python学习推荐网址:
白月黑羽
一、语法基础
目标:
• list、tuple、set、dict的基本用法
• 内置函数 len(), eval(),range(),sort(Ist, key=")
•列表推导式:
• data = [num for num in range(20) if num%2==1]
• data =[[random) for j in range(5)] for i in range(3)]
•生成器表达式
•惰性求值,需要转化成list或tuple使用
• 内置函数 enumerate(),filter(), map(), zip(,reversed()

1、运算符

☆运算符 逻辑表达式 简要说明
and x and y 布尔"与" - 若 x 为 False,x and y 返回 False,否则返回 y 的计算值
or x or y 布尔"或" - 若 x 为非 0,则返回 x 的值,否则返回 y 的计算值
not not x 布尔"非" - 若 x 为 True,返回 False;若 x 为 False,返回 True
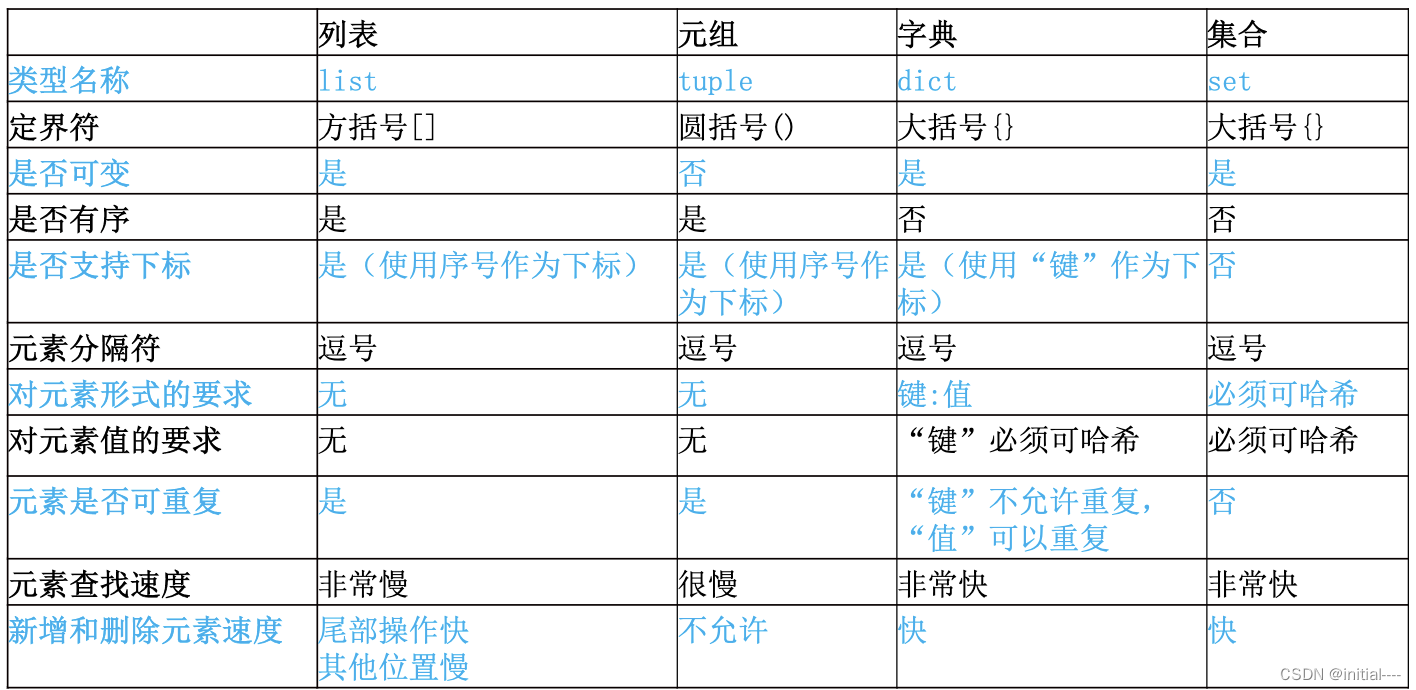
常用数据类型对比图:
2、字符串String" "
(1)切片

