目录
Numpy科学计算库
什么是多维数组
数组基础
高维数组
操作和创建数组
Numpy介绍
创建数组
数组的属性
二维数组
三维数组
数组元素的数据类型
创建特殊的数组
np.arange()
np.ones()
np.zeros()
np.eye()
np.linspace()
np.logspace()
asarray()
数组运算常用函数
数组元素的切片——一维数组
数组元素的切片——二维数组
改变数组形状
创建数组并且改变数组的形状
数组间的运算
矩阵运算——矩阵乘法
矩阵运算——矩阵相乘
矩阵运算——转置和求逆
数组间的运算概念
sum():数据求和
一维数组(rank=1)
二维数组(rank=2)
三维数组(rank=3)
其他函数与sum类似
数组的堆叠运算
一维数组堆叠
二维数组堆叠
矩阵和随机数
矩阵运算-矩阵相乘
矩阵运算--转置、求逆
随机数
打乱顺序函数
Python能够成为目前最流行和最广泛使用的编程语言之一,最重要的原因是,他拥有出色的第三方库生态系统,借助他们可以极大的缩短开发周期,更高效的解决问题。在这一章中,我们将会介绍一些神经网络和深度学习中常用的库,为后续的学习打下基础。
直通车:机器学习基础:与Python关系和未来发展-CSDN博客
Numpy科学计算库
什么是多维数组
数组基础
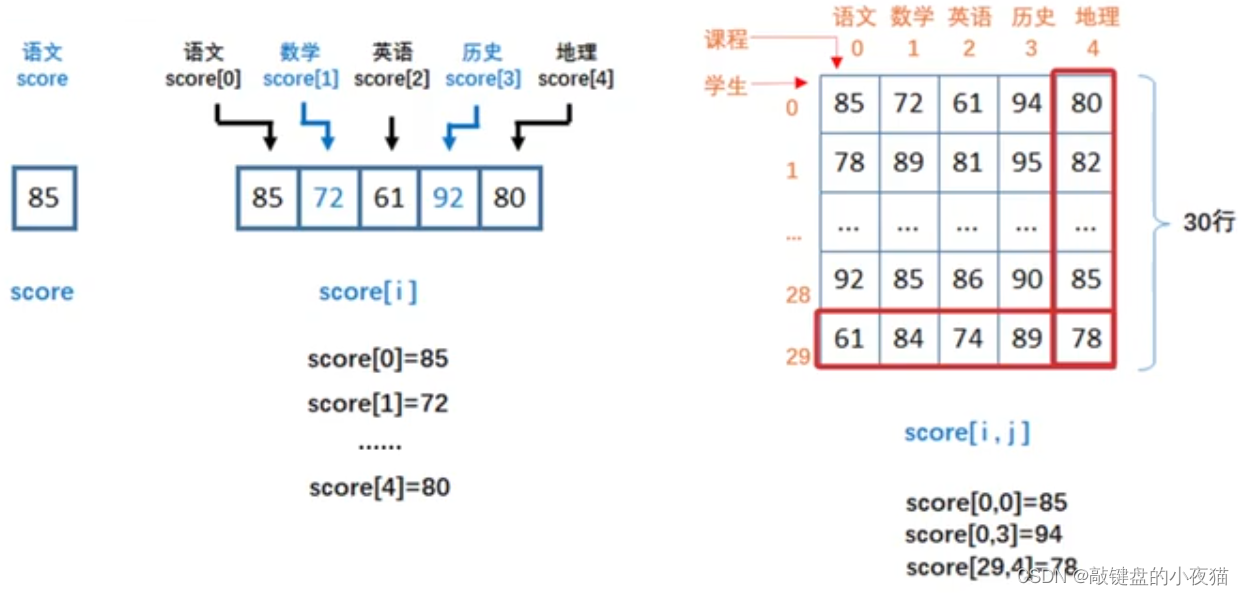
在机器学习中,我们需要把所有的输入数据,比如文本、图像、股票价格或者视频,都转变为多维数组的形式。例如,我们需要表示学生的语文考试成绩,这是一个数字,可以用一个变量score来表示。如果有五门课程的成绩,就需要构造一个一维数组,用下标 i 指明不同的课程,例如score[0]是语文成级85,score[1]是数学成绩72,一直到score[4]是地理成绩80,每门课的成绩都可以用score[i]的形式来表示,I的取值为0到4。
现在,如果全班有30位同学,要把所有学生的成绩都存储起来,那么就需要一个二维数组,二维数组是一个矩阵。其中每行对应一名学生,每列对应一门课程矩阵中的每一个元素,用score[i][j]的形式来表示,其中i是行的下标,表示不同的学生取值为0到29。j是列的下标,对应不同的课程,取值为0到4,例如,score[0][0]表示第0行第0列的元素,也就是第1位学生的语文成绩85,score[0][3]是0行3列的元素,是第1位学生的历史成绩94,score[29][4]是29行4列的元素,也就是最后一位学生的地理成绩78。
一维数组写成这种形式:[85,72,61,92,80]
二维数组则可以写成这种形式:[[85,72,61,92,80],[78,89,81,95,82],.…,[61,84,74,89,78]]
也可以更形象的写为这种形式
[[85,72,61,92,80],
[78,89,81,95,82],
.…,
[61,84,74,89,78]]

数组的形状用来描述数组的维度以及各个维度内部的元素个数,例如对于这个二维数组,它的形状是(30,5),形状是一个元组,用小括号括起来,这是一个二维数组,所以这里有两个数字,其中第一个数字30,表示在第一个维度中有30个元素,第二个数字5表示第二个维度中有5个元素。形状35表示这是一个30 * 5的二维矩阵,这里的30和5被称为长度,也就是各维度内部的元素个数。

对于这个一维数组,它的维度是1。因此,形状中应该只有1个数字,在这个数组中有5个元素,也就是长度是5,因此它的形状是5,这个逗号表示它是一个元组。
小结一下,数组的形状用一个元组来表示,他描述了数组的维数和长度,是几维数组就有几个数字,每个数字对应一个维度,这个维度中有几个元素,这个数组就是几,表示了这个维度的长度。
高维数组

下面我们再来看一下更高维数组的情况。如果有10个班级,每个班级的成绩是一个二维数组,为了存储所有班级的学生的成绩,我们将这些二维数组堆叠形成一个三维数组,可以通过下标 i,j,k来访问其中的任何元素。其中下标 i 代表班级,下标 j 代表学生,下标 k 代表课程,例如score[0][0][4]表示第1个班的第1位学生的最后1门课程成绩80,这个三维数组的形状是[10,35,5],因为它是一个三维数组,所以这个元组中有3个元素,其中第一维的长度是 10,第二维的长度是 30,第三维的长度是 5。我们可以把这个三维数组看成是这样1个数字立方体,其中存储了1个年级中所有学生的成绩。
如果学校中一共有5个年级的学生,那么我们可以把5个这样的立方体堆叠起来构成一个数据柱,这个数据柱是一个4维数组,它的形状中有4个元素,分别是5、10、30、5。
现在,如果有4所不同的学校要存储所有这些学校中的学生成绩,可以使用4组这样的数据柱构成这样的数据墙,这个数据墙又增加了一个维度,是一个5维数组。因此,它的形状中有5个元素,增加的这个维度的长度是4。
当然,如果还有不同地区、不同城市的学校,还可以继续堆叠为更高维的数组,大家可以发挥想象力。
操作和创建数组
在上个章节中,我们知道在机器学习和神经网络中,会涉及到大量的多维数组的运算,数组的形状用一个元素来表示,它描述了数组的维度和长度。

