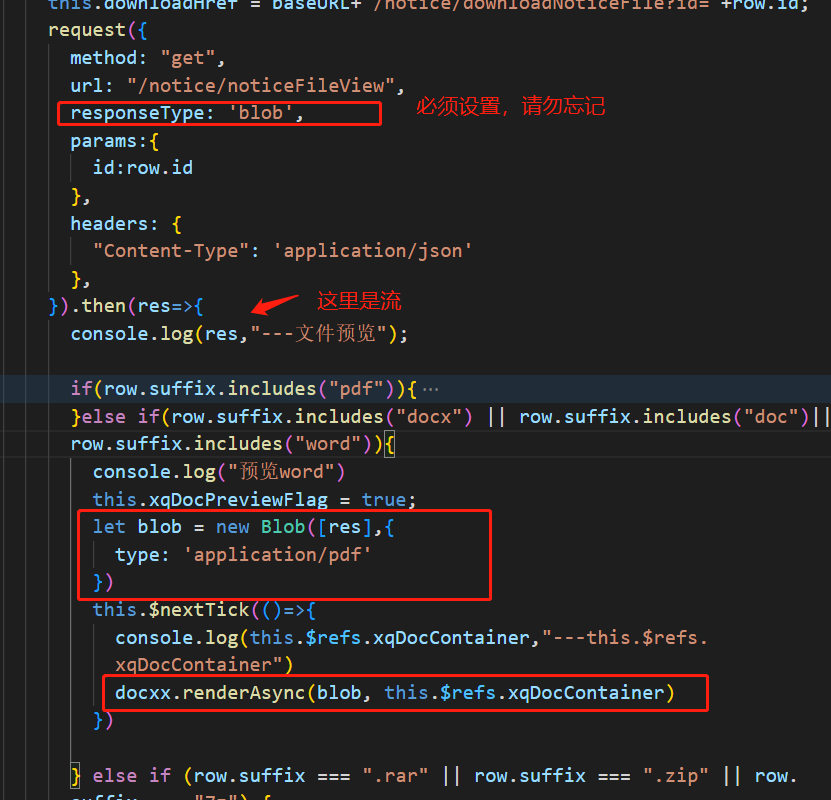
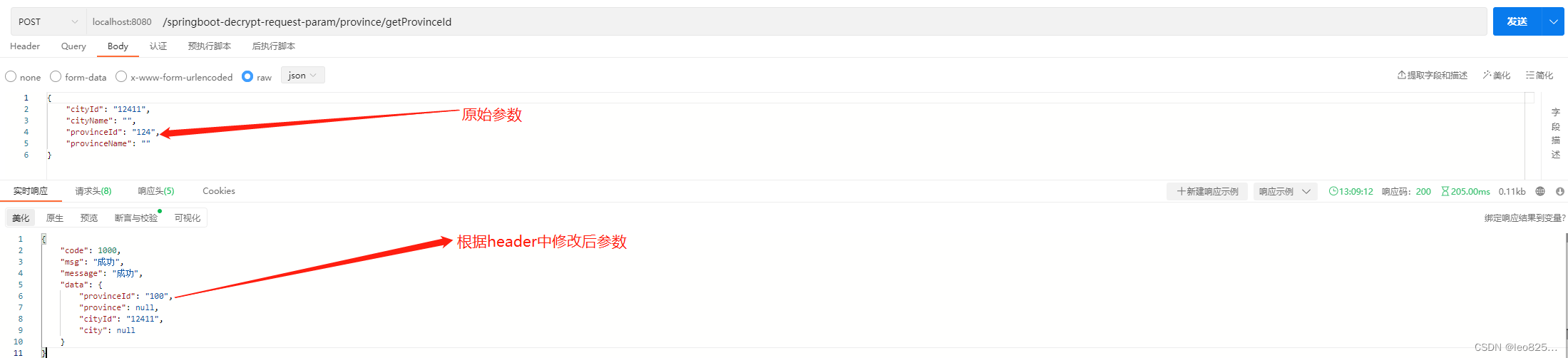
YOLO-v3
- 6. YOLO-v3
- 6.1 YOLO-v3 改进综述
- 6.2 多scale方法改进与特征融合
- 6.3 经典变换方法对比分析
- 6.4 残差连接方法解读
- 6.5 整体网络模型架构分析
- 6.6 先验框设计改进
- 6.7 softmax层改进
6. YOLO-v3
**tips:**作者本人因为美军广泛运用于军事领域,所以决定不再继续开发YOLO系列。但是其他人还是继续往后做了~v8都有了
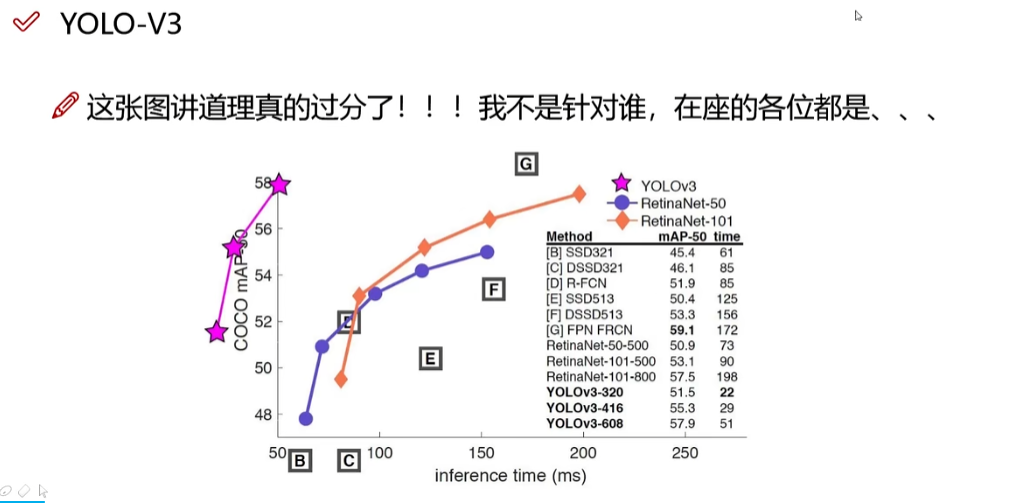
