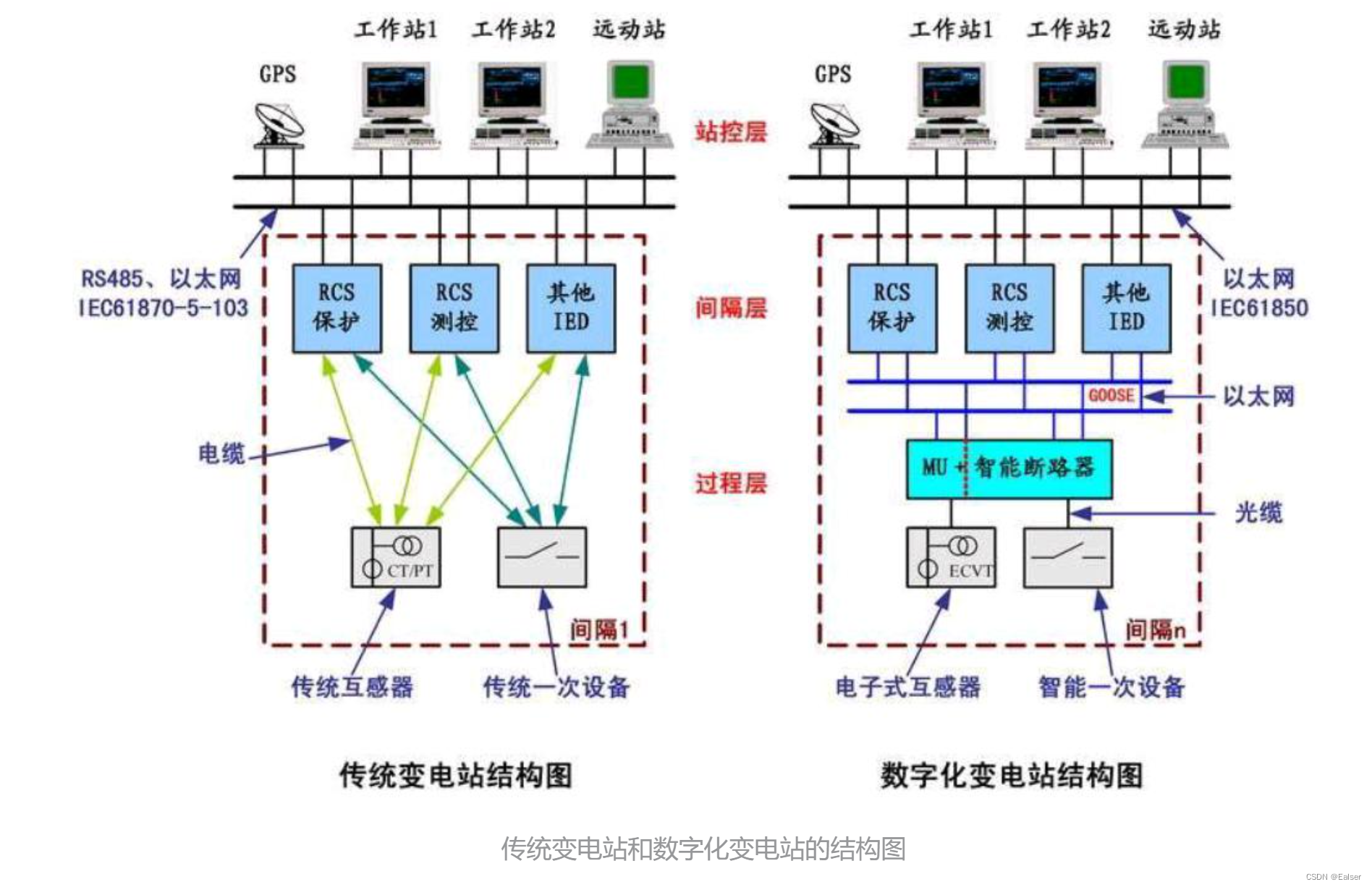
一、引言
论文: DN-DETR: Accelerate DETR Training by Introducing Query DeNoising
作者: IDEA
代码: DN-DETR
注意: 该算法是在DAB-DETR基础上的改进,在学习该算法前,建议掌握DETR、DAB-DETR等相关知识。
特点: 指出DETR收敛慢的另一个主要原因为二分图匹配的不稳定性,提出对真实目标的锚框信息和标签信息施加噪声并将其喂入解码器中,使解码器进行去噪操作的训练方式。去噪部分引入了真实目标信息且不需要二分图匹配,所以有利于原始匹配部分的稳定从而加速收敛。
二、为什么降噪能加速DETR的训练
2.1 使匈牙利匹配更加稳定
前期的优化过程通常是随机的,导致每次的预测结果可能有比较大的波动。例如,对于同一个查询,第一次预测该查询与图片中的狗🐶匹配,第二次预测该查询可能就与图片中的汽车🚗匹配了。匈牙利匹配结果的巨大变化,进一步导致优化目标的不一致,模型需要反反复复进行学习修正才能逐渐稳定,所以收敛速度自然就慢了。
所以作者引入施加了噪声的真实目标信息,包括目标的中心坐标、宽高、类别。因为它们有明确的对应目标,将它们也添加到解码器中获得的预测是不需要进行二分图匹配的,也就缓解了匈牙利匹配的不稳定性。
为描述训练前期匈牙利匹配的不稳定性,作者提出了一种指标:
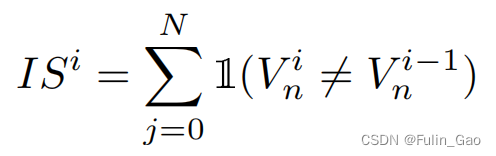
其中, I ( ⋅ ) \mathbb{I}(\cdot) I(⋅)为指示函数,括号中内容成立为1,否则为0; V n i V_n^i Vni表示第 i i i个epoch的第n个查询经解码器后得到的预测目标的匹配情况,定义如下:
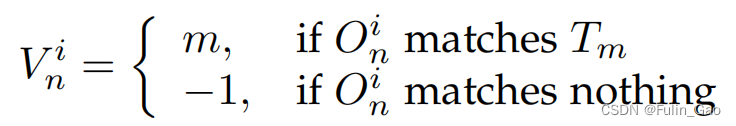
其中, O i = { O 0 i , O 1 i , ⋯ , O N − 1 i } \mathbf{O}^i=\{O_0^i,O_1^i,\cdots,O_{N-1}^i\} Oi={O0i,O1i,⋯,ON−1i}表示N个预测目标, T = { T 0 , T 1 , ⋯ , T M − 1 } \mathbf{T}=\{T_0,T_1,\cdots,T_{M-1}\} T={T0,T1,⋯,TM−1}表示M个真实目标。
