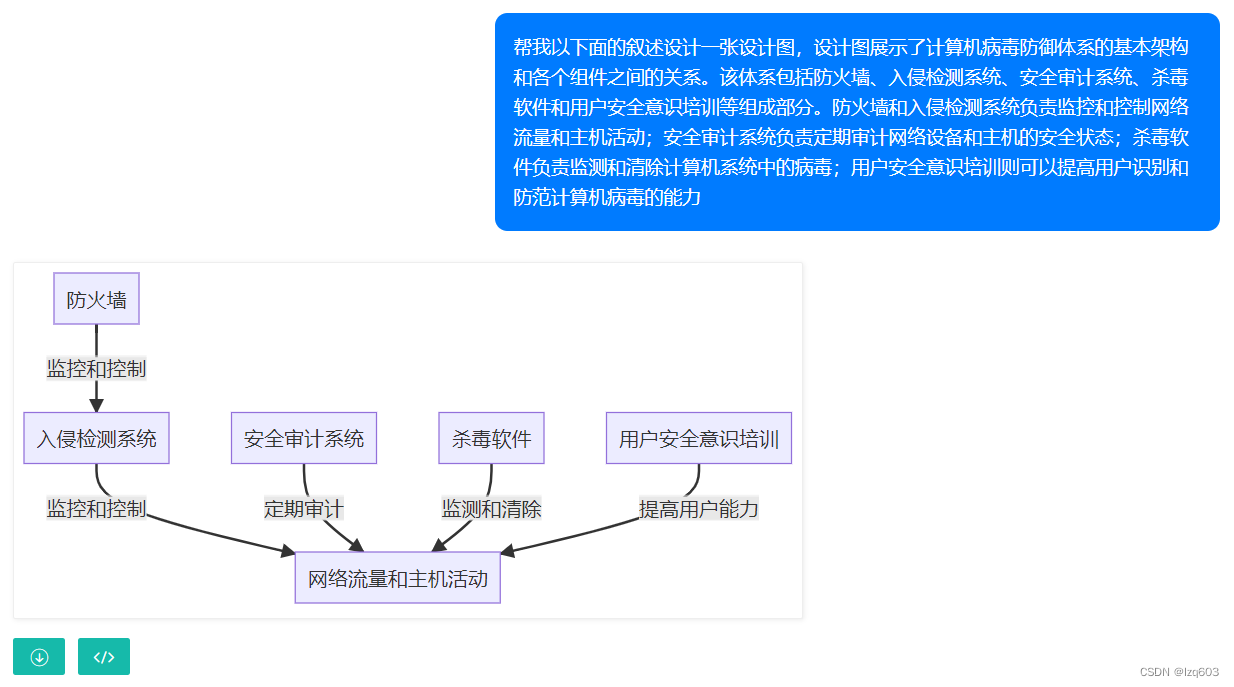
在项目开发 有需求 需要跟硬件通信
也没有mqtt 作为桥接 也不能http 请求 api 所以也不能 json字符串这么爽传输
所以要用tcp 请求 进行数据交互 数据还是16进制的 写法 有帧头 什么的
对于这种物联网的这种对接
我的理解就是 我们做的工作就像翻译
把这些看不懂的 字节流 变成 java 认识的数据
就了解了一下 netty 这个依赖
在springboot 项目种使用这个依赖进行 连接
但是这个依赖 如果不熟悉 使用不当 有可能有内存溢出的风险
所以大家如果自己用这个netty 依赖 做物联网的调用
要小心 最好能找一下 物联网中间件 基于netty封装的
这是我后续 找的一个中间件 也不算很成熟 如果大家有更好用的 欢迎留言 一起分享
http://www.iteaj.com/#/course
但是我发现还是要根据 对接的物联网硬件文档 写自定义解码器 或者编码器
这篇文章主要分享一下 我了解到的 netty 下的 四个解码器 使用方案
概念:
拆包和沾包
是典型的拆包和沾包问题,俗话说就是两端通信,一端发送一端接收,接收的那一端怎么知道是否已经完整的接收了数据?
