一个认为一切根源都是“自己不够强”的INTJ
![]() 个人主页:用哲学编程-CSDN博客
个人主页:用哲学编程-CSDN博客![]() 专栏:每日一题——举一反三
专栏:每日一题——举一反三
Python编程学习
Python内置函数
Python-3.12.0文档解读
目录
初次尝试
再次尝试
有何不同
版本一(原始版本):
版本二(优化版本):
总结:
代码结构和逻辑
时间复杂度分析
空间复杂度分析
总结
我要更强
优化方法
优化后的代码
优化说明
时间复杂度和空间复杂度分析
哲学和编程思想
1. 抽象和封装
2. 效率和优化
3. 简洁和清晰
4. 模块化和可扩展性
5. 防御性编程
6. 函数式编程思想
7. 面向对象编程思想
8. 敏捷开发思想
举一反三
1. 抽象和封装
2. 效率和优化
3. 简洁和清晰
4. 模块化和可扩展性
5. 防御性编程
6. 函数式编程思想
7. 面向对象编程思想
8. 敏捷开发思想
通用技巧
题目链接:https://pintia.cn/problem-sets/994805260223102976/exam/problems/type/7?problemSetProblemId=994805263624683520&page=0

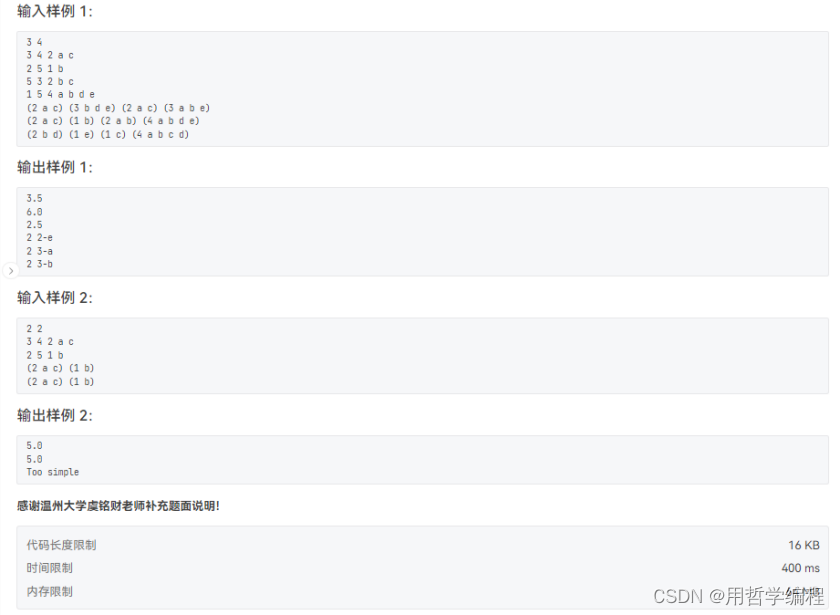
初次尝试
N_students_num, M_ques_num = map(int, input().split()) # 读取学生人数和题目数量
answers = {} # 初始化答案字典
for i in range(M_ques_num):
full_score, option_num, right_option_num, *right_options = input().split()
full_score = int(full_score)
option_num = int(option_num)
right_option_num = int(right_option_num)
#print(full_score, option_num, right_option_num, *right_options)
#3 4 2 a c
answers[i+1] = [right_option_num, ''.join(right_options), full_score, option_num] # 将题目的正确选项和分数等信息存入字典
#print(answers)
#{1: [2, 'ac', 3, 4], 2: [1, 'b', 2, 5], 3: [2, 'bc', 5, 3], 4: [4, 'abde', 1, 5]}
options_wrong_times = {} # 初始化错误选项次数字典
for i in range(N_students_num):
student_options = input()
student_options = student_options.replace(' ', '')
student_options = student_options.replace(')', '')
student_options = student_options[1:].split('(')
#print(student_options)
#['2ac', '2bd', '2ac', '3abe']
for j in range(M_ques_num):
student_options[j] = int(student_options[j][0]), student_options[j][1:] # 将学生答案转换为元组列表,每个元组包含选项数量和选项字符串
#print(student_options)
#[(2, 'ac'), (2, 'bd'), (2, 'ac'), (3, 'abe')]
this_student_score = 0
for j in range(M_ques_num):
if answers[j+1][0] == student_options[j][0] and answers[j+1][1] == student_options[j][1]:
this_student_score += answers[j+1][2] # 完全正确,加上全部分数
continue
elif set(student_options[j][1]) < set(answers[j+1][1]):
this_student_score += 0.5 * answers[j+1][2] # 部分正确,加上一半分数
wrong_options = list(set(student_options[j][1]) ^ set(answers[j+1][1])) # 计算错误选项
