Spark和PySpark的介绍

PySpark的相关设置
安装PySpark库
pip install pyspark
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark
构建PySpark执行环境入口对象
# 导包
from pyspark import SparkConf, SparkContext
# 创建SparkConf类对象
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
"""
上面这句等价于:
conf = SparkConf()
conf.setMaster("local[*]")
conf.setAppName("test_spark_app")
"""
# 基于SparkConf类对象创建SparkContext类对象
sc = SparkContext(conf=conf)
# 打印pyspark的运行版本
print(sc.version)
# 停止SparkContext类对象的运行(停止pyspark程序)
sc.stop()PySpark的编程模型
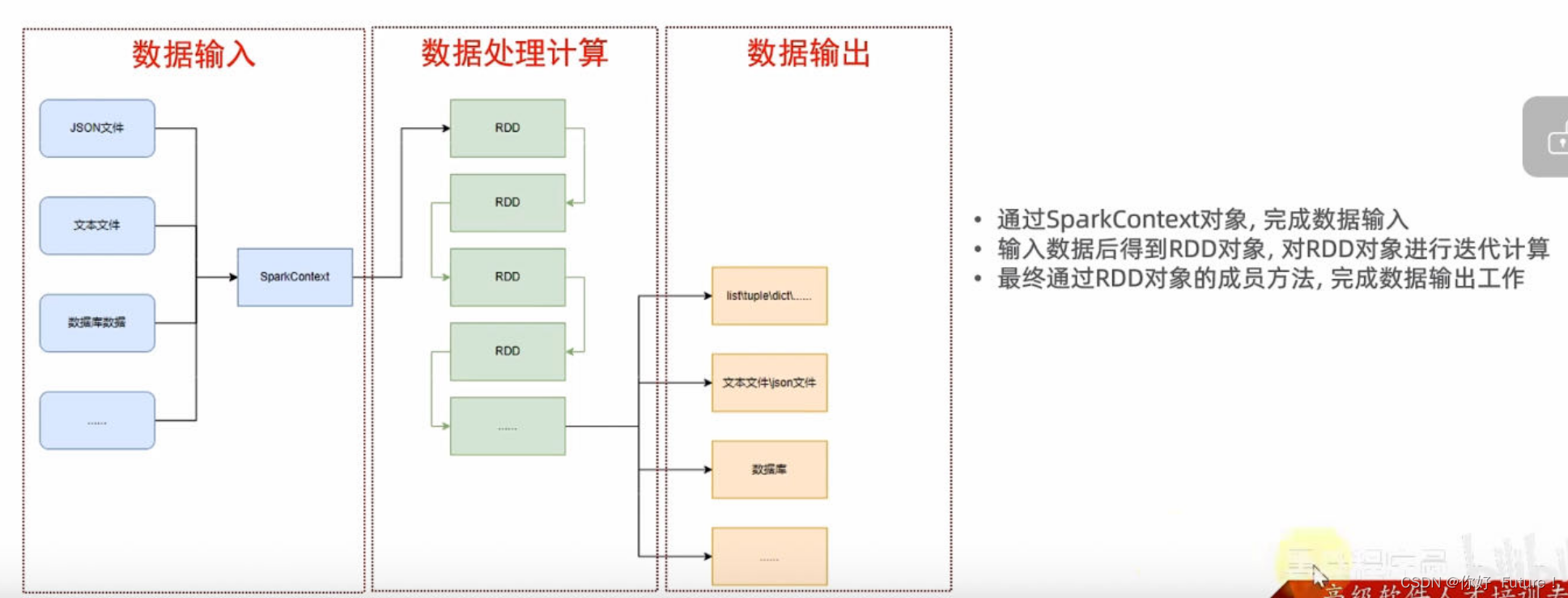
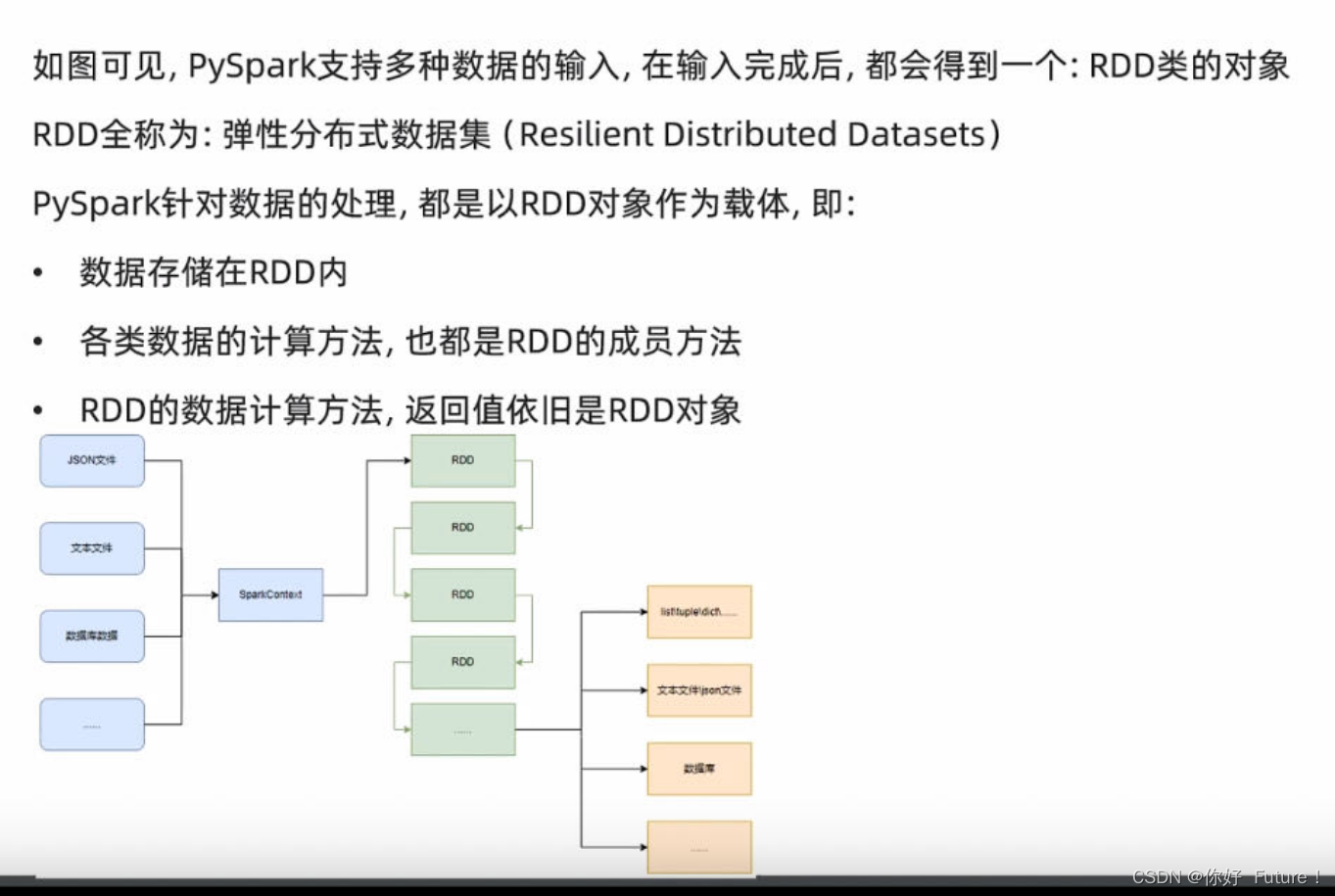
RDD对象
将容器转化为RDD对象

from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
sc = SparkContext(conf=conf)
rdd1 = sc.parallelize([1,2,3,4,5])
rdd2 = sc.parallelize("12345")
rdd3 = sc.parallelize((1,2,3,4,5))
rdd4 = sc.parallelize({1,2,3,4,5})
rdd5 = sc.parallelize({"name":1,"age":2})
print(rdd1.collect())
print(rdd2.collect())
print(rdd3.collect())
print(rdd4.collect())
print(rdd5.collect())
[1, 2, 3, 4, 5]
['1', '2', '3', '4', '5']
[1, 2, 3, 4, 5]
[1, 2, 3, 4, 5]
['name', 'age']读取文件转RDD对象
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
sc = SparkContext(conf=conf)
rdd = sc.textFile("C:/Users/18757/Desktop/pythontext/bill.txt") # 文件路径
print(rdd.collect())
['周杰轮,2022-01-01,100000,消费,正式', '周杰轮,2022-01-02,300000,消费,正式', '周杰轮,2022-01-03,100000,消费,测试', '林俊节,2022-01-01,300000,消费,正式', '林俊节,2022-01-02,100000,消费,正式', '林俊节,2022-01-03,100000,消费,测试', '林俊节,2022-01-02,100000,消费,正式']
RDD操作
map算子

from pyspark import SparkConf, SparkContext
# 导入python解释器的位置
import os
os.environ['PYSPARK_PYTHON'] = r"D:\dev\python\python3.10.4\python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1,2,3,4,5])
# 通过map方法将全部数据都乘以10
def func(data):
return data * 10
rdd2 = rdd.map(func).map(lambda x:x+1)
print(rdd2.collect())
[11, 21, 31, 41, 51]
flatmap算子