假设服务端连续发送了两条消息:hello world! / hello client!
由于客户端不知道怎么才算一条消息,怎么才算两条消息,所以读取会有以下几种情况:
1.分两次读取消息,第一次是hello world!,第二次是hello client! 这是正常情况
2.一次就读取完成,hello world!hello client! 这种情况就叫沾包
3.分两次读取消息,第一次是hello ,第二次是world!hello client! 这第一次读取就是拆包,第二次就是沾包
总之就是读取到的信息不完整就是拆包,读取到的信息有额外多的信息就是沾包
解码器就可以来解决这个问题
依赖引入就不说了
先分享代码
netty配置类
package com.netty.server.tpcServer;
import io.netty.bootstrap.Bootstrap;
import io.netty.bootstrap.ServerBootstrap;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.Unpooled;
import io.netty.channel.Channel;
import io.netty.channel.ChannelFuture;
import io.netty.channel.ChannelInitializer;
import io.netty.channel.EventLoopGroup;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.channel.socket.SocketChannel;
import io.netty.channel.socket.nio.NioServerSocketChannel;
import io.netty.channel.socket.nio.NioSocketChannel;
import io.netty.handler.codec.LengthFieldBasedFrameDecoder;
import io.netty.handler.codec.string.StringEncoder;
import io.netty.util.CharsetUtil;
import lombok.extern.slf4j.Slf4j;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
/**
* User:Json
* Date: 2024/4/12
**/
@Component
@Slf4j
public class NettyServer {
private static final Logger logger = LoggerFactory.getLogger(NettyServer.class);
// 服务端NIO线程组
private final EventLoopGroup bossGroup = new NioEventLoopGroup();
private final EventLoopGroup workGroup = new NioEventLoopGroup();
public ChannelFuture start(String host, int port) {
ChannelFuture channelFuture = null;
try {
ServerBootstrap bootstrap = new ServerBootstrap();
bootstrap.group(bossGroup, workGroup)
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel socketChannel) throws Exception {
// 1024 就是规定传入的 字节长度的大小
// 对于字节 一个字符串占多少字节 int 占多多少字节 long 占多多少字节 如果明白这个 应该很好理解
//第一种:LineBasedFrameDecoder:传入的参数是消息最大长度,发送消息的大小必须小于设置值
// 行分隔符解码器(结尾根据 “\n” 作为结束标识)
//socketChannel.pipeline().addLast(new LineBasedFrameDecoder(1024));
//第二种:DelimiterBasedFrameDecoder 自定义分割器解码器,结尾根据什么作为结束标识可以自定义 比如用 |
// socketChannel.pipeline().addLast(new DelimiterBasedFrameDecoder(1024, Unpooled.copiedBuffer("|".getBytes())));