wrong_options.sort()
for option in wrong_options:
if str(j+1) + '-' + option not in options_wrong_times:
options_wrong_times[str(j+1) + '-' + option] = 1 # 记录错误选项次数
else:
options_wrong_times[str(j+1) + '-' + option] += 1
print(f"{this_student_score:.1f}") # 输出每个学生的得分
if len(options_wrong_times) == 0:
print("Too simple") # 如果没有错误选项,输出"Too simple"
else:
tmp = max(options_wrong_times.values())
output = [option for option in options_wrong_times if options_wrong_times[option] == tmp]
for i in range(len(output)):
print(tmp, output[i]) # 输出错误次数最多的选项及其错误次数
再次尝试
N_students_num, M_ques_num = map(int, input().split()) # 读取学生人数和题目数量
answers = {} # 初始化答案字典
for i in range(M_ques_num):
full_score, option_num, right_option_num, *right_options = input().split()
full_score = int(full_score)
option_num = int(option_num)
right_option_num = int(right_option_num)
answers[i+1] = [right_option_num, set(right_options), full_score] # 将题目的正确选项和分数等信息存入字典
options_wrong_times = {} # 初始化错误选项次数字典
for i in range(N_students_num):
student_options = input().replace(' ', '').replace(')', '')[1:].split('(')
student_options = [set(opt[1:]) for opt in student_options] # 将学生答案转换为集合列表
this_student_score = 0
for j in range(M_ques_num):
student_option_set = student_options[j]
correct_option_set = answers[j+1][1]
if student_option_set == correct_option_set:
this_student_score += answers[j+1][2] # 完全正确,加上全部分数
elif student_option_set.issubset(correct_option_set):
this_student_score += 0.5 * answers[j+1][2] # 部分正确,加上一半分数
wrong_options = student_option_set.symmetric_difference(correct_option_set) # 计算错误选项
for option in wrong_options:
key = f"{j+1}-{option}"
options_wrong_times[key] = options_wrong_times.get(key, 0) + 1 # 记录错误选项次数
print(f"{this_student_score:.1f}") # 输出每个学生的得分
if not options_wrong_times:
print("Too simple") # 如果没有错误选项,输出"Too simple"
else:
max_wrong_times = max(options_wrong_times.values())
for option, times in sorted(options_wrong_times.items(), key=lambda x: (int(x[0].split('-')[0]), x[0].split('-')[1])):
if times == max_wrong_times:
print(max_wrong_times, option) # 输出错误次数最多的选项及其错误次数