(2)函数


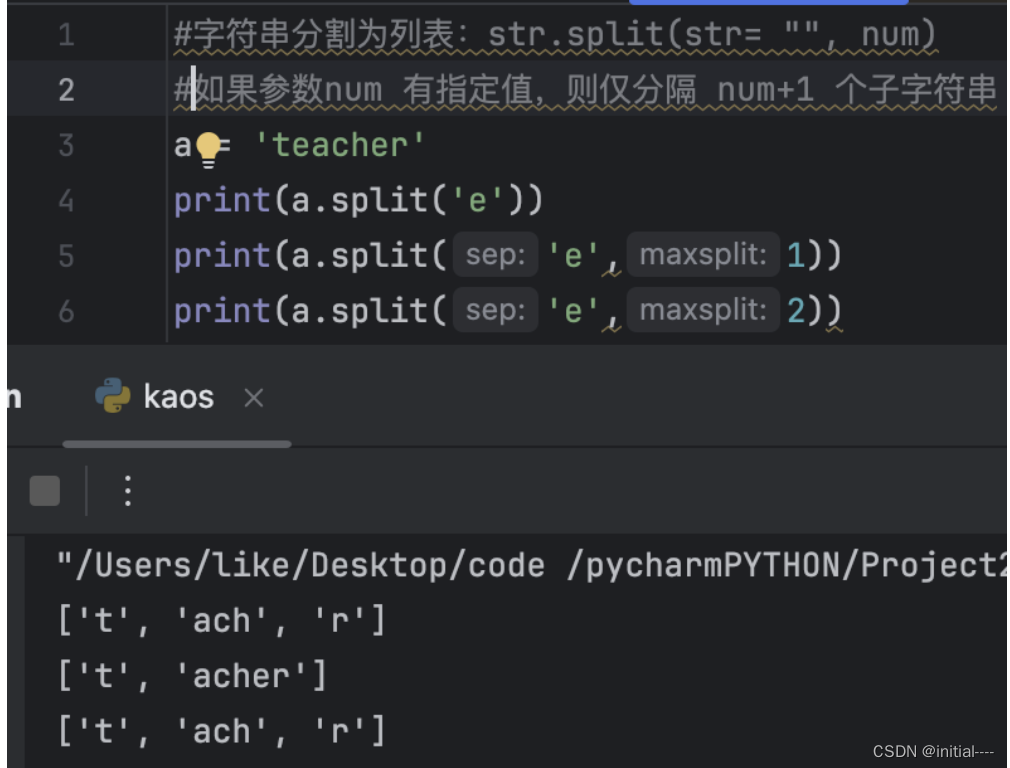
#提取下面字符串中的50,0,51
str="xxxxxxxxxxxx5 [50,0,51]>,xxxxxxxxxx"
print(str.split('[')[1].split(']')[0].split(','))
#output:['50', '0', '51']3、列表List [ ]
tips:
1、list1.append(str)
#返回:直接在原列表上添加单个元素,不能写成list2=list1.append(str)
2、list1.extend(list2)
#返回list1,将两个列表连起来组成(相加)一个新的列表,即list1+=list2
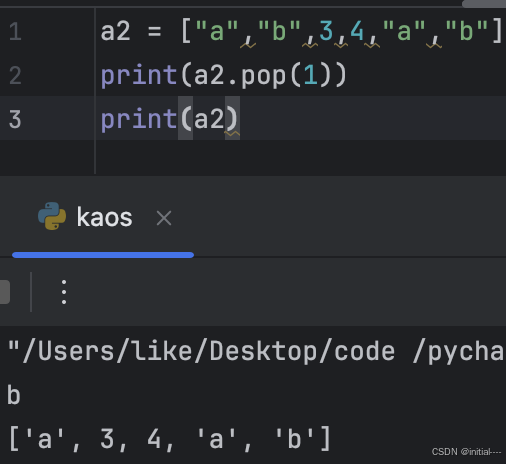
3、a1.pop()
#删除指定的索引位置元素,默认删除最后一个元素,并将删除的元素显示
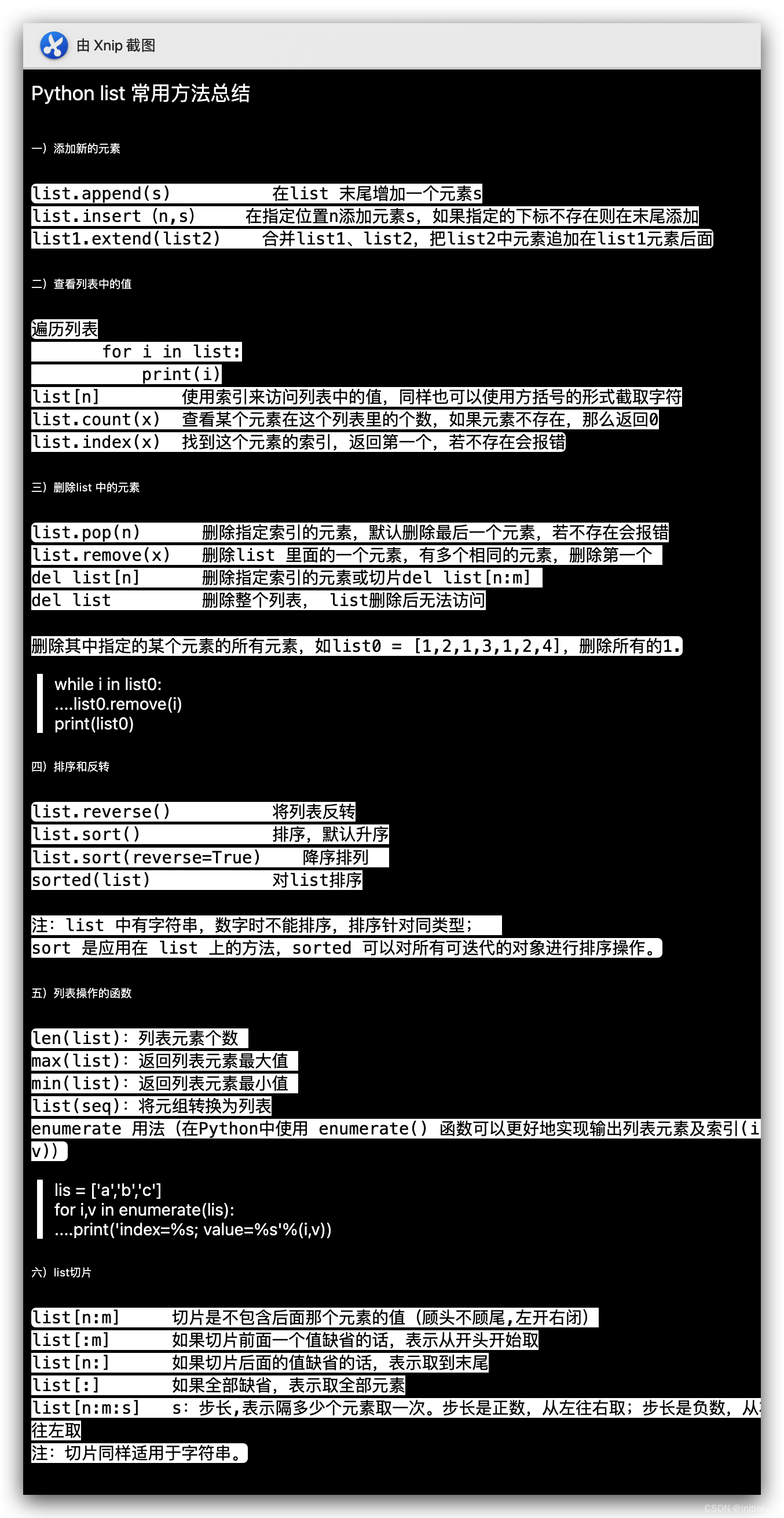
list常用方法:
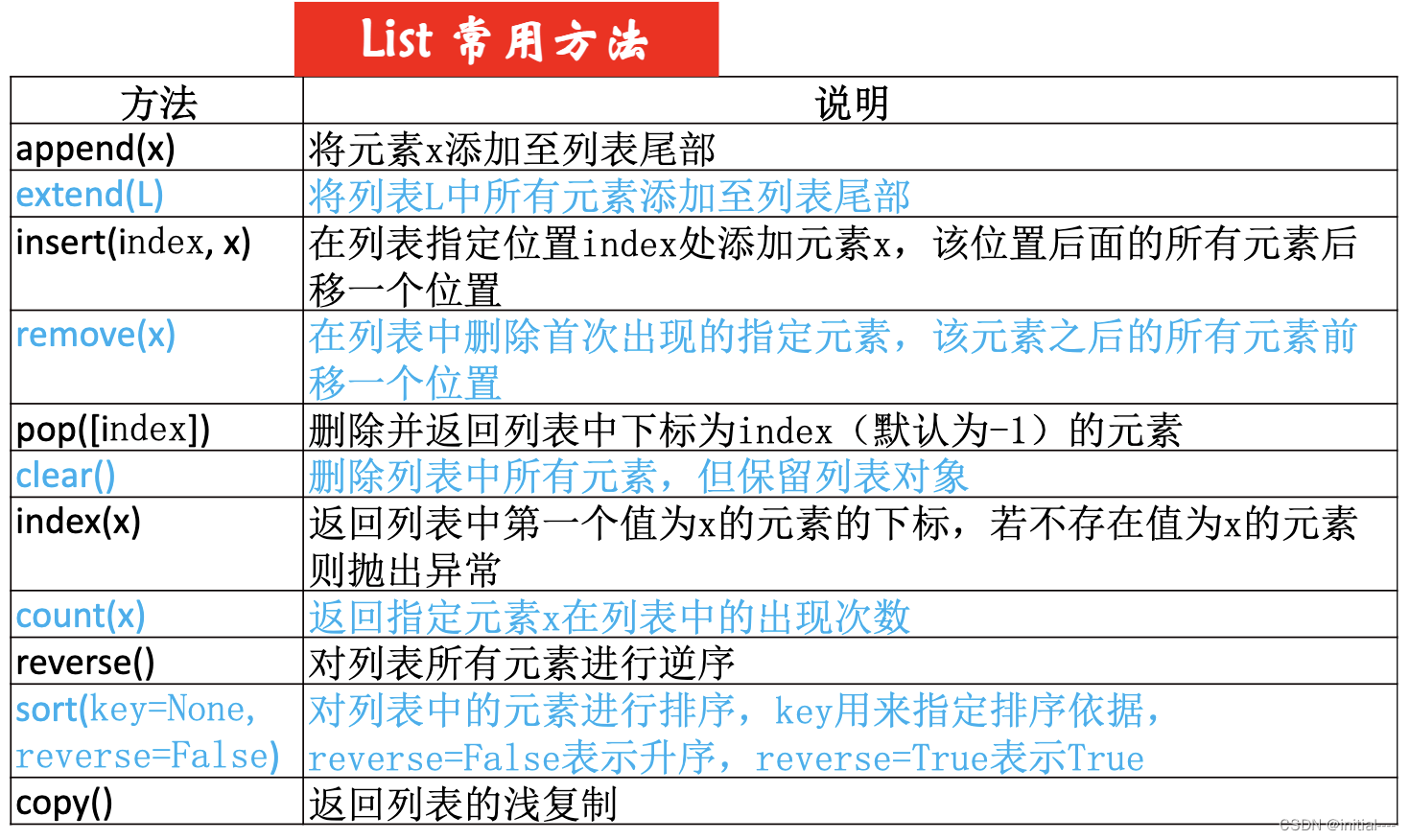
4、元组tuple( )