// 第三种: FixedLengthFrameDecoder // 固定长度解码器,发送的消息需要定长
// socketChannel.pipeline().addLast(new FixedLengthFrameDecoder(7));
// 上面三个解码器明显的看到不够灵活 所以还有第四种
//第四种:LengthFieldBasedFrameDecoder:基于长度的自定义解码器,比较灵活 这个
// 这个 解码器 一共有 5个参数
// maxFrameLength:最大帧长度。也就是可以接收的数据的最大长度。如果超过,此次数据会被丢弃
// lengthFieldOffset:长度域偏移量。存储数据长度的一个偏移量
// lengthFieldLength:长度域字节数。存储数据长度的一个大小
// lengthAdjustment:数据长度修正。因为长度既可以代表data的长度,也可以是整个消息的长度
// initialBytesToStrip:跳过的字节数。可以选择舍弃一部分数据
// 可以理解为 我们给数据定义传输规则 就像http请求 定义规则 比如 请求头 数据结构 json 等等
// 所以我们作为接收数据的服务端 可以在开发接收数据的时候 定义规则 然后让客户端按照规则来传输数据
// 比如 发送一个消息,我们定义的结构为:消息头+数据长度+数据
// 我们怎么定义规则呢 比如:
// 整体字节为 15个字节
// 要发送的数据 "Message" 长度为 7个字节
//我们规定 maxFrameLength :1024 接收的最大数据,
// lengthFieldOffset:长度域偏移量 一般用来定义消息头 4个字节、
// lengthFieldLength:长度域字节数 用于定义数据长度(length)的【值】的大小 4个字节
// lengthAdjustment : 0 数据长度修正
// 假设我设置的数据长度是20,代表了整个消息体的长度,但是我数据却只有12个字节,这往后读20个字节无疑是错的,所以我们需要修正,怎么修正? 减8 就行
// 所以如果你需要修正你的 数据长度,那么lengthAdjustment就是用来修正的。
// initialBytesToStrip :8 ,如果在我们业务层只需要 消息体 像消息头 和 数据长度都不需要 那么 initialBytesToStrip就是用来跳过的字节数。
// 就比如 消息头规定 4个字节 数据长度 4个字节 所以我们如果只要 消息体里的内容 就需要跳过 8个字节 所以设置8 即可
// 获取全部数据
// socketChannel.pipeline().addLast(new LengthFieldBasedFrameDecoder(1024,4,4,0,0));
// 只获取消息体里的数据
socketChannel.pipeline().addLast(new LengthFieldBasedFrameDecoder(1024,4,4,0,8));
// 自定义服务处理 所以再进行服务处理之前 需要先经历 解码器 既然有解码器 也有编码器
// 如果我们作为服务端 那就需要编码器 如果我们作为客户端 那就需要解码器
// 解码器主要用于 将接收到的字节数据转换成有意义的业务对象。比如java 认识的 实体类对象
// 在网络编程中,数据在传输过程中通常是以字节数组的形式进行传递的,
// 而业务处理通常需要对这些字节数组进行解析,转换为具体的业务对象。解码器正是完成这一工作的组件
// 而且解码器 还需要 处理拆包和沾包 等 所以我们在使用 tcp 进行通信的时候 到业务层处理 的时候 需要先经过解码器
socketChannel.pipeline().addLast(new ServerHandler());
}
});
// 绑定端口并同步等待
channelFuture = bootstrap.bind(host, port).sync();
log.info("======Start Up Success!=========");
} catch (Exception e) {
e.printStackTrace();
}
return channelFuture;
}
public void close() {
workGroup.shutdownGracefully();
bossGroup.shutdownGracefully();
log.info("======Shutdown Netty Server Success!=========");
}
//测试 main
public static void main(String[] args) throws Exception {