注意,原点值(x轴预测时间,y轴map)是50而不是0!YOLO-v3比其他的强很多!
6.1 YOLO-v3 改进综述
- 终于到 V3了,最大的改进就是网络结构,使其更适合小目标检测
- 特征做的更细致,融入多持续特征图信息来预测不同规格物体
- 先验框更丰富了,3种scale,每种3个规格,一共9种
- softmax改进,预测多标签任务:多分类改成很多个二分类
6.2 多scale方法改进与特征融合
从上到下依次是检测小、中、大物体
[外链图片转存中…(img-tcdXelFQ-1675132984921)]
6.3 经典变换方法对比分析
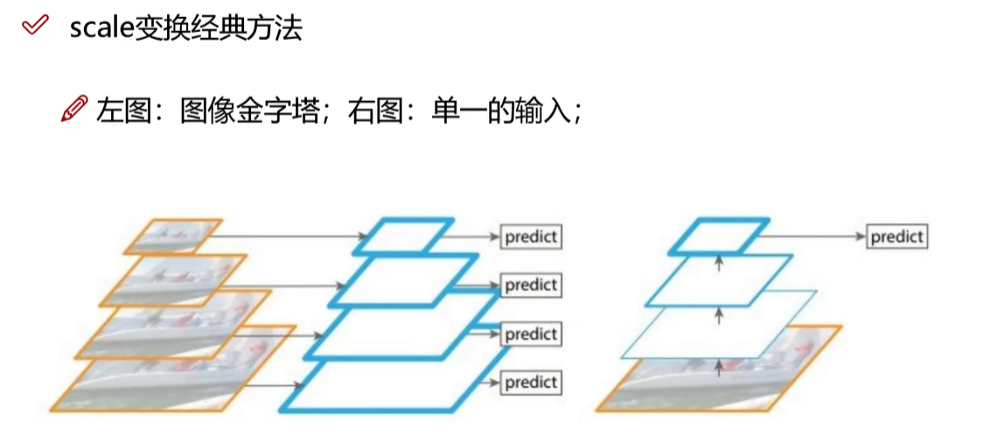