可以看出, I S i IS^i ISi越高表明本次迭代时匈牙利匹配结果与上次的匹配结果相差越大,即不稳定性越大。

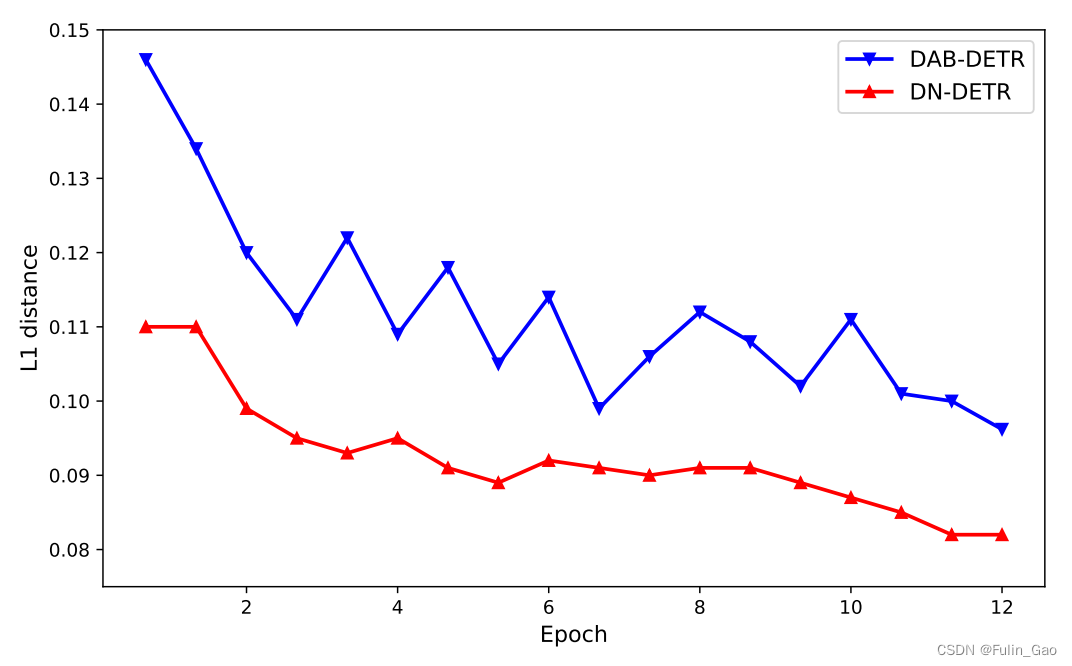
上图为DETR、DAB-DETR、DN-DETR前12个epoch的 I S IS IS变化情况,可以看出,DN-DETR的稳定性要好于另外两个方法,也就说明了降噪操作能够使匈牙利匹配更加稳定。
2.2 使搜索范围更加局部化
因为降噪训练所引入的锚框虽然施加了噪声,但是其所处位置仍然在真实目标附近,所以模型在调整预测位置时不必进行全局搜索,而是只进行局部搜索就可以了。锚框和目标框之间距离的缩短使得训练过程更加简单,收敛也就更快。
上图为DETR和DAB-DETR训练过程中锚框与目标框之间的距离,可以看出,DN-DETR的锚框与目标框之间的距离更小,所以训练难度更低,收敛速度也就更快。
三、框架
3.1 施加噪声
DN-DETR施加的噪声是在真实目标上的,包括三个部分:中心坐标 ( x , y ) (x,y) (x,y)、宽高 ( w , h ) (w,h) (w,h)、标签 l l l。
对于中心坐标 ( x , y ) (x,y) (x,y),会施加随机偏移。 偏移量要满足 ∣ Δ x ∣ < λ 1 w 2 |\Delta x|<\frac{\lambda_1 w}{2} ∣Δx∣<2λ1w、 ∣ Δ y ∣ < λ 1 h 2 |\Delta y|<\frac{\lambda_1 h}{2} ∣Δy∣<2λ1h的限制,其中 λ 1 ∈ ( 0 , 1 ) \lambda_1\in(0,1) λ1∈(0,1)。 λ 1 \lambda_1 λ1的取值范围能够保证中心坐标的偏移不会过大,无论如何偏移,新的中心坐标仍然位于旧框之中。
对于宽高 ( w , h ) (w,h) (w,h),会施加随机缩放。 缩放后的范围在 [ ( 1 − λ 2 ) w , ( 1 + λ 2 ) w ] [(1-\lambda_2)w,(1+\lambda_2)w] [(1−λ2)w,(1+λ2)w]、 [ ( 1 − λ 2 ) h , ( 1 + λ 2 ) h ] [(1-\lambda_2)h,(1+\lambda_2)h] [(1−λ2)h,(1+λ2)h]之间,其中 λ 2 ∈ ( 0 , 1 ) \lambda_2\in(0,1) λ2∈(0,1)。并没有固定的缩放程度,而是在上述范围内随机取宽、高。
