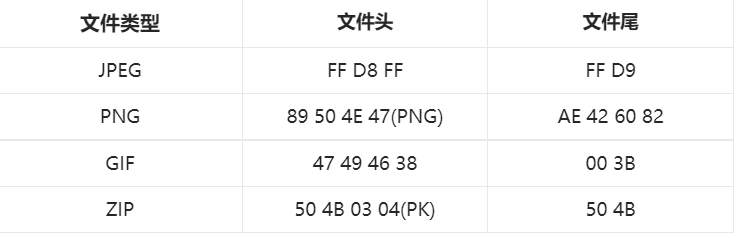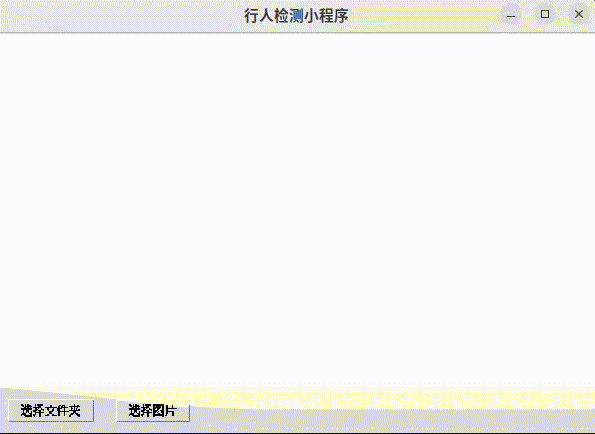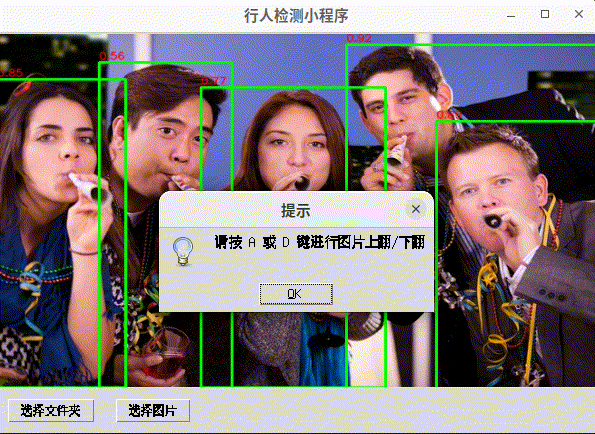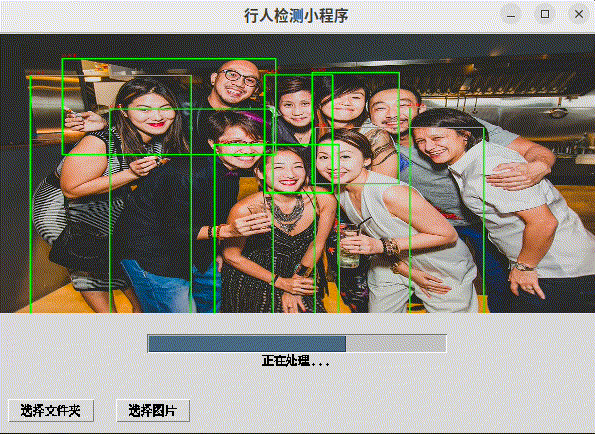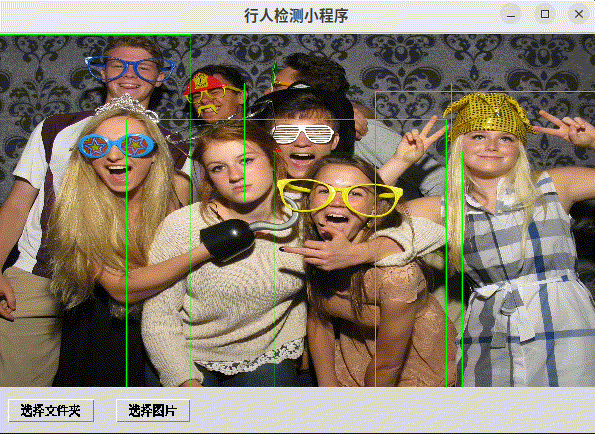
程序提供了一个用户友好的界面,允许用户选择图片或文件夹,使用行人检测模型进行处理,并在GUI中显示检测结果。用户可以通过点击画布上的检测结果来获取更多信息,并使用键盘快捷键来浏览不同的图片。
一. 基本功能介绍
-
界面布局:程序使用
tkinter库创建一个窗口界面,包括标题栏、可调整大小的画布以及底部的操作按钮。 -
图片加载:用户可以通过点击“选择文件夹”或“选择图片”按钮来加载需要检测的图片。支持多种图片格式,如JPG、JPEG、PNG等。
-
目标检测:程序内置了一个检测器(例如YOLOv8),用于识别图片中的行人,并在图片上绘制矩形框和置信度标签。
-
进度显示:在处理多张图片时,程序会显示一个进度条,告知用户当前的检测进度。
-
结果展示:检测完成后,程序会在GUI中展示第一张图片的检测结果,并允许用户通过键盘操作(A键上一张,D键下一张)浏览所有图片。
-
交互反馈:用户点击画布上的检测框时,程序会弹出一个消息框显示选中目标的类别和置信度。
-
图片缩放:程序能够根据窗口大小调整图片的显示尺寸,确保图片在不同分辨率的屏幕上都能清晰显示。
-
日志记录:程序使用
logging模块记录操作日志,便于问题追踪和调试。 -
多线程处理:为了不阻塞GUI操作,图片的检测处理在后台线程中进行。
-
配置灵活:程序允许用户通过参数配置检测器的行为,例如模型路径、图片尺寸、置信度阈值等。
二. 主要方法介绍
-
__init__: 类的构造函数,用于初始化GUI窗口、设置窗口属性、创建组件和绑定事件。 -
load_dir: 允许用户通过文件对话框选择一个文件夹,程序会加载该文件夹下的所有支持格式的图片。 -
load_imgs: 使用文件对话框让用户选择一个或多个图片文件,并将这些文件的路径添加到图片列表中。 -
show_progress_window: 显示进度条窗口,用于在处理图片时提供用户反馈。 -
process_files: 在后台线程中处理所有选中的图片,对每张图片运行检测算法,并更新进度条。 -
run_detect: 对单张图片运行检测器,返回检测结果。 -
draw_result: 在原始图片上绘制检测结果,如边界框和置信度标签。 -
draw_detections: 在GUI的画布上绘制检测结果,包括边界框和文本标签。 -
remove_progress_bar: 在所有图片处理完毕后,移除进度条和相关组件。 -
display_image: 在GUI中显示当前选中的图片及其检测结果。 -
on_canvas_click: 绑定到画布的点击事件,用于检测用户点击的位置是否在检测框内,并显示选中目标的详细信息。 -
win_change: 响应窗口大小变化事件,调整图片的显示大小以适应窗口。 -
on_win_change: 处理窗口大小变化事件,调用win_change方法。 -
on_key_press: 绑定到窗口的键盘按键事件,允许用户通过按键浏览图片。 -
cv2pil: 将使用OpenCV加载的BGR格式图片转换为PIL图像,以便在Tkinter中显示。
三. 代码
import tkinter as tk
from tkinter import ttk
from tkinter import filedialog, messagebox
import cv2
import math
import json
import time
import os
import threading
from PIL import Image, ImageTk
import logging
logging.basicConfig(level=logging.INFO)
from person_detection import api
class MyGUI(tk.Tk):
def __init__(self, det_kwargs):
super().__init__()
self.title('行人检测小程序')
self.geometry('600x400')
self.resizable(width=True, height=True)
self.label = tk.Label(self)
self.bind('<Configure>', self.on_win_change)
self.bind('<Key>', self.on_key_press)
