本篇作者:
IoTDB 社区 -- 廖兰宇
本文将概述用户使用 UDF 的大致流程,UDF 的详细使用说明请参考官网用户手册:
https://iotdb.apache.org/zh/UserGuide/Master/Operators-Functions/User-Defined-Function.html
1
编写 UDF
IoTDB 为用户提供编写 UDF 的 JAVA API,用户可以自主实现 UDTF 类,IoTDB 将通过类加载机制装载用户编写的类。
1.1
Maven 依赖
如果您使用 Maven,可以从 Maven 库中搜索下面示例中的依赖。请注意选择和目标 IoTDB 服务器版本相同的依赖版本,本文中使用 1.0.0 版本的依赖。
<dependency>
<groupId>org.apache.iotdb</groupId>
<artifactId>udf-api</artifactId>
<version>1.0.0</version>
<scope>provided</scope>
</dependency>1.2
实现接口
UDTF 目前有如下接口:
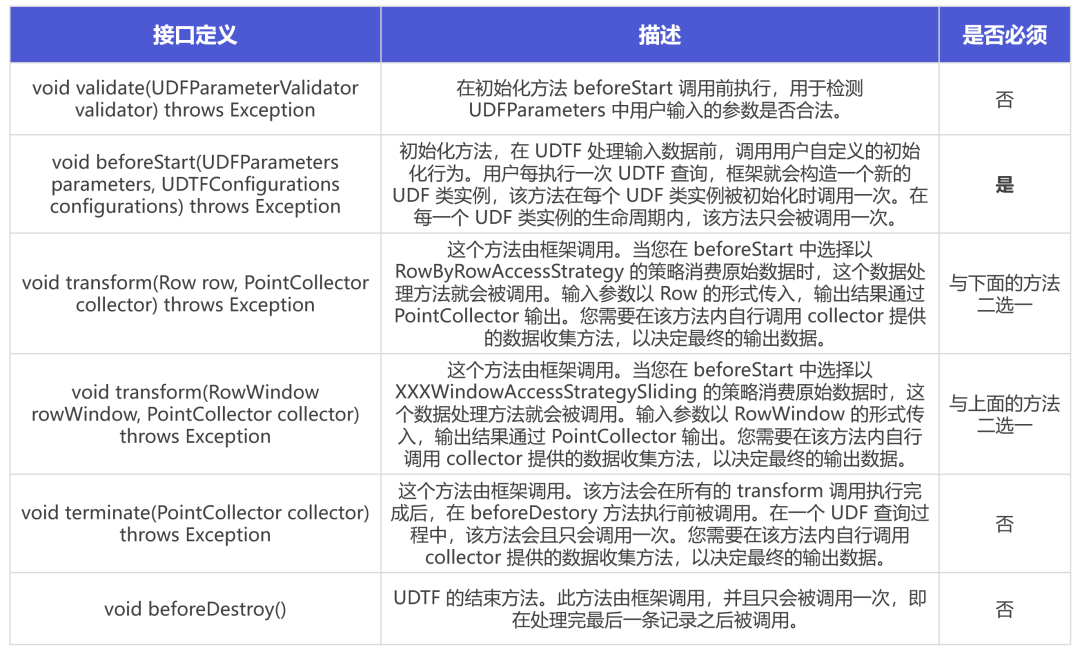
在一个完整的 UDTF 实例生命周期中,各个方法的调用顺序如下:
1. void validate(UDFParameterValidator validator) throws Exception2. void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exception3. void transform(Row row, PointCollector collector) throws Exception
// 或者
void transform(RowWindow rowWindow, PointCollector collector) throws Exception4. void terminate(PointCollector collector) throws Exception5. void beforeDestroy()注意,框架每执行一次 UDTF 查询,都会构造一个全新的 UDF 类实例,查询结束时,对应的 UDF 类实例即被销毁,因此不同 UDTF 查询(即使是在同一个 SQL 语句中)UDF 类实例内部的数据都是隔离的。您可以放心地在 UDTF 中维护一些状态数据,无需考虑并发对 UDF 类实例内部状态数据的影响。
UDTF 有较为完善的 Javadoc 说明,在编码实现 UDTF 类前,阅读说明可以帮助您更好的使用 UDTF。
1.3
注意事项
下面列出在实现 UDTF 的一些接口时需要注意的地方。
1.3.1 validate 接口
/**
* This method is mainly used to validate {@link UDFParameters} and it is executed before {@link
* UDTF#beforeStart(UDFParameters, UDTFConfigurations)} is called.