tuple.count(x):统计x元素在元组中的索引
tuple.index(x):查找第一个x元素在元组中的索引
5、字典dict { key:value}


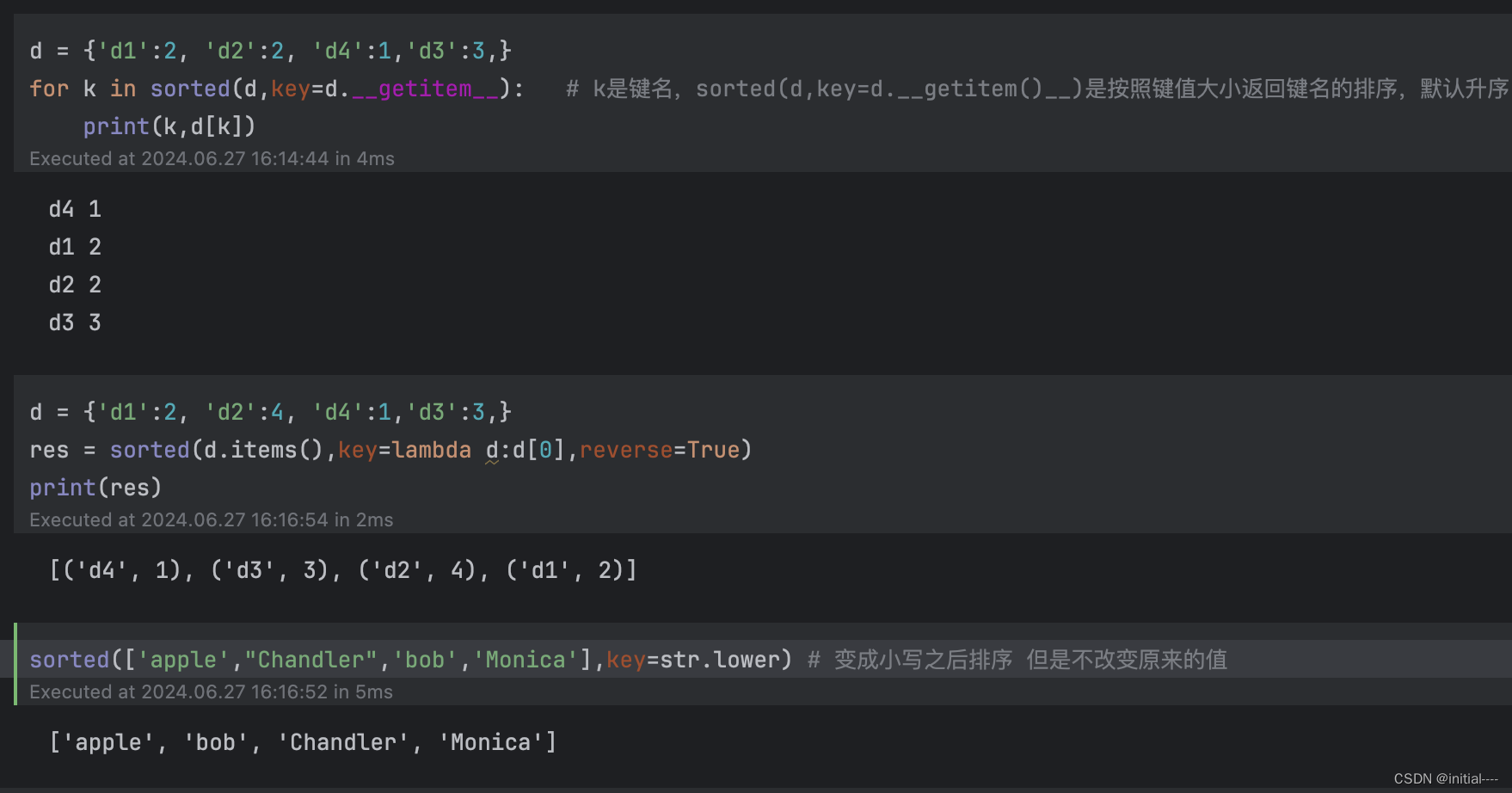
字典元素访问:
使用字典对象的items()方法返回字典中的元素,即所有“键:值”对,
字典对象的keys()方法返回所有“键”,
values()方法返回所有“值”。
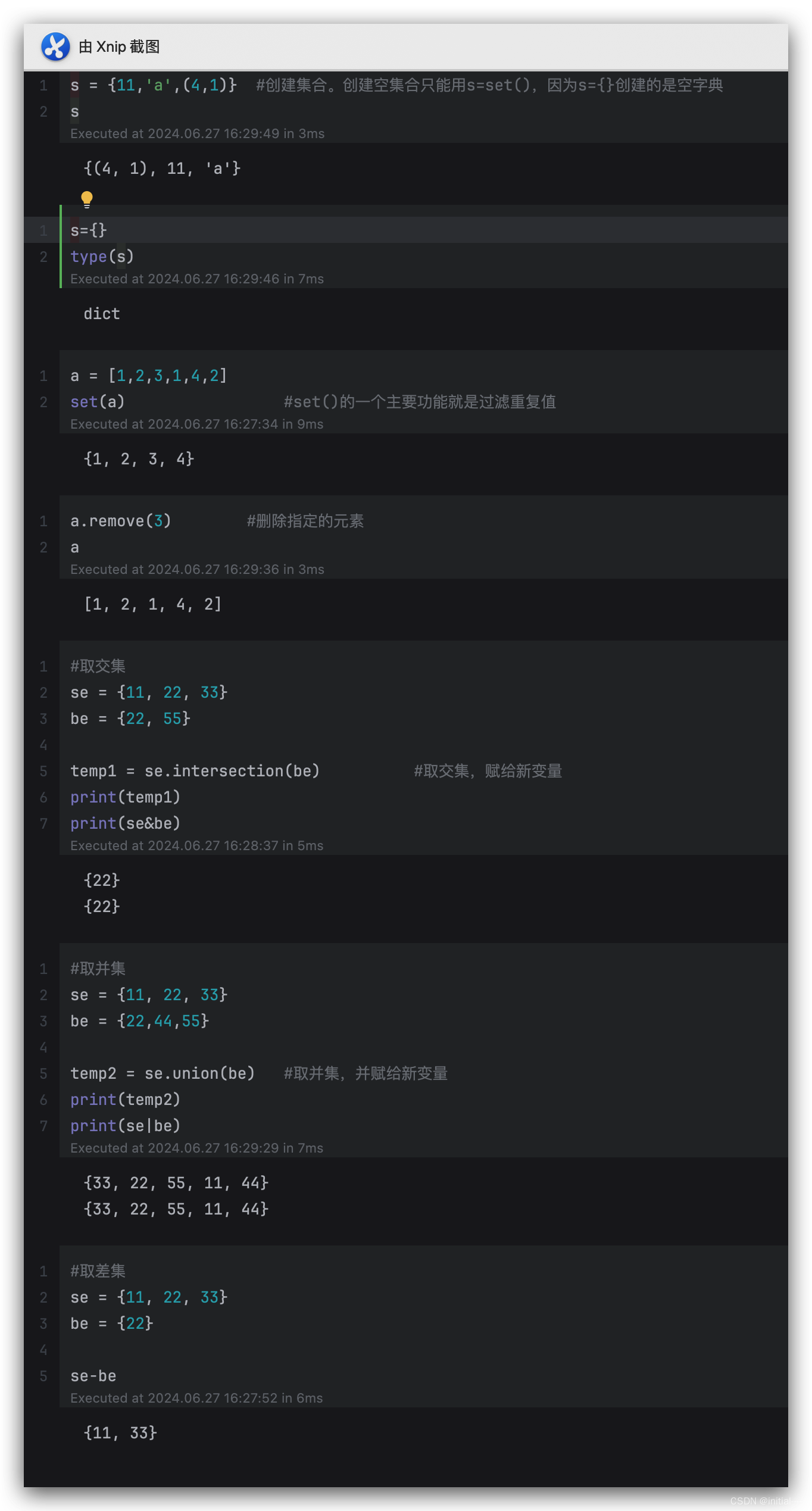
6、集合set{ }
1、set是一个无序且不重复的元素集合。
2、集合成员可以做字典中的键。
集合支持用in和not in操作符检查成员
由len()内建函数得到集合的基数(大小)
用 for 循环迭代集合的成员。
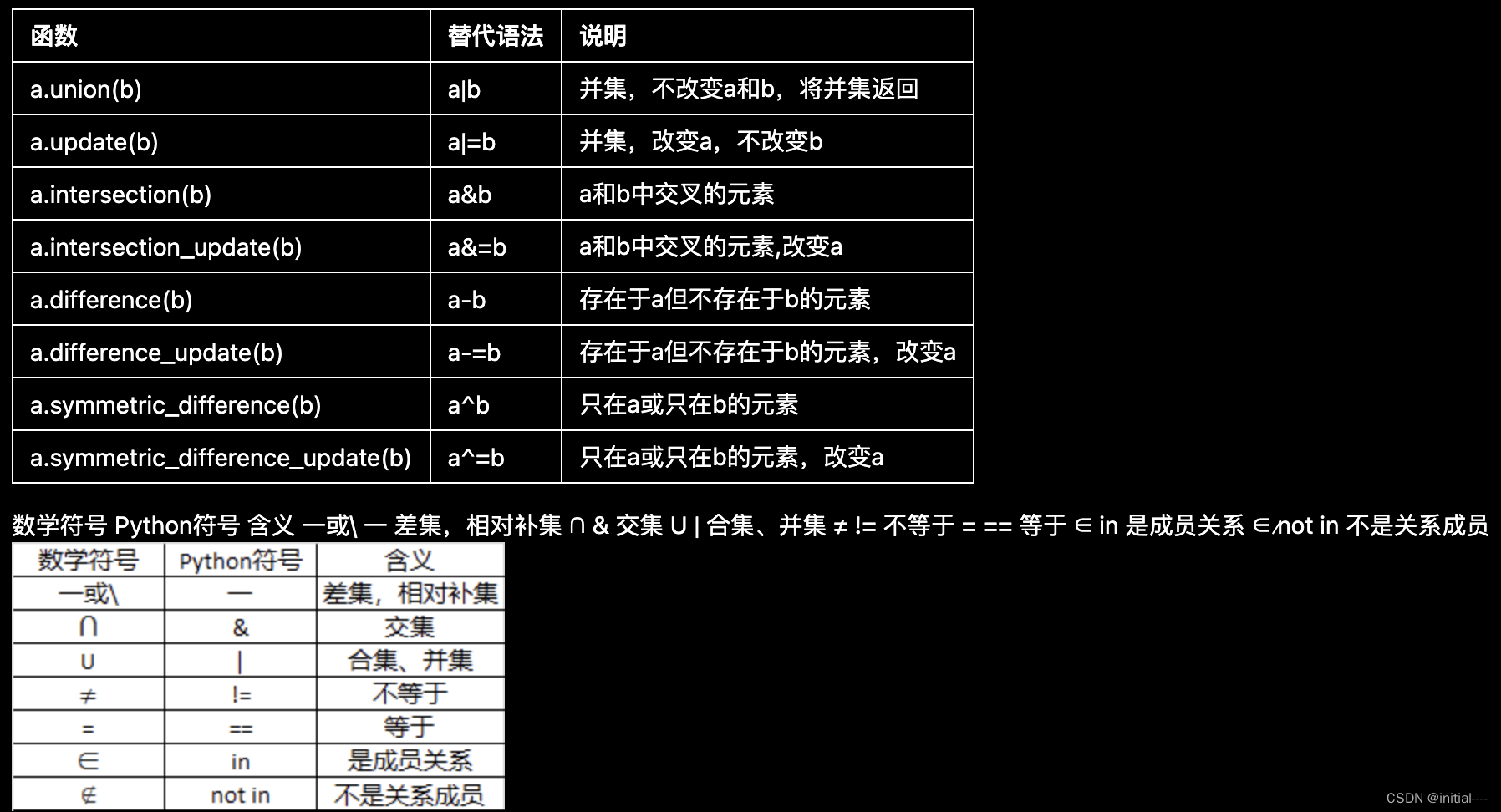
增加一个元素:set. 𝑎𝑑𝑑( )
合并两个集合:set.update( )
set.pop( ) 随机删除一个元素,不需要给参数值
set.remove 删除指定值
set.discard( ) 删除指定值
但是因为集合本身是无序的,不可以为集合创建索引或执行切片(slice)操作。
3、set和dict一样,只是没有value,相当于dict的key集合,由于dict的key是不重复的,且key是不可变对象因此set也有如下特性:
1)不重复 ,常用它过滤list、tuple等重复值。
2)元素为不可变对象。列表和字典是不能作为集合的元素的
x in set(true/flase)
x not in set (true/flase)
len(set)
7、函数
(1)自定义函数
def name (XXX):
body
return value
(2)lambda

