3-数据提取方法1(json)(6节课学会爬虫)
- 1,Json
- 2,哪里会返回json的数据(值得尝试的操作)
- 3,Json字符串转换成字典或python类型进行数据提取
- (1)Json.loads
- (2)Json.dumps
- 4,百度翻译
- 5,豆瓣电视剧
1,Json
数据交换格式(数据后端传递到前端,一般是json的格式),看起来像python的字符串列表、字典
使用json前需要导入 import json
2,哪里会返回json的数据(值得尝试的操作)
浏览器切换到手机版(不是每个页面都会返回json数据,如百度手机版,虽然是手机版,但返回的不是json而是HTML的数据)
抓包App(很多app,有的前端和后端都是被人写的,会在前端和后端传输数据的时候加密,抓到的数据都是加密后的,可能也会获取不到,也是值得尝试的,一旦找到返回json数据的地址,会使我们后续的操作非常的容易)
3,Json字符串转换成字典或python类型进行数据提取
(1)Json.loads
-把json字符串转换成python字典类型
Json.loads(json字符串)
(2)Json.dumps
把python的字典类型转换成字符串
Json.dumps({“a”:”a”,”b”:2})
当我们写文件时,将字典写入到本地是不行的,只能是字符串
Ensure_ascii:让中文显示成中文
Indent:能够让下一行在上一行的基础上空格
4,百度翻译
https://blog.csdn.net/qq_25404477/article/details/103331566
百度翻译反爬越来越难爬取(不能使用其他字符串的原因如上连接)
#-*- codeing = utf-8 -*-
#@Time : 2020/12/9 18:45
#@Author : 招财进宝
#@File : 06-try_json.py
#@Software: PyCharm
import requests
import json
#模拟浏览器访问
url = "https://fanyi.baidu.com/v2transapi?from=zh&to=en"
#query_str = input("请输入要翻译的中文:")
data={
"from": "zh",
"to": "en",
"query": "你好",
"transtype": "translang",
"simple_means_flag": "3",
"sign": "232427.485594",
"token": "365f8c1b81a6764199c2f387c1da6e2f",
"domain": "common"
}
print(data)
headers = {
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9",
"cache-control": "no-cache",
"content-length": "150",
"content-type": "application/x-www-form-urlencoded; charset=UTF-8",