*
* @param validator the validator used to validate {@link UDFParameters}
* @throws Exception if any parameter is not valid
*/
@SuppressWarnings("squid:S112")
default void validate(UDFParameterValidator validator) throws Exception {}该接口在初始化方法 beforeStart 调用前执行,用于检测 UDFParameters 中用户输入的参数是否合法。
同时,可以检测作为输入的时间序列的数据类型是否符合预期,比如以如下方式实现该接口:
@Override
public void validate(UDFParameterValidator validator) throws Exception {
validator
// this udf only accepts 1 time series
.validateInputSeriesNumber(1)
// the data type of the first input time series should be INT32
.validateInputSeriesDataType(0, Type.INT32)
// this udf doesn't accept any extra parameters
// the validation rule is not required because extra parameters will be ignored
.validate(
attributes -> ((Map) attributes).isEmpty(),
"extra udf parameters are not allowed",
validator.getParameters().getAttributes());
}那么该 UDF 将只能接受 INT32 类型的时间序列作为输入,其它类型的序列作为输入将报错:
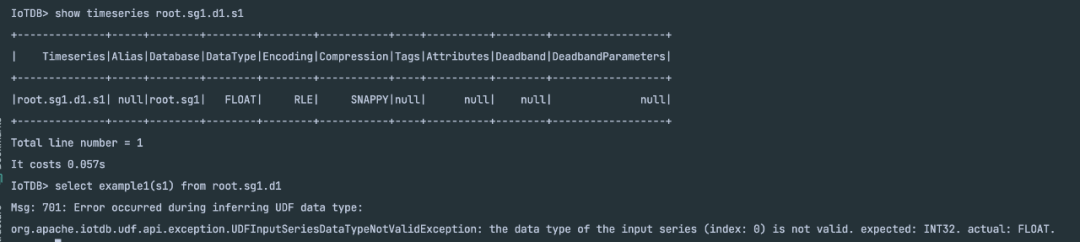
INT32 类型的序列正常执行查询:
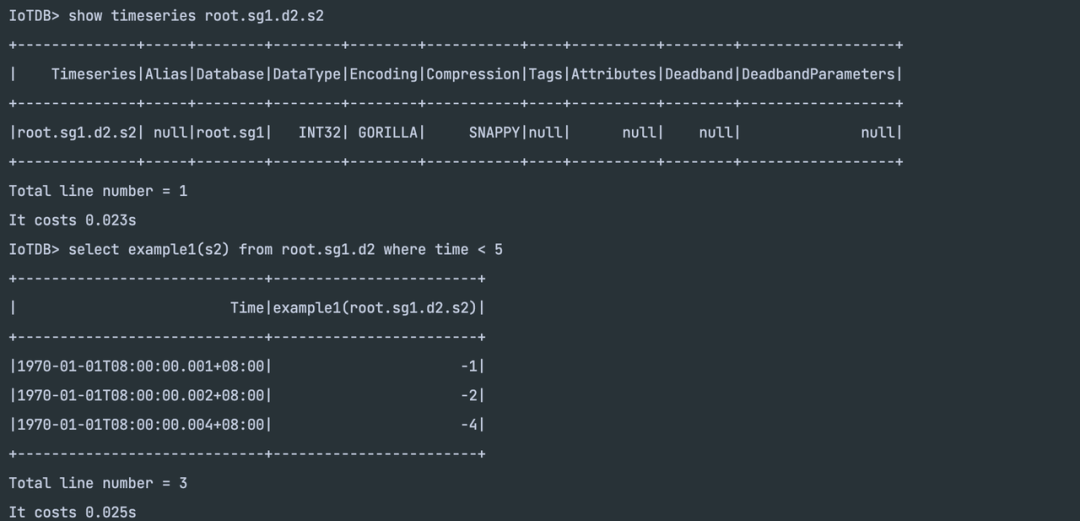
1.3.2 beforeStart 接口
void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exception该接口是 UDTF 类必须实现的接口,可以指定 UDF 访问原始数据时采取的策略和输出结果序列的类型,最简单的实现方式如下:
@Override
public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
configurations.setAccessStrategy(new RowByRowAccessStrategy()).setOutputDataType(Type.INT32);
}上述实现表明该 UDF 将逐行访问数据并调用相应的 transform 方法,同时,该 UDF 的 transform 方法的 PointCollector 将只能接收 INT32 类型的数据,如果接收其它类型的数据可能会出现运行时错误,具体可以参考 UDTF Javadoc。可以参考如下的简单实现方式:
@Override
public void transform(Row row, PointCollector collector) throws IOException {
if (!row.isNull(0)) {
// 由于 beforeStart 方法中设置了 outPutDataType 为 INT32
// 这里如果调用 collector.putFloat(row.getTime(), -row.getInt(0)) 可能会出现运行时错误
collector.putInt(row.getTime(), -row.getInt(0));
}
}这样实现之后,查询效果可以理解成将每一行数据取负:
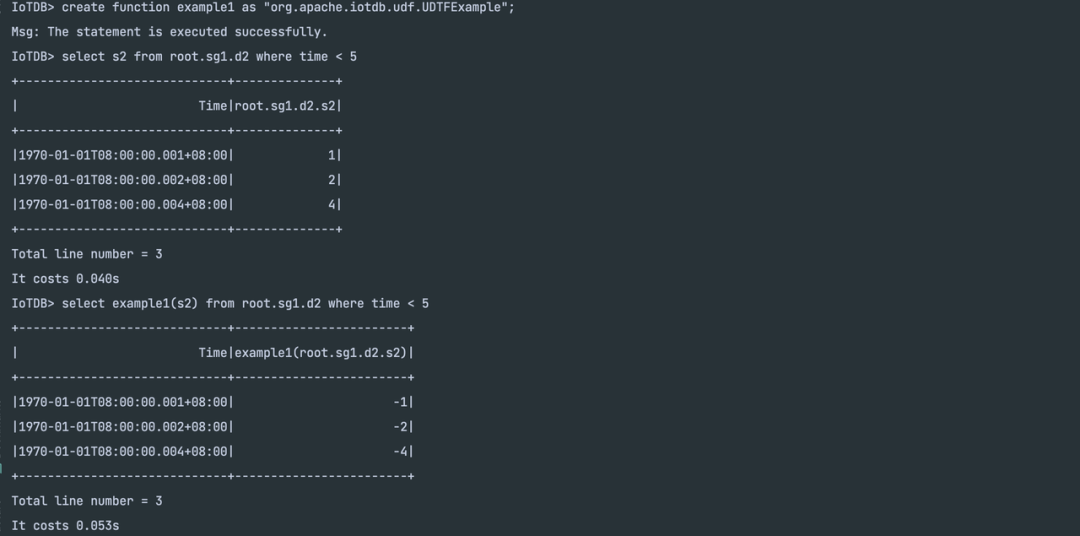
1.3.3 transform 接口
transform 接口有两种参数列表,具体调用哪一种由实现的 UDF beforeStart 接口中设置的 AccessStrategy 类型决定。如果 AccessStrategy 类型为 XXXWindowStrategy,则会调用下述 transfrom:
/**
* When the user specifies {@link SlidingSizeWindowAccessStrategy} or {@link
* SlidingTimeWindowAccessStrategy} to access the original data in {@link UDTFConfigurations},
* this method will be called to process the transformation. In a single UDF query, this method
* may be called multiple times.