from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON'] = r"D:\dev\python\python3.10.4\python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
sc = SparkContext(conf=conf)
rdd = sc.parallelize(["itheima itcast 666", "itheima itheima itcast", "python itheima"])
def func(data):
return data.split(" ")
# 需求:将RDD数据里面的一个个单词提取出来
rdd2 = rdd.map(func)
print(rdd2.collect())
[['itheima', 'itcast', '666'], ['itheima', 'itheima', 'itcast'], ['python', 'itheima']]from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON'] = r"D:\dev\python\python3.10.4\python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
sc = SparkContext(conf=conf)
rdd = sc.parallelize(["itheima itcast 666", "itheima itheima itcast", "python itheima"])
def func(data):
return data.split(" ")
# 需求:将RDD数据里面的一个个单词提取出来
rdd2 = rdd.flatMap(func)
print(rdd2.collect())
['itheima', 'itcast', '666', 'itheima', 'itheima', 'itcast', 'python', 'itheima']reduceByKey算子
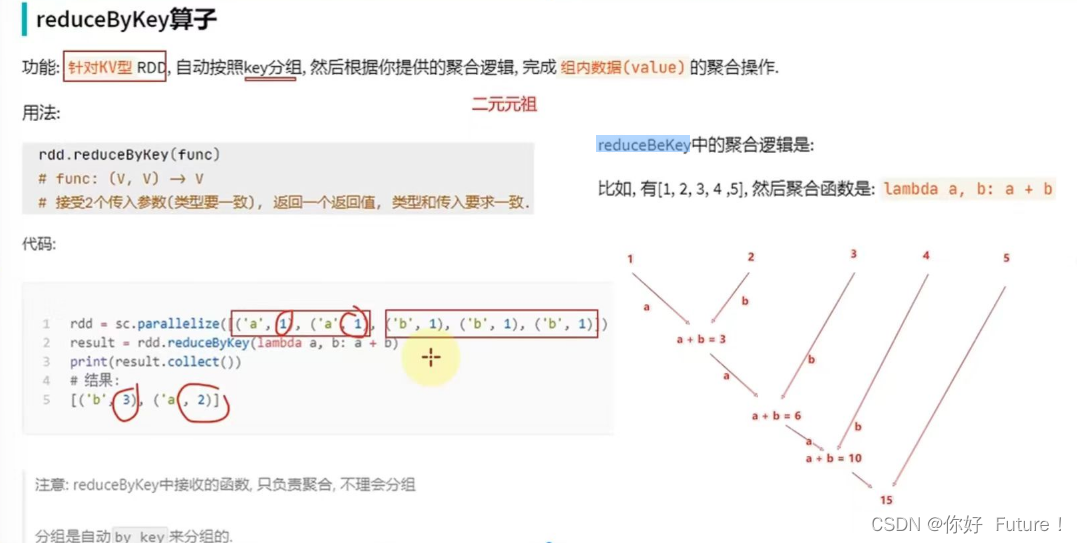
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON'] = r"D:\dev\python\python3.10.4\python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("text_spark_app")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([('a',1), ('a',1), ('b',1), ('b',1), ('b',1)])
result = rdd.reduceByKey(lambda a, b: a + b)
print(result.collect())[('b', 3), ('a', 2)]练习案例1
将以下文档中,各个单词出现的次数统计出来
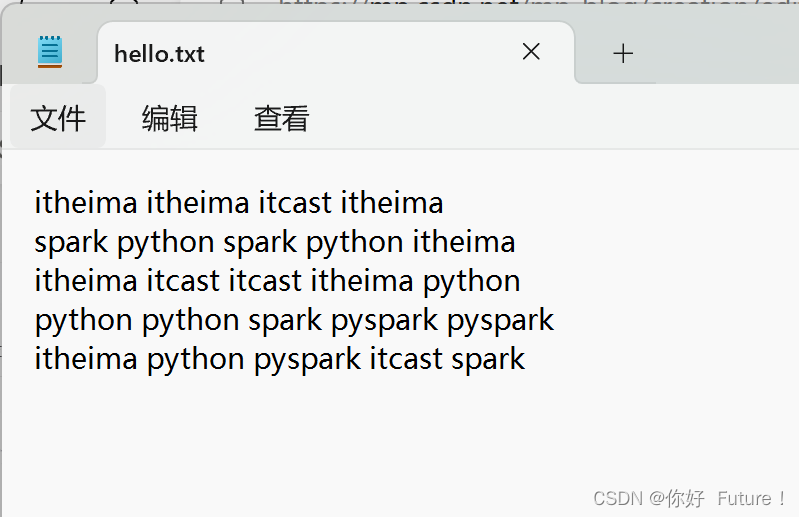
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON'] = r"D:\dev\python\python3.10.4\python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("text_spark_app")
sc = SparkContext(conf=conf)
rdd = sc.textFile(r"C:\Users\18757\Desktop\pythontext\3\hello.txt")
word_rdd = rdd.flatMap(lambda x:x.split(" "))
word_with_one_rdd = word_rdd.map(lambda x:(x,1))
result = word_with_one_rdd.reduceByKey(lambda a, b: a + b)
print(result.collect())[('itcast', 4), ('python', 6), ('itheima', 7), ('spark', 4), ('pyspark', 3)]Filter

