最快的速度把10亿条数据导入到数据库,首先需要明确一下,10亿条数据什么形式存在哪里,每条数据多大,是否有序导入,是否不能重复,数据库是否是MySQL?
假设和面试官明确后,有如下约束
10亿条数据,每条数据 1 Kb
数据内容是非结构化的用户访问日志,需要解析后写入到数据库
数据存放在Hdfs 或 S3 分布式文件存储里
10亿条数据并不是1个大文件,而是被近似切分为100个文件,后缀标记顺序
要求有序导入,尽量不重复
数据库是 MySQL
首先考虑10亿数据写到MySQL单表可行吗?
数据库单表能支持10亿吗?
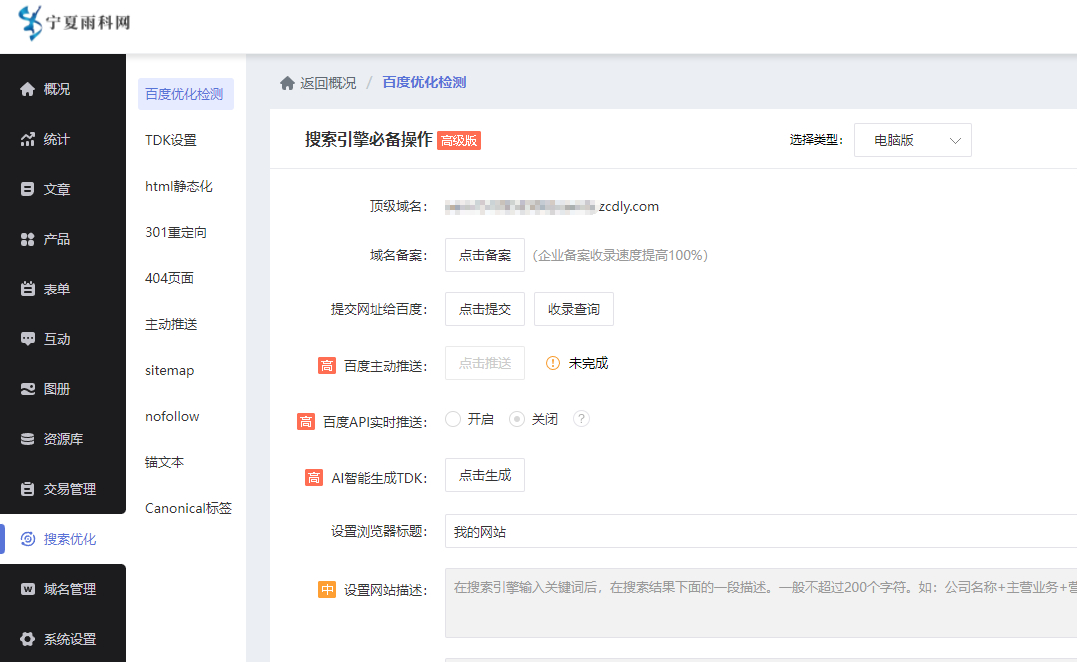
答案是不能,单表推荐的值是2000W以下。这个值怎么计算出来的呢?