# 创建检测器
self.detector = api.YOLOv8(**det_kwargs) if det_kwargs else None
self.classes = {0: 'person'}
# 用于记录当前的图片数据
self.raw_img_file_path = None
self.visual_image = None
self.photo_image = None
# 创建按钮框架
self.button_frame = tk.Frame(self)
self.button_frame.pack(side=tk.BOTTOM, fill=tk.X, expand=False)
# 创建按钮
self.load_dir_button = tk.Button(self.button_frame, text="选择文件夹", command=self.load_dir)
self.load_dir_button.pack(side=tk.LEFT, padx=10, pady=10, expand=False)
self.load_imgs_button = tk.Button(self.button_frame, text="选择图片", command=self.load_imgs)
self.load_imgs_button.pack(side=tk.LEFT, padx=10, pady=10, expand=False)
# 创建用于显示图片的Canvas
self.image_canvas = tk.Canvas(self, bg='white')
self.image_canvas.pack(side=tk.TOP, fill=tk.BOTH, expand=True)
self.image_id = self.image_canvas.create_image(
0, 0, image=self.photo_image, anchor='nw'
)
# 创建进度条窗口和进度条
self.bar_frame = None
self.progress_window = None
self.progress_bar = None
self.processing_label = None
# 为Canvas绑定鼠标点击事件
self.image_canvas.bind("<Button-1>", self.on_canvas_click)
# 为窗口绑定大小和位置变化事件的监听
self.bind("<Configure>", self.on_win_change)
# 记录每次加载的图片路径列表,检测结果,以及当前的图片索引
self.img_list = []
self.result_list = []
self.index = 0
# 初始化缩放比例属性
self.scale_width = 1.0
self.scale_height = 1.0
def load_dir(self):
"""
选择文件夹,从中加载图片
"""
# 选择图片
file_dir = filedialog.askdirectory(title='选择文件夹')
logging.info("选择的文件夹: {}".format(file_dir))
if file_dir != ():
for i, file in enumerate(os.listdir(file_dir)):
if file.endswith(('.jpg', '.jpeg', '.png', '.bmp', '.tiff', '.webp')):
img_path = os.path.join(file_dir, file)
self.img_list.append(img_path)
# 显示进度条窗口
self.show_progress_window(self.img_list)
def load_imgs(self):
"""
选择单个或多个文件以加载图片
"""
file_paths = filedialog.askopenfilenames(
title='选择图片文件', filetypes=[('图像文件', '*.jpg *.jpeg *.png *.bmp *.tiff *.webp'), ('所有文件', '*.*')])
logging.info("选择的文件: {}".format(file_paths))
if file_paths != ():
for img_path in file_paths:
self.img_list.append(img_path)
# 显示进度条窗口
self.show_progress_window(self.img_list)
def show_progress_window(self, img_list):
# 创建进度条框架
self.bar_frame = tk.Frame(self)