如图,第一个数组,它是一个一维数组,其中有4个元素,形状是(4,)。第二个数组是一个二维数组,其中第一维的长度为3,第二维的长度为4,因此形状是(3,4)。第三个数组是一个三维数组,其中第一维中有2个元素,每一个元素又是一个3 * 4的二维数组,因此形状是(2,3,4)。
那么如何在Python程序中创建这些数组,又如何使用它们呢?这就是我们本章节将要介绍的内容。
Numpy介绍
Python中的数组运算主要依赖于第三方库Numpy,Numpy是一个专门用来处理多维数组的科学计算库。它的名称来源于Numeric Python,它提供了多维数组矩阵的常用操作和一些高效的科学计算函数。Numpy的底层运算是通过C语言是实现的,因此它的存储效率、输入输出性能、运算速度都非常的优越,远远优于Python中的列表、元组等数据结构,而且它性能的提升是与数组的规模成比例的,数组规模越大,性能提升越明显。
在Numpy中包含两种数据类型,数组和矩阵,在标准的Python中需要使用循环语句处理这两种数据类型。而在Numpy中,则可以直接完成运算,而省去了复杂的循环,因此对于同样的数值计算任务,使用Numpy也比直接编写Python代码要简洁的多。
#安装Numpy库
pip install numpy
#导入NumPy库
import numpy as np
from numpy import *其实,Numpy在Anaconda中已经安装好了,可以直接导入。如果你所使用的Python发行版中没有安装它们,那么可以执行Python的pip命令来安装,安装之后就可以使用import去导入。
为了方便使用,一般会给它起一个别名np,采用这种方式导入时,以后调用Numpy中的函数时,一定要加上前缀。也可以使用from语句导入,采用这种方式导入Numpy库在使用时可以不加前缀,但是为了避免Numpy和Python中同名函数的混淆,不建议这么做。
在本章节中,所有的代码段要独立运行,那么都首先要使用import语句导入Numpy库。
创建数组
array([列表]/(元组))Numpy中使用array函数创建数组,参数是Python列表或者元组,因此,这里要用"[]"或者"()"括起来。要注意,这里有两层括号,外层的小括号表示函数参数。内层的中括号或小括号表示参数是列表或者元组,如果漏掉一层括号就会出错。

这是创建一维数组的例子,直接输出数组名,可以看到数组的定义,使用print函数可以输出数组中的元素,使用type函数可以得到a的类型。可以看到,在Numpy中,数组是一个ndarray对象,可以使用索引访问Numpy数组中的元素,也可以使用print函数输出指定的元素,另外和列表类似,也可以使用切片来访问数组中的一部分。
数组的属性
数组对象常用的属性有数组的维数、形状、数组元素的总个数、数据类型和数组中每各元素的字节大小等。
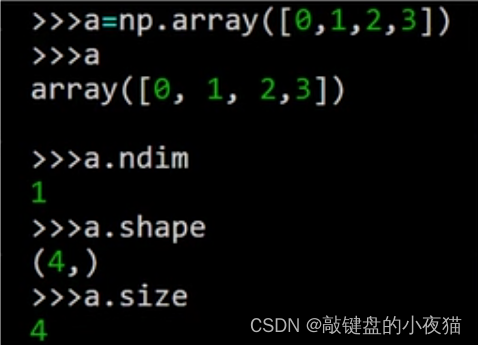
我们刚才建立的这个数组a,维度是1,形状是4,这里的逗号表示这是一个元组。size是数组中的元素的个数,也就是长度。

二维数组
下面我们来创建一个二维数组,这里的参数是一个Python的二维列表,可以你看到创建了一个二维数组。

它的维度是2,形状是(3,4),这个数组中的元素总个数是12。
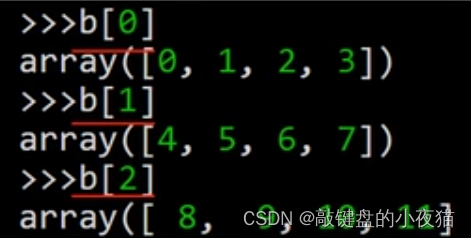
在这个二维数组中,第1维有三个元素,其中每个元素又是1个1维数组,用b[0]、b[1]和b[2]来表示,在这里输出b[0]、b[1]和b[2],可以得到这三个一维数组。
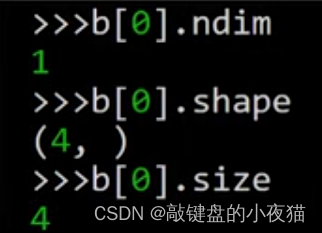
输出b[0]的维数形状和元素个数,可以看到它的维数是1,形状是4,一共有4个元素。

b[0]表示这个一维数组。那么b[0][0]就表示在b[0]这个一维数组中的第1个元素就是这个0。


同样b[0][1]表示这个1,这种形式和直接使用双下标b[0,0]和b[0,1]效果是一样的,都可以访问二维数组中的元素,分别使用这两种形式访问数组中的元素,可以看到能够得到相同的结果。
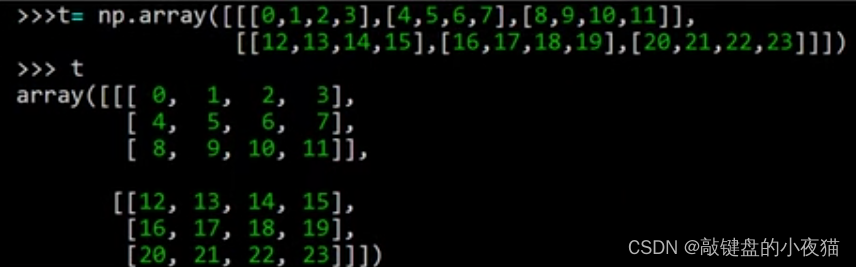
三维数组
下面我们来创建一个三维数组t,可以看到,这个三维数组中,第一维有两个元素,上边是第1个元素,下面是第2个元素,它们都分别是一个3 * 4的二维数组可以用t[0]、t[1]分别访问这两个元素。
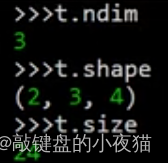
输出这个三维数组的属性,可以看到维数是3,形状是(2,3,4),其中,共有24个元素。

输出t[0]的属性,可以看到它的维度是2,形状是(3,4),其中一共有12个元素。我们已经知道,t[0]表示这个二维数组,t[0][0]就是这个二维数组中的第一个元素,也就是这个一维数组。

输出t[0][0],可以看到结果就是这个一维数组,下面分别是t[0][0]的维数形状和元素个数。同样,t[0][0][0]就表示在t[0][0]这个数组中的第一个元素,它的效果和直接使用三个索引值去访问三维数组中的元素是一样的。
数组元素的数据类型
Numpy要求数组中所有元素的数据类型必须是一致的。
int8、uint8、int16、uint16、int32、uint32、int64、uint64
float16、float32、float64、float128
complex64、complex128、complex256
bool、object、string_、unicode_Python支持的数据类型仅有整型、浮点型和复数型,不不足以满足多种科学计算的需求,因此,Numpy增加了许多其他的数据类型,包括不同长度的有符号和无符号的整数类型,不同长度和精度的浮点型,还有复数、布尔型、次符串类型、Python对象类型以及unicode类型。
array([列表]/(元组),dtype=数据类型)
在使用array函数创建数组时,可以使用dtype参数指定数组中元素的类型,例如这里使用dtype参数指定元素的数据类型是64位整型,int64、'int64'、"np.int64"这三种形式都可以,如果创建数组时指定了数据类型,那么在输出的时候也会有dtype项。

