本文将介绍PAE,一种用于包含 PDF格式的文本和图像的产品属性提取算法。目前大部分的方法侧重于从标题或产品描述中提取属性,或利用现有产品图像中的视觉信息。与之前的工作相比,PAE从潮流趋势报告的PDF文件中提取属性,提取的属性包含了未来的时尚趋势,然后将这些属性和零售商的产品目录对比,以便于提前做出预判和规划。

小编提示:本项目的亮点和价值在于细节,具体的作业细节!!

潮流报告
产品目录会被用于战略性地选择和组织系列产品,以满足客户需求并最大限度地提高销售额。这个过程涉及分析市场趋势、客户偏好和竞争对手的策略,以确定潜在的差距和机会——这个过程通常需要对未来流行的趋势进行预测和决策。
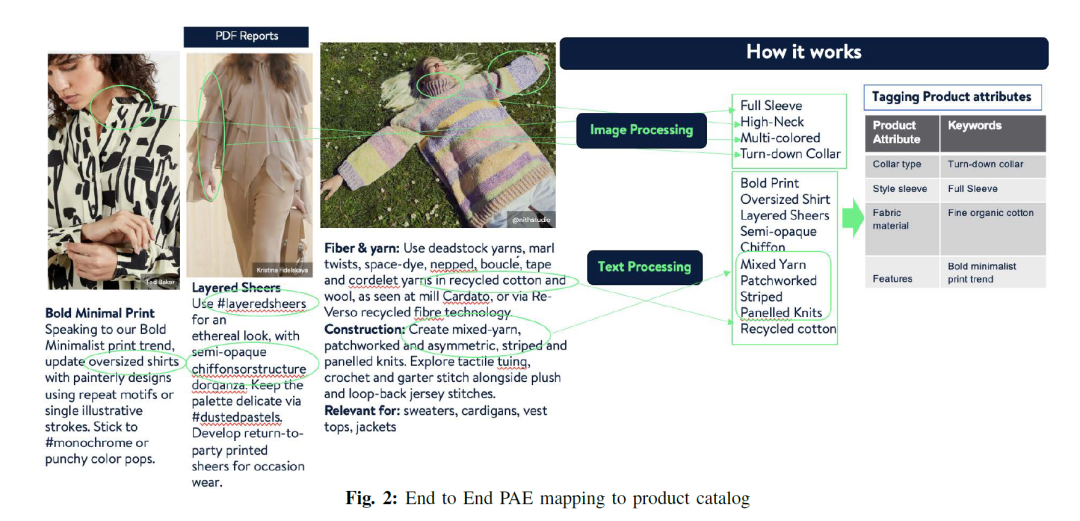
如上图所示,一些主流或者相关行业的调查报告会涵盖纺织品和材料创新、产品开发以及生活方式和室内设计趋势,通过对这些信息进行提取产品属性值,然后将属性值正确的映射到产品属性。在结合自身的产品库,就可以根据未来的流行趋势对自身的产品进行调整,或者为自身的产品贴上更合适的标签以便于形成网红产品。
项目的具体流程如下,从给定的PDF文件中提取所有文本(段落)和相关图像,使用LLM模型从图像和文本中提取相关属性。将属性合并到每个类别中,并为每个属性保留唯一值。利用基于Bert的模型将这些属性和目前现有库存的商品进行匹配,以便组织和规划未来的目录。
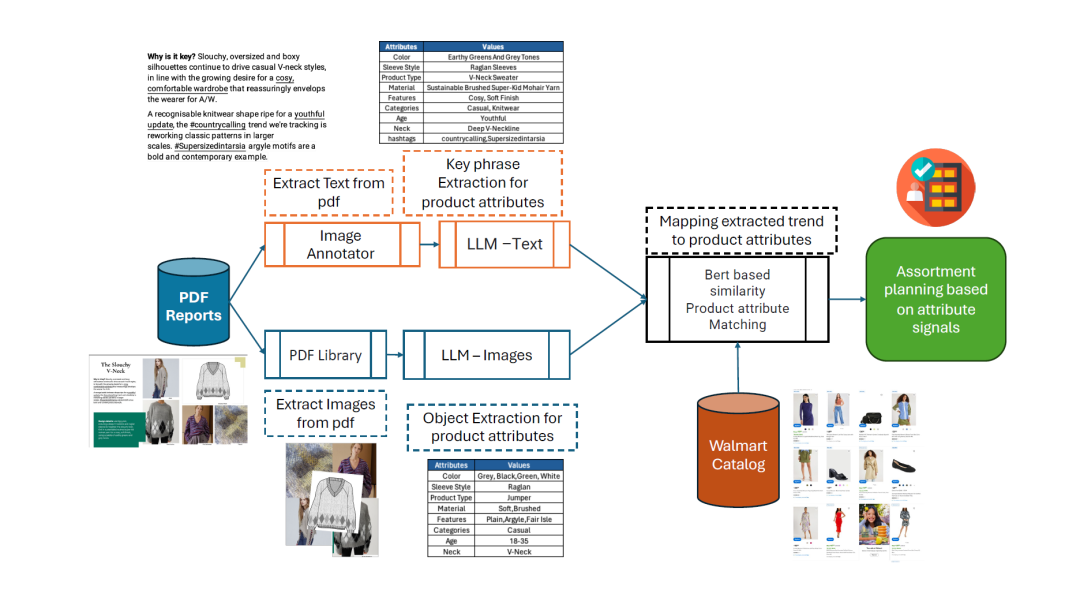
产品属性提取 (PAE) 引擎可以帮助零售行业加入新商品或从现有目录中提取属性。我们进行了这篇较长的论文中描述的大量实验,以表明与现有的最先进的属性提取框架相比,PAE 是一个有效、灵活的框架,与现有最先进的属性提取框架相当或更胜一筹(平均 92.5% F1 分数)。

