N, heads, dropout)
self.out = nn.Linear(d_model, trg_vocab)
def forward(self, src, trg, src_mask, trg_mask):
e_outputs = self.encoder(src, src_mask)
d_output = self.decoder(trg, e_outputs, src_mask, trg_mask)
output = self.out(d_output)
return output
参考资料
https://zhuanlan.zhihu.com/p/657456977
《Attention is all you need》
版权声明
本博客内容仅供学习交流,转载请注明出处。