对于已经创建的数组,可以使用dttype属性获取其中元素的数据类型属性itemsize表示每个元素所占的字节数,因为是64位整数,所以占8个字节。
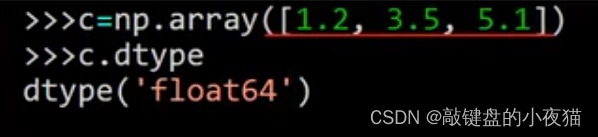
这个数组中的数据类型是浮点数,输出它的数据类型可以看到是64位浮点数。在使用Python列表或元组。创建Numpy数组时,所创建的数组类型由原来的元素类型推导而来。
创建特殊的数组
| 函数 | 功能描述 |
| np.arange() | 创建数字序列数组 |
| np.ones() | 创建全1数组 |
| np.zeros() | 创建全0数组 |
| np.eye() | 创建单位矩阵 |
| np.inspace() | 创建等差数列 |
| np.logspace() | 创建等比数列 |
在编程时,我们经常需要创建一些特殊的数组,例如全0数组、全1数组、等差等比数组等,Numpy中提供了相应的函数,可以方便的创建这些数组。
np.arange()
np.arange(起始数字,结束数字,步长,dtype=数据类型)np.arange()函数用来创建一个由数字序列构成的数组,和python中的arange()函数相似,它从起始数字开始生成一个连续增加的数字序列,到结束数字终止,也是前闭后开的。
数字序列中不包括结束数字。起始数字省略时,默认从0开始,步长省略时默认为1,dtype指定了元素的数据类型。

例如起始数字省略结束数字为4。那么所创建的数组就是0,1,2,3。

使用arange函数也可以创建一个小数数组,这里有三个参数,分别是初始值0、结束值2,步长0.3。可以看到,这是所创建的小数数组,在结束值2之前终止。
np.ones()
np.ones(shape,dtype=数据类型)np.ones()函数,用来创建一个元素全为1的数组。参数式数组的形状和数据类型,数据类型可以省略。

例如这里创建了一个3 * 2的二维数组,数据类型为16位整型,所有元素都为1。
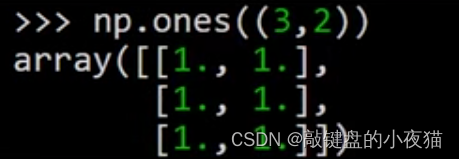
要注意的是,当数据类型省略时,这里仍然有两层括号,外面这层括号是ones函数参数的括号,里面这层是表示形状的元组的括号。
np.zeros()
np.zeros(shape,dtype=数据类型)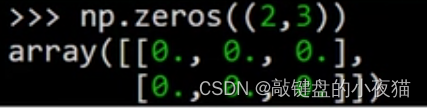
zero()函数,用来创建一个元素全部为0的数组。参数的用法和one参数相同,这里创建了一个2 * 3的全0数组。
np.eye()
np.eye(shape)另外,Numpy中提供了一个eye函数,通过它可以快速的创建单位矩阵
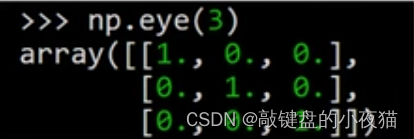
这是创建一个3 * 3的单位矩阵
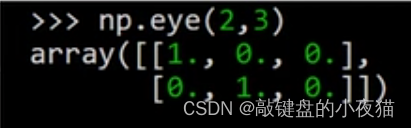
这是创建一个2 * 3的矩阵。前两行两列的对角线元素为1,其他元素都是0
np.linspace()
np.linspace(start,stop,num=50)inspace函数来创建一个等差数列,参数分为起始数字、结束数字和元素个数。

例如这里起始数字为1,结束数字为10,一共有10个元素,因此创建了一个从1到10的等差数列。要注意的是,这里不是前闭后开的。数列中包括终止数字10。
np.logspace()
np.logspace(start,stop,num=50,base=10)
logspace函数用来创建等比数列参数分别为起始指数、结束指数、元素个数和积。例如,这表示创建一个等比数列积为2,起始元素为2的1次方,结束元素为2的5次方,一共产生5个数。因此,所产生的等比数列就是2的一次方,2的2次方,一直到2的5次方,也就是2、4、8、16、32。
asarray()
另外,在Python中还可以使用asarray()函数创建数组,它和array函数类似,也可以将列表或元组转化为数组对象。主要区别是,当数据源本身已经是一个数组对象时,array仍然会复制出一个副本占用新的内存,而asarray则不会。

例如,在这个例子中,首先定义一个列表list1,接下来分别通过array和as array函数将它转化为numpy数组,然后修改list1中的元素值,并分别输出list1和list2两个数组。
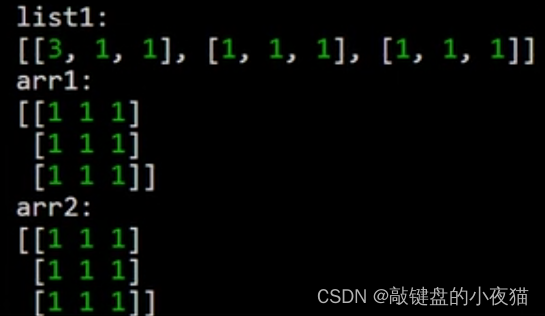
这是运行结果,当数据源是列表时,array和asarray都是对列表进行了复制,因此当修改列表时,不会影响数组中的值。

下面再来看这个例子,这里数组一是一个全1的Numpy数组,分别使用array函数和asarray函数将它转化为数组2和数组3,现在改变数组1中元素的值,看一下数组2和数组3是否发生了改变。

这是运行结果,数组2没有受到影响,而数组3发生了改变。可见,当数据源本身已经是一个ndarray对象时,array仍然会复制出一个副本,而asdarray则没有,它直接引用了本来的数组。
数组运算常用函数
Numpy是一个专门用来处理多维数组的科学计算库,可以使用array/asarray函数将Python中的列表或元组转化为数组,也可以使用专用的函数创建全0数组、全1数组、等差等比数组等特殊的数组。在本章节中,我们介绍如何对Numpy数组进行运算,和Python中的序列数据结构一样,可以使用切片来访问数组中的一部分。
数组元素的切片——一维数组

例如,这里创建了一个一维数组,在切片[0][3]表示取得下标为0,1,2的元素,如果起始数字缺省,那么从0开始,如果结束数字缺省,那么到最后一个元素为止。

数组元素的切片——二维数组
再创建二维数组b,这个二维数组的第一维中有三个元素,每个元素都是一个一维数组,因此如果使用单索引值,那么就指定了一个一维数组。
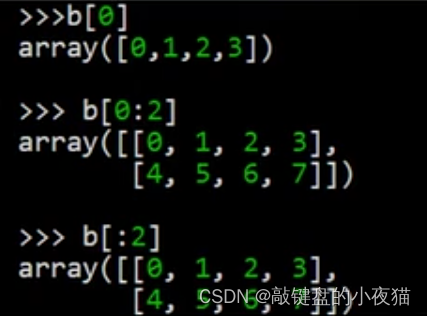
例如索引值为0的元素是第一个一维数组[0,1,2,3],也就是这里的第一行,如果要得到前2个一维数组,也就是前2行,可以使用切片儿起始数字为0,结束数字为2,可以看到结果是前两行,这里起始数字0也可以省略。

还可以使用两个索引值来实现二维的切片,例如,如果想获得这样一个切片,那么使用第一个索引值切出前两行,再使用第二个索引值切出前两列,就可以得到这个二维的切片。同样,如果想得到这样的切片,那么第一个索引值仍然是对0到2的切片,第二个索引值设置为1到3的切片就可以了。
那么如果要得到第一列的元素,应该怎么做呢?这仍然是在二维空间中进行的切片,第一维取到所有的行,在第二维中只取第一个元素,因此应该这样进行切片逗号前面是第一维,起始数字和结束数字都省略,只保留一个冒号,表示取到所有的行。逗号后面是第2位,索引值为0,表示只取第1列。要注意的是,这个切片操作虽然是二维的,但是切片得到的结果是一维的,这是一个长度为3的一维数组,而不是一个三行一列的二维数组。这种情况在我们后面的编程中非常常见,也一定要注意加以区分,

数组元素的切片——三维数组
下面我们来看一下对三维数组的切片。

首先创建一个三维数组,第一维上选择所有元素,也就是这两个元素都选。第二维中也是选择所有的元素,也就是这里的每一行都选,然后第三维中只选择索引值为0的元素,也就是只选择每行的第一个元素,因此结果为[0,4,8]、[12,16,20] 这是一个2 * 3的数组,
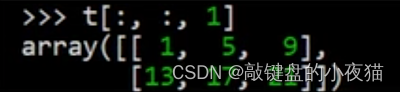
如果这里改为1的话,那么取到所有第二列的元素,结果是[1,5,9]、[13,17,21]。
改变数组形状
| 函数 | 功能描述 |
| np.reshape(shape) | 不改变当前数组,按照shapet创建新的数组 |
| np.resize(shape) | 改变当前数组,按照shapet创建数组 |

