说明
在第一步获取数据源,然后进入Mongo(第一个数据节点)开始,QTV200的数据流体系就开始动了。后续用多少时间完成不太好确定,短则数周,长则数月。毕竟有过第一版实验的基础,应该还是可以做到的。
下面就是天马行空,简单的想想,梳理一下,后续会更清楚写。
内容
1 第一版做了什么?
第一版只在很有限的几个标的上实验,主要就是沪深300、中证500、券商和医药,还有就是很早之前(甚至早到研究生论文)关注过的军工ETF。
在获取数据后,我快速做了两个版本。一个版本完全是基于惯性(回归),另一个版本是基于动量做的。后来证明,惯性的方法甚至不一定比动量的差。大概是因为ETF本身已经形成了较为稳定的分布。
后来进行了回测,以及通过短信通知的操作方式进行实盘实验。最初我认为,模型的决策能力比人强,这个本身没有错;差别点在于,人类的操盘手,他们进行交易决策时所依赖的数据与模型的并不相同。很多时候是在模式的状态下工作的。所以,即使模型的决策能力比人强,但是由于数据维度的“不公平”,所以很难说模型一定超过人类。
但是anyway,在去年到今年一年的时间里,模型一直以回测状态在运行,虽然没有很高的收益,但是没亏钱,在这个行情下说不定超额收益蛮高的(沪深300亏了20个点吧)。当然,我觉得qtv本身有很大的提升空间,即使在过去一年这样的行情下,我认为仍然应当取得稳定收益。从实盘的观测上看,这是存在可能性的。这也是qtv200的目标和意义。
第一版的意义在于真正意义上开始了这件事
其实从我的眼光来看,第一版从技术上讲是不及格的。其中既包括了当时所用的技术架构,也包括了从业务上看不具备足够的单量和盈亏比表现。自我批判和自我否定是必要的,但绝对不是去抹掉第一版的成果 ,而是要充分吸收当时做的好的地方,然后利用现在新的工具,以及实际操作之后的经验,来更上一层楼。
架构上,当时用了所谓的ADBS方法,也就是队列+mongo+apifunc的方式。这种方式从表现上看,IO上过于低效了,在流程上也比较冗杂,是基于标的一个个的建立mongo数据库和stream来进行的。现在通过flask-celery提供异步worker,会完全解决掉IO问题,至少支持60~100个标的没有问题。这肯定会解决掉单量不足的问题。
无可以持续改进的数据基础。这可能是较为隐性的问题,当我有灵感,想要再次给这个系统加buff的时候,突然发现是无从下手的。这体现了在数据流设计上的缺失 ,没法进行扩展和修改。现在通过UCS,从机制上,所有的工作已经被统一了。另外,基于flask-celery-aps形成的数据流体系,也使得改造变得尤其简单。(刚刚做完从clickhouse - mongo的转变,丝滑的不可思议) 基于新的数据流系统,持续改善以及分布式执行都将得到大幅提升。
模型的机制缺陷。最初我只是简单的做判别模型,一个潜在的风险是什么呢? 具备大涨可能性的同时,也具备大跌的可能性。所以最终策略还能不亏钱,已经算是还蛮厉害了。(毕竟每个订单都存在0.5%的费率损失) 这个将在qtv200得到很大的改善,但有很多更高级的方法,现在我尚无工程结论。
没有区分模式。最初我是想寻找一个子空间,让模型处在更高的概率区间运行的,但是失败了。我记得主要的原因是一旦筛选了概率,那么数据支持度就会不够。现在想想,我建模的时候是基于空间的,但模式并不一定非得基于空间啊,应该可以基于时间,或者时空。