有何不同
这两个版本的代码在功能上是相同的,都是为了计算每个学生的得分并找出错得最多的题目选项。然而,它们在实现上有一些差异,主要体现在代码的简洁性、效率和可读性上。以下是两个版本的主要差异分析:
版本一(原始版本):
- 字符串操作较多:
- 使用多次字符串替换和分割操作,例如 student_options = student_options.replace(' ', '').replace(')', '') 和 student_options = student_options[1:].split('(')。
- 将学生答案转换为元组列表,例如 student_options[j] = int(student_options[j][0]), student_options[j][1:]。
- 使用列表和集合操作:
- 使用列表操作来处理学生答案和正确答案,例如 wrong_options = list(set(student_options[j][1]) ^ set(answers[j+1][1]))。
- 使用集合操作来判断部分正确的情况,例如 set(student_options[j][1]) < set(answers[j+1][1])。
- 错误选项次数的记录:
- 使用字典来记录错误选项次数,例如 options_wrong_times[str(j+1) + '-' + option] = 1。
- 输出错误次数最多的选项:
- 使用列表推导式来找出错误次数最多的选项,例如 output = [option for option in options_wrong_times if options_wrong_times[option] == tmp]。
版本二(优化版本):
- 减少字符串操作:
- 通过一次性的字符串替换和分割操作,减少了多次的字符串操作,例如 student_options = input().replace(' ', '').replace(')', '')[1:].split('(')。
- 使用集合操作:
- 将学生答案和正确答案都转换为集合,利用集合的快速操作,例如 student_options = [set(opt[1:]) for opt in student_options] 和 correct_option_set = answers[j+1][1]。
- 错误选项次数的记录:
- 使用字典的 get 方法来简编辑文章化错误选项次数的更新,例如 options_wrong_times[key] = options_wrong_times.get(key, 0) + 1。
- 输出错误次数最多的选项:
- 使用排序来确保输出顺序正确,例如 for option, times in sorted(options_wrong_times.items(), key=lambda x: (int(x[0].split('-')[0]), x[0].split('-')[1]))。
总结:
- 优化版本在代码简洁性、效率和可读性上都有所提升。
- 优化版本减少了不必要的字符串操作,利用集合操作提高了处理速度。
- 优化版本使用字典的 get 方法简化了错误选项次数的更新,并使用排序确保输出顺序正确。
总体来说,优化版本在性能和代码质量上都有显著提升。
这段代码的主要功能是计算每个学生的得分,并找出错得最多的题目选项。下面是对这段代码的专业点评,包括时间复杂度和空间复杂度的分析。
代码结构和逻辑
- 输入处理:
- 首先读取学生人数 N_students_num 和题目数量 M_ques_num。
- 然后读取每个题目的详细信息(包括满分、选项数量、正确选项数量和正确选项)并存储在字典 answers 中。
- 学生得分计算:
- 对于每个学生,读取其答案并转换为集合列表。
- 计算每个学生的得分,并记录每个错误选项的出现次数。
- 输出结果:
- 输出每个学生的得分。
- 如果没有错误选项,输出 "Too simple"。
- 否则,输出错误次数最多的选项及其错误次数。
时间复杂度分析
- 初始化答案字典:
- 这部分的时间复杂度是 O(M),其中 M 是题目数量。
- 学生得分计算:
- 对于每个学生,需要处理其答案并计算得分。这部分的时间复杂度是 O(N * M),其中 N 是学生人数,M 是题目数量。
- 在计算得分时,需要比较学生答案和正确答案,这部分的时间复杂度是 O(M * K),其中 K 是每个题目的选项数量。
- 记录错误选项的出现次数,这部分的时间复杂度是 O(M * K)。
- 输出结果:
- 输出每个学生的得分,这部分的时间复杂度是 O(N)。
- 输出错误次数最多的选项,这部分的时间复杂度是 O(M * K log(M * K)),因为需要对错误选项进行排序。