对于已经创建好的数组,可以使用reshape函数或者resize函数改变数组的形状,reshape函数不对原始数组进行修改,而是返回一个新的数组。resize函数则直接对原始数组进行修改。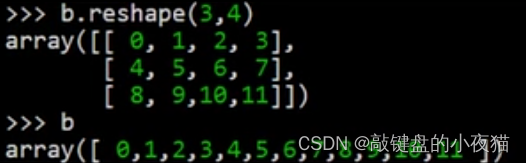
例如,这里首先创建数组b,然后使用reshape函数改变这个数,组的形状结果是一个3 * 4的二维数组,但是可以看到数组b本身并没有发生变化。

下面使用reset函数可以看到,看到数组b本身的形状已经被改变了。


要注意的是,当改变形状时,应该考虑到数组中元素的个数,确保改变前后元素总个数相等,例如,如果这里形状的值设置为2,5,就会出现元素个数不匹配的错误提示。
创建数组并且改变数组的形状

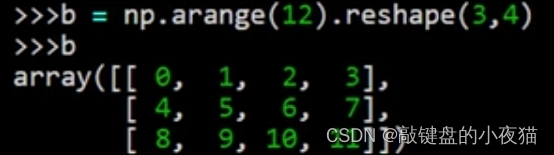
这两条语句也可以合并表示创建数组并改变数组的形状,通过这种方法可以快速的创建指定形状的数字序列矩阵。

这是一个创建三维数组的例子,首先创建一维数组,然后改变它的形状,这是运行的结果。
在reshape函数中的形状参数中,也可以把其中的某一个维度设置为-1,这时Numpy会根据数组中的元素总个数以及其他维度的取值来自动的计算出这个维度的取值。
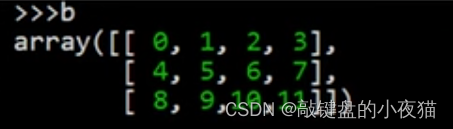
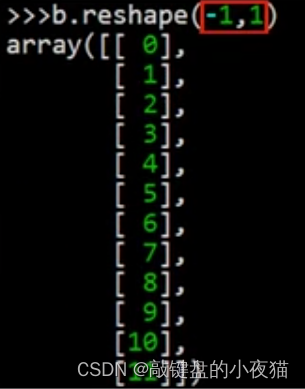
例如,要把这个二维数组b改为n行1列的,这个行数n是多少我们不知道,或者懒得去计算。那么就可以把行数设置为-1,列数设置为1,这个-1就表示不知道有多少行由系统自动计算,这是运行的结果。
可以看到得到了一个12行1列的结果,要注意的是,这不是一维数组,而是一个12 * 1的二维数组。

可以使用reshape函数把它改变为一维数组,这里形状参数只有一个元素,说明是一维数组,-1表示长度不知道,由Numpy自动计算,可以看到运行结果是一个一维数组。

数组间的运算
Numpy支持数组之间的四则运算、幂运算等。
数组加法运算,将数组内对应的元素相加,例如这里定义数组a和数组d,相加的结果是a和d中对应的元素相加。
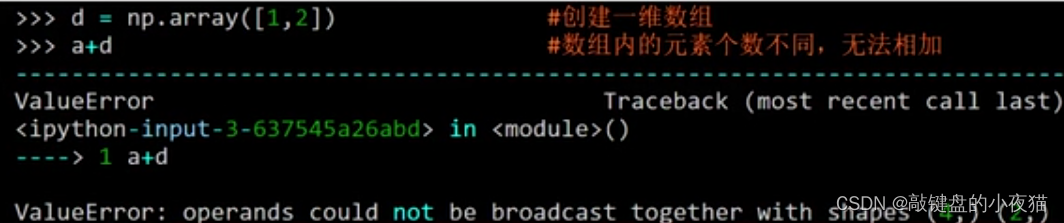
要注意的是,相加的两个数组的形状和长度应该一致,否则就会出现错误的提示。
例如,如果数组d中只有两个元素与a相加,则会出现形状不匹配的错误信息,但是一维数组可以和多维数组相加,相加时会将一维数组扩展至多维数组。
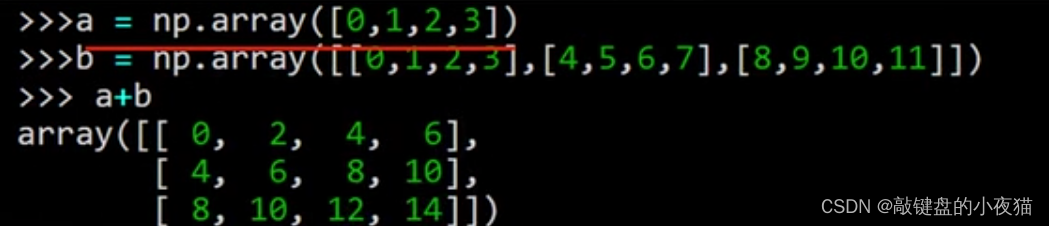
例如,数组a是一维数组,数组b是二维数组,它们相加时,一维数组a中的各个元素首先与b中的第一行中的对应元素相加,得到0,2,4,6。然后再与b中的第二行对应元素相加,得到4,6,8,10 下面再与最后一行相加得到8,10,12,14。数组之间的减法、乘法、除法运算和加法运算规则相同,我们在这里就不再举例子了,大家可以自己试一下。
另外,当2个数组中的元素的数据类型不同时,在运算时,精度低的数据类型型会自动的转换为精度更高的数据类型,然后再进行运算。
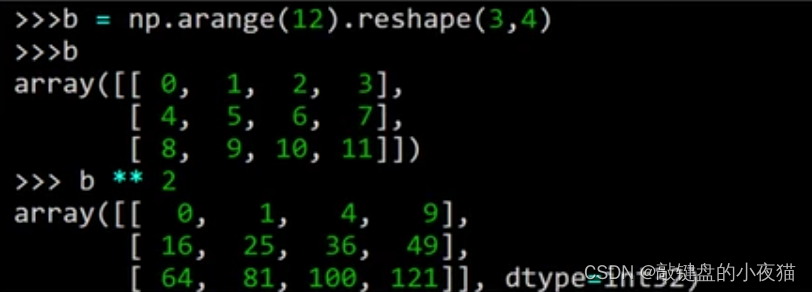
幂运算是对数组中每个元素求n次方,例如这是对数组B求2次方,这是得到的结果。
矩阵运算——矩阵乘法
二维数组就是一个矩阵,是一种非常常用的数据组织形式,下面我们来介绍Numpy中几种常用的矩阵运算。

在Numpy中,二维数组之间使用乘号运算符是将两个二维数组中对应的元素分别相乘,例如,对于这样两个二维数组,a和b对应元素相乘,就是1 * 2、1 * 0、0 * 3和1 * 4,因此结果是2,0,0,4。

这是代码实现。首先创建两个数组,然后对应元素相乘,这是运行结果。
矩阵运算——矩阵相乘
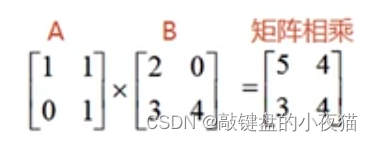
如果要得到这种矩阵乘积的结果,那么可以使用Numpy中的matmul函数或者dot函数来实现。


可以看到,这两种方法都可以得到矩阵相乘的结果。
矩阵运算——转置和求逆
另外,在后面的编程中,我们还可能用到矩阵的转置和求逆运算。
矩阵转置使用transpose函数,矩阵求逆使用linalg中的inv函数。