很明显,左图的图像金字塔更能满足多尺度特征融合的要求,但是YOLO的特点是速度快,因此这样反而不合适,那右图合适吗?我们接着往下看:
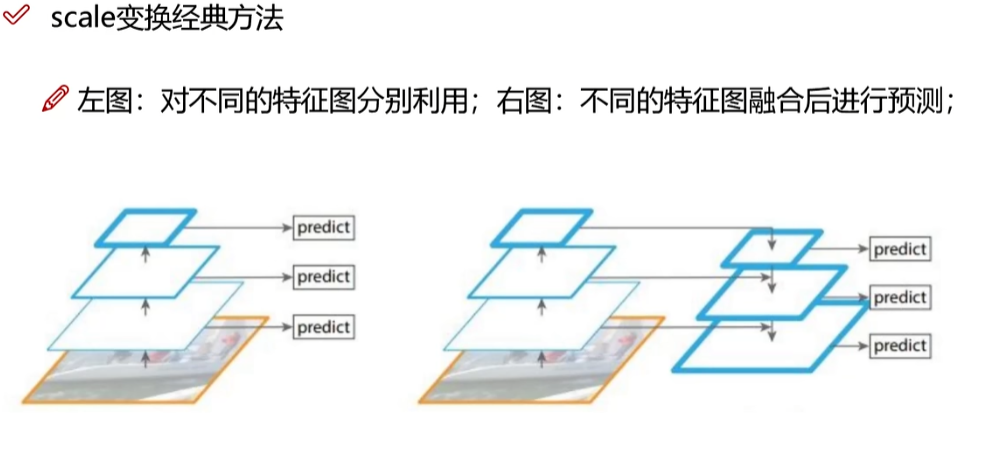
右图是YOLO-v3的核心思想,13 * 13 的特征图可以上采样成26 * 26的特征图,然后融合原来的26 * 26的特征图。
6.4 残差连接方法解读
右边的曲线图表示模型的卷积层并不是越多越好;左图就是resnet所提出的想法:残差连接
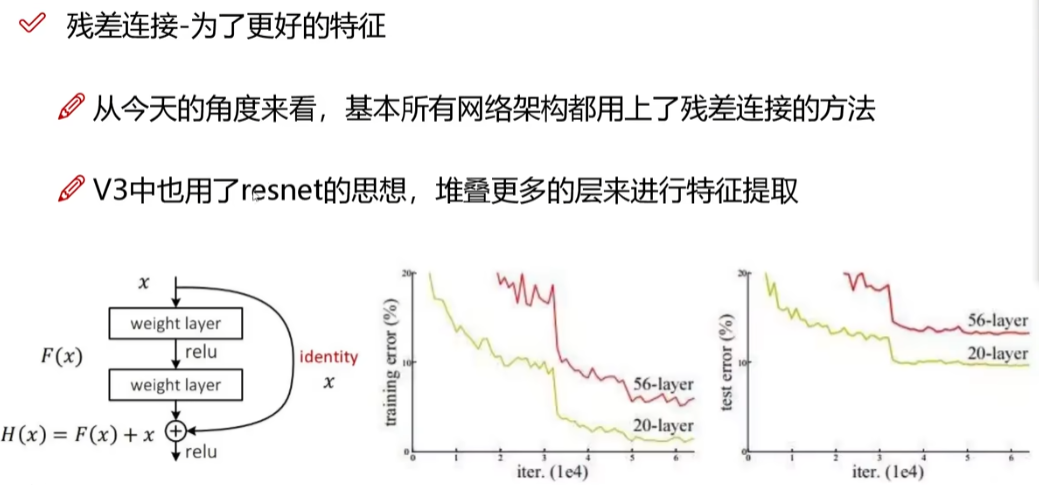
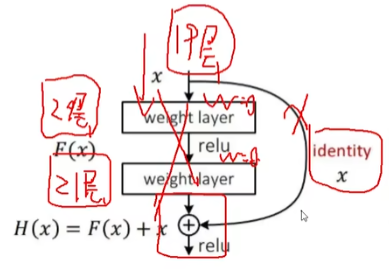
残差连接会自动检测出不适合的参数,然后跳过,总结就是一句话:至少不比原来差!