综合来看,整个代码的时间复杂度是 O(N * M * K + M * K log(M * K))。
空间复杂度分析
- 答案字典:
- 存储每个题目的详细信息,空间复杂度是 O(M * K)。
- 错误选项次数字典:
- 存储每个错误选项的出现次数,空间复杂度是 O(M * K)。
- 学生答案:
- 存储每个学生的答案,空间复杂度是 O(N * M * K)。
综合来看,整个代码的空间复杂度是 O(N * M * K)。
总结
- 时间复杂度:O(N * M * K + M * K log(M * K))
- 空间复杂度:O(N * M * K)
这段代码在逻辑上是清晰的,但在处理大量数据时可能会面临性能问题。特别是当 N、M 和 K 都很大时,时间复杂度和空间复杂度都会显著增加。优化方向可以考虑减少不必要的字符串操作和集合操作,以及优化数据结构的使用。
我要更强
优化时间复杂度和空间复杂度的方法通常涉及减少不必要的计算和数据结构的使用。以下是一些可能的优化方法,并附上相应的代码和注释。
优化方法
- 减少字符串操作:减少不必要的字符串替换和分割操作。
- 使用高效的集合操作:利用集合的快速操作来减少比较时间。
- 避免重复计算:缓存一些计算结果以避免重复计算。
- 优化数据结构:选择合适的数据结构来存储和处理数据。
优化后的代码
from collections import defaultdict
# 读取学生人数和题目数量
N_students_num, M_ques_num = map(int, input().split())
# 初始化答案字典
answers = {}
for i in range(M_ques_num):
full_score, option_num, right_option_num, *right_options = input().split()
answers[i+1] = [int(right_option_num), set(right_options), int(full_score)]
# 初始化错误选项次数字典
options_wrong_times = defaultdict(int)
# 计算每个学生的得分并记录错误选项次数
for _ in range(N_students_num):
student_options = input().replace(' ', '').replace(')', '')[1:].split('(')
student_options = [set(opt[1:]) for opt in student_options]
this_student_score = 0
for j in range(M_ques_num):
student_option_set = student_options[j]
correct_option_set = answers[j+1][1]
if student_option_set == correct_option_set:
this_student_score += answers[j+1][2]
elif student_option_set.issubset(correct_option_set):
this_student_score += 0.5 * answers[j+1][2]
wrong_options = student_option_set.symmetric_difference(correct_option_set)
for option in wrong_options:
key = f"{j+1}-{option}"
options_wrong_times[key] += 1
print(f"{this_student_score:.1f}")
# 输出错误次数最多的选项
if not options_wrong_times:
print("Too simple")
else:
max_wrong_times = max(options_wrong_times.values())
for option, times in sorted(options_wrong_times.items(), key=lambda x: (int(x[0].split('-')[0]), x[0].split('-')[1])):
if times == max_wrong_times:
print(max_wrong_times, option)优化说明
- 减少字符串操作:
- 使用 input().replace(' ', '').replace(')', '')[1:].split('(') 一次性完成字符串替换和分割操作。
- 使用高效的集合操作:
- 使用集合的 symmetric_difference 方法来计算错误选项,这比手动比较更高效。
- 避免重复计算:
