目录
从 MindSpore 模块中导入nn和ops
定义模型类
模型层
nn.Flatten
nn.Dense
nn.ReLU
nn.SequentialCell
nn.Softmax
模型参数
从 MindSpore 模块中导入nn和ops
将 MindSpore 整个模块引入到当前的 Python 脚本里,方便后续运用 MindSpore 所提供的各类功能与类。从 MindSpore 模块中单独导入“nn”(一般代表神经网络相关的类和函数)以及“ops”(通常指操作符相关的功能),如此一来,在后续的代码中就能够直接使用“nn”和“ops”,而无需添加“mindspore.”这个前缀,让代码变得更加简洁、更易于阅读。
代码如下:
import mindspore
from mindspore import nn, ops 定义模型类
当我们定义神经网络时,可以继承nn.Cell类,在__init__方法中进行子Cell的实例化和状态管理,在construct方法中实现Tensor操作。
代码如下:
#用 MindSpore 框架定义了一个名为 Network 的类,它继承自 nn.Cell
class Network(nn.Cell):
#在 __init__ 方法(构造函数)中进行了一些初始化操作
def __init__(self):
#用于调用父类(即 nn.Cell )的构造函数。
super().__init__()
#定义了 flatten 为 nn.Flatten 对象。
self.flatten = nn.Flatten()
#定义了 dense_relu_sequential 为一个包含多层全连接层(nn.Dense )和激活函数(nn.ReLU )的序列。
self.dense_relu_sequential = nn.SequentialCell(
nn.Dense(28*28, 512, weight_init="normal", bias_init="zeros"),
nn.ReLU(),
nn.Dense(512, 512, weight_init="normal", bias_init="zeros"),
nn.ReLU(),
nn.Dense(512, 10, weight_init="normal", bias_init="zeros")
)
#construct 方法用于定义前向传播的计算过程。
def construct(self, x):
x = self.flatten(x)
logits = self.dense_relu_sequential(x)
return logits
#然后创建了 Network 类的实例 model ,并打印出 model 的相关信息。
model = Network()
print(model) 运行结果:
Network<
(flatten): Flatten<>
(dense_relu_sequential): SequentialCell<
(0): Dense<input_channels=784, output_channels=512, has_bias=True>
(1): ReLU<>
(2): Dense<input_channels=512, output_channels=512, has_bias=True>
(3): ReLU<>
(4): Dense<input_channels=512, output_channels=10, has_bias=True>
>
> 我们构造一个输入数据,直接调用模型,可以获得一个二维的Tensor输出,其包含每个类别的原始预测值。
代码如下:
X = ops.ones((1, 28, 28), mindspore.float32)
logits = model(X)
# print logits
logits 分析:在这段代码里,“X = ops.ones((1, 28, 28), mindspore.float32)”创建了一个 3 维的张量 X,其中所有元素都是 1,形状为(1, 28, 28),数据类型是 mindspore.float32。
“logits = model(X)” 表示将这个 X 作为输入传递给之前定义的名为 model 的模型进行计算,计算得到的结果被存储在 logits 变量中。
所以,这里的“logits”指的是模型对特定输入 X 进行处理和计算后所产生的输出值。
运行结果:
Tensor(shape=[1, 10], dtype=Float32, value=
[[ 4.24947031e-03, -3.66483117e-03, -2.42522405e-03 ... -5.67489350e-03, -8.09418689e-03, 3.98061844e-03]])
在此基础上,我们通过一个nn.Softmax层实例来获得预测概率。
代码如下:
pred_probab = nn.Softmax(axis=1)(logits)
y_pred = pred_probab.argmax(1)
print(f"Predicted class: {y_pred}") 分析:pred_probab = nn.Softmax(axis=1)(logits) 对 logits 进行 Softmax 运算,沿着第 1 个维度(通常是类别维度)计算概率分布,结果存储在 pred_probab 中。
y_pred = pred_probab.argmax(1) 从计算得到的概率分布 pred_probab 中,沿着第 1 个维度找出最大值的索引,将结果存储在 y_pred 中。
print(f"Predicted class: {y_pred}") 打印出预测的类别,即 y_pred 的值。
总的来说,这段代码是对模型的输出 logits 进行处理,得到预测的类别并打印输出。
运行结果:
Predicted class: [5]
模型层
首先我们构造一个shape为(3, 28, 28)的随机数据(3个28x28的图像),依次通过每一个神经网络层来观察其效果。
代码如下:
input_image = ops.ones((3, 28, 28), mindspore.float32)