*
* @param rowWindow original input data window (rows inside the window are aligned by time)
* @param collector used to collect output data points
* @throws Exception the user can throw errors if necessary
* @see SlidingSizeWindowAccessStrategy
* @see SlidingTimeWindowAccessStrategy
*/
@SuppressWarnings("squid:S112")
default void transform(RowWindow rowWindow, PointCollector collector) throws Exception {}由于入参 RowWindow 时按照原始数据划分的窗口,在访问窗口数据时有几点需要注意:
1. 窗口可能为空,此时访问窗口内具体某一行可能报越界异常,所以建议在访问具体数据前检查 if(rowWindow.windowSize() > 0)
2. 目前 PointCollector 只支持将特定时间戳放入一次,如果同一时间戳被多次放入,则可能非预期地终止计算。而在进行窗口的运算的时候,需要选取窗口中某一行的时间戳作为这个窗口结果的时间戳,在特定数据场景下,这种使用可能会由于窗口重叠造成同一时间戳被多次放入 PointCollector 而导致非预期的结果。如果要避免这种情况,可以选择使用 RowWindow 提供的 windowStartTime() 或者 windowEndTime() 作为窗口结果的时间戳。
可以参考下述实现:
public void transform(RowWindow rowWindow, PointCollector collector) throws Exception {
long result = 0L;
for (int i = 0; i < rowWindow.windowSize(); ++i) {
if (!rowWindow.getRow(i).isNull(0)) {
result += rowWindow.getRow(i).getLong(0);
}
}
// 这里使用 rowWindow.windowStartTime() 而非 rowWindow.getRow(0).getTime()
collector.putLong(rowWindow.windowStartTime(), result);
}2
注册UDF
注册一个 UDF 可以按如下流程进行:
实现一个完整的 UDF 类,假定这个类的全类名为
org.apache.iotdb.udf.UDTFExample
2. 将项目打成 JAR 包
3. 进行注册前的准备工作,根据注册方式的不同需要做不同的准备,具体可参考示例
4. 使用以下 SQL 语法注册 UDF
CREATE FUNCTION <UDF-NAME> AS <UDF-CLASS-FULL-PATHNAME> (USING URI URI-STRING)?完成注册后即可以像使用内置函数一样使用注册的 UDF 了。
2.1
注册方式示例
注册名为 example 的 UDF,以下两种注册方式任选其一即可。
2.1.1 不指定 URI
准备工作:
使用该种方式注册时,需要提前将 JAR 包放置到目录 iotdb-server-1.0.0-all-bin/ext/udf(该目录可配置) 下。
注意,如果使用的是集群,那么需要将 JAR 包放置到所有 DataNode 的该目录下。
放置完成后使用注册语句:
CREATE FUNCTION example AS 'org.apache.iotdb.udf.UDTFExample'2.1.2 指定 URI
准备工作:
使用该种方式注册时,您需要提前将 JAR 包上传到服务器上并确保执行注册语句的 IoTDB 实例能够访问该服务器。
指定 URI 后无需手动放置 JAR 包到指定目录,IoTDB 会下载 JAR 包并正确同步到整个集群。
注册语句:
CREATE FUNCTION example AS 'org.apache.iotdb.udf.UDTFExample' USING URI 'http://jar/example.jar'2.2
注意事项
1. 1.0.0 版本的 UDF API 包路径与之前版本的 IoTDB 不同,因此 1.0.0 版本的 IoTDB 实例并不能注册 0.13 及之前版本已经构建好的 UDF jar 包。可以通过更新 UDF 依赖版本,重新 import 正确路径的 UDF API,再构建 jar 包的方式更新 UDF 实现至 1.0.0 及以上版本。
2. 由于 IoTDB 的 UDF 是通过反射技术动态装载的,因此在装载过程中无需启停服务器。
3. UDF 函数名称是大小写不敏感的。
4. 请不要给 UDF 函数注册一个内置函数的名字。使用内置函数的名字给 UDF 注册会失败。
5. 不同的 JAR 包中最好不要有全类名相同但实现功能逻辑不一样的类。例如 UDF(UDAF/UDTF):udf1、udf2 分别对应资源 udf1.jar、udf2.jar。如果两个 JAR 包里都包含一个
org.apache.iotdb.udf.UDTFExample 类,当同一个 SQL 中同时使用到这两个 UDF 时,系统会随机加载其中一个类,导致 UDF 执行行为不一致。