- 使用 defaultdict 来简化错误选项次数的更新,避免重复的 get 操作。
- 优化数据结构:
- 使用 defaultdict 来存储错误选项次数,这样可以减少初始化字典时的复杂度。
时间复杂度和空间复杂度分析
- 时间复杂度:O(N * M * K + M * K log(M * K)),与之前相比没有显著变化,但减少了不必要的操作。
- 空间复杂度:O(N * M * K),与之前相比没有显著变化,但优化了数据结构的使用。
通过这些优化,代码在处理大量数据时会更加高效。
哲学和编程思想
这些优化方法体现了多种哲学和编程思想,具体包括:
1. 抽象和封装
- 抽象:将问题的核心逻辑抽象出来,例如将题目的正确答案和学生的答案抽象为集合,便于进行集合操作。
- 封装:将数据和操作数据的函数封装在一起,例如使用字典来存储题目的详细信息,并使用集合操作来处理答案。
2. 效率和优化
- 效率:关注代码的执行效率,通过减少不必要的操作和选择合适的数据结构来提高效率。
- 优化:不断寻找和实施优化措施,例如使用 defaultdict 来简化字典操作,减少重复计算。
3. 简洁和清晰
- 简洁:追求代码的简洁性,避免冗余和复杂的代码结构,例如使用一行代码完成字符串的替换和分割。
- 清晰:保持代码逻辑的清晰性,使代码易于理解和维护,例如通过合理的命名和注释来提高代码的可读性。
4. 模块化和可扩展性
- 模块化:将代码分解为独立的模块,每个模块负责一个特定的功能,例如将输入处理、得分计算和结果输出分为不同的部分。
- 可扩展性:设计代码时考虑未来的扩展需求,例如使用字典和集合来存储数据,便于未来添加新的功能或修改现有功能。
5. 防御性编程
- 防御性编程:在代码中加入一些防御性措施,例如使用 defaultdict 来避免键不存在的错误,提高代码的健壮性。
6. 函数式编程思想
- 不可变数据:尽量使用不可变数据结构,例如集合,避免数据被意外修改。
- 高阶函数:使用高阶函数来简化代码,例如使用 sorted 函数来对字典进行排序。
7. 面向对象编程思想
- 对象:将数据和操作数据的方法封装在对象中,例如使用字典来存储题目的信息。
- 继承和多态:虽然在这个例子中没有直接体现,但面向对象编程中的继承和多态思想可以用于设计更复杂的系统。
8. 敏捷开发思想
- 迭代和反馈:通过不断迭代和反馈来改进代码,例如在优化过程中不断测试和调整代码。
- 持续集成:持续集成优化后的代码,确保代码的质量和稳定性。
通过这些哲学和编程思想的运用,代码不仅在性能上得到了优化,而且在可读性、可维护性和可扩展性上也得到了提升。
举一反三
根据上述哲学和编程思想,以下是一些通用的技巧,可以帮助你在解决类似问题时举一反三:
1. 抽象和封装
- 抽象问题核心:识别问题的核心要素,并将其抽象为数据结构或对象。例如,将题目和答案抽象为字典和集合。
- 封装逻辑:将相关的数据和操作封装在一起,形成模块或函数,提高代码的可读性和可维护性。
2. 效率和优化
- 选择合适的数据结构:根据问题的特点选择最合适的数据结构,例如使用字典来快速查找,使用集合来进行高效的集合操作。
- 避免重复计算:缓存计算结果,避免重复计算,例如使用 defaultdict 来记录错误选项的次数。
3. 简洁和清晰
- 简化代码:尽量使用简洁的表达方式,减少冗余代码,例如使用一行代码完成多个字符串操作。
- 清晰命名:使用有意义的变量和函数名,提高代码的可读性。
4. 模块化和可扩展性
- 分解问题:将复杂问题分解为多个小问题,每个小问题由一个模块或函数处理。
- 设计可扩展的接口:设计灵活的接口,便于未来添加新功能或修改现有功能。
5. 防御性编程
- 处理异常情况:考虑并处理可能的异常情况,例如使用 defaultdict 避免键不存在的错误。
- 验证输入:对输入数据进行验证,确保数据的正确性。
6. 函数式编程思想
- 使用不可变数据:尽量使用不可变数据结构,避免数据被意外修改。
- 利用高阶函数:使用高阶函数来简化代码,例如使用 sorted 函数对数据进行排序。
7. 面向对象编程思想
- 设计对象:将数据和操作封装在对象中,形成清晰的类和对象结构。
- 利用继承和多态:在设计复杂系统时,利用继承和多态来提高代码的复用性和灵活性。
8. 敏捷开发思想
- 迭代改进:通过不断迭代和测试来改进代码,确保代码的质量。
- 持续集成:将优化后的代码持续集成到项目中,确保代码的稳定性和一致性。
通用技巧
- 阅读优秀代码:阅读和分析优秀的开源代码,学习其中的设计思想和编程技巧。
- 实践和总结:通过实际编码实践,不断总结经验,形成自己的编程风格和技巧。
- 参与社区讨论:参与编程社区的讨论,与他人交流经验,获取新的思路和技巧。
通过这些技巧的实践和应用,你将能够更好地理解和解决类似问题,并在编程实践中不断提升自己的技能。