print(input_image.shape) 分析:首先使用 ops 中的 ones 函数创建一个元素全为 1 的张量 input_image ,这个张量的形状是 (3, 28, 28) ,数据类型是 mindspore.float32 。然后使用 print 函数输出这个张量的形状。
ops.ones((3, 28, 28), mindspore.float32) 表示创建一个 3 维的张量,第一个维度大小为 3,第二个维度大小为 28,第三个维度大小为 28,并且元素值都为 1,数据类型为单精度浮点数。
print(input_image.shape) 用于打印出 input_image 张量的形状信息。
运行结果:
(3, 28, 28)
nn.Flatten
实例化nn.Flatten层,将28x28的2D张量转换为784大小的连续数组。
代码如下:
flatten = nn.Flatten()
flat_image = flatten(input_image)
print(flat_image.shape)分析:首先,创建了一个名为 flatten 的对象,它是由 nn 模块中的 Flatten 类实例化得到的。Flatten 通常用于将多维的输入张量展平为一维。
然后,使用这个 flatten 对象对 input_image 进行处理,得到展平后的张量 flat_image 。
最后,打印出 flat_image 的形状。
总的来说,这段代码的目的是将一个多维的张量 input_image 展平,并查看展平后的形状。
运行结果:
(3, 784)
nn.Dense
nn.Dense为全连接层,其使用权重和偏差对输入进行线性变换。
代码如下:
layer1 = nn.Dense(in_channels=28*28, out_channels=20)
hidden1 = layer1(flat_image)
print(hidden1.shape) 分析:首先,创建了一个名为 layer1 的全连接层(Dense 层)对象。该层的输入通道数(in_channels)为 28*28 ,输出通道数(out_channels)为 20。
然后,将展平后的张量 flat_image 作为输入传递给这个全连接层 layer1 ,得到输出张量 hidden1 。
最后,打印出 hidden1 的形状。
这段代码主要是构建了一个全连接层,并对输入数据进行处理,以观察输出的形状特征。
运行结果:
(3, 20)
nn.ReLU
nn.ReLU层给网络中加入非线性的激活函数,帮助神经网络学习各种复杂的特征。
代码如下:
print(f"Before ReLU: {hidden1}\n\n")
hidden1 = nn.ReLU()(hidden1)
print(f"After ReLU: {hidden1}") 分析:首先,使用格式化字符串 f-string 打印出一条信息 Before ReLU: {hidden1}\n\n ,其中 {hidden1} 会被 hidden1 的值替换。\n\n 表示两个换行符,用于在输出中增加一些空白行。
接下来,将 hidden1 作为输入传递给 nn.ReLU() 激活函数进行处理,并将处理后的结果再次赋值给 hidden1 。
最后,再次使用 f-string 打印出信息 After ReLU: {hidden1} ,展示经过 ReLU 激活函数处理后的 hidden1 的值。
总的来说,这段代码的目的是先打印出激活前的 hidden1 的值,然后对其应用 ReLU 激活函数,再打印出激活后的结果。
运行结果:
#先打印
Before ReLU: [[ 0.3087794 0.9850689 -0.4070658 -0.701891 0.18653367 0.33947796
0.16613327 -0.09155615 -0.24978569 -0.4789814 -0.15506613 0.15600255
-0.25922856 0.89553624 0.4162153 -0.1209818 -1.3496804 -1.0204036
0.36344895 0.10704644]
[ 0.3087794 0.9850689 -0.4070658 -0.701891 0.18653367 0.33947796
0.16613327 -0.09155615 -0.24978569 -0.4789814 -0.15506613 0.15600255
-0.25922856 0.89553624 0.4162153 -0.1209818 -1.3496804 -1.0204036
0.36344895 0.10704644]
[ 0.3087794 0.9850689 -0.4070658 -0.701891 0.18653367 0.33947796
0.16613327 -0.09155615 -0.24978569 -0.4789814 -0.15506613 0.15600255
-0.25922856 0.89553624 0.4162153 -0.1209818 -1.3496804 -1.0204036
0.36344895 0.10704644]]
#后打印
After ReLU: [[0.3087794 0.9850689 0. 0. 0.18653367 0.33947796
0.16613327 0. 0. 0. 0. 0.15600255
0. 0.89553624 0.4162153 0. 0. 0.
0.36344895 0.10704644]
[0.3087794 0.9850689 0. 0. 0.18653367 0.33947796
0.16613327 0. 0. 0. 0. 0.15600255
0. 0.89553624 0.4162153 0. 0. 0.
0.36344895 0.10704644]
[0.3087794 0.9850689 0. 0. 0.18653367 0.33947796
0.16613327 0. 0. 0. 0. 0.15600255
0. 0.89553624 0.4162153 0. 0. 0.