对于标签 l l l,会施加随机翻转。 翻转是以 γ \gamma γ的概率将标签改为另一个随机标签。
3.2 注意力掩吗
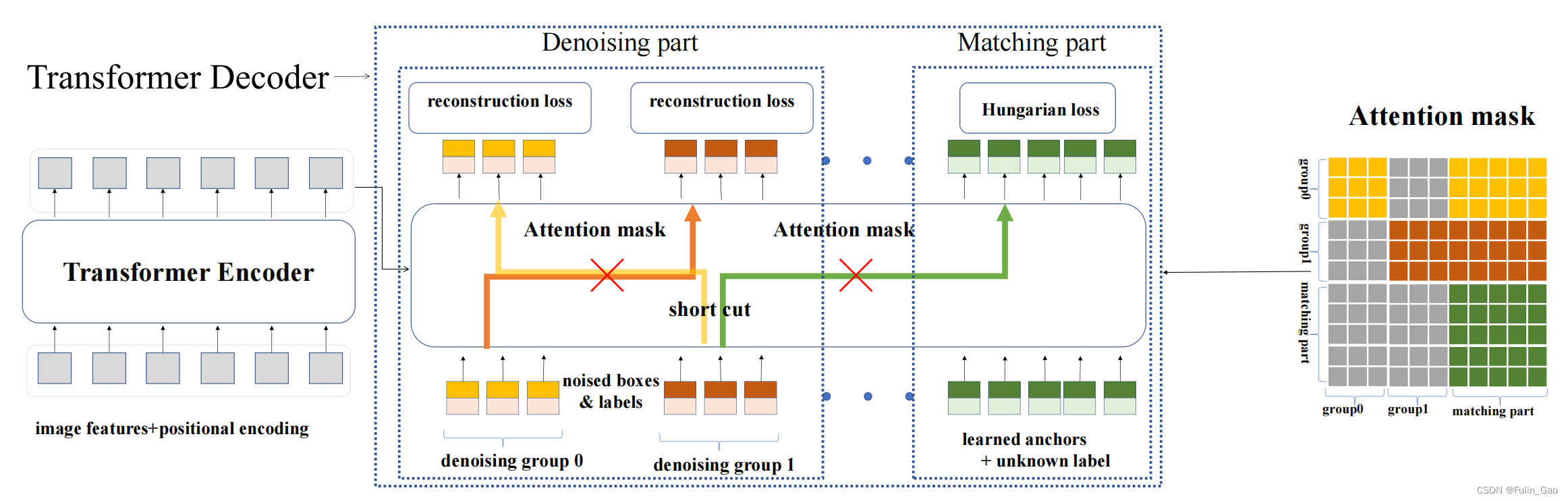
DN-DETR引入了 P P P个版本的噪声,这些噪声有差别但都满足3.1中的条件。假设一张训练图片中有 M M M个目标,施加 P P P个版本的噪声后,就会得到 P P P组带噪目标,共 M × P M\times P M×P个新的带噪目标。假设原始一张图片有N个查询,新的带噪目标会作为额外的查询与原始查询拼接到一起,于是形成 M × P + N M\times P+N M×P+N个查询。原始查询就是DAB-DETR中的300个查询。
⚠️ DN-DETR将与带噪目标相关的部分称为去噪部分,将与原始查询相关的部分称为匹配部分。
虽然新的查询中被施加了噪声,但其仍然包含真实目标的信息,如果不同组之间的查询能够相互访问,那学习过程可能会异常简单。此外,如果新的查询与原始查询之间能够相互访问,那么与噪声相关的部分就无法与原始查询解耦,当进入无法获取真实目标信息的推理阶段时,整个方法就瘫痪了。所以DN-DETR引入了注意力掩码来避免这两个问题,注意力掩码矩阵如下:

图中, P = 2 , M = 3 , N = 5 P=2,M=3,N=5 P=2,M=3,N=5;匹配部分表示 N N N个原始查询;灰色部分表示对应查询不可访问,彩色部分表示可以访问。访问是单向的。
从图中可以看出,组0可以与自身、匹配部分通信。与自身不必多说,可以访问匹配部分是因为匹配部分中不包含任何与真实目标相关的信息,所以开放给组0访问也没关系。组1与组0类似,但组0与组1相互均不可访问。匹配部分要与去噪部分解耦,所以只能访问自身。
3.3 与DAB-DETR的差别
⚠️ DN-DETR只是提供了一个训练策略,在推理的时候与去噪部分相关的内容和操作都会被移除,变得与DAB-DETR完全一样。
所以,DN-DETR和DAB-DETR在结构上的差别很小。下图为DAB-DETR和DN-DETR的解码器中交叉注意力部分的结构图:

如上图所示,二者的主要差别在于查询部分Q的解码器嵌入(初始化全0)替换为了类别标签嵌入+指示项。这种替换是为了同时进行标签和锚框的去噪,否则原始输入中只有可学习锚框与中心坐标 ( x , y ) (x,y) (x,y)、宽高 ( w , h ) (w,h) (w,h)相关,没有与标签 l l l相关的部分。