T04.python关于Lambda的用法-CSDN博客
(3)遍历函数 map ()
遍历列表,即对序列中每个元素进行同样的操作,最终获取新的序列。
map(f, s)
将函数f 作用在序列S上。
(4)筛选函数 filter ()
对序列中的元素进行筛选,最终获取符合条件的元素
filter(f. s)
将条件函数f作用在序列S上,筛选出符合条件函数的元素
(5)累计函数 reduce ()
对序列内的所有元素进行累计操作。
reduce (f(x y),S)
将序列S中第一个元素和第二个元素用二元函数f(x,y)作用后的结果,与第三个元素继续作用,再将所得结果与第四个元素继续用x,y)作用,直到最后。
(6)函数 eval()
eval()的数将字符串当成有效的表达式来求值并返回计算结果,也就是实现列表、字典、元组与字符串之间的转化。
(7)range () arange( )函数
用于生成序列,多与for 循环搭配使用。其使用格式如下range0函数中的3个参数与切什中的参数一致,差异是 range0参数间使用逗号range(start, stop [,step])隔开。start 表示计数起始值,为0时可省略;stop表示计数结束值,但不包括 stop本身;step 表示步长,默认为1,不可以为0。其生成一个左闭右开的整数范围。
对于range0函数,有以下几个注意点:
(1)它的参数表示的是左闭右开的区间;
(2)它接收的参数必须是整数;