"origin": "https://fanyi.baidu.com",
"pragma": "no-cache",
"referer":"https://fanyi.baidu.com/v",
"sec-fetch-destv": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"x-requested-with": "XMLHttpRequest",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
"cookie": "换成自己的"
}
response = requests.post(url,data=data,headers=headers)
html_str = response.content.decode() #json字符串,类型是str
dict_ret = json.loads(html_str) #将json字符串转换成字典类型
print(dict_ret) #{'trans_result': {'data': [{'dst': 'Hello', 'prefixWrap': 0,........
print(type(dict_ret))
ret = dict_ret["trans_result"]["data"][0]["dst"] #从上方的dict_ret结果进行需要的数据的提取,提取的方式如左侧
#
print("翻译的结果是:",ret)
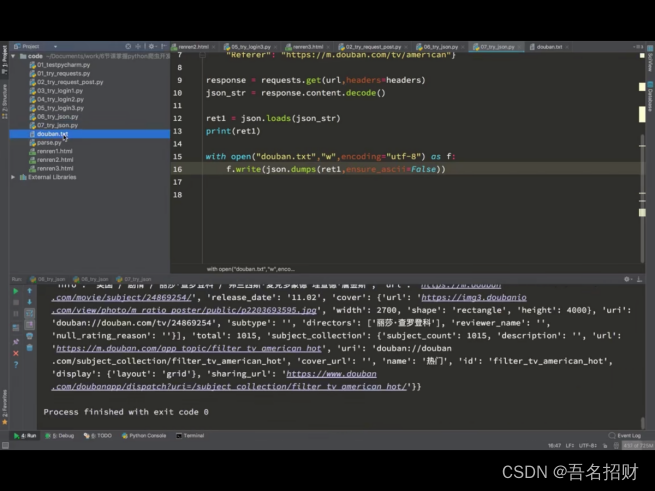
5,豆瓣电视剧
使用Chrome浏览器打开百度页面,可以切换到手机版(我这里是手机上的网页版,因为其要下载app,可能后面的结果不是json的,直接就是网页),手机版对应的页面返回的是json
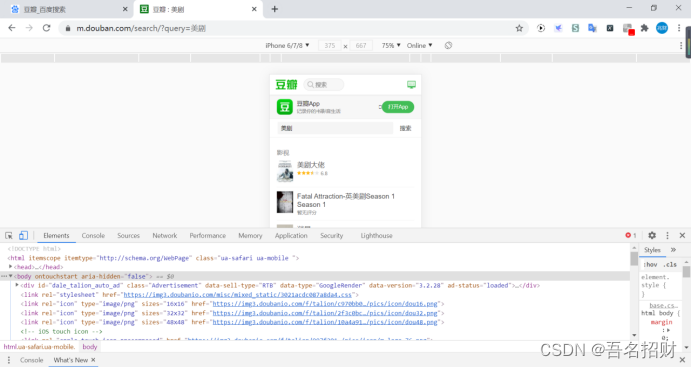
要在network中找到那个url地址是包含这些美剧信息的地址
当我们点击
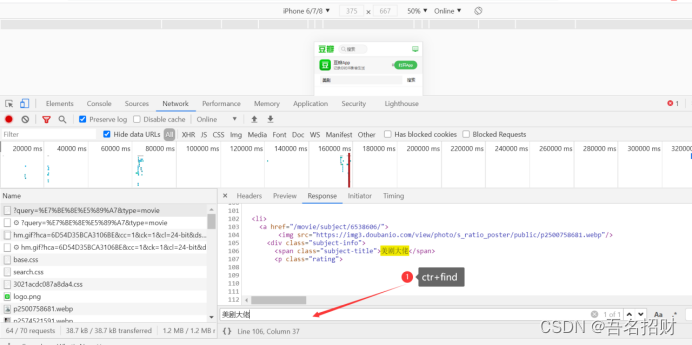
当我们点击ctr+F的时候,进行搜索上面的内容是否在response中,有时候无法搜索到,原因有2:
1.response中没有
2.中文是被编码后的中文,直接使用中文是搜索不到的,可以在preview中搜索(在preview中的中文就是正常中文)
当以上两种方式在url中都无法找到时,可以接着向下寻找url,只要js和css都不需要管,最后发现
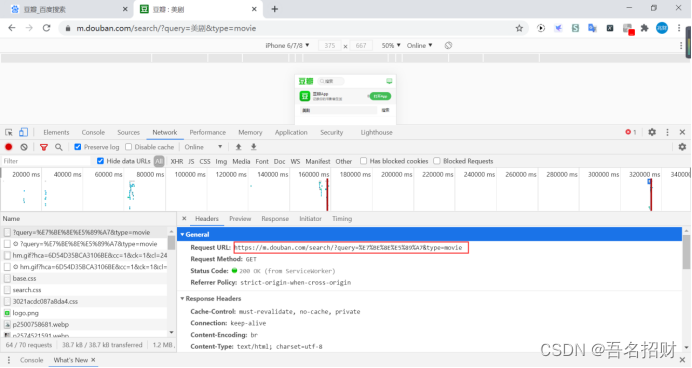
https://m.douban.com/search/?query=%E7%BE%8E%E5%89%A7&type=movie
当使用上面链接进行另一标签页再打开的时候,发现可能会出错,
在request的headers中进行查看,其中accept都不用关心,而下方的要和前面的标签页面进行对比,最后发现refer这个字段内容没有,很有可能是此内容导致页面的数据无法获取