对于类别标签嵌入,要先由nn.Embedding初始化一个尺寸为 ( n u m _ c l a s s e s + 1 , h i d d e n _ d i m − 1 ) (num\_classes+1,hidden\_dim-1) (num_classes+1,hidden_dim−1)的矩阵。 n u m _ c l a s s e s + 1 num\_classes+1 num_classes+1中 n u m _ c l a s s e s num\_classes num_classes指数据集的类别总数, + 1 +1 +1表示额外增加的未知类。 h i d d e n _ d i m hidden\_dim hidden_dim是原始查询的维度, − 1 -1 −1表示减去一个维度留给指示项。对于去噪部分的 M × P M\times P M×P个查询,它们有明确的类别(施加噪声后的),所以可以直接从矩阵中索引对应的特征。对于匹配部分的 N N N个查询,它们不知道与什么类别匹配,均被假设为未知类,用矩阵的最后一个特征表达。剩下的那个维度用指示项填补,指示项用于表示当前查询属于原始的匹配部分(0)还是新增的去噪部分(1)。
对于可学习锚框,匹配部分按照DAB-DETR进行均匀分布的初始化,去噪部分直接使用施加噪声后的中心坐标和宽高。
下图为DN-DETR的结构图:
总结下来,DAB-DETR和DN-DETR仅训练时有差别,差别是:
(1) 解码器嵌入被换成了类别标签嵌入+指示项。嵌入部分由nn.Embedding初始化,匹配部分按未知类取最后一个特征,去噪部分按噪声类别取对应索引的特征。指示项为0表示匹配部分,为1表示去噪部分。
(2) 输入查询的数量从
N
N
N变成了
M
×
P
+
N
M\times P+N
M×P+N。
M
×
P
M\times P
M×P是该图片中
M
M
M个真实目标被施加了
P
P
P个版本的噪声后得到的锚框和标签。
(3) 为了避免通信带来的问题,引入了注意力掩码。
(4) 与原始查询拼接在一起的去噪查询也会经解码器输出框和标签预测。为实现去噪,对于框使用l1 loss和GIOU loss,对于标签使用Focal loss,三个loss合并称为重构损失(reconstruction loss)。
致谢:
本博客仅做记录使用,无任何商业用途,参考内容如下:
DN-DETR 论文简介
DN-DETR 源码解析