回测机制效率低。具体的细节我没有再去查探了,应该是这样的。而且很多同质的信号。但是,这种类似与随机优化的方式,也还是值得在精神上肯定一下的。
交易机制有bug。发现的时候已经太晚了,而且很不好改,所以也就放弃了。主要是在最大持有和卖出的时间上有问题,要么周期未到,要么连消息都漏了,要么就是收盘后给我发一个当前3:00平仓的信号,简直无语。主要是自己做的,没其他人可抱怨,都怨我,哈哈。
以上是我觉得不及格原因,没有夸张。但反过来想,这样都能在这种行情下不亏钱(甚至还略有盈余),所以这事靠谱啊。
第一版并不是一无是处的,除了勇气之外,技术有一些地方可以肯定,并且我也打算复用。
变量的特征处理标准化。 当时时间紧任务急,我最担心的是开发和生产时的特征处理不一致,所以使用了VV(Var & VFrame)对象来确保特征的统一生成。最终确实是一种不错的方法,即使操作稍显冗余,但也是workable的,并且这种模式很容易向智能(Agent)方法发展,因为中间的过程都是参数化操作。
模型标准对象。 我将模型的预测和使用封装为一个基类对象,可以更好的流水线生产模型。我觉得这次可以稍微先用一下,看有没有机会用更好的方式进行封装,或者进行改造(例如和MLR方法对接)
2 现在又有了什么
马斯克说,创新并不总是创造出全新的东西,在新的环境下,即使是把老的东西用新的方法再做一次,也是创新。我深以为然。
我一直是在遵循第一性理论,基于我对一件事(比如量化)的想象,不断的去学习、实验,来找到那个第一性答案。实际能看到的变化是,我的工具、方法一直在按一种线性的方式前进。这还是挺让我感到欣慰的,毕竟目标还是0,过程中能看到一些实证还是挺好的。
在过去的一年里,肉眼可见的变化还是很多的:
- 1 异步任务系统。简单点说就是flask-celery-aps, 过去定位有问题,想用这个来进行通用的分布式,这是不太行的。但是作为IO的worker,这个是非常合适的。这个系统可以帮助我更有效的构建数据流(大幅减少时间),使得在当前硬件下,可以支持足够etf的吞吐。同时,这使得分布式工作变得自然。
- 2 算力租用机。在过去的一年里,算力租用这件事对我变得非常自然,我也至少对3个平台的租用和部署比较熟悉了。这对我之后进行超大规模计算提供了算力基础。
- 3 clickhouse。这个很有用,至少有两方面:块读取和统计分析。这个数据库可以提供近乎内存的读取和计算速度。
- 4 pydantic。 过去没有重视,随着大模型的研究,这个浮出水面。这可以大幅简化配置、数据规范化传递、数据节点定义等工作。既有编程上的帮助(简单),也有结构上的帮助(数据流中数据节点的具象描述)。
- 5 GlobalFuncs & GFGoLite & Basefuncs: 最初是全局函数,后来因为怕概念太大没等设计好就荒废了,所以迅速弄了GFGoLite,一个轻一点但是马上能用的服务,后来又觉得本地包也需要(和GFGoLite几乎同源),所以有了这么几个形态。这些工具既能提供编程帮助,也蕴含了规范约束(UCS),还有想未来智能演化的潜质(间接使用、参数化调用、Agent)