MySQL索引数据结构是B+树,全量数据存储在主键索引,也就是聚簇索引的叶子结点上。B+树插入和查询的性能和B+树层数直接相关,2000W以下是3层索引,而2000w以上则可能为四层索引。
Mysql b+索引的叶子节点每页大小16K。当前每条数据正好1K,所以简单理解为每个叶子节点存储16条数据。b+索引每个非叶子节点大小也是16K,但是其只需要存储主键和指向叶子节点的指针,我们假设主键的类型是 BigInt,长度为 8 字节,而指针大小在 InnoDB 中设置为 6 字节,这样一共 14 字节,这样一个非叶子节点可以存储 16 * 1024/14=1170。
也就是每个非叶子节点可关联1170个叶子节点,每个叶子节点存储16条数据。由此可得到B+树索引层数和存储数量的表格。2KW 以上 索引层数为 4 层,性能更差。
如何高效的写入数据库
单条写入数据库性能比较差,可以考虑批量写入数据库,批量数值动态可调整。每条1K,默认可先调整为100条批量写入。
批量数据如何保证数据同时写成功?MySQL Innodb存储引擎保证批量写入事务同时成功或失败。
写库时要支持重试,写库失败重试写入,如果重试N次后依然失败,可考虑单条写入100条到数据库,失败数据打印记录,丢弃即可。
此外写入时按照主键id顺序顺序写入可以达到最快的性能,而非主键索引的插入则不一定是顺序的,频繁地索引结构调整会导致插入性能下降。最好不创建非主键索引,或者在表创建完成后再创建索引,以保证最快的插入性能。
是否需要并发写同一个表
不能
并发写同一个表无法保证数据写入时是有序的。
提高批量插入的阈值,在一定程度上增加了插入并发度。无需再并发写入单表
MySQL存储引擎的选择
Myisam 比innodb有更好的插入性能,但失去了事务支持,批量插入时无法保证同时成功或失败,所以当批量插入超时或失败时,如果重试,势必对导致一些重复数据的发生。但是为了保证更快的导入速度,可以把myisam存储引擎列为计划之一。
现阶段我引用一下别人的性能测试结果:MyISAM与InnoDB对比分析

从数据可以看到批量写入明显优于单条写入。并且在innodb关闭即时刷新磁盘策略后,innodb插入性能没有比myisam差太多。
innodb_flush_log_at_trx_commit: 控制MySQL刷新数据到磁盘的策略。
默认=1,即每次事务提交都会刷新数据到磁盘,安全性最高不会丢失数据。
当配置为0、2 会每隔1s刷新数据到磁盘, 在系统宕机、mysql crash时可能丢失1s的数据。
考虑到Innodb在关闭即时刷新磁盘策略时,批量性能也不错,所以暂定先使用innodb(如果公司MySQL集群不允许改变这个策略值,可能要使用MyIsam了。)。线上环境测试时可以重点对比两者的插入性能。
要不要进行分库
mysql 单库的并发写入是有性能瓶颈的,一般情况5K TPS写入就很高了。
当前数据都采用SSD 存储,性能应该更好一些。但如果是HDD的话,虽然顺序读写会有非常高的表现,但HDD无法应对并发写入,例如每个库10张表,假设10张表在并发写入,每张表虽然是顺序写入,由于多个表的存储位置不同,HDD只有1个磁头,不支持并发写,只能重新寻道,耗时将大大增加,失去顺序读写的高性能。所以对于HDD而言,单库并发写多个表并不是好的方案。回到SSD的场景,不同SSD厂商的写入能力不同,对于并发写入的能力也不同,有的支持500M/s,有的支持1G/s读写,有的支持8个并发,有的支持4个并发。在线上实验之前,我们并不知道实际的性能表现如何。
所以在设计上要更加灵活,需要支持以下能力
支持配置数据库的数量
支持配置并发写表的数量,(如果MySQL是HDD磁盘,只让一张表顺序写入,其他任务等待)
通过以上配置,灵活调整线上数据库的数量,以及写表并发度,无论是HDD还是SSD,我们系统都能支持。不论是什么厂商型号的SSD,性能表现如何,都可调整配置,不断获得更高的性能。这也是后面设计的思路,不固定某一个阈值数量,都要动态可调整。
接下来聊一下文件读取,10亿条数据,每条1K,一共是931G。近1T大文件,一般不会生成如此大的文件。所以我们默认文件已经被大致切分为100个文件。每个文件数量大致相同即可。为什么切割为100个呢?切分为1000个,增大读取并发,不是可以更快导入数据库吗?刚才提到数据库的读写性能受限于磁盘,但任何磁盘相比写操作,读操作都要更快。尤其是读取时只需要从文件读取,但写入时MySQL要执行建立索引,解析SQL、事务等等复杂的流程。所以写的并发度最大是100,读文件的并发度无需超过100。
更重要的是读文件并发度等于分表数量,有利于简化模型设计。即100个读取任务,100个写入任务,对应100张表。
如何保证写入数据库有序
既然文件被切分为100个10G的小文件,可以按照文件后缀+ 在文件行号 作为记录的唯一键,同时保证同一个文件的内容被写入同一个表。例如
index_90.txt 被写入 数据库database_9,table_0 ,
index_67.txt被写入数据库 database_6,table_7。
这样每个表都是有序的。整体有序通过数据库后缀+表名后缀实现。
如何更快地读取文件
10G的文件显然不能一次性读取到内存中,场景的文件读取包括
Files.readAllBytes一次性加载内内存
FileReader+ BufferedReader 逐行读取
File+ BufferedReader
Scanner逐行读取
Java NIO FileChannel缓冲区方式读取
在MAC上,使用这几种方式的读取3.4G大小文件的性能对比
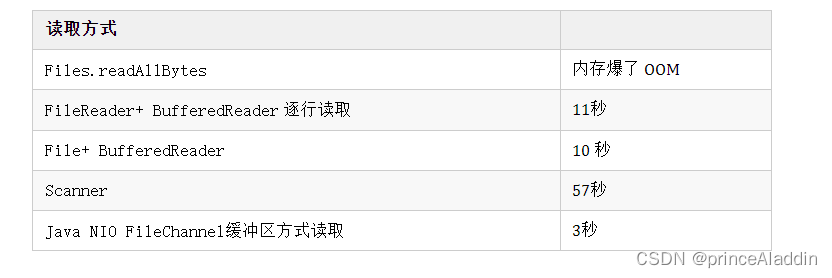
由此可见 使用JavaNIO FileChannnel明显更优,但是FileChannel的方式是先读取固定大小缓冲区,不支持按行读取。也无法保证缓冲区正好包括整数行数据。如果缓冲区最后一个字节正好卡在一行数据中间,还需要额外配合读取下一批数据。如何把缓冲区变为一行行数据,比较困难。
File file = new File("/xxx.zip");
FileInputStream fileInputStream = null;
long now = System.currentTimeMillis();
try {
fileInputStream = new FileInputStream(file);
FileChannel fileChannel = fileInputStream.getChannel();
int capacity = 1 * 1024 * 1024;//1M
ByteBuffer byteBuffer = ByteBuffer.allocate(capacity);
StringBuffer buffer = new StringBuffer();
int size = 0;
while (fileChannel.read(byteBuffer) != -1) {
//读取后,将位置置为0,将limit置为容量, 以备下次读入到字节缓冲中,从0开始存储
byteBuffer.clear();
byte[] bytes = byteBuffer.array();
size += bytes.length;
}
System.out.println("file size:" + size);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//TODO close资源.
}
System.out.println("Time:" + (System.currentTimeMillis() - now));
JavaNIO 是基于缓冲区的,ByteBuffer可转为byte数组,需要转为字符串,并且要处理按行截断。
但是BufferedReader JavaIO方式读取可以天然支持按行截断,况且性能还不错 ,10G文件,大致只需要读取30s,由于导入的整体瓶颈在写入部分,即便30s读取完,也不会影响整体性能。所以文件读取使用BufferedReader 逐行读取。即方案3
如果协调读文件任务和写数据库任务
这块比较混乱,请耐心看完。
100个读取任务,每个任务读取一批数据,立即写入数据库是否可以呢?前面提到了由于数据库并发写入的瓶颈,无法满足1个库同时并发大批量写入10个表,所以100个任务同时写入数据库,势必导致每个库同时有10个表同时在顺序写,这加剧了磁盘的并发写压力。为尽可能提高速度,减少磁盘并发写入带来的性能下降, 需要一部分写入任务被暂停的。那么读取任务需要限制并发度吗?不需要。
假设写入任务和读取任务合并,会影响读取任务并发度。初步计划读取任务和写入任务各自处理,谁也不耽误谁。但实际设计时发现这个方案较为困难。
最初的设想是引入Kafka,即100个读取任务把数据投递到Kafka,由写入任务消费kafka写入DB。100个读取任务把消息投递到Kafka,此时顺序就被打乱了,如何保证有序写入数据库呢?我想到可以使用Kafka partition路由,即读取任务id把同一任务的消息都路由到同一个partition,保证每个partition内有序消费。
要准备多少个分片呢?100个很明显太多,如果partition小于100个,例如10个。那么势必存在多个任务的消息混合在一起。如果同一个库的多个表在一个Kafka partition,且这个数据库只支持单表批量写入,不支持并发写多个表。这个库多个表的消息混在一个分片中,由于并发度的限制,不支持写入的表对应的消息只能被丢弃。所以这个方案既复杂,又难以实现。
所以最终放弃了Kafka方案,也暂时放弃了将读取和写入任务分离的方案。
最终方案简化为 读取任务读一批数据,写入一批。即任务既负责读文件、又负责插入数据库。
如何保证任务的可靠性
如果读取任务进行到一半,宕机或者服务发布如何处理呢?或者数据库故障,一直写入失败,任务被暂时终止,如何保证任务再次拉起时,再断点处继续处理,不会存在重复写入呢?