下方在编程中进行实现,加入refer字段后,就能得到数据了,说明豆瓣的反爬机制是对此有反应的(但真实情况是use-agent一个字段就可以了,应该是视频上的出现了错误)
#-*- codeing = utf-8 -*-
#@Time : 2020/12/10 9:10
#@Author : 招财进宝
#@File : 07_try_json.py
#@Software: PyCharm
import requests
url = "https://m.douban.com/search/?query=%E7%BE%8E%E5%89%A7&type=movie"
headers={
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1",
}
response = requests.get(url,headers=headers)
print(response.content.decode())
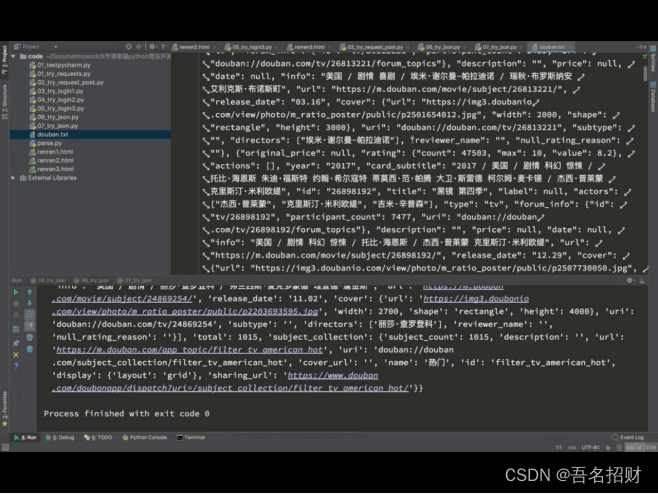
https://m.douban.com/search/?query=%E7%BE%8E%E5%89%A7&type=movie因为上方的结果是网页的HTML,并不是json的数据格式,所以接下来的编写就不进行了
Ensure_ascii =False #不再以ASCII码的方式保存中文
Indent=2 #能在保存时有换行的效果,下一行比上一行空2格
https://m.douban.com/j/search/?q=%E7%BE%8E%E5%89%A7&t=movie&p=1
当我们使用鼠标在上方的收集版网页进行搜索时,需要点击更多搜索结果,然后会出现新的url,在此url中,如上,可以看到页面的
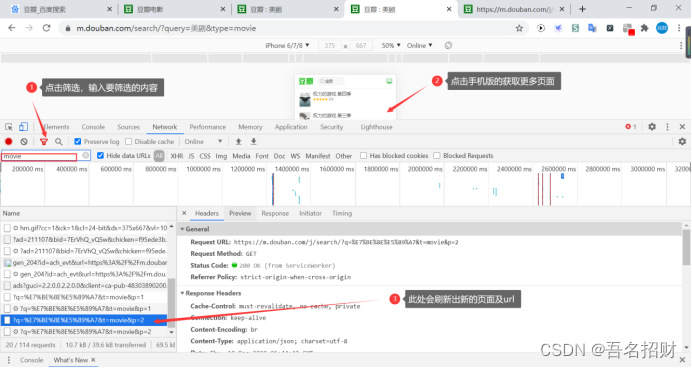
当我们将其输入到地址栏中时,就可以看到返回的json数据
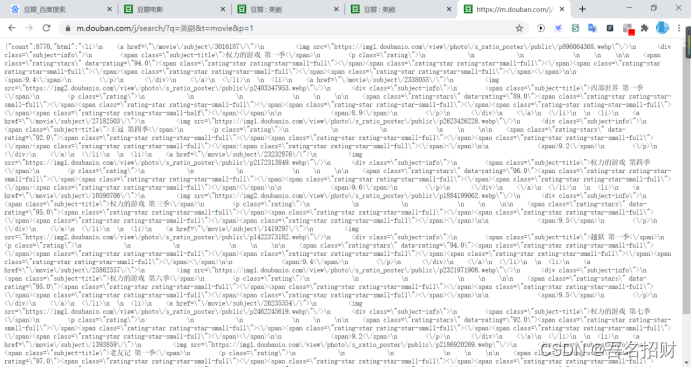
由此可以判断https://m.douban.com/j/search/?q=%E7%BE%8E%E5%89%A7&t=movie&p=1
就是根据p改变的页面
通过p向服务器说明要返回什么数据
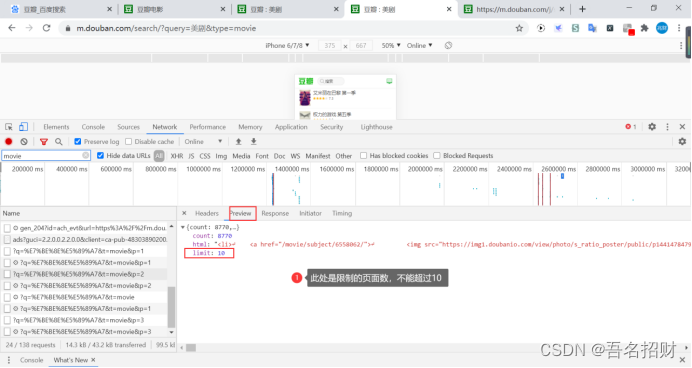
或者自己的分析不够精确,可能是count的作为限制数
下方就不编写这个手机版的json的爬取代码了,因为此处和视频上的是无法对应的,这个实时性太强了,现在使用之前的代码函数,是无法获取的到数据的。
下面是写到一半的代码
#-*- codeing = utf-8 -*-
#@Time : 2020/12/10 9:58
#@Author : 招财进宝
#@File : 08_douban_spider.py
#@Software: PyCharm
from parse import parse_url #此处的parse文件应放在项目的下一级,而不是好几级,会引入不到
import json
class DoubanSpider:
def __init__(self):