EventLoopGroup group = new NioEventLoopGroup();
try {
Bootstrap bootstrap = new Bootstrap();
bootstrap.group(group)
.channel(NioSocketChannel.class)
.handler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ch.pipeline().addLast(new StringEncoder());
}
});
ChannelFuture channelFuture = bootstrap.connect("192.168.0.209", 17070).sync();
Channel channel = channelFuture.channel();
// 连续发送多条消息
for (int i = 0; i < 100; i++) {
//System.getProperty("line.separator") 获取系统换行符 测试一种情况
// String message = "Message " + i + System.getProperty("line.separator");
// String message = "Message " + i+"|"; //测试第二种情况
// String message = "Message"; // 第三种 固定长度情况
// channel.writeAndFlush(message);
//第四种 自定义解码器
//[4个字节 + 4个字节 + 数据]
// 我们传输数据 就要这样拼接数据 消息头 +数据长度+数据
String message = "Message"+i;
//消息头 4个字节
ByteBuf byteBuf = Unpooled.buffer();
byteBuf.writeInt(102); //【lengthFieldOffset】 4个字节
// 102 测试随便写的 只要是占4个字节的数字就行 为啥写个102就4个字节 因为102 是int类型 int类型的字节数是4个字节
// 这个应该是 数据类型基础 int string long 等等 占几个字节的问题
//数据长度 4个字节 长度也是 int型 所以跟消息头 一样 所以在设置解码器长度参数的时候 【lengthFieldLength】 4个字节就够用
byteBuf.writeInt(message.getBytes().length);
//发送的数据
byteBuf.writeBytes(Unpooled.copiedBuffer(message, CharsetUtil.UTF_8));
channel.writeAndFlush(byteBuf);
// Thread.sleep(100); // 可能需要调整间隔时间
}
channel.closeFuture().sync();
} finally {
group.shutdownGracefully();
}
}
}
回调类
package com.netty.server.tpcServer;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.Unpooled;
import io.netty.channel.ChannelHandlerContext;
import io.netty.channel.ChannelInboundHandlerAdapter;
import io.netty.util.CharsetUtil;
import java.text.SimpleDateFormat;
import java.util.Date;
/**
* User:Json
* Date: 2024/4/12
**/
public class ServerHandler extends ChannelInboundHandlerAdapter {
/**
* 客户端数据到来时触发
*/
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
ByteBuf buf = (ByteBuf) msg;
//第一种到第三种解码器测试
// System.out.println("client request: " + buf.toString(CharsetUtil.UTF_8)+"======");
// SimpleDateFormat sf = new SimpleDateFormat("yyyy/MM/dd HH:mm:ss");
// String callback = sf.format(new Date());