(8)内置函数对列表的操作

8、程序结构
1、顺序语句
2、分支语句

3、循环语句
4、try函数

try-except语句说明:
1. as 子句是用于绑定错误对象的变量,可以省略
2. except 子句可以有一个或多个,但至少要有一个.
一般的需要写清楚需捕获异常的类型,见上面的常见错误异常链接,
定制什么类型异常,能捕获相应的异常,但是没有指定的异常的话还是会报错的。
不过有一个万能异常:Exception
3. else子句最多只能有一个,也可以省略不写.
else子句的语句将在此try语句没有发生异常时被执行
4. finally子句最多只能有一个,也可以省略不写.
finally子句的语句在任何情况下都会被执行
二、NumPy与Pandas
1、NumPy的基本使用方法
1、数组创建
(1)zeros():创建一个矩阵
内部元素均为0,第一个参数提供维度,第二个参数提供类型。
(2)ones():创建一个矩阵
内部元素均为1,第一个参数提供维度,第二个参数提供类型。
(3)empty():创建一个矩阵
内部是无意义的数值,第一个参数提供维度第二个参数提供型。
(4)eye():创建一个对角矩阵
第一个参数提供矩阵规模,对于第二个参数而言,如果为0则对
角线全为“1”,大于0则右上方第K条对角线全为“1”,小于0则左下方第K条对角线全为“1”,
第三个参数提供类型。
(5)full():
full((m,n),c)可以生成一个m×n的元素全为c的矩阵。
(6)random.random():
random.random((m,n))生成一个m×n的元素为0~1之间随机数的矩阵。
(7)random.randint():
numpy.random.randint(low, high=None, size=None, dtype='l')
函数的作用是,返回一个随机整型数,范围从低(包括)到高(不包括),即[low, high)。如果没有写参数high的值,则返回[0,low)的值。
(8)random.rand():
random.rand(d0,d1,…,dn)
函数根据给定维度生成[0,1)之间的数据,其中,dn表示每个维度的元素个数。
(9)random.randn():
random.randn(d0,d1,…,dn)
函数返回一个或一组样本,具有标准正态分布,其中,dn表示每个维度的元素个数。





2、 数组索引和切片
3、 数组运算
数组运算实质上是数组对应位置的元素进行运算,常见的是加、减、乘、除、开方等运算。


2、 pandas数据结构
1、Series
Series是一种类似于一维数组的对象,它由一维数组以及一组与之相关的数据标签(即索引)组成,仅由一组数据即可产生最简单的Series。
Series的字符串表现形式为:
索引在左边,值在右边。如果没有为数据指定索引,就会自动创建一个0到N-1(N为数据的长度)的整数型索引。可以通过Series的values和index属性获取其数组表现形式和索引对象。



2、DataFrame
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame既有行索引也有列索引,它可以被看作由Series组成的字典(公用同一个索引)。跟其他类似的数据结构相比,DataFrame中面向行和面向列的操作基本是平衡的。其实,DataFrame中的数据是以一个或多个二维块存放的(而不是列表、字典或者别的一维数据结构)