0.36344895 0.10704644]]
nn.SequentialCell
nn.SequentialCell是一个有序的Cell容器。输入Tensor将按照定义的顺序通过所有Cell。我们可以使用nn.SequentialCell来快速组合构造一个神经网络模型。
代码如下:
seq_modules = nn.SequentialCell(
flatten,
layer1,
nn.ReLU(),
nn.Dense(20, 10)
)
logits = seq_modules(input_image)
print(logits.shape) 分析:创建了一个名为 seq_modules 的顺序模块(SequentialCell)对象,该模块依次包含了之前定义的 flatten(展平操作)、layer1(全连接层)、ReLU 激活函数和另一个全连接层 nn.Dense(20, 10)(输入大小为 20,输出大小为 10)。
然后,将 input_image 作为输入传递给这个顺序模块 seq_modules ,得到输出 logits 。
最后,打印出 logits 的形状。
总的来说,这段代码构建了一个包含多个层的神经网络模块,并对输入图像进行处理,查看最终输出的形状。
运行结果:
(3, 10)
nn.Softmax
最后使用nn.Softmax将神经网络最后一个全连接层返回的logits的值缩放为[0, 1],表示每个类别的预测概率。axis指定的维度数值和为1。
代码如下:
softmax = nn.Softmax(axis=1)
pred_probab = softmax(logits) 分析:首先,创建了一个 Softmax 激活函数对象 softmax ,并指定了在维度 1 上进行 Softmax 运算。
然后,将之前得到的 logits 作为输入传递给这个 Softmax 激活函数,得到的结果赋值给 pred_probab 。
Softmax 函数通常用于将输入值转换为概率分布,使得所有值都在 0 到 1 之间,并且总和为 1。在这种情况下,它将 logits 转换为预测的概率分布。
模型参数
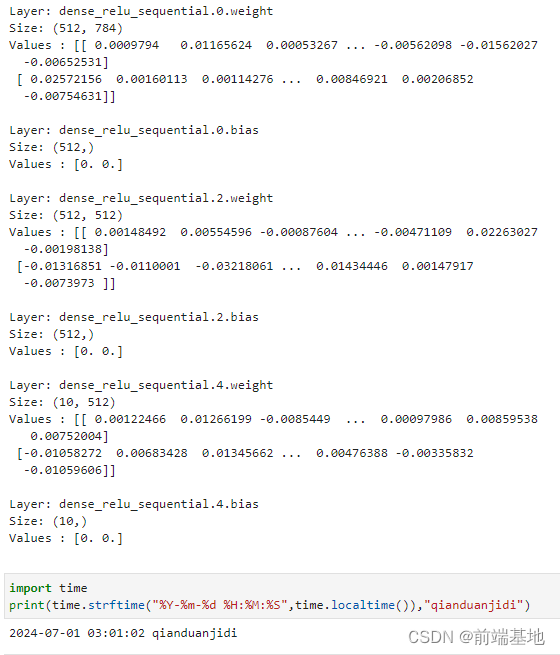
网络内部神经网络层具有权重参数和偏置参数(如nn.Dense),这些参数会在训练过程中不断进行优化,可通过 model.parameters_and_names() 来获取参数名及对应的参数详情。
代码如下:
print(f"Model structure: {model}\n\n")
for name, param in model.parameters_and_names():
print(f"Layer: {name}\nSize: {param.shape}\nValues : {param[:2]} \n") 分析:首先,使用 f-string 打印出模型的结构信息,{model} 会被模型对象的相关描述替换。
然后,通过遍历模型 model 的参数及其名称。对于每个参数,打印出参数所在的层的名称 name ,参数的形状 param.shape ,以及参数的前两个值 param[:2] 。
总的来说,这段代码用于展示模型的结构以及每个层参数的一些基本信息,例如名称、形状和部分值。
运行结果:
Model structure: Network<
(flatten): Flatten<>
(dense_relu_sequential): SequentialCell<
(0): Dense<input_channels=784, output_channels=512, has_bias=True>
(1): ReLU<>
(2): Dense<input_channels=512, output_channels=512, has_bias=True>
(3): ReLU<>
(4): Dense<input_channels=512, output_channels=10, has_bias=True>
>
>
Layer: dense_relu_sequential.0.weight
Size: (512, 784)
Values : [[ 0.0009794 0.01165624 0.00053267 ... -0.00562098 -0.01562027
-0.00652531]
[ 0.02572156 0.00160113 0.00114276 ... 0.00846921 0.00206852
-0.00754631]]
Layer: dense_relu_sequential.0.bias
Size: (512,)
Values : [0. 0.]
Layer: dense_relu_sequential.2.weight
Size: (512, 512)
Values : [[ 0.00148492 0.00554596 -0.00087604 ... -0.00471109 0.02263027
-0.00198138]
[-0.01316851 -0.0110001 -0.03218061 ... 0.01434446 0.00147917
-0.0073973 ]]
Layer: dense_relu_sequential.2.bias
Size: (512,)
Values : [0. 0.]
Layer: dense_relu_sequential.4.weight
Size: (10, 512)
Values : [[ 0.00122466 0.01266199 -0.0085449 ... 0.00097986 0.00859538
0.00752004]
[-0.01058272 0.00683428 0.01345662 ... 0.00476388 -0.00335832
-0.01059606]]
Layer: dense_relu_sequential.4.bias
Size: (10,)
Values : [0. 0.] 打印时间:
import time
print(time.strftime("%Y-%m-%d %H:%M:%S",time.localtime()),"qianduanjidi")运行截图: