一、引言
1、数据库管理系统DBMS的事务处理技术实现的另一个主要功能部分是并发控制机制。并发控制机制完成的功能就是对并发执行的事务进行控制,保证事务的隔离性,从而进一步保持数据库的一致性。
2、事务的并发控制就是对并发执行的不同事务中的数据库的交错执行进行调度,解决并发事务的非串行调度带来的数据不一致问题,使非串行调度可串行化
二、事务的调度
1、事务的调度是指多个并发执行的事务中的并发操作按照它们的执行时间顺序形成的一个操作序列
- 在调度中,某个事务中的操作执行顺序与单个事务执行时的操作顺序应该是相同的
- 但并发事务中的操作可以交错执行
2、在调度中,若每个事务中的操作都是连续执行的,不存在不同事务中的操作的交错执行,则称该调度为串行调度,否则称为非串行调度

(1)对于这里给出的两个事务T1和T2,我们仍用对缓冲区数据的读写来表达对数据库的读写操作,变量t、s分别是事务中的局部变量,不是数据库中的数据,数据X、Y为数据库中的数据在内存缓冲区中的值而不一定是他们在磁盘上的值,同时为了更清晰地表达对数据库的并发操作,后续我们省略掉事务定义语句
(2)则这两个事务的串行调度,可以是T1中的所有操作都在T2中的所有操作前执行,也可以是T1中的所有操作都在T2的所有操作后执行。
(3)如果两个调度中X和Y的初值一样,如X=100,Y=50,则两个串行调度的结果一样,均为X=150,Y=100。

(4)若与事务T1并发执行的事务是事务T3,则这两个事务的串行调度,当两个调度中X、Y的初值一致,假设X=100,Y=50,则结果分别为X=100,Y=100和X=150,Y=100,可见对于并发执行的事务,不同的串行调度的结果并不一样。但不管结果如何,多个并发事务的串行调度结果会与该多个事务的串行执行的一个结果相同。
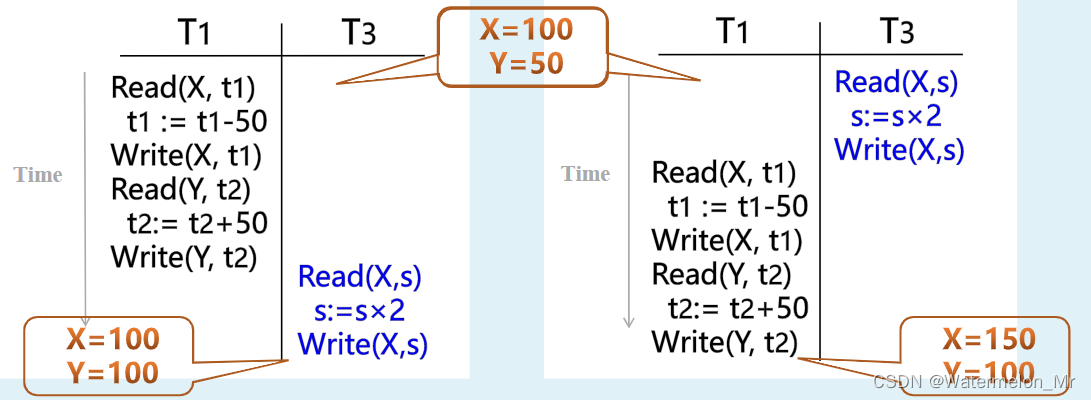
若数据库初始时处于一致性状态,且所有的事务具有一致性,则事务的串行执行将保持数据库的一致性。所以多个并发事务的串行调度也会保持数据库的一致性
3、但并发事务中的并发操作更多地进行交错执行,构成非串行调度


这里给出了事务T1和T2的两个不同的非串行调度。当并发事务非串行调度中的操作读或写缓冲区中同一数据库对象时,就可能会产生数据不一致性问题,主要体现在更新丢失(Lost Update)、脏读(Dirty Read)和不可重复读(Non_Repeatable Read)等方面
三、数据不一致性问题
1、更新丢失(Lost Update)
更新丢失是指在并发执行的非串行调度中,来自不同事务的操作,先后读取同一数据对象并对其进行更新,一个事务对某数据对象的更新结果覆盖了另一个事务对该数据对象的更新结果,导致先写的数据更新结果丢失

比如在事务T1和T2的非串行调度中,事务T1读取了缓冲区中数据对象X之后将X值减少50,但将X值写入缓冲区之前,事务T2也读取了缓冲区中的数据对象X,将X增加了100,又在事务T1将X值写入缓冲区之后,也将X值写入缓冲区。假设X初值为100,这样缓冲区中的数据X的最终结果就是200,只增加了100而没有减少50,不是串行调度的结果150。事务T1对X的更新结果丢失
2、脏读(Dirty Read)
脏读是指在并发事务的非串行调度中,一个事务读取了另一个还没有提交的事务所写的中间结果数据(脏数据)。脏读也就是对脏数据的读取。

比如在事务T1和T2的非串行调度中,事务T1读取了缓冲区中数据对象X之后,将X值减少50并将X值写入缓冲区,假设X的初值为100,此时缓冲区中的数据X的结果就是50,随后事务T2读取了事务T1对X的更新结果并进行计算,即事务T2读取的X值为50,但事务T1在完成之前发生了故障,事务T1撤销回滚,将X的值恢复为事务T1开始时的初值,即100,这样事务T2读取的是夭折事务T1对X的中间更新结果值50,是脏数据,并在此基础上对X进行了更新,使数据库处于不一致状态,
3、不可重复读(Non_Repeatable Read)
不可重复度是指在并发事务的非串行调度中,同一事务对同一数据对象进行多次读取得到不同的结果。

比如在事务T1和T2的非串行调度中,事务T1读取数据对象X,假设此时X的值为100,随后事务T2执行了对数据库对象X的更新操作,X值增加100,当事务T1再次读取数据对象X时,X值为200,无法再现前一次读取的结果,事务T1产生了不可重复读现象。
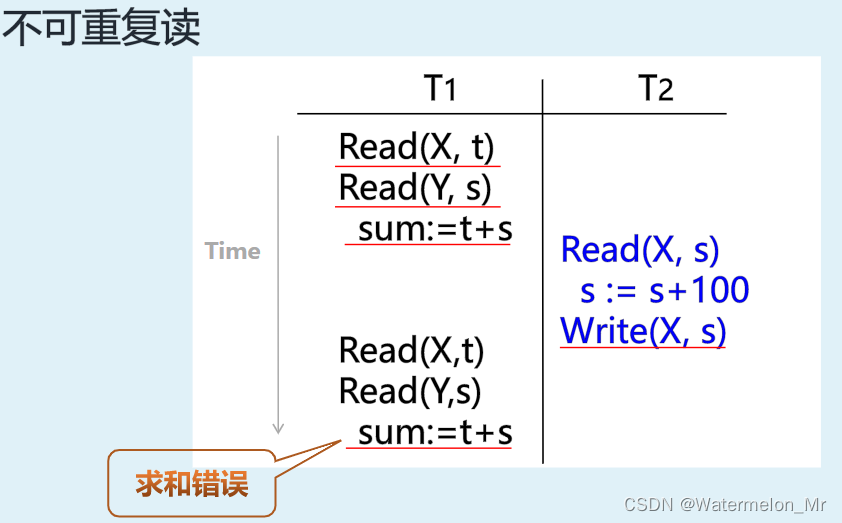
还比如事务T1每次读取X后,又读取数据Y,并对X和Y进行求和,在两次操作之间,事务T2对数据X进行了更新,则事务T1两次的求和结果不同,用户会感觉得到了一个错误的求和结果,这也是一种不可重复读现象
4、产生上述不一致问题的主要原因是并发事务的非串行调度的执行,使并发的事务之间互相干扰,破坏了事务之间的隔离性
5、为解决这些问题,需要对并发执行的事务进行控制,使得一个事务的执行不受其他事务的干扰,从而避免数据的不一致性。由于多个并发事务的串行调度不会破坏数据库的一致性,如果通过控制,将并发事务的非串行调度的执行效果与这些并发事务的串行调度的执行效果相同,则仍可保持数据库的一致性
因此,并发控制要实现的就是并发事务的非串行调度的可串行化
四、非串行调度的可串行化
1、如果n个并发事务的一个非串行调度S的执行效果等价于这n个事务的某个串行调度的执行效果,那我们就称这n个事务的该非串行调度S是可串行化的调度
2、这里的等价是指对于任意的数据库初始状态,调度S和 的执行效果都相同