from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON'] = r"D:\dev\python\python3.10.4\python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("text_spark_app")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 2, 3, 4, 5])
result = rdd.filter(lambda x:x % 2 == 0)
print(result.collect())[2, 4]distinct算子

from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON'] = r"D:\dev\python\python3.10.4\python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("text_spark_app")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 1, 3, 3, 5, 5, 6, 6, 6])
rdd = rdd.distinct()
print(rdd.collect())[1, 3, 5, 6]sortBy方法
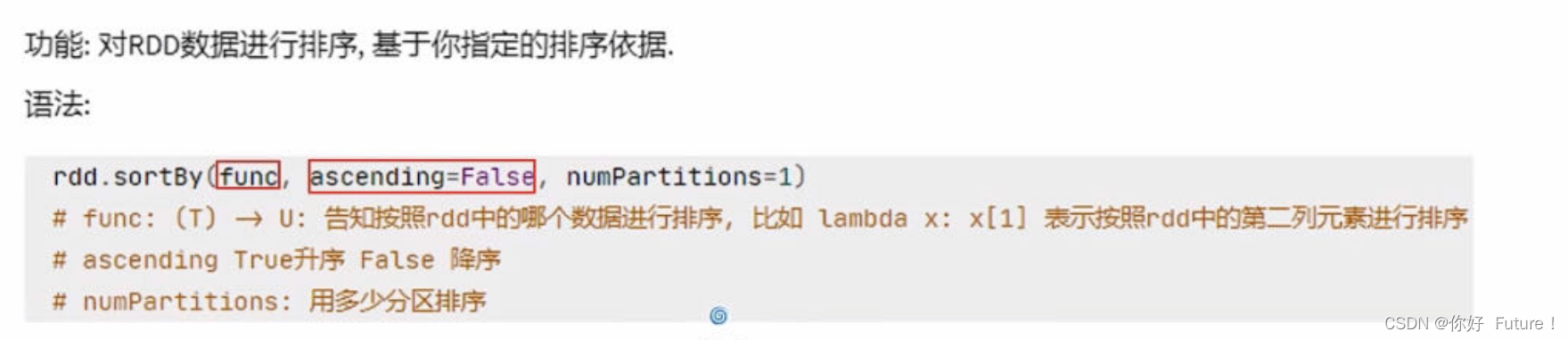
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON'] = r"D:\dev\python\python3.10.4\python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("text_spark_app")
sc = SparkContext(conf=conf)
rdd = sc.textFile(r"C:\Users\18757\Desktop\pythontext\3\hello.txt")
word_rdd = rdd.flatMap(lambda x:x.split(" "))
word_with_one_rdd = word_rdd.map(lambda x:(x,1))
result = word_with_one_rdd.reduceByKey(lambda a, b: a + b).sortBy(lambda x:x[1],False,1)
print(result.collect())
综合案例

from pyspark import SparkConf,SparkContext
import json
import os
os.environ['PYSPARK_PYTHON'] = r"D:\dev\python\python3.10.4\python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("text_spark_app")
sc = SparkContext(conf=conf)
# 1 求各个城市销售额,并根据销售额排名
# 1.1 读取文件得到RDDD
file_rdd = sc.textFile(r"C:\Users\18757\Desktop\pythontext\3\orders.txt")
# 1.2 取出一个个JSON字符串
JSON_rdd = file_rdd.flatMap(lambda x:x.split("|"))