6.5 整体网络模型架构分析
[外链图片转存中…(img-E1iE52ku-1675132984924)]
所有的重复部分用2x,8x等表示出来了。下图表示出了残差连接的部分:上采样——》拼接——》卷积
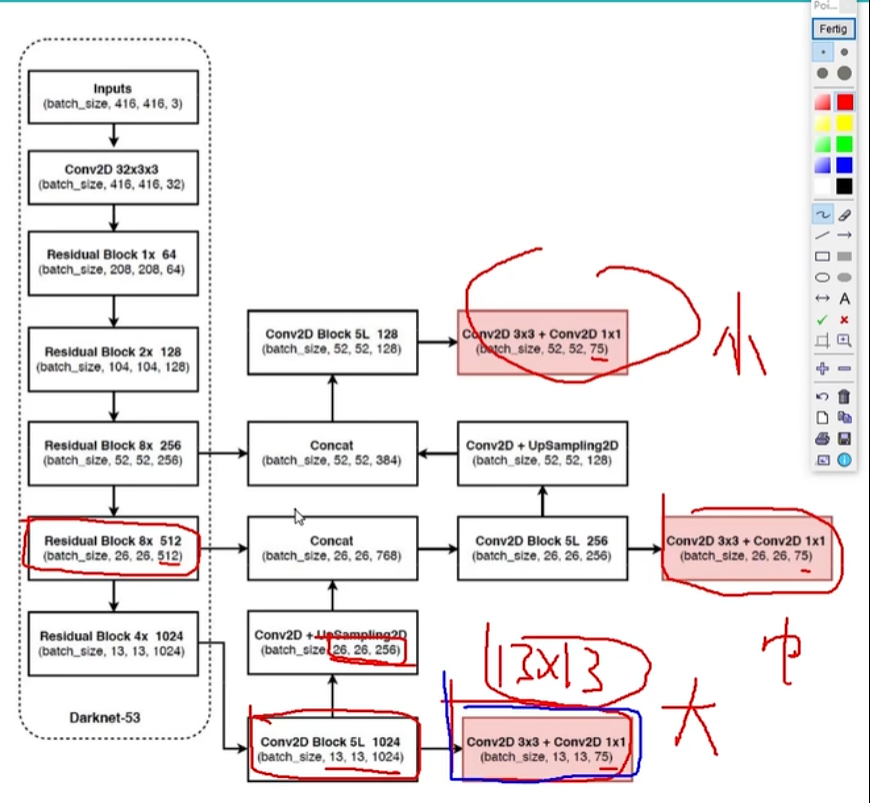
6.6 先验框设计改进
[外链图片转存中…(img-Td8DWG3g-1675132984924)]