PDF的文字提取
PDF文档的布局复杂性可能会使提取过程变得困难。例如,存在多个列、图像、表格和脚注会使纯文本的提取变得复杂。另一个挑战是在PDF中使用非标准或自定义字体,这可能导致提取结果不准确。此外,页眉、页脚、HTML 标签和页码等“噪音”的存在也会干扰提取过程。

有许多工具可用于文本提取,例如pdfMiner或pdfquery。上图显示从pdf 文件中提取文本的过程。首先,使用pdf2image中的“convert from path”功能将PDF文件拆分为PIL(Python 图像库)图像。
在内部,该函数使用pdfinfo命令行工具从 PDF 文件中提取元数据,例如页数。然后使用pdftocairo命令行工具将PDF的每一页转换为图像。其次,将图像转换为灰度,并通过应用形态梯度算子来增强和隔离文本区域,从而在每个页面上进行形态转换。最后使用具有光学字符识别 (OCR)功能的图像注释器进行文本提取。提取文本后使用拼写校正器(如 LanguageTool)来修复 OCR 中任何被误解的文本。

PDF的图片提取
PDF文件可以包含各种格式的图像,例如JPEG、PNG或TIFF。从不同格式提取图像可能需要多种技术。高效、及时地从大型 PDF 文件中提取图像可能是一个挑战,尤其是在处理有限的系统资源时。为了应对上述挑战,利用纯Python PDF库直接从 PDF 文件中提取图像对象并将它们提取为原始的字符串。然后使用 Pillow处理提取的图像并以 jpg 格式保存。