- 6 GlobalBuffer。这个可以作为worker的元数据缓存,确保每次的运行是可以有状态的。
- 7 强化学习。这块强行粗浅的入了门,算是战略部署。最后在业务上体现的系统效果是通过强化学习来完成的。
- 8 关于模型和策略的方面的新想法。一个想法是模式优先。一个想法是模型目标,以盈利而非赢单为目标。
- 9 简单有限状态机(SFSM)。一种可以更明确和有效定义运行状态的方法。
- 10 Streamlit & Gradio。后端到前端的快速投射,一个使用与做快速的web展示,一个可以做更复杂的后端操作。
- 11 异步请求与异步服务。异步请求将可以使对多个微服务系统的数据请求同步完成。
- 12 Nginx的反向代理与负载均衡。这块经过更多的测试和调整,减少开放的web端口,并真正实现有效的负载均衡。
虽然还感觉有无数的东西要完善,感觉自己做的还不够好,不过回头过一看,还是有不少收获的。毕竟我算是偏笨一些的,只能靠长期堆量来找到正确的方式。这么一想,心理就平衡了。
3 接下来怎么做
首先是数据规划。明确每个数据节点的作用与形态,which should/could be pydantical。
下面是之前画的一个草图。由于异步任务系统的存在,可以认为当前本地资源可以确保60~100个标的的流转不会有任何问题。绿色的都是队列:队列的一端必然连接worker,worker是绝对灵活的。
上次修改是的[行情数据Out] --(s2ch)-->[行情数据], 取消了s2ch,而是用一个临时的worker(xxx s2mongo.py)替代了,解决了数据可能存在的重复问题。
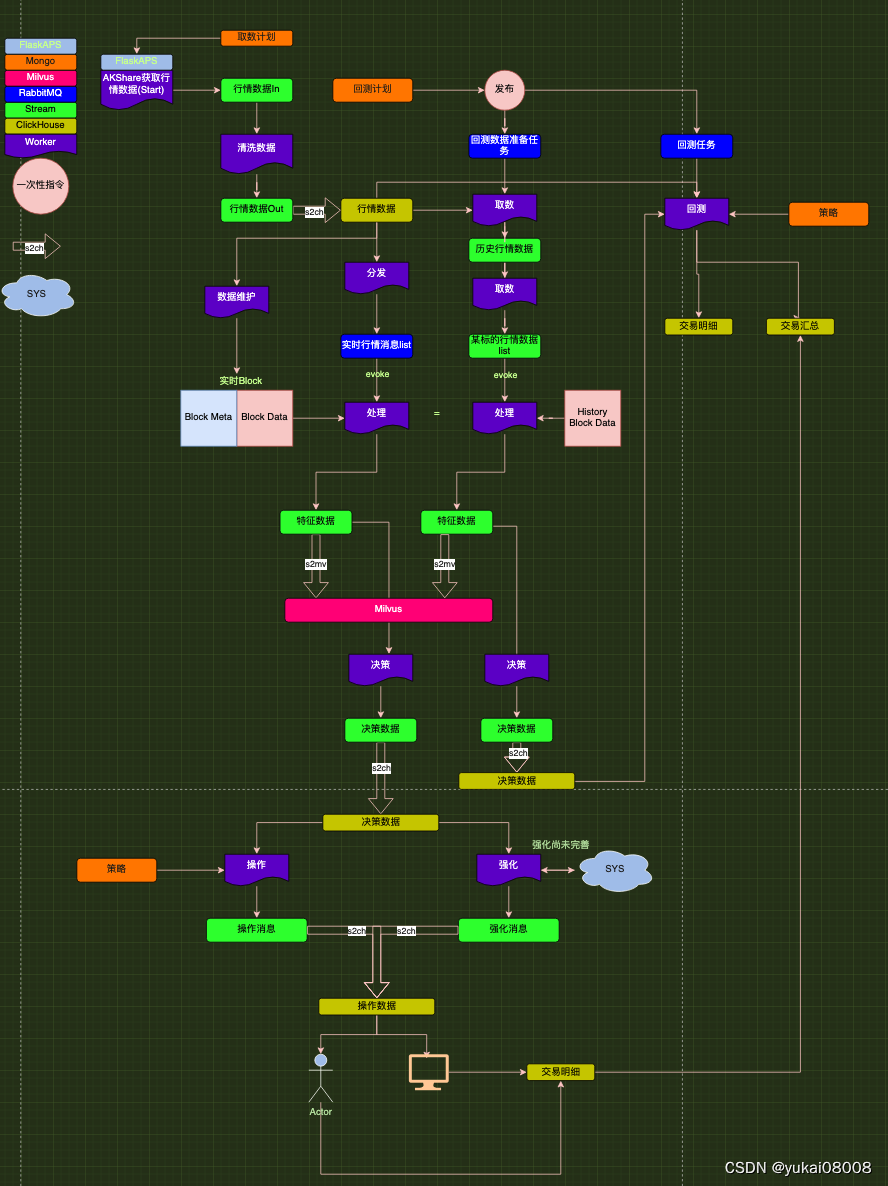
在第一步完成了之后,可以将历史数据补全,然后下一步有三个分支。
- 1 【实时数据保持】将所需的block在内存中进行实时保留。
- 2 【特征生成】【数据分析】【模式识别】形成一套方案,根据前N个block数据形成一套特征。即时间转空间特征。对应的工具是VV。本次在进入特征生成之前,先进行基础的数据分析。需要形成描述性的技术指标,供分析和思考。需要得到的成果是,可以根据技术指标,快速的获得总体态势感知、策略表现等。另外,要能够形成 一套模式识别方法。
- 3 【回测】回测时将预先生成好所有可生成的数据,然后按照时间轴向前推进。使用的对象包括TimeTraveller,执行的方式将通过RabbitMQ任务方式。
这里要注意,结构化数据将从mongo出提取出,然后存入clickhouse。这个机制需要补上,而且后续形成的可解释、结构化的结果,应该都存入clickhouse:这样方便block读取,也可以快速统计。
这部分要学习一下在 ClickHouse 中处理更新和删除, ch支持块级删除让我觉得太适合UCS了,UCS本身就强调以块为单位操作。
再下一步就是指定具体的策略,以及通过强化学习来进行挑选,并和操作进行集成,暂且不提。




![[Ant Design Vue 树控件Tree]内存溢出报错](https://img-blog.csdnimg.cn/direct/bd6970794fd643f58577ad84968b52f9.png)