# ['{"id":1,"timestamp":"2019-05-08T01:03.00Z","category":"平板电脑","areaName":"北京","money":"1450"}', '{"id":2,"timestamp":"2019-05-08T01:01.00Z","category":"手机","areaName":"北京","money":"1450"}', '{"id":3,"timestamp":"2019-05-08T01:03.00Z","category":"手机","areaName":"北京","money":"8412"}', '{"id":4,"timestamp":"2019-05-08T05:01.00Z","category":"电脑","areaName":"上海","money":"1513"}', '{"id":5,"timestamp":"2019-05-08T01:03.00Z","category":"家电","areaName":"北京","money":"1550"}', '{"id":6,"timestamp":"2019-05-08T01:01.00Z","category":"电脑","areaName":"杭州","money":"1550"}', '{"id":7,"timestamp":"2019-05-08T01:03.00Z","category":"电脑","areaName":"北京","money":"5611"}', '{"id":8,"timestamp":"2019-05-08T03:01.00Z","category":"家电","areaName":"北京","money":"4410"}', '{"id":9,"timestamp":"2019-05-08T01:03.00Z","category":"家具","areaName":"郑州","money":"1120"}', '{"id":10,"timestamp":"2019-05-08T01:01.00Z","category":"家具","areaName":"北京","money":"6661"}', '{"id":11,"timestamp":"2019-05-08T05:03.00Z","category":"家具","areaName":"杭州","money":"1230"}', '{"id":12,"timestamp":"2019-05-08T01:01.00Z","category":"书籍","areaName":"北京","money":"5550"}', '{"id":13,"timestamp":"2019-05-08T01:03.00Z","category":"书籍","areaName":"北京","money":"5550"}', '{"id":14,"timestamp":"2019-05-08T01:01.00Z","category":"电脑","areaName":"北京","money":"1261"}', '{"id":15,"timestamp":"2019-05-08T03:03.00Z","category":"电脑","areaName":"杭州","money":"6660"}', '{"id":16,"timestamp":"2019-05-08T01:01.00Z","category":"电脑","areaName":"天津","money":"6660"}', '{"id":17,"timestamp":"2019-05-08T01:03.00Z","category":"书籍","areaName":"北京","money":"9000"}', '{"id":18,"timestamp":"2019-05-08T05:01.00Z","category":"书籍","areaName":"北京","money":"1230"}', '{"id":19,"timestamp":"2019-05-08T01:03.00Z","category":"电脑","areaName":"杭州","money":"5551"}', '{"id":20,"timestamp":"2019-05-08T01:01.00Z","category":"电脑","areaName":"北京","money":"2450"}', '{"id":21,"timestamp":"2019-05-08T01:03.00Z","category":"食品","areaName":"北京","money":"5520"}', '{"id":22,"timestamp":"2019-05-08T01:01.00Z","category":"食品","areaName":"北京","money":"6650"}', '{"id":23,"timestamp":"2019-05-08T01:03.00Z","category":"服饰","areaName":"杭州","money":"1240"}', '{"id":24,"timestamp":"2019-05-08T01:01.00Z","category":"食品","areaName":"天津","money":"5600"}', '{"id":25,"timestamp":"2019-05-08T01:03.00Z","category":"食品","areaName":"北京","money":"7801"}', '{"id":26,"timestamp":"2019-05-08T01:01.00Z","category":"服饰","areaName":"北京","money":"9000"}', '{"id":27,"timestamp":"2019-05-08T01:03.00Z","category":"服饰","areaName":"杭州","money":"5600"}', '{"id":28,"timestamp":"2019-05-08T01:01.00Z","category":"食品","areaName":"北京","money":"8000"}', '{"id":29,"timestamp":"2019-05-08T02:03.00Z","category":"服饰","areaName":"杭州","money":"7000"}']
# 1.3 将一个个JSON字符串转换为字典
file_dict = JSON_rdd.map(lambda x:json.loads(x))
# [{'id': 1, 'timestamp': '2019-05-08T01:03.00Z', 'category': '平板电脑', 'areaName': '北京', 'money': '1450'}, {'id': 2, 'timestamp': '2019-05-08T01:01.00Z', 'category': '手机', 'areaName': '北京', 'money': '1450'}, {'id': 3, 'timestamp': '2019-05-08T01:03.00Z', 'category': '手机', 'areaName': '北京', 'money': '8412'}, {'id': 4, 'timestamp': '2019-05-08T05:01.00Z', 'category': '电脑', 'areaName': '上海', 'money': '1513'}, {'id': 5, 'timestamp': '2019-05-08T01:03.00Z', 'category': '家电', 'areaName': '北京', 'money': '1550'}, {'id': 6, 'timestamp': '2019-05-08T01:01.00Z', 'category': '电脑', 'areaName': '杭州', 'money': '1550'}, {'id': 7, 'timestamp': '2019-05-08T01:03.00Z', 'category': '电脑', 'areaName': '北京', 'money': '5611'}, {'id': 8, 'timestamp': '2019-05-08T03:01.00Z', 'category': '家电', 'areaName': '北京', 'money': '4410'}, {'id': 9, 'timestamp': '2019-05-08T01:03.00Z', 'category': '家具', 'areaName': '郑州', 'money': '1120'}, {'id': 10, 'timestamp': '2019-05-08T01:01.00Z', 'category': '家具', 'areaName': '北京', 'money': '6661'}, {'id': 11, 'timestamp': '2019-05-08T05:03.00Z', 'category': '家具', 'areaName': '杭州', 'money': '1230'}, {'id': 12, 