// ctx.write(Unpooled.copiedBuffer(callback.getBytes()));
//第四种 自定义解码器测试
System.out.println("========================");
// 获取全部数据
// System.out.println("消息头:"+buf.readInt());
// int i = buf.readInt();
// System.out.println("数据长度:"+i);
// System.out.println("消息体:"+buf.readBytes(i).toString(CharsetUtil.UTF_8));
//只获取消息体里的数据
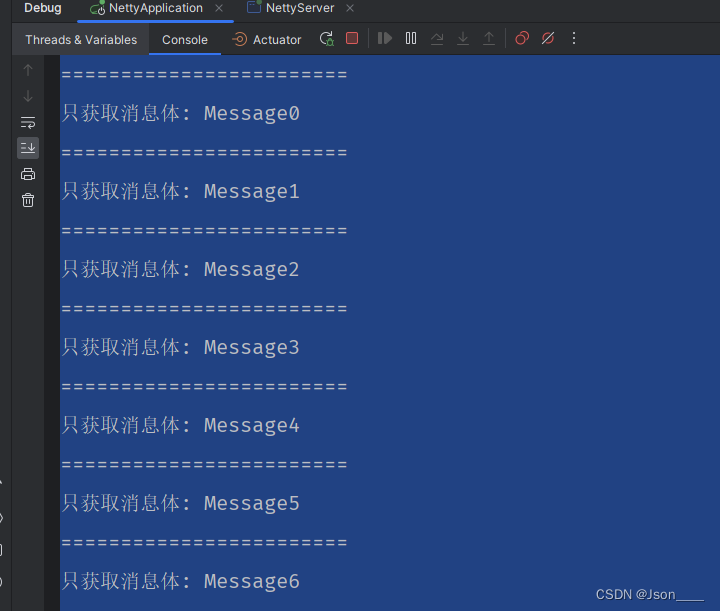
System.out.println("只获取消息体: "+buf.toString(CharsetUtil.UTF_8));
}
@Override
public void channelReadComplete(ChannelHandlerContext ctx) throws Exception {
// 将发送缓冲区的消息全部写到SocketChannel中
ctx.flush();
}
/**
* 发生异常时触发
*/
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception {
System.out.println(cause.getMessage());
cause.printStackTrace();
// 释放与ChannelHandlerContext相关联的资源
ctx.close();
}
}
springboot 启动时运行
package com.netty.server.init;
import com.netty.server.tpcServer.NettyServer;
import io.netty.channel.ChannelFuture;
import lombok.extern.slf4j.Slf4j;
import org.springframework.boot.CommandLineRunner;
import org.springframework.core.annotation.Order;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
/**
* User:Json
* Date: 2024/4/12
**/
@Component
@Slf4j
@Order(2)
public class NettyServerInit implements CommandLineRunner {
@Resource
private NettyServer nettyServer;
// 这个 线程 后续优化 比如关闭 等等
@Override
public void run(String... args) throws Exception {
// 开启服务
ChannelFuture future = nettyServer.start("192.168.0.209", 17070);
// 在JVM销毁前关闭服务
Runtime.getRuntime().addShutdownHook(new Thread() {
@Override
public void run() {
nettyServer.close();
}
});
future.channel().closeFuture().sync();
}
}
核心测试代码 在 NettyServer 类里
下面逐个分享一下解码器的 意思 :
第一种:
new LineBasedFrameDecoder(1024)
1024 就是规定传入的 字节长度的大小
对于字节 一个字符串占多少字节 int 占多多少字节 long 占多多少字节 如果明白这个 应该很好理解
LineBasedFrameDecoder:传入的参数是消息最大长度,发送消息的大小必须小于设置值
行分隔符解码器(结尾根据 “\n” 作为结束标识)
第二种:
new DelimiterBasedFrameDecoder(1024, Unpooled.copiedBuffer("|".getBytes()))
DelimiterBasedFrameDecoder 自定义分割器解码器,结尾根据什么作为结束标识可以自定义 比如用 |
第三种:
new FixedLengthFrameDecoder(7)
// 固定长度解码器,发送的消息需要定长
第四种:重点