例如,这是对矩阵a,b分别求转置,这是运行结果,再对它们分别求逆,这是运行结果。
数组间的运算概念
Numpy对数组的常用操作,包括对数组的切片、改变数组的形状以及数组之间的常用运算,在这本章节中,我们来介绍数组元素之间的运算。
| 函数 | 功能描述 |
| numpy.sum() | 计算所有元素的和 |
| numpy.prod() | 计算所有元素的乘积 |
| numpy.diff() | 计算数组的相邻元素之间 |
| np.sqrt() | 计算各元素的平方根 |
| np.exp() | 计算各元素的指数值 |
| np.abs() | 取各元素的绝对值 |
Numpy中提供了一些对数组中的元素之间进行数学运算的函数,常用的有求和、乘积、平方根、指数,取绝对值函数等。
sum():数据求和
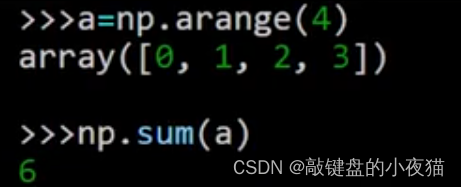
求和函数sum对数组中的所有元素得值求和,例如首先使用arange函数创建一维数组a,然后使用sum函数对数组a中所有的元素求和,这是运行的结果。

下面再创建一个二维数组b,使用sum函数,这是运行的结果,可以看到也是对数组中的所有元素求和。
那么,如果我们希望按行求和或者按列求和,应该怎么做呢?这就要用到sum函数中的第二个参数轴,在Numpy中,数组中的每一个维度被称之为一个轴,轴的个数,被称之为秩。

例如这个一维数组a有一个轴,秩为1。这个二维数组b有两个轴,分别对应于两个维度,秩为2,要注意,这里的秩和线性代数中的秩的概念是不一样的。在Numpy中,每个轴都有一个索引值,就是这个轴的序号,一维数组只有一个轴,这个轴的序号是0,二维数组有两个轴,序号分别是0和1,可以形象的理解为二维数组的两个坐标轴,对于三维数组就有三个轴序号分别是0,1,2。
一维数组(rank=1)

现在我们就可以利用轴对数组元素从不同方向上进行运算,先来看一维数组,它的形状是4,轴等于0,对,它使用sum函数,就是把这个轴上的所有4个元素相加,相加后的结果中这个轴就消失了,收缩成了一个点。从一维数组变成了1个数字。
二维数组(rank=2)

那么对于这个二维数组,第一个维度上轴等于0,第二个维度上轴等于1。当执行轴等于0时,应该是将这个轴上的所有3个元素相加,相加后这个轴就消失了,得到的4个数字,就是得到的结果是1个一维数组。
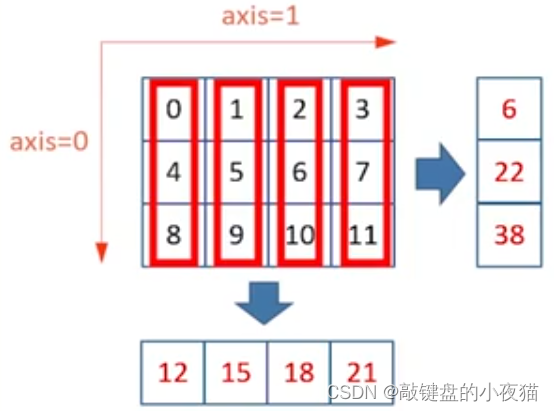

当轴等于1时,是将这个轴上的4个元素相加,也就是各个行上的数字分别相加,相加后,这个轴就消失了,结果是由三个行上的和构成的一维数组。

三维数组(rank=3)
下面看一下三维数组的例子,这里创建了一个三维数组t,它的形状是(2,3,4),因此它有3个轴,轴的取值分别是0,1,2。
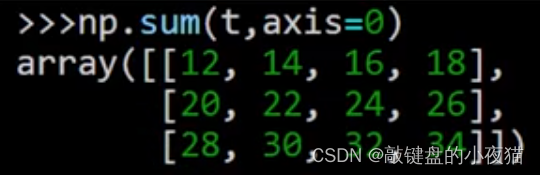
当轴等于0时,对第1个维度中的元素求和,第一个维度上有两个元素都是二维数组,因此,就是将这两个二维数组上的对应元素相加,结果是一个新的二维数组,可以看到结果中消除了这个维度,得到一个新的二维数组,是一个3 * 4的矩阵。
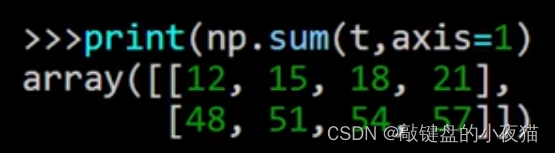

当轴等于1时,是将这个轴上的3个分量相加,结果中消除了这个分量,得到一个2 * 4的二维数组,因此这种情况类似于二维数组中轴等于0的情况。分别将各列中的三个分量相加,得到两个一维数组,12、15、18、21和48、51、54、57。

同样,当轴等于2时,是对这个轴上的4个分量相加,结果应该是一个2 * 3的二维数组,因此类似于二维数组。中轴等于1的情况,也就是将各行元素相加得到2个一维数组,6、22、38和54、70、86。同样也可以推广到更高维的情况。
其他函数与sum类似
prod的函数,用来计算所有元素的乘积,和sum函数一样,对于多维数组也可以对指定的轴计算乘积。除此之外,还可以使用diff函数计算数组中相邻元素之间的差。使用sqrt函数计算数组中各个元素的平方根,使用exp函数计算各个元素的指数。使用abs函数取各个元素的绝对值。
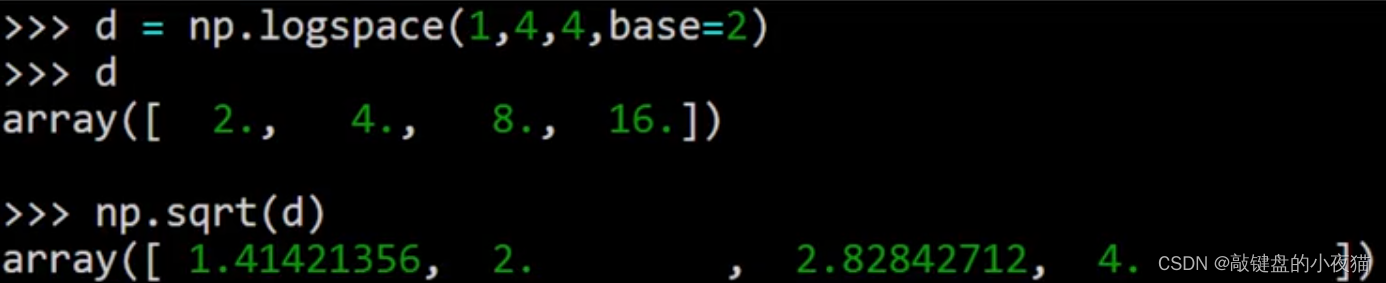
例如,这里首先使用logspace函数创建一个等比数列,这4个参数分别是起始指数、结束指数、元素个数和基数,这里的基数为2,因此所创建数组中的元素分别为2的1次方、2的2次方、2的3次方和2的4次方。然后使用square的函数对数组中的各个元素求平方根,这是运算的结果。
数组的堆叠运算
有时候我们希望把几个低维的数组组合在一起,形成成一个更高维的数组,这就是数组的堆叠,Numpy库中使用函数stack来完成数组的堆叠。
np.stack((数组1,数组2,…),axis)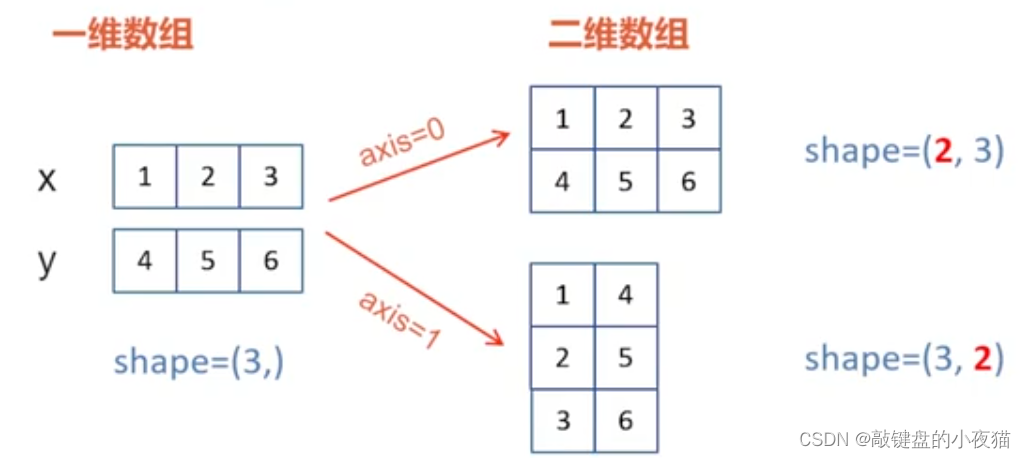
这是stack函数的语法,参数的第一部分是带堆叠的数组,参数的第二部分是指定堆叠时使用的轴,这里的轴的概念和前面是一致的。
一维数组堆叠
例如,对于两个一维数组,x和y,要把它们堆叠为二维数组,就有两种方式,在轴0上堆叠,或者在轴1上堆叠。如果在轴0上堆叠,那么堆叠后新出现的轴是第一个轴。这两个数组本身的形状都是(3,),堆叠后形成的二维数组形状就是(2,3),因此应该是以这种方式进行堆叠。如果是在轴1上堆叠,那么堆叠后新出现的轴就是第二个轴,堆叠后的二维数组的形状应该是(3,2)。因此,应该以这种方式进行堆叠。