刚才我们提到可以 为每一个记录设置一个主键Id,即 文件后缀index+文件所在行号。可以通过主键id的方式保证写入的幂等。
文件所在的行号,最大值 大致为 10G/1k = 10M,即10000000。拼接最大的后缀99。最大的id为990000000。
所以也无需数据库自增主键ID,可以在批量插入时指定主键ID。
如果另一个任务也需要导入数据库呢?如何实现主键ID隔离,所以主键ID还是需要拼接taskId。例如{taskId}{fileIndex}{fileRowNumber} 转化为Long类型。如果taskId较大,拼接后的数值过大,转化为Long类型可能出错。
最重要的是,如果有的任务写入1kw,有的其他任务写入100W,使用Long类型无法获知每个占位符的长度,存在冲突的可能性。而如果拼接字符串{taskId}{fileIndex}{fileRowNumber} ,新增唯一索引,会导致插入性能更差,无法满足最快导入数据的诉求。所以需要想另一个方案。
可以考虑使用Redis记录当前任务的进度。例如Redis记录task的进度,批量写入数据库成功后,更新 task进度。
INCRBY KEY_NAME INCR_AMOUNT
指定当前进度增加100,例如 incrby task_offset_{taskId} 100。如果出现批量插入失败的,则重试插入。多次失败,则单个插入,单个更新redis。要确保Redis更新成功,可以在Redis更新时 也加上重试。
如果还不放心Redis进度和数据库更新的一致性,可以考虑 消费 数据库binlog,每一条记录新增则redis +1 。
如果任务出现中断,则首先查询任务的offset。然后读取文件到指定的offset继续 处理。
如何协调读取任务的并发度
前面提到了为了避免单个库插入表的并发度过高,影响数据库性能。可以考虑限制并发度。如何做到呢?
既然读取任务和写入任务合并一起。那么就需要同时限制读取任务。即每次只挑选一批读取写入任务执行。
在此之前需要设计一下任务表的存储模型。

bizId为了以后支持别的产品线,预设字段。默认为1,代表当前业务线。
datbaseIndex 代表被分配的数据库后缀
tableIndex 代表被分配的表名后缀
parentTaskId,即总的任务id
offset可以用来记录当前任务的进度
10亿条数据导入数据库,切分为100个任务后,会新增100个taskId,分别处理一部分数据,即一个10G文件。
status 状态用来区分当前任务是否在执行,执行完成。
如何把任务分配给每一个节点,可以考虑抢占方式。每个任务节点都需要抢占任务,每个节点同时只能抢占1个任务。具体如何实现呢?可以考虑 每个节点都启动一个定时任务,定期扫表,扫到待执行子任务,尝试执行该任务。
如何控制并发呢?可以使用redission的信号量。key为数据库id、
RedissonClient redissonClient = Redisson.create(config);
RSemaphore rSemaphore = redissonClient.getSemaphore("semaphore");
// 设置1个并发度
rSemaphore.trySetPermits(1);
rSemaphore.tryAcquire();//申请加锁,非阻塞。
由任务负责定期轮训,抢到名额后,就开始执行任务。将该任务状态置为Process,任务完成后或失败后,释放信号量。
TaskTassk任务表Redisalt争抢信号量成功定时轮训任务开始查询待执行的任务循环争抢信号量修改任务状态执行中,设置开始时间时间查询当前进度读取文件到从当前进度读取文件,批量导入数据库更新进度执行完成,释放信号量申请下一个任务的信号量TaskTassk任务表Redis
但是使用信号量限流有个问题,如果任务忘记释放信号量,或者进程Crash无法释放信号量,如何处理呢?可以考虑给信号量增加一个超时时间。那么如果任务执行过长,导致提前释放信号量,另一个客户单争抢到信号量,导致 两个客户端同时写一个任务如何处理呢?