'timestamp': '2019-05-08T01:01.00Z', 'category': '书籍', 'areaName': '北京', 'money': '5550'}, {'id': 13, 'timestamp': '2019-05-08T01:03.00Z', 'category': '书籍', 'areaName': '北京', 'money': '5550'}, {'id': 14, 'timestamp': '2019-05-08T01:01.00Z', 'category': '电脑', 'areaName': '北京', 'money': '1261'}, {'id': 15, 'timestamp': '2019-05-08T03:03.00Z', 'category': '电脑', 'areaName': '杭州', 'money': '6660'}, {'id': 16, 'timestamp': '2019-05-08T01:01.00Z', 'category': '电脑', 'areaName': '天津', 'money': '6660'}, {'id': 17, 'timestamp': '2019-05-08T01:03.00Z', 'category': '书籍', 'areaName': '北京', 'money': '9000'}, {'id': 18, 'timestamp': '2019-05-08T05:01.00Z', 'category': '书籍', 'areaName': '北京', 'money': '1230'}, {'id': 19, 'timestamp': '2019-05-08T01:03.00Z', 'category': '电脑', 'areaName': '杭州', 'money': '5551'}, {'id': 20, 'timestamp': '2019-05-08T01:01.00Z', 'category': '电脑', 'areaName': '北京', 'money': '2450'}, {'id': 21, 'timestamp': '2019-05-08T01:03.00Z', 'category': '食品', 'areaName': '北京', 'money': '5520'}, {'id': 22, 'timestamp': '2019-05-08T01:01.00Z', 'category': '食品', 'areaName': '北京', 'money': '6650'}, {'id': 23, 'timestamp': '2019-05-08T01:03.00Z', 'category': '服饰', 'areaName': '杭州', 'money': '1240'}, {'id': 24, 'timestamp': '2019-05-08T01:01.00Z', 'category': '食品', 'areaName': '天津', 'money': '5600'}, {'id': 25, 'timestamp': '2019-05-08T01:03.00Z', 'category': '食品', 'areaName': '北京', 'money': '7801'}, {'id': 26, 'timestamp': '2019-05-08T01:01.00Z', 'category': '服饰', 'areaName': '北京', 'money': '9000'}, {'id': 27, 'timestamp': '2019-05-08T01:03.00Z', 'category': '服饰', 'areaName': '杭州', 'money': '5600'}, {'id': 28, 'timestamp': '2019-05-08T01:01.00Z', 'category': '食品', 'areaName': '北京', 'money': '8000'}, {'id': 29, 'timestamp': '2019-05-08T02:03.00Z', 'category': '服饰', 'areaName': '杭州', 'money': '7000'}]
# 1.4 取出城市和销售额
city_with_money = file_dict.map(lambda x: (x["areaName"],int(x["money"])))