属性映射到现有产品目录
首先需要从之前的文本和图像中提炼有效的产品的属性值,这里直接使用Prompt工程利用现有的LLM进行信息的提炼。如下为具体的例子:
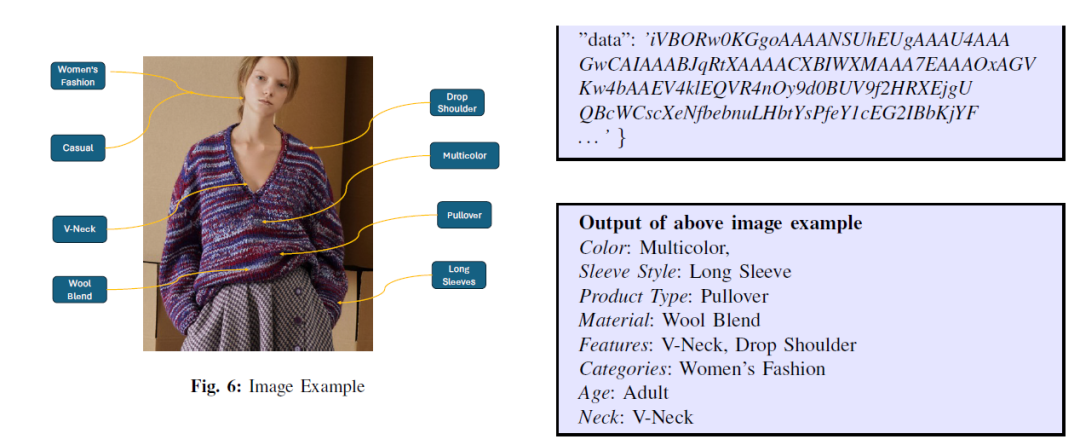
这个阶段常见的问题是存在嘈杂和缺失的标签。准确标记和注释PDF中每一页的所有相关信息是一项具有挑战性的任务。尽管采用了各种自动和手动注释流程,但几乎不可能获得完美标记的结构化数据。为了解决这个问题,研究团队采用图像预处理或数据清理技术来消除重复、嘈杂和无效的图像,然后再进行属性提取。
那么从每个页面上的文本和图像中提取属性,聚合之后就有了很多潮流趋势的属性和属性值。如何将这些信息映射到现有的产品目录,具体的过程如下:
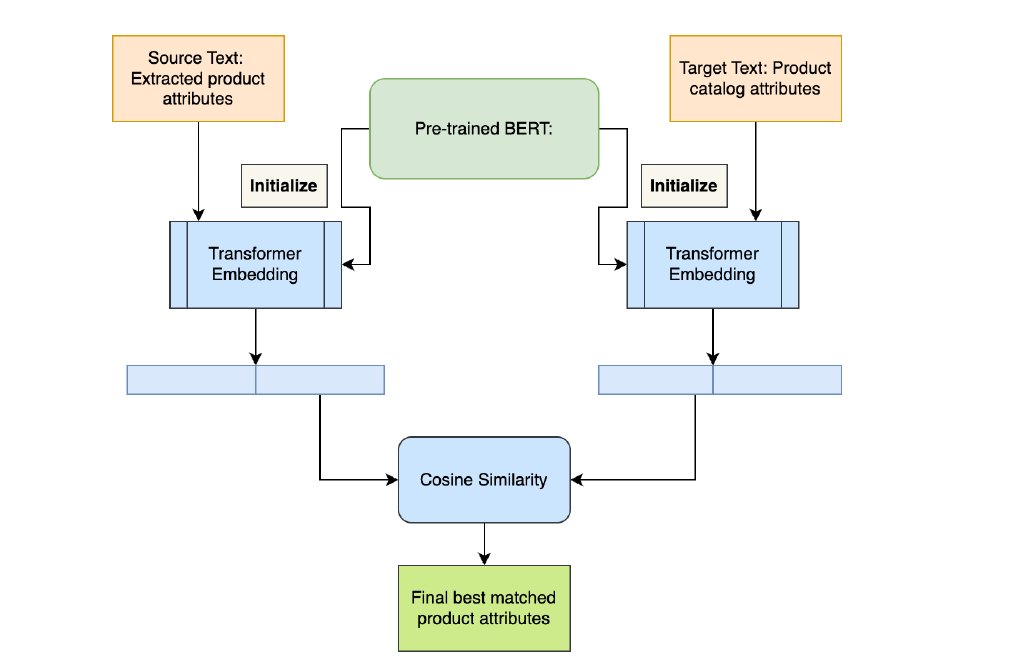
商品属性匹配的挑战之一是,一个属性有很多不同的表示说法。例如,“vneck”需要和“V-Neck”进行合并为“V-Neck”。
这里使用了预训练BERT无大小写模型。BERT是个双向表示的模型,通过它生成源和目标的词嵌入,最后用余弦相似度来匹配现有目录中的相似的属性。
|
|
|
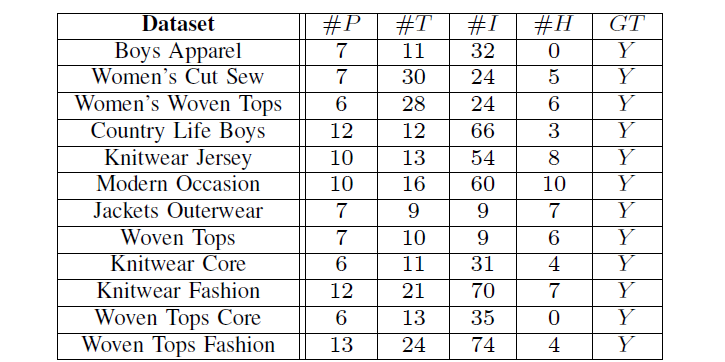

上面左图为每种潮流类型(都是衣服)提炼的页数P,文本数T,图片数I,小标签数H。右图则为F1-Score(准确性)。
到此就完成了从pdf提炼信息,然后和自身数据库整合的过程。后续就会有很多的应用,例如可以将匹配的产品增加曝光,或者增加缺乏的产品。其实某种意义上实现了最新信息跟踪的数字化过程。小编认为要是结合LangChian或者LlamaIndex作为调度框架会更加的流畅,具体就交给各位读者去实施。