*13 13 * 3 * 85:
- 尺度13*13
- 3种先验框
- 85=80(类别)+4(x,y,w,h)+1(confidence置信度)
[外链图片转存中…(img-rCJDp7RE-1675132984925)]
还是用聚类选择的先验框
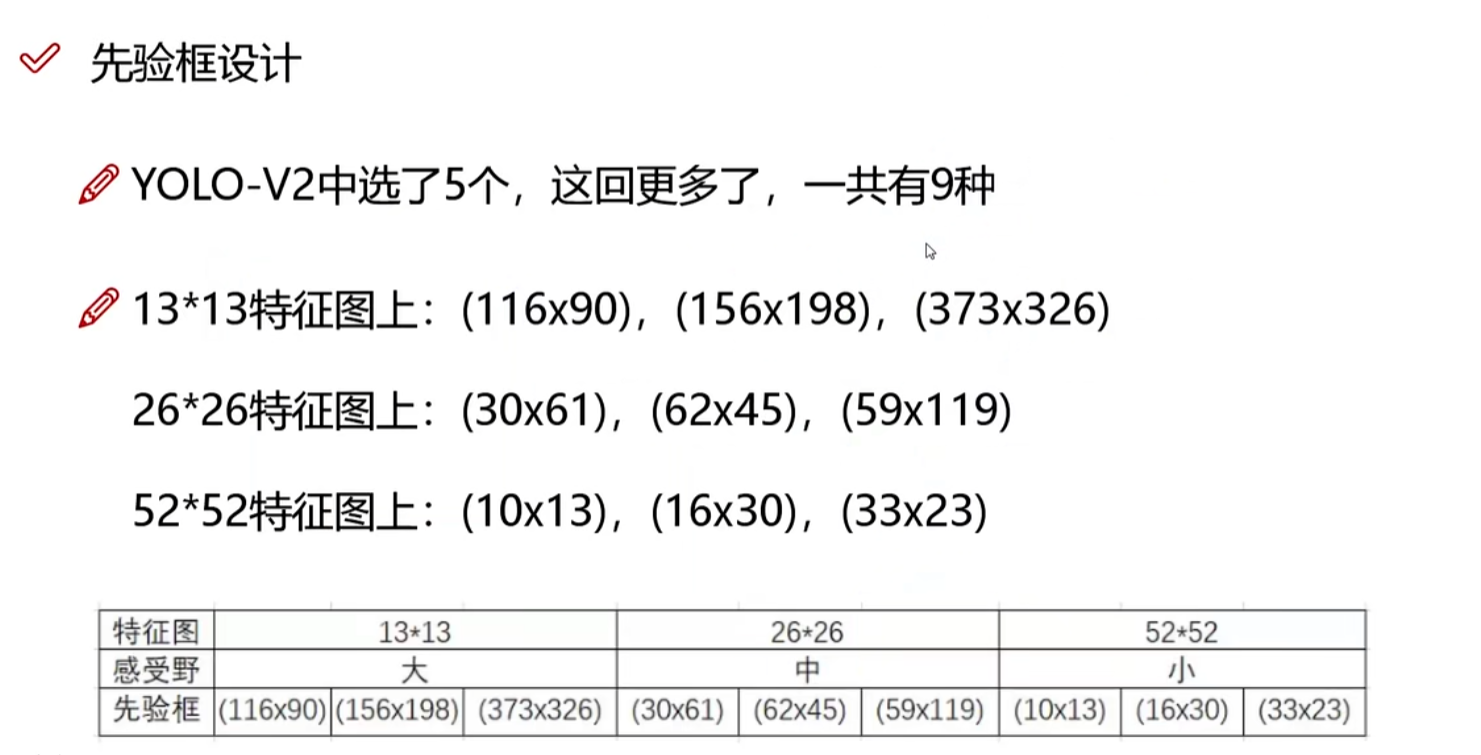