下面我们来用程序验证一下,创建两个一维数组,首先在轴等于0时进行堆叠,这是运行结果,然后在轴等于1时堆叠,这是运行结果,可以看到和我们的分析是一样的。

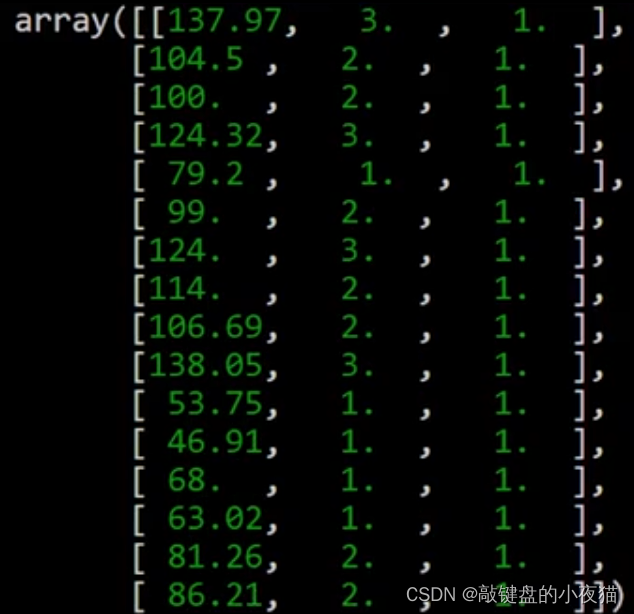
也可以同时堆叠多个数组,例如,这里有三个数组,第一个数组area是浮点数数组。第二个数组room是整数数组。第三个数组是全1数组,每个数组中都有16个元素对这三个数组在轴1上堆叠,将得到一个16 * 3的二维数组,这是运行的结果。
二维数组堆叠
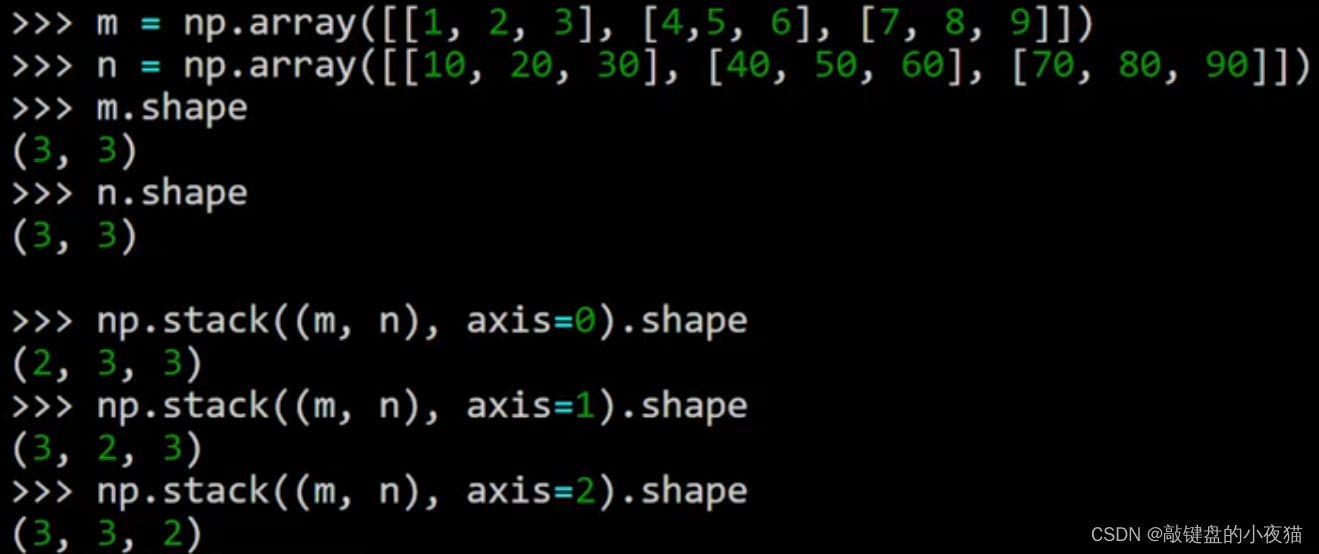
我们再来看一个对二维数组进行堆叠的例子,首先创建两个二维数组,m和n,它们的形状都是(3,3),将它们堆叠为三维数组,如果在轴0上堆叠,那么堆叠后的形状是(2,3,3)。如果在轴1上堆叠,那么堆叠后的形状是(3,2,3),如果在轴2上堆叠,那么堆叠后的形状是(3,3,2)。
那么堆叠后的结果数组是什么呢?请大家试着分析一下,然后再通过代码验证,看看你的分析是否正确。
矩阵和随机数
通过上个章节的学习,我们学习了使用Numpy创建和使用数组的方法,总结为以下内容:在Numpy中每个数组都是一个ndarray对象,数组中的元素要求有同样的数据类型,下标从0开始,数组对象常用的属性有维数、形状、数据类型等,一个形状为(m,n)的二维数组,可以看成是m行n列的矩阵。
matrix(字符串/列表/元组/数组)
mat(字符串/列表/元组/数组)其实除了数组之外,在Numpy中也专门提供了矩阵对象,Numpy模块中的矩阵对象是Numpy.matrix,使用matrix()函数创建,这个函数也可以简写为mat(),其中的参数可以是字符串python列表元组或者Numpy数组。

例如这是参数为字符串的例子,各个元素之间用空格隔开,各行之间用分号隔开,因此这就表示第一行的元素是1,2,3,第二行的元素是4,5,6,现在输出a得到这样的结果,matrix表示这是一个矩阵。
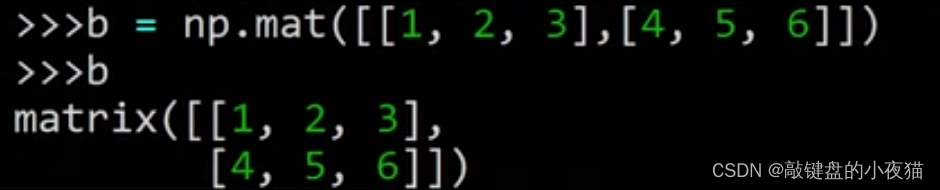
在这个例子中,参数是python二维列表,可以看到得到了同样的结果。
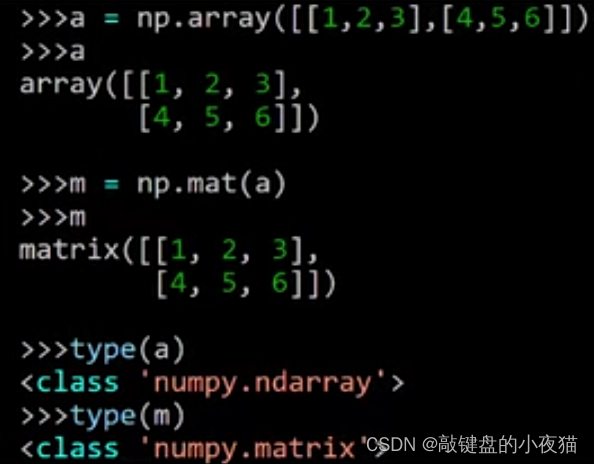
也可以借助Numpy的二维数组来创建矩阵,首先使用array函数来创建一个二维数组,然后把它作为mat()函数的参数来创建矩阵,可以看到a是一个数组,而m是一个矩阵。
也可以使用type()函数来查看它们的类型,a对象是Numpy的数组类型,m对象是Numpy的矩阵类型。
| 属性 | 说明 |
| .ndim | 矩阵的维数 |
| .shape | 矩阵的形状 |
| .size | 矩阵的元素个数 |
| .dtype | 元素的数据类型 |
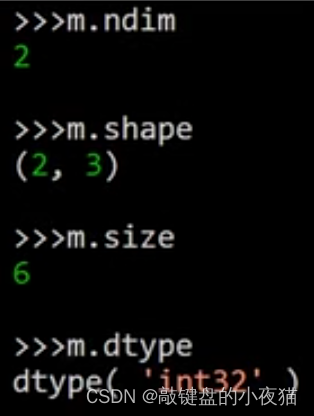
和Numpy数组一样,也可以通过matrix对象的属性来获得矩阵的维数、形状、元素个数和数据类型。例如这个m矩阵,维数是2,形状是(2,3)矩阵中一共有6个元素,是32位整形。
矩阵运算-矩阵相乘
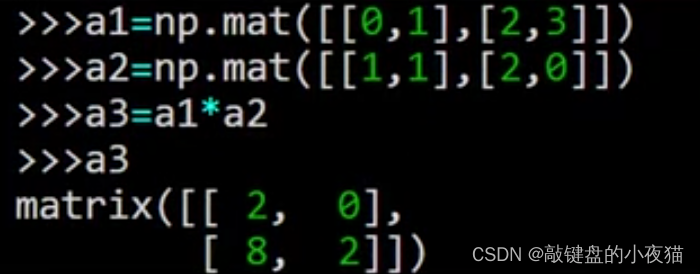
下面我们来看一下基本的矩阵运算,两个矩阵相乘可以直接用乘法的符号完成,例如,这里首先创建了两个二维矩阵,然后将它们相乘,这是运算的结果。
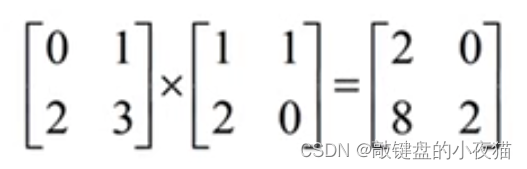
可以手工计算一下,结果是一样的。
矩阵运算--转置、求逆
矩阵转置:.T
矩阵求逆:.I矩阵的转制、求逆运算分别用T运算和I运算来完成,要注意,这里的T和I都是大写的。
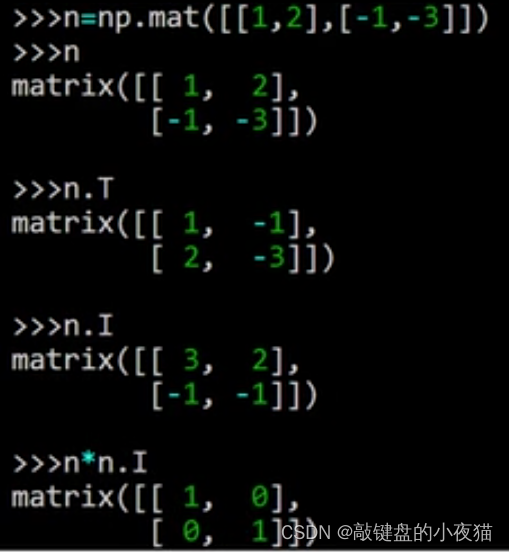
例如首先创建矩阵n,这是一个2 * 2的方阵,下面求它的转制,第二行是它的转制的结果,然后对矩阵求逆,第三行是结果,我们来验证一下这个求逆的结果是否正确,我们知道一个矩阵乘以它的逆等于单位阵,因此,我们只要把这个结果和矩阵m本身相乘,看一下是否是单位阵就可以了,第四行为结果,可以看到结果是一个单位阵。对于不是方阵的矩阵,也可以对它求转置和求逆。
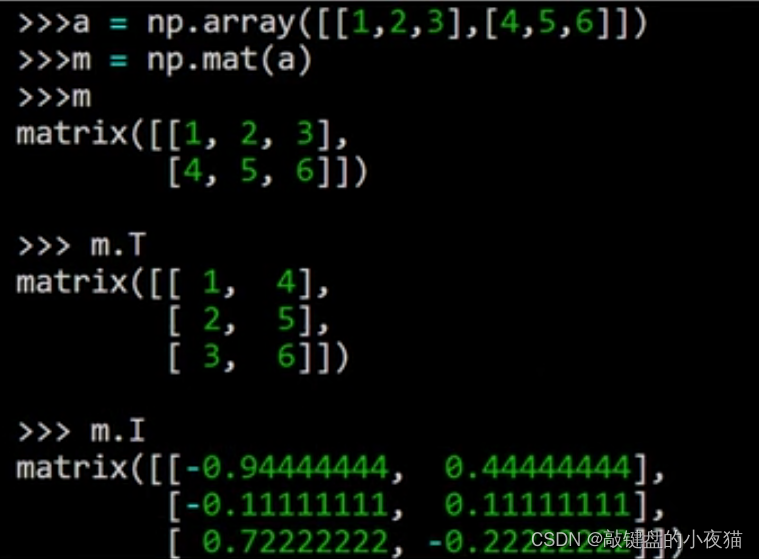
比如2 * 3的矩阵m,求它的转置结果是一个3 * 2的矩阵,再对m求逆,这是得到的结果。Numpy中的矩阵和二维数组是相似的,在很多时候是通用的,矩阵的优势就是运算符号相对简单,例如两个矩阵相乘可以直接采用乘号表示,而数组的优势在于不仅可以表示二维,还可以表示更高维的数组,另外数组更加的灵活,速度更快。因此,两者在通用的情况下,建议尽量选择数组。
随机数
随机数就是计算机随机产生的数字序列。在机器学习神经网络的程序中,经常会用到随机数,例如神经网络中权值的初始化训练集和测试集的随机划分、训练集的随机清洗等等。
| 函数 | 功能描述 | 返回值 |
| np.random.rand(do,d1,...,dn) | 元素在[0,1)区间均匀分布的数组 | 浮点数 |
| np.random.uniform(low,hige,size) | 元素在[low,hige)区间均匀分布的数组 | 浮点数 |
| numpy.random.randint(low,hige,size) | 元素在[low,hige)区间均匀分布的数组 | 整数 |
| np.random.randn(do,d1,...,dn) | 产生标准正态分布的数组 | 浮点数 |
| np.random.normal(loc,scale,size) | 产生正态分布的数组 | 浮点数 |
在Numpy的random模块中提供了很多产生随机数的函数,这些函数的返回值都是Numpy数组。
rand函数产生均匀分布的数组,其中参数d0到dn是数组的形状,所返回的数组中的元素是[0,1)区间中的浮点数,注意这里是前闭后开的。如果参数是空的,那么就会返回一个数字。
uniform()函数产生均匀分布的数组,参数low和high分别是起始值和结束值,size是数组的形状,返回值也是浮点数。
roundn()函数产生标准正态分布的数组,标准正态分布就是标准差是1,均值是0的正态分布。
normal()函数产生正态分布的数组,参数loc是均值,scale是标准差。
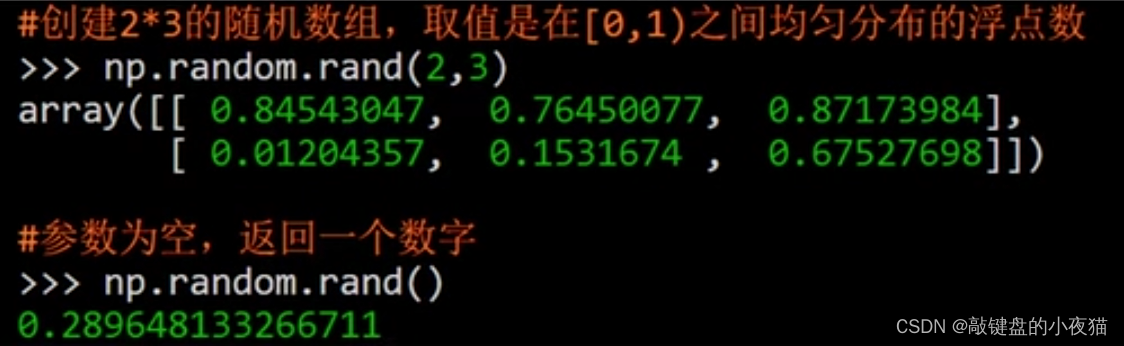
例如,这个例子生成一个2 * 3的随机数组,可以看到结果是一个Numpy数组,取值是分布在[0,1)区间中的浮点数。如果参数为空,就会返回一个数字。
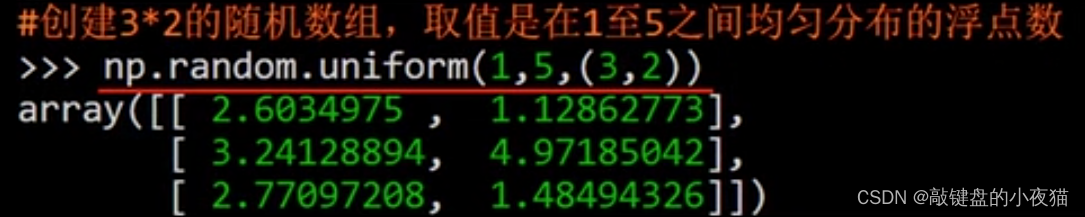
这个例子创建了一个3 * 2的随机数组,数组元素是在1到5之间均匀分布的浮点数,这是运行结果。
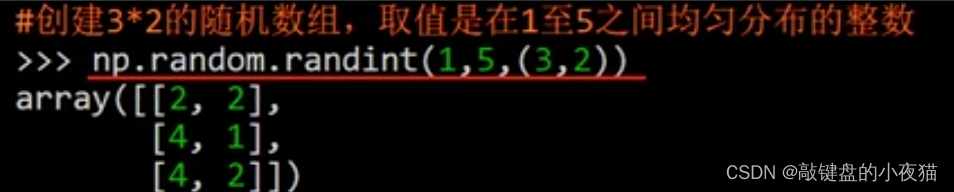
这是创建了一个3 * 2的随机数组,数组元素是在1到5之间均匀分布的整数,这是运行结果。