这里给出两个事务的非串行调度,其中左边的这个调度就是可串行化的,在这个调度中,从任何一个一致的数据库状态开始,其结果都与先执行T1再执行T2的串行调度的结果一样,而右边的这个调度确是一个非可串行化的调度,其结果并不总与T1、T2的任一串行调度的结果相同。虽然可能存在某一算数的巧合,使得其结果相同,但仍是非可串行化的调度,可自行设定初始状态进行验证
3、对于并发事务的非串行调度,当且仅当是可串行化的,才能保持事务的隔离性
4、因此,我们把“可串行化”作为对并发事务进行并发控制的目标
5、而大多数DBMS实现的是一个更强的要求,实现的是并发事务的非串行调度的冲突可串行化
6、冲突是指并发事务非串行调度中一对连续的操作(读操作或写操作),操作应来自不同的事务,如果它们的执行顺序交换后,操作所在的事务中至少有一个的后续操作结果会改变,则这对操作就是冲突的
7、因此,不同事务对不同数据对象的读写操作显然是不冲突的
8、不同事务对同一数据对象的读操作也是不冲突的
9、但不同事务对同一数据对象的读写操作是冲突的。下面我们用ri(X)和wi(X)分别表示某事务Ti从缓冲区读数据X和往缓冲区写数据X。
- 则不同事务对同一数据对象的写操作,即wi(X)和wj(X)是冲突的,因为事务Ti和Tj的写入值可能不同,交换操作的顺序,最终缓冲区中的X值是不同的,丢失的将是不同事务的更新结果

- 不同事务对同一数据对象的读写操作或或写读操作,即ri(X)和wj(X)是冲突的,交换读写操作的顺序会影响到读操作所读到的数据不同,如果将写操作从读操作后移到读操作前,读操作读入的值将是新写入的值,而不是交换前应读到的值,可能会引起读操作所在事务出现不可重复读或脏读现象

10、如果并发事务非串行调度中的相邻操作是非冲突的,则这两个操作是可以交换的,不会影响相关事务的执行效果
11、因此将一事务的非串行调度中相邻的非冲突操作通过一系列的交换后,得到的调度与交换前的调度是等价的,我们称这两个调度是冲突等价的
12、而如果一个非串行调度冲突等价于一个串行调度,也就是将该非串行调度中相邻的非冲突操作进行一系列变换后可转换为一个串行调度,则称该非串行调度是冲突可串行化的
比如,这里给出两个并发事务的一个非串行调度,只列出事务对缓冲区数据的读写操作,忽略了事务读取数据后在内存中的计算,因这些操作的先后不影响调度的执行结果,下面我们来判断一下这个调度是否是冲突可串行化的

经过这一系列的相邻的非冲突操作的交换,得到的新调度序列等价于事务1先执行事务T2再执行大的一个串行调度,因此这里给出的这个非串行调度是冲突可串行化的
13、冲突可串行化是可串行化的一个充分条件,即冲突可串行化调度是可串行化调度
比如对于这里给出的这三个事务,它们各自为B写入一个值,事务T1和T2在为B写入值之前还都为A写入值,其并发执行的一个非串行调度S1,最受使B具有事务T3写入的值,而A具有事务T2写入的值,该调度的执行结果与事务T1、T2和T3依次执行的串行调度S2的执行结果相同,因此非串行调度S1是可串行化的调度,但由于该调度没有可交换的非冲突操作,不能冲突等价于一个串行调度,所以非串行调度S1不是冲突可串行化调度

五、小结
1、DBMS的并发控制机制需采用一定的技术来保证并发事务非串行调度是可串行化的
2、目前常用的并发控制技术有
- 封锁(实现冲突可串行化)
- 时间戳
- 有效确认
3、虽然冲突可串行化不是可串行化的必要条件,但商用DBMS通常实现的是冲突可串行化



![[go-zero] goctl 生成api和rpc](https://img-blog.csdnimg.cn/direct/031b51d3e4474d989c127df27371ac95.png)