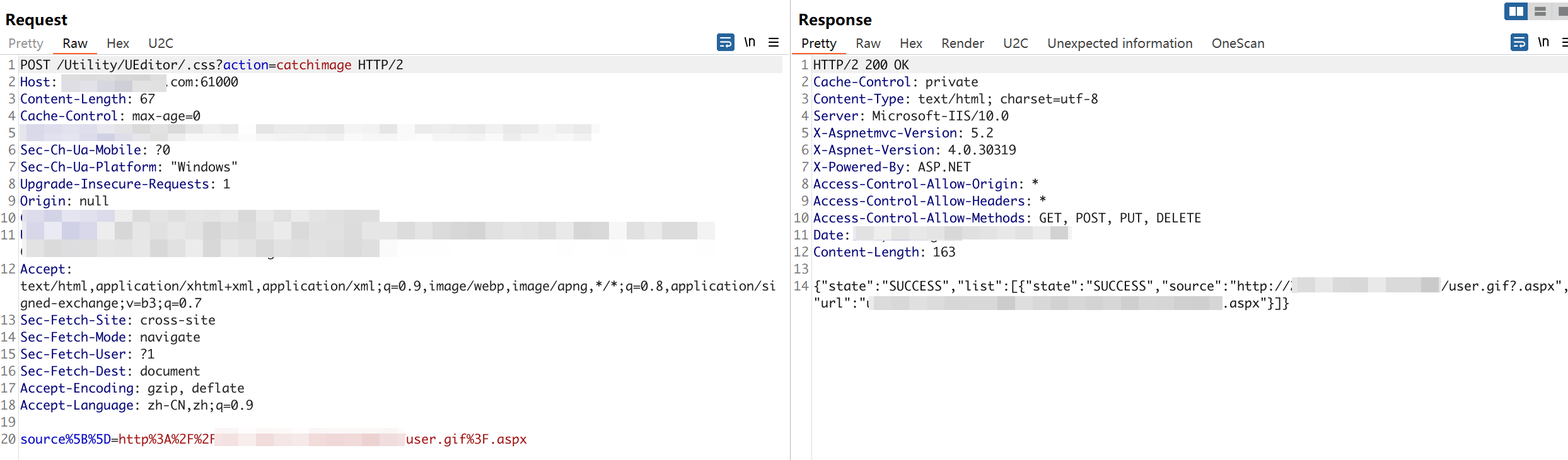
文生图工作流
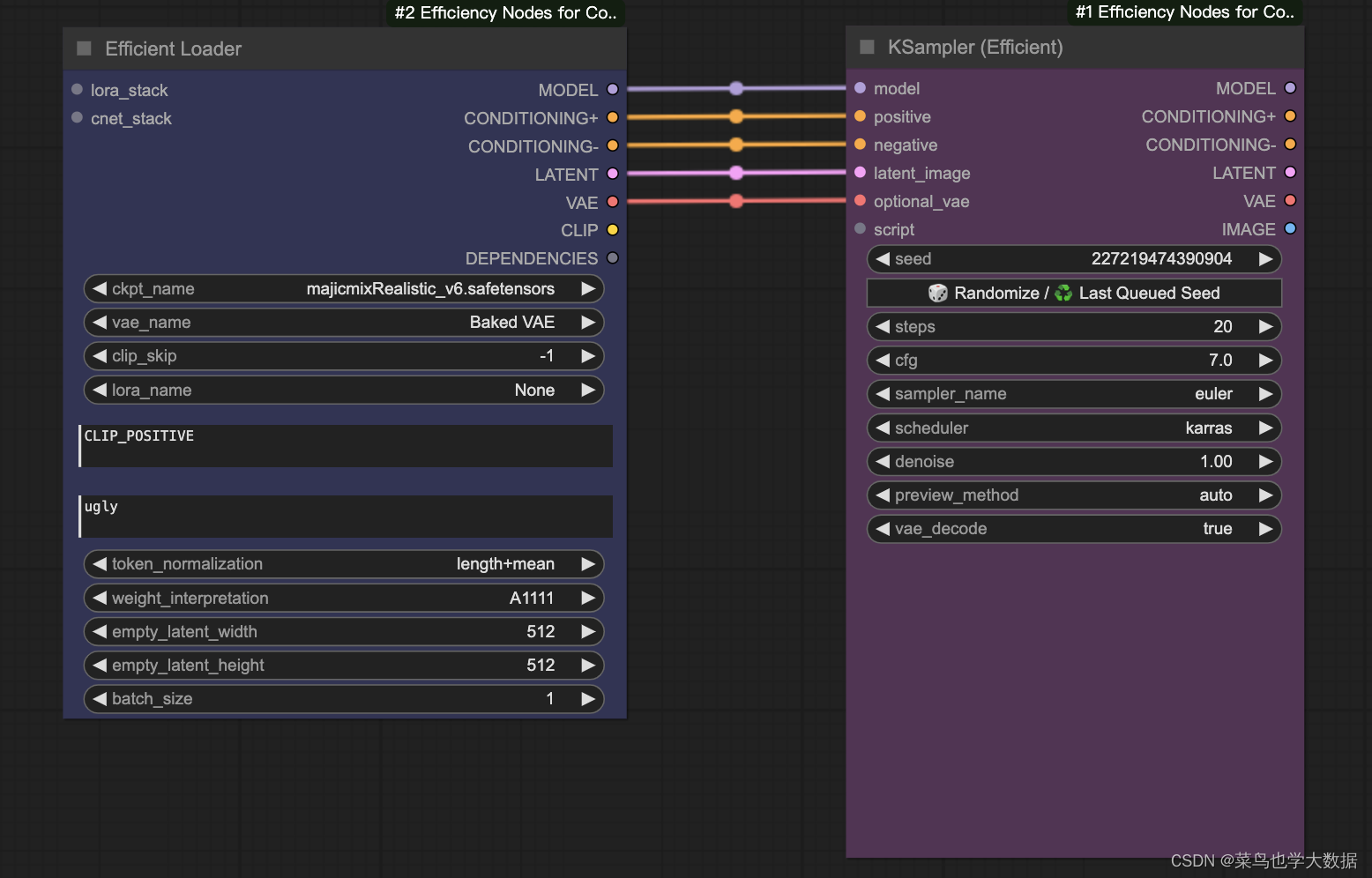
- Efficient Loader节点用于高效加载和缓存模型
ckpt_name:选择要加载的检查点模型的名称。通常选择你的主要模型名称
vae_name:定义要使用的VAE(变分自编码器)模型。一般选择与你的主要模型匹配的VAE,或者使用默认的。
clip_skip:决定跳过CLIP模型的层数。通常设置为1或2,层数越多对生成图像影响越大。
lora_name:指示要应用的LoRA(低秩适应)模型的名称。如果需要特定风格或效果,可以选择相应的LoRA模型。
lora_model_strength:设置LoRA模型对基础模型的影响强度。一般在0.5-1之间,根据需要的风格效果调整。
lora_clip_strength:调整LoRA模型对CLIP模型的影响强度。设置与lora_model_strength类似的值即可。
positive:输入正向提示词的文本框。描述你希望图像包含的特征。
negative:输入反向提示词的文本框。描述你希望图像避免的特征。
token_normalization:定义如何归一化tokens。一般选择“none”或“length”。
weight_interpretation:确定提示词中权重的解释方式。选择“comfy”或“A1111”。
batch_size:指定批处理图像的数量。根据显存大小调整,通常在1-4之间。
lora_stack:允许堆叠多个LoRA模型。启用此选项可以组合多个LoRA效果。
cnet_stack:允许堆叠ControlNet模型。启用此选项可以控制图像生成的多个方面。
- kSampler (Efficient)节点用于优化采样过程
model:选择要使用的模型。通常选择你的主模型,如"Stable Diffusion"。
seed:设置随机种子,确保结果一致。使用相同种子可以重现图像。
steps:定义采样步骤数。步骤越多,图像细节越丰富,建议设置在50-100之间。
cfg:配置缩放因子,控制模型对提示词的遵从度。常用范围在7-15之间,数值越高图像越符合提示词。
sampler_name:选择采样算法。常用的选项是“euler_ancestral”或“ddim”。
scheduler:定义调度器,控制采样过程。一般选择“normal”或“karras”。
positive:输入正向提示词。描述你希望图像包含的元素。
negative:输入负向提示词。描述你希望图像避免的元素。
latent_image:输入潜在空间图像。用于在已有潜在空间图像基础上生成新图像。
denoise:设置去噪强度。通常在0.5-1之间,数值越高图像越干净。
preview_method:选择预览方法。一般使用“auto”。
vae_decode:指定是否解码潜在空间图像。大多数情况下选择“true”。
optional_vae:选择可选的VAE模型。如果有特定的VAE模型需求,选择对应模型。
script:指定要运行的脚本。通常保持默认即可,除非有特定需求。