结果:
[外链图片转存中…(img-rFfQYa7R-1675132984925)]
6.7 softmax层改进
加了一个交叉熵损失
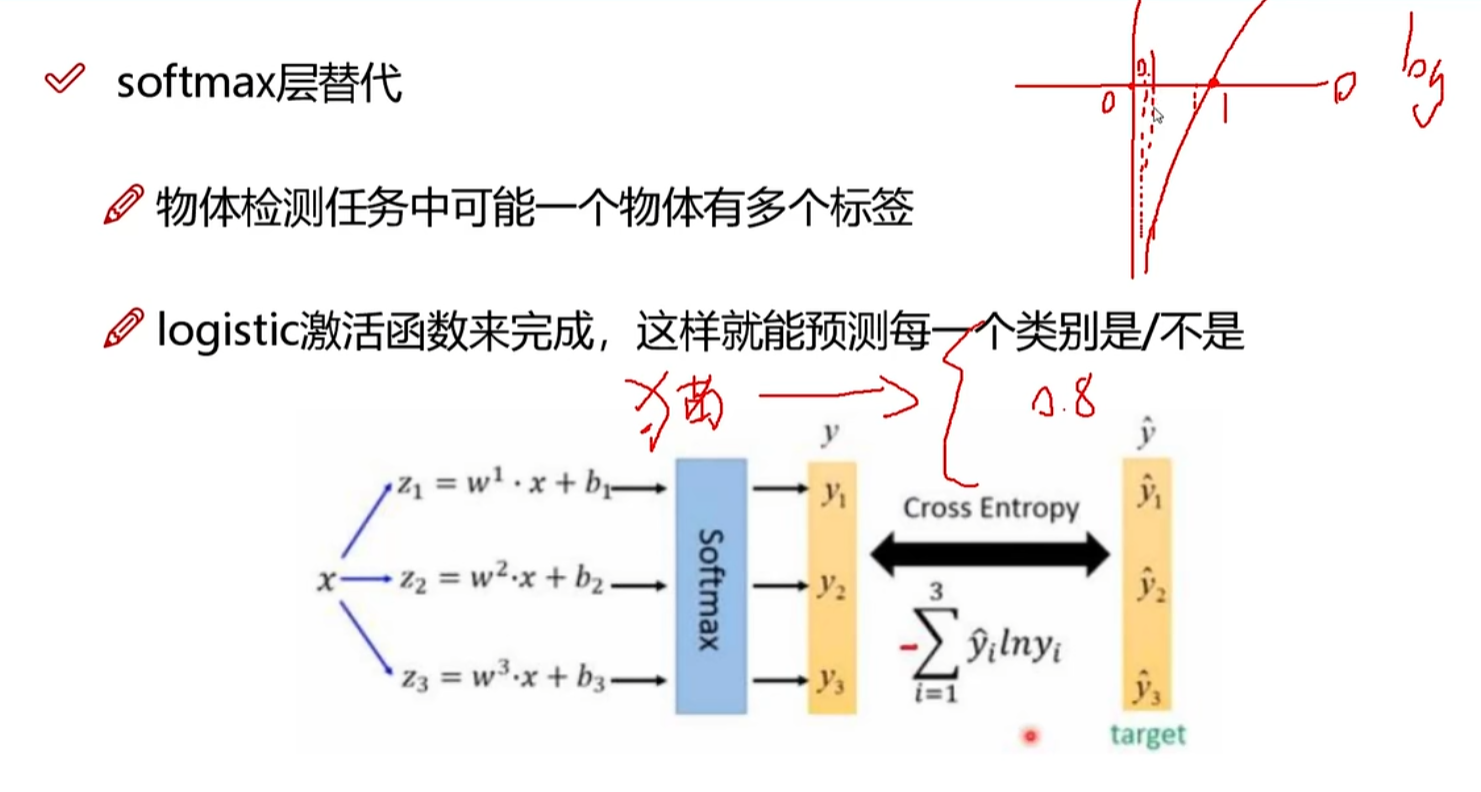
二分类任务:取阈值大于某个值的作为正确值。
[外链图片转存中…(img-k45c0d5b-1675132984926)]