what,明明是将10亿数据导入数据库,怎么变成分布式锁超时的类似问题?
实际上 Redisson的信号量并没有很好的办法解决信号量超时问题,正常思维:如果任务执行过长,导致信号量被释放,解决这个问题只需要续约就可以了,任务在执行中,只要发现快信号量过期了,就续约一段时间,始终保持信号量不过期。但是 Redission并没有提供信号量续约的能力,怎么办?
不妨换个思路,我们一直在尝试让多个节点争抢信号量,进而限制并发度。可以试试选取一个主节点,通过主节点轮训任务表。分三种情况,
情况1 当前执行中数量小于并发度。
则选取id最小的待执行任务,状态置为进行中,通知发布消息。
消费到消息的进程,申请分布式锁,开始处理任务。处理完成释放锁。借助于Redission分布式锁续约,保证任务完成前,锁不会超时。
情况2 当前执行中数量等于并发度。
主节点尝试 get 进行中任务是否有锁。
如果没有锁,说明有任务执行失败,此时应该重新发布任务。如果有锁,说明有任务正在执行中。
情况3 当前执行中数量大于并发度
上报异常情况,报警,人工介入
使用主节点轮训任务,可以减少任务的争抢,通过kafka发布消息,接收到消息的进程处理任务。为了保证更多的节点参与消费,可以考虑增加Kafka分片数。虽然每个节点可能同时处理多个任务,但是不会影响性能,因为性能瓶颈在数据库。
那么主节点应该如何选取呢?可以通过Zookeeper+curator 选取主节点。可靠性比较高。
10亿条数据插入数据库的时间影响因素非常多。包括数据库磁盘类型、性能。数据库分库数量如果能切分1000个库当然性能更快,要根据线上实际情况决策分库和分表数量,这极大程度决定了写入的速率。最后数据库批量插入的阈值也不是一成不变的,需要不断测试调整,以求得最佳的性能。可以按照100,1000,10000等不断尝试批量插入的最佳阈值。
总结
要首先确认约束条件,才能设计方案。确定面试官主要想问的方向,例如1T文件如何切割为小文件,虽是难点,然而可能不是面试官想考察的问题。
从数据规模看,需要分库分表,大致确定分表的规模。
从单库的写入瓶颈分析,判断需要进行分库。
考虑到磁盘对并发写的支持力度不同,同一个库多个表写入的并发需要限制。并且支持动态调整,方便在线上环境调试出最优值。
MySQL innodb、myisam 存储引擎对写入性能支持不同,也要在线上对比验证
数据库批量插入的最佳阈值需要反复测试得出。
由于存在并发度限制,所以基于Kafka分离读取任务和写入任务比较困难。所以合并读取任务和写入任务。
需要Redis记录任务执行的进度。任务失败后,重新导入时,记录进度,可避免数据重复问题。
分布式任务的协调工作是难点,使用Redission信号量无法解决超时续约问题。可以由主节点分配任务+分布式锁保证任务排他写入。主节点使用Zookeeper+Curator选取。