self.bar_frame.pack(side=tk.TOP, fill=tk.Y, pady=20, expand=False)
# 创建正在处理的文本标签和进度条
self.processing_label = tk.Label(self.bar_frame, text="正在处理...")
self.processing_label.pack(side=tk.BOTTOM, fill=tk.Y, pady=0, expand=False)
self.progress_bar = ttk.Progressbar(self.bar_frame, orient='horizontal', length=300, mode='determinate')
self.progress_bar.pack(side=tk.BOTTOM, pady=0, expand=False)
# 设置最大值为文件数量
total_files = len(img_list)
self.progress_bar['maximum'] = total_files
# 更新初始进度
self.progress_bar['value'] = 0
# 在新线程中处理文件以避免阻塞GUI
threading.Thread(target=self.process_files, args=(img_list,)).start()
# 使用阻塞的方式处理文件
# self.process_files(file_dir)
def process_files(self, img_list):
for i, img_path in enumerate(img_list):
# 模拟处理文件的耗时操作
logging.info("处理文件: {}".format(img_path))
img = cv2.imread(img_path)
self.result_list.append(self.run_detect(img))
# 更新进度条
self.progress_bar['value'] = i + 1 # 更新进度条
# 处理完成后,显示消息框并移除进度条
# self.after(100, self.remove_progress_bar) # 稍后执行
self.remove_progress_bar() # 立即执行
# 显示图片到Canvas
self.display_image()
# 调整图片至窗口大小
self.win_change()
def run_detect(self, img):
return self.detector.detect([img])
def draw_result(self, img, result):
img = img.copy()
dets = result['data'][0]['dets']
for det in dets:
id, score, bbox = det['id'], det['score'], det['bbox']
x1, y1, x2, y2 = map(int, bbox)
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.putText(img, '%.2f' % score, (x1, y1 - 4),
cv2.FONT_HERSHEY_SIMPLEX, 0.4, (0, 0, 255), thickness=1, lineType=cv2.LINE_AA)
return img
def draw_detections(self, result):
dets = result['data'][0]['dets']
for det in dets:
id, score, bbox = det['id'], det['score'], det['bbox']
x1, y1, x2, y2 = map(int, bbox)
x1 = int(x1 / self.scale_width)
y1 = int(y1 / self.scale_height)
x2 = int(x2 / self.scale_width)
y2 = int(y2 / self.scale_height)
self.image_canvas.create_rectangle(x1, y1, x2, y2, outline='red', width=2)
self.image_canvas.create_text(x1, y1 - 10, text=f'{score:.2f}', fill='red', font=('Arial', 8))
def remove_progress_bar(self):
"""
移除进度条,进行一些销毁与重置的操作
"""
# 显示消息框
messagebox.showinfo("完成", "文件处理完成!")