这是创建了一个2 * 3的随机数组,符合标准正态分布。
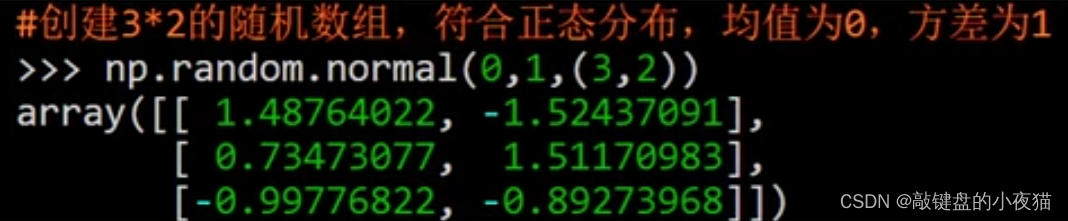
这里创建了一个3 * 2的随机数组,符合正态分布,均值为0。标准差是1,也就是一个标准正态分布。

因为是随机数,因此大家在做这个练习的时候,所得到的结果和我这里一定是不同的,我使用两次同样的语句产生两次随机数,得到的结果也是不同的。但是,这些其实并不是严格意义上的随机数,而是伪随机数,它们是由随机种子根据一定的算法生成的,只要算法一样,随机种子一样,那么所产生的随机数就是一样的。在默认情况下,随机种子来源于系统时钟,用户也可以自己设置随机种子。

在Numpy的random模块中使用seed的函数设置随机种子,例如设置随机种子为612,然后生成随机数,可以看到现在每次产生的随机数都是一样的,要注意的是,采用seed的函数设置的随机种子仅一次有效,例如在最后这次没有设置随机种子,因此产生了不一样的结果。
另外,随机数产生的算法还和系统有关,例如,即使随机种子一样,windows和linux系统产生的随机数也是不一样的。
np.random.shuffle(序列)打乱顺序函数
在机器学习、神经网络的编程中,为了防止过拟合,常常需要把数据打乱,shuffle()函数就提供了这个功能,这个函数也被形象的称作洗牌函数,shuffle函数的参数可以是python列表,Numpy数组等。
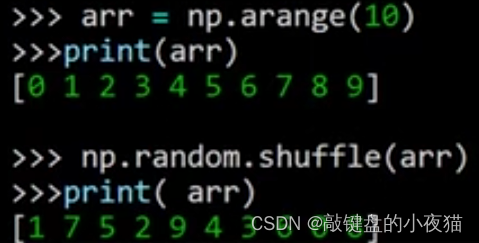
例如,在这段代码中,首先使用orange函数生成一个数字序列,然后使用shuffle函数打乱,每次执行这段代码,都会重新打乱数组元素,得到不同的运行结果。
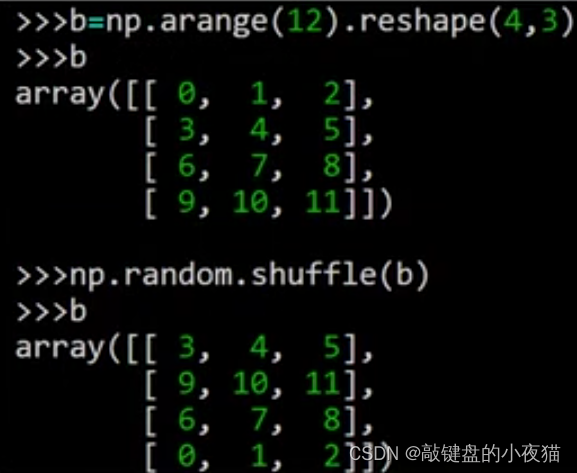
对于多维数组使用shuffle函数值打乱第一维元素。例如,首先生成一个二维数组b,然后使用shuffle函数打乱它,这是打乱的结果,可以看到只是打乱了第一维元素的顺序。也就是说,只是各行的位置发生了变化,而每行内的元素不变,如果这是一个数据样本集,每行是一个样本,那么shuffle函数就实现了对样本集的打乱。
以上就是本章节的全部内容,我们已经知道Numpy提供了多维数组和矩阵的常用操作和一些高效的科学计算函数,它的底层是使用c语言实现的。因此在操作向量和矩阵时性能非常的优越,在后面的文章中,我们会大量的使用到Numpy数组和随机模块,因此这个部分非常的重要。