self.temp_url = "https://m.douban.com/j/search/?q=%E7%BE%8E%E5%89%A7&t=movie&p={}"
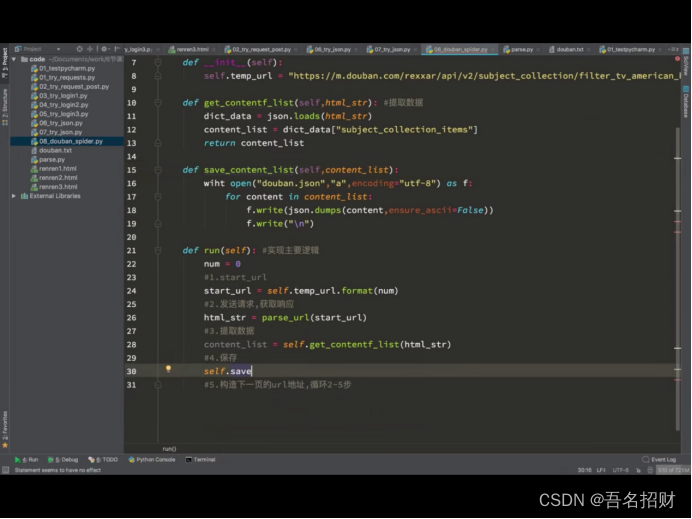
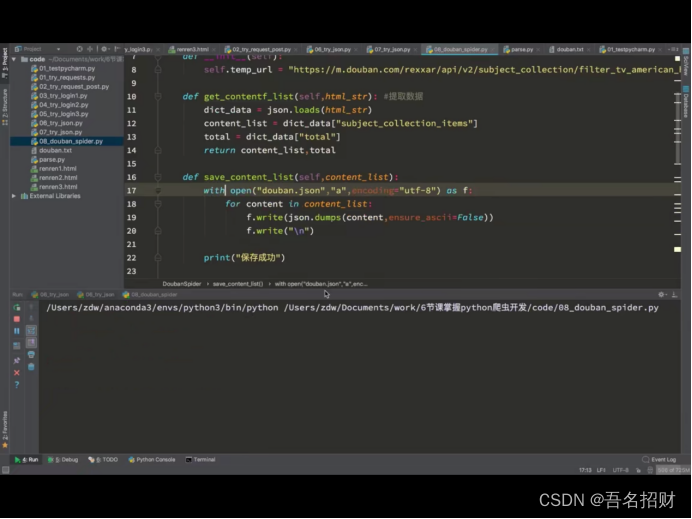
def get_contentf_list(self,html_str): #提取数据
dict_data = json.loads(html_str)
content_list = dict_data["html"] #返回的是HTML字段的数据(不再进行下去了)
def run(self):#实现主要逻辑
num=1
#1.start_url
start_url = self.temp_url.format(1)
#2.发送请求获取响应
html_str = parse_url(start_url) #使用自己封装的函数进行url请求
#3.提取数据
#4.保存
#5.构造下一页的url地址,循环2-5次
#-*- codeing = utf-8 -*-
#@Time : 2020/12/9 14:36
#@Author : 招财进宝
#@File : parse.py
import requests
from retrying import retry
#下方是电脑版的,若是手机版的,还需要更改为手机版
headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"}
# headers={
# "User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1",
# }
@retry(stop_max_attempt_number=3) #让下面被装饰的函数反复执行三次,三次全部报错才会报错,中间有一次正常,程序继续往后走
def _parse_url(url):
print("*"*100)
response = requests.get(url,headers=headers,timeout=5)
return response.content.decode()
def parse_url(url):
try:
html_str = _parse_url(url)
except:
html_str = None
return html_str
if __name__ == '__main__':
url = "http://www.baidu.com"
print(parse_url(url)[:100]) #只打印前100字符串,此处访问成功只出现一行*
url1 = "www.baidu.com" #此处地址有误
print(parse_url(url1)) #会出现三行*
#@Software: PyCharm
下面是视频上的内容
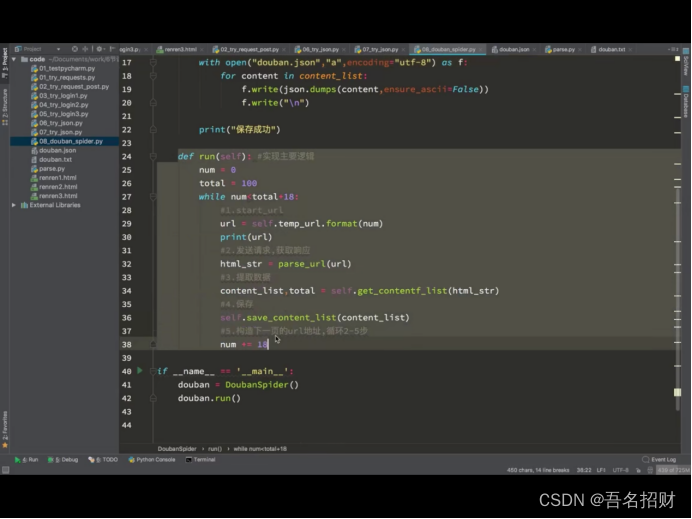
定义run方法,可以清楚的知道先做了什么,后做了什么,接着就是各个函数的编写
在浏览器中,获取的数据只有几百条,被限制住了