# 从主窗体中移除进度条
if self.progress_bar is not None:
self.progress_bar.pack_forget() # 隐藏进度条
self.progress_bar.destroy() # 销毁进度条对象
# 从主窗体中移除进度条标签
if hasattr(self, 'processing_label') and self.processing_label is not None:
self.processing_label.pack_forget() # 隐藏进度条
self.processing_label.destroy() # 销毁进度条对象
# 从主窗体中移除进度条框架
if self.bar_frame is not None:
self.bar_frame.destroy() # 销毁进度条框架
def display_image(self):
if len(self.img_list) == 0:
return
image = cv2.imread(self.img_list[self.index])
image = self.draw_result(image, self.result_list[self.index])
# 将OpenCV图像转换为PIL图像,然后转换为PhotoImage
pil_image = self.cv2pil(image)
self.photo_image = ImageTk.PhotoImage(pil_image)
# 显示图片
self.image_canvas.delete("all") # 删除旧的图片
self.image_id = self.image_canvas.create_image(
0, 0, image=self.photo_image, anchor='nw'
)
self.image_canvas.image = self.photo_image # 保持对图像的引用
def on_canvas_click(self, event):
# 使用缩放比例将画布坐标转换为图像坐标
canvas_x = event.x
canvas_y = event.y
img_x = int(canvas_x / self.scale_width)
img_y = int(canvas_y / self.scale_height)
# 初始化最近目标的距离和索引
min_distance = float('inf') # 正无穷大,用于比较
closest_index = -1
closest_id = None
closest_score = None
# 检查点击坐标是否在检测结果的边界框内
if len(self.result_list) > 0:
dets = self.result_list[self.index]['data'][0]['dets']
for i, det in enumerate(dets):
id, score, bbox = det['id'], det['score'], det['bbox']
x1, y1, x2, y2 = map(int, bbox) # 边界框的坐标
# 计算边界框的中心点坐标
center_x = (x1 + x2) / 2
center_y = (y1 + y2) / 2
if x1 <= img_x <= x2 and y1 <= img_y <= y2:
# 计算点击位置到边界框中心的欧氏距离
distance = math.sqrt((img_x - center_x) ** 2 + (img_y - center_y) ** 2)
# 更新最近目标的距离和索引
if distance < min_distance:
min_distance = distance
closest_index = i
closest_id = id
closest_score = score
# 如果找到最近的目标,则显示信息
if closest_index != -1:
messagebox.showinfo("检测到的目标", f"标签: {self.classes[closest_id]}\n置信度: {closest_score:.2f}")
# else:
# messagebox.showinfo("点击区域", "未检测到目标")
def win_change(self):
if len(self.result_list) > 0: # 确保图像不为空
image = cv2.imread(self.img_list[self.index])
visual_image = self.draw_result(image, self.result_list[self.index])
# 保存原始图像尺寸和画布尺寸
self.orig_width = visual_image.shape[1]
self.orig_height = visual_image.shape[0]
canvas_width = self.image_canvas.winfo_width()
canvas_height = self.image_canvas.winfo_height()
# 计算缩放比例
self.scale_width = canvas_width / self.orig_width
self.scale_height = canvas_height / self.orig_height
# 根据缩放比例调整图像大小
new_width = int(self.orig_width * self.scale_width)
new_height = int(self.orig_height * self.scale_height)
resized_image = cv2.resize(visual_image, (new_width, new_height))