3、索引对象
pandas的索引(Index)对象负责管理轴标签和轴名称等。构建Series或DataFrame时,所用到的任何数组或其他序列的标签都会被转换成一个Index对象。 Index对象是不可修改的,Series和DataFrame中的索引都是Index对象。
3、基本功能
1、 重新索引
2、 丢弃指定轴上的项
3、 索引、选取和过滤
4、 算术运算
5、 DataFrame和Series之间的运算
6 、函数应用和映射
7 、排序和排名
8、分组
9 、shape函数
10、 info()函数
11 、cut()函数
三、正则表达式
学习目标:
- 基本规则
- Match, compile , findallo, rearcho
- 字符串的替换和修改
- 格式化输出
正则表达式(Regular Expression),又称正规表示式、规则表达式、常规表示法等,在代 码中常简写为 regex、regexp 或 RE,是计算机科学的一个概念。在很多文本编辑器里,正则 表达式通常被用来检索、替换那些匹配某个模式的文本。
正则表达式对于 Python 来说并不是独有的。
Python 中正则表达式的模块通常叫做“re”, 利用“import re”来引入,它是一种用来匹配字符串的强有力武器。
作用
1. 判断匹配
> re.match() 从字符串起始位置开始匹配,如果不在起始配置匹配,re.match(r'正则表达式',‘字符串’) 函数返回None.
2. 切分字符串
> re.split(r'正则表达式’,‘字符串’)# 切分结果为列表
3. 分组
> 正则表达式还能提取字串。用()表示出要提取的字串,即分组(Group)
m=re.match('^(0[0-9]|1[0-9]|2[0-9]\:[0-5][0-9]:[0-5][0-9]$','19:05:30').groups()
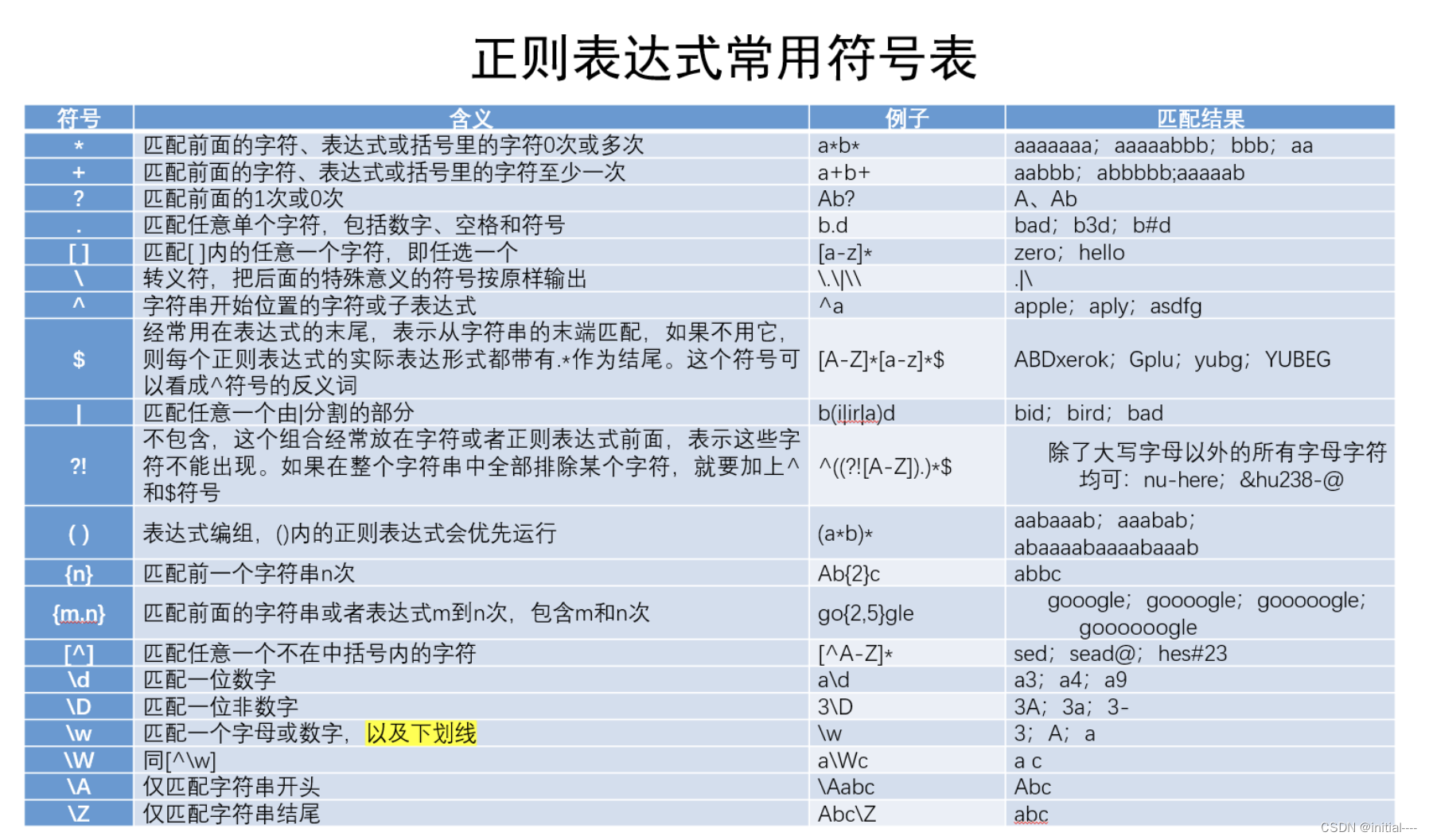
1、基本规则
注:
1、\s 是一个特殊序列,它匹配任何空白字符,包括空格、制表符、换行符、回车符等。
2、0到1是? 大于0是* 大于1是+
助记:
https://blog.csdn.net/m0_74161592/article/details/140027909?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22140027909%22%2C%22source%22%3A%22m0_74161592%22%7D![]() https://blog.csdn.net/m0_74161592/article/details/140027909?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22140027909%22%2C%22source%22%3A%22m0_74161592%22%7D
https://blog.csdn.net/m0_74161592/article/details/140027909?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22140027909%22%2C%22source%22%3A%22m0_74161592%22%7D
☆☆常见特殊表达式:



2、正则函数
tips:
1、match()函数判断是否匹配:
如果匹配成功,返回一个match对象,否则返回None。
(1)re.match()匹配
re.match(pattern, string)


1、切分字符串
(1)str.split(正则表达式)
(2)re.split(正则表达式,str)
2、分组Group
提取子串的强大功能:
如果正则表达式中定义了组,就可以在match对象上用group()方法提取出子串。注意到group(0)是原始字符串,group(1)、group(2)……表示第1、2……个子串。

(2)re.compile( )
re.compile(pattern, flags=0)
re.compile()函数编译正则表达式模式,返回一个对象。可以把常用的正则表达式编译成正则表
达式对象,方便后续调用及提高效率。
(3)re.findall( )☆
re.findall(pattern,string,flags=0)
调用re.findall()函数时可以非常简单地得到一个所有匹配模式的列表,而不是得到match的对象。