# [('北京', 1450), ('北京', 1450), ('北京', 8412), ('上海', 1513), ('北京', 1550), ('杭州', 1550), ('北京', 5611), ('北京', 4410), ('郑州', 1120), ('北京', 6661), ('杭州', 1230), ('北京', 5550), ('北京', 5550), ('北京', 1261), ('杭州', 6660), ('天津', 6660), ('北京', 9000), ('北京', 1230), ('杭州', 5551), ('北京', 2450), ('北京', 5520), ('北京', 6650), ('杭州', 1240), ('天津', 5600), ('北京', 7801), ('北京', 9000), ('杭州', 5600), ('北京', 8000), ('杭州', 7000)]
# 1.5 分组聚合各个城市销售额,并根据销售额排名
city_with_money_result = city_with_money.reduceByKey(lambda a, b: a + b)
# [('杭州', 28831), ('天津', 12260), ('北京', 91556), ('上海', 1513), ('郑州', 1120)]
city_with_money_result = city_with_money_result.sortBy(lambda x:x[1],False,1)
print(city_with_money_result.collect())
# 2 全部城市,有哪些商品类别在售卖
city_with_category = file_dict.map(lambda x: (x["areaName"],x["category"]) )
# [('北京', '平板电脑'), ('北京', '手机'), ('北京', '手机'), ('上海', '电脑'), ('北京', '家电'), ('杭州', '电脑'), ('北京', '电脑'), ('北京', '家电'), ('郑州', '家具'), ('北京', '家具'), ('杭州', '家具'), ('北京', '书籍'), ('北京', '书籍'), ('北京', '电脑'), ('杭州', '电脑'), ('天津', '电脑'), ('北京', '书籍'), ('北京', '书籍'), ('杭州', '电脑'), ('北京', '电脑'), ('北京', '食品'), ('北京', '食品'), ('杭州', '服饰'), ('天津', '食品'), ('北京', '食品'), ('北京', '服饰'), ('杭州', '服饰'), ('北京', '食品'), ('杭州', '服饰')]
city_with_category = city_with_category.distinct(1)
def func(a, b):
result = a + "、"
result += b
return result
city_with_category_result = city_with_category.reduceByKey(func)
# [('北京', '平板电脑、手机、家电、电脑、家具、书籍、食品、服饰'), ('上海', '电脑'), ('杭州', '电脑、家具、服饰'), ('郑州', '家具'), ('天津', '电脑、食品')]
print(city_with_category_result.collect())
[('北京', 91556), ('杭州', 28831), ('天津', 12260), ('上海', 1513), ('郑州', 1120)]
[('北京', '平板电脑、手机、家电、电脑、家具、书籍、食品、服饰'), ('上海', '电脑'), ('杭州', '电脑、家具、服饰'), ('郑州', '家具'), ('天津', '电脑、食品')]







![Leetcode[反转链表]](https://img-blog.csdnimg.cn/img_convert/acd306aae60fe83bf7fd1f7692ce7234.jpeg)