new LengthFieldBasedFrameDecoder(1024,4,4,0,0)
第四种:LengthFieldBasedFrameDecoder:基于长度的自定义解码器,比较灵活 这个
这个 解码器 一共有 5个参数
maxFrameLength:最大帧长度。也就是可以接收的数据的最大长度。如果超过,此次数据会被丢弃
lengthFieldOffset:长度域偏移量。存储数据长度的一个偏移量
lengthFieldLength:长度域字节数。存储数据长度的一个大小
lengthAdjustment:数据长度修正。因为长度既可以代表data的长度,也可以是整个消息的长度
initialBytesToStrip:跳过的字节数。可以选择舍弃一部分数据
可以理解为 我们给数据定义传输规则 就像http请求 定义规则 比如 请求头 数据结构 json 等等
所以我们作为接收数据的服务端 可以在开发接收数据的时候 定义规则 然后让客户端按照规则来传输数据
比如 发送一个消息,我们定义的结构为:消息头+数据长度+数据
对于字节 一个字符串占多少字节 int 占多多少字节 long 占多多少字节 如果明白这个 应该很好理解
我们怎么定义规则呢 比如:
整体字节为 15个字节
要发送的数据 “Message” 长度为 7个字节
我们规定 maxFrameLength :1024 接收的最大数据,
lengthFieldOffset:长度域偏移量 一般用来定义消息头 4个字节、
lengthFieldLength:长度域字节数 用于定义数据长度(length)的【值】的大小 4个字节
lengthAdjustment : 0 数据长度修正
假设我设置的数据长度是20,代表了整个消息体的长度,但是我数据却只有12个字节,这往后读20个字节无疑是错的,所以我们需要修正,怎么修正? 减8 就行
所以如果你需要修正你的 数据长度,那么lengthAdjustment就是用来修正的。
initialBytesToStrip :8 ,如果在我们业务层只需要 消息体 像消息头 和 数据长度都不需要 那么 initialBytesToStrip就是用来跳过的字节数。
就比如 消息头规定 4个字节 数据长度 4个字节 所以我们如果只要 消息体里的内容 就需要跳过 8个字节 所以设置8 即可
结合发送端和 接收数据端 一个例子 整体
接收数据端的 定义
socketChannel.pipeline().addLast(new LengthFieldBasedFrameDecoder(1024,4,4,0,8));
发送端
//第四种 自定义解码器
//[4个字节 + 4个字节 + 数据]
// 我们传输数据 就要这样拼接数据 消息头 +数据长度+数据
String message = "Message"+i;
//消息头 4个字节
ByteBuf byteBuf = Unpooled.buffer();
byteBuf.writeInt(102); //【lengthFieldOffset】 4个字节
// 102 测试随便写的 只要是占4个字节的数字就行 为啥写个102就4个字节 因为102 是int类型 int类型的字节数是4个字节
// 这个应该是 数据类型基础 int string long 等等 占几个字节的问题
//数据长度 4个字节 长度也是 int型 所以跟消息头 一样 所以在设置解码器长度参数的时候 【lengthFieldLength】 4个字节就够用
byteBuf.writeInt(message.getBytes().length);
//发送的数据
byteBuf.writeBytes(Unpooled.copiedBuffer(message, CharsetUtil.UTF_8));
channel.writeAndFlush(byteBuf);
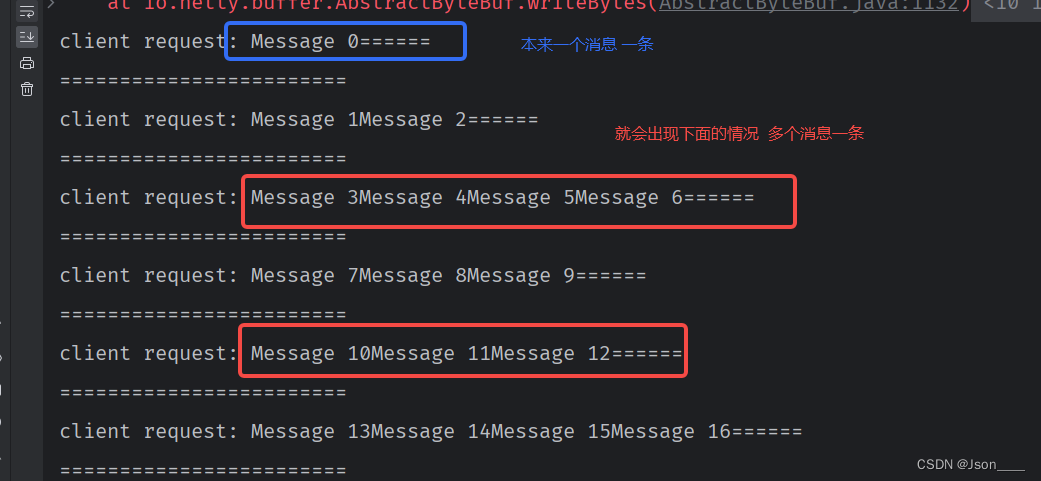
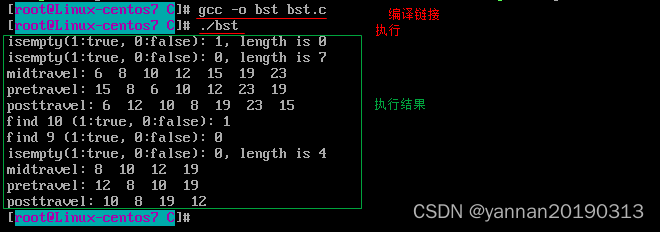
测试结果
没有解码器的情况
有了之后:
补充: socketChannel.pipeline().addLast()
这里addLast() 可以添加很多 各种处理器
比如
解码器
编码器
编码器
日志处理器
超时处理器
等等 使用的时候 添加顺序也要注意一下




![[图解]分析模式高阶+课程讲解03物品模式](https://img-blog.csdnimg.cn/direct/b0960148e0c8448c91ca5265137ae2df.png)
![[Cloud Networking] OSPF](https://img-blog.csdnimg.cn/direct/70fbaafc6078451cb23ec9e98b596777.png)