# 显示调整大小后的图像
pil_image = self.cv2pil(resized_image)
self.photo_image = ImageTk.PhotoImage(pil_image)
self.image_canvas.itemconfig(self.image_id, image=self.photo_image)
def on_win_change(self, event):
"""
监控窗口大小和位置的变化
:param event:
:return:
"""
self.win_change()
def on_key_press(self, event):
"""
监控键盘按键的按下事件,根据按键进行index增减,以进行图片浏览切换
设定规则:
A:上一张
D:下一张
"""
if len(self.result_list) == 0:
return
if event.keysym in ['A', 'a']:
if self.index == 0:
messagebox.showinfo("提示", "已经是第一张图片了")
self.index = max(0, self.index - 1)
elif event.keysym in ['D', 'd']:
if self.index == len(self.img_list) - 1:
messagebox.showinfo("提示", "已经是最后一张图片了")
self.index = min(len(self.img_list)-1, self.index + 1)
else:
messagebox.showinfo("提示", "请按 A 或 D 键进行图片上翻/下翻")
self.display_image()
self.win_change()
def cv2pil(self, cv2_img):
# 转换图片至RGB颜色空间
image = cv2.cvtColor(cv2_img, cv2.COLOR_BGR2RGB)
# 转换图片至PIL格式
return Image.fromarray(image)
def get_filename(self, file_path):
return os.path.splitext(os.path.split(file_path)[-1])[0]
if __name__ == '__main__':
det_kwargs = dict(
model_path='/home/leon/Nextcloud/ChengDu_Research/computer_vision/algorithms/human/person_detection/1.0.1/person_detection_1.0.1.onnx',
img_size=(640, 384),
mode=api.ie.MODE_ORT,
conf_thresh=0.5,
providers=['CUDAExecutionProvider'], # if no GPU, use 'CPUExecutionProvider'
# half=True,
)
app = MyGUI(det_kwargs)
app.mainloop()
请注意:在代码中,我用到了一个目标检测器,你需要替换为你自己的检测器,从而实现不同目标的检测!
代码中和检测相关方法/变量如下:
方法:
run_detect(self, img): 使用检测器对提供的图像进行检测。draw_result(self, img, result): 在图像上绘制检测结果,如边界框和分数。process_files(self, img_list): 处理一个图片列表,对每张图片执行检测。display_image(self): 在GUI上显示当前选中的图片和其检测结果。draw_detections(self, result): 在Canvas上绘制检测结果。show_progress_window(self, img_list): 显示进度条窗口,准备开始处理图片列表。remove_progress_bar(self): 完成图片处理后,移除进度条。变量:
self.detector: 用于存储检测器实例,例如api.YOLOv8。self.classes: 一个字典,用于将检测到的类别ID映射到类别名称。self.img_list: 存储加载的图片路径列表。self.result_list: 存储每张图片的检测结果。self.index: 当前显示图片的索引。self.raw_img_file_path: 记录当前处理的原始图片文件路径。self.visual_image: 用于存储绘制了检测结果的图像。self.photo_image: 用于存储Tkinter能够显示的图像对象。self.image_id: 存储Canvas上图像的ID,用于更新显示的图像。self.scale_width和self.scale_height: 存储图像的缩放比例。
对于我的检测器,这里贴出来一个输出示例:
{
"code": "0",
"message": "",
"data": [
{
"dets": [
{
"id": 0,
"score": 0.7589585781097412,
"bbox": [
873.7188720703125,
236.35150146484375,
910.048095703125,
335.6061706542969
]
},
{
"id": 0,
"score": 0.716355562210083,
"bbox": [
447.7972717285156,
278.9081726074219,
521.7301025390625,
421.3373718261719
]
}
]
}
]
}参考:
tkinter — Python interface to Tcl/Tk — Python 3.12.4 documentation