(4)re.srearch( )
re.search()函数对整个字符串进行搜索匹配,返回第一个匹配的字符串的match对象。

然而re.search()函数会在它查找到一个匹配项之后停止继续查找,因此在示例字符串中re.search()函数查找'dog'只找到其首次出现的位置。

3、字符串的替换和修改
sub (rule , replace , target [,count] )
subn(rule , replace , target [,count] )
第一个参数是正则规则,第二个参数是将要被替换的字符串,第三个参数是目标字符串,第四个参数是被替换的次数。
这两个函数的唯一区别是返回值。sub返回一个被替换的字符串,subn返回一个元组,第一个元素是被替换的字符串,第二个元素是一个数字,表明产生了多少次替换。
4、格式化输出
1、%符号进行格式化输出
引号内的%为格式化的开始,类似于占位符,其后s表示占位处要补充的是字符型,紧跟在引号之后的%为需要填充的内容。使用这种方式进行字符串格式化时,要求被格式化的内容和格式字符之间必须一一对应。用%进行格式化时:%d表示数值(取整)占位,%f表示浮点型占位。
2、使用format()函数进行格式化
除了%字符串格式化方法之外,推荐使用format()函数进行格式化,该方法非常灵活,不仅可以使用位置进行格式化,还支持使用关键参数进行格式化。Python中format()函数用于字符串的格式化。
3、f方法格式化
在普通字符串前添加f或F前缀,其效果类似于%方式或者format()。
四、数据处理与数据分析
1、数据处理
数据预处理的主要任务包括:1、数据清洗。 2、数据集成。 3 、数据变换。4、数据规约。
(1)数据清洗
数据清洗就是处理缺失数据以及清除无意义的数据,如:1、删除原始数据集中的无关数据,2、重复数据,3、平滑噪声数据,4、处理缺失值,5、异常值。
【1】重复值的处理
Python中的Pandas模块对重复数据去重步骤如下:
- 利用DataFrame中的duplicated( )函数返回一个布尔型的Series,显示是否有重复行,没有重复行显示为False,有重复行则从重复的第二条记录起,重复的均显示为True。
- 利用DataFrame中的drop_duplicates( )函数,返回一个移除了重复行的DataFrame。
- 使用df[df.列名.duplicated( )]显示重复值的行。
【2】缺失值处理
1)、处理缺失值的方法可分为三类:
1、删除记录,2、数据插补,3、不处理。
其中常用的数据插补方法见下表:

2)、缺失值的处理包括两个步骤;
1、缺失数据的识别,2、缺失值处理
(1)缺失数据的识别。
Pandas使用浮点值NaN表示浮点和非浮点数组里的缺失数据,并使用.isnull()和.notnull()函
数来判断缺失情况。
(2)缺失数据的处理。
对于缺失数据的处理有数据补齐、删除对应行、不处理等方法。
①dropna():对数据结构中有值为空的行进行删除。(删除数据中空值所对应的行)
②df.fillna():用其他数值填充NaN。
③df.fillna(method='pad'):用前一个数据值替代NaN。
④df.fillna(method='bfill') :用后一个数据值替代NaN。
⑤df.fillna(df.mean()):用平均数或者其他描述性统计量来代替NaN,使用均值来填补空数据。
⑥df.fillna(df.mean()['开始列名':'终止列名'] ) 起止连续的多列进行均值填充。
⑦df.fillna({'列名1':值1,'列名2':值2}):可以传入一个字典,对不同的列填充不同的值
⑧strip():清除字符型数据左右(首尾)指定的字符,默认为空格,中
间的不清除。
【3】异常值处理
异常值处理方法:
1、删除含有异常值的记录 。2、视为缺失值。3、平均值修正 。4、不处理。

(2)数据集成
1. 数据合并
2. 数据抽取
3. 数据拆分
(3)数据变换
1】、数据变换:主要是对数据进行规范化的操作,将数据转换成“适当的”格式,以适用于挖掘任务及算法的需要。
1. 数据标准化
2. 数据离散化
3. 数据泛化
4. 属性构造
2】、常见基本数据变换操作:
5. 简单函数变换
6. 轴向旋转
7. 分组与聚合
8、哑变量处理
9、函数映射转换(行、列、元素)
(4)数据规约
2、数据标准化
3、数据分析
五、作业复盘
1、

#1、接收来自键盘的输入,并做好省份字典,并将省份的代码全部提取出来做成变量keys
i = input("pls your ID:")
prov = {11: "北京", 12: "天津", 13: "河北", 14: "山西",15: "内蒙古",21: "辽宁", 22: "吉林", 23: "黑龙江",31: "上海", 32: "江苏", 33: "浙江", 34: "安徽", 35: "福建", 36: "江西", 37: "山东", 41: "河南", 42: "湖北", 43: "湖南", 44: "广东", 45: "广西", 46: "海南",50: "重庆", 51: "四川", 52: "贵州", 53: "云南", 54: "西藏",61: "陕西", 62: "甘肃", 63: "青海", 64: "宁夏", 65: "新疆", 71: "台湾", 81: "香港", 82: "澳门",91: "国外"}
keys = tuple(prov.keys())
#2、提取省份代码字符,并看看提取的省份代码是否在全部的省份代码变量keys中
sf = int(i[:2])
sf in keys
#3、输出省份名称
prov[sf]2、
from random import random
data =[[random() for j in range(5)] for i in range(3)]
data这段代码生成了一个3行5列的二维列表,列表中的每个元素都是一个[0.0, 1.0)之间的随机浮点数。

3、
a= list((x for x in range(10) if x % 3 == 0 for i in range(3)))
print(a)[0, 0, 0, 3, 3, 3, 6, 6, 6, 9, 9, 9]
4、
print (1 and 9, 1 or 9, 0 and 9, 0 or 9)
print ( 1 and 9 or 0 , 0 or 1 and 9 )
print ( 0 and 9 or 8)and 运算符要求两边的所有条件都为真(True)时,结果才为真;而 or 运算符只要任一边的条件为真,结果就为真。