文章目录
- 1 fullmatch
- 2 match
- 3 search
- 4 findall
- 5 finditer
- 6 split
- 7 sub
- 8 compile
本篇博客主要讲解正则表达式相关的函数,均不涉及复杂的正则表达式语法。如需了解正则表达式语法,请参考下面的文章:
Python正则表达式语法详解
1 fullmatch
Python 中的 re.fullmatch() 函数用于检查输入字符串是否完全匹配给定的正则表达式模式。它接受两个参数:第一个是正则表达式模式,第二个是要与该模式匹配的字符串。如果匹配成功,它会返回一个匹配对象,如果匹配失败,则返回 None。
import re
text = "Hello, world!"
pattern = re.compile("Hello, world!")
match = pattern.fullmatch(text)
if match:
print(match)
else:
print("整个字符串与模式不匹配。")
此处完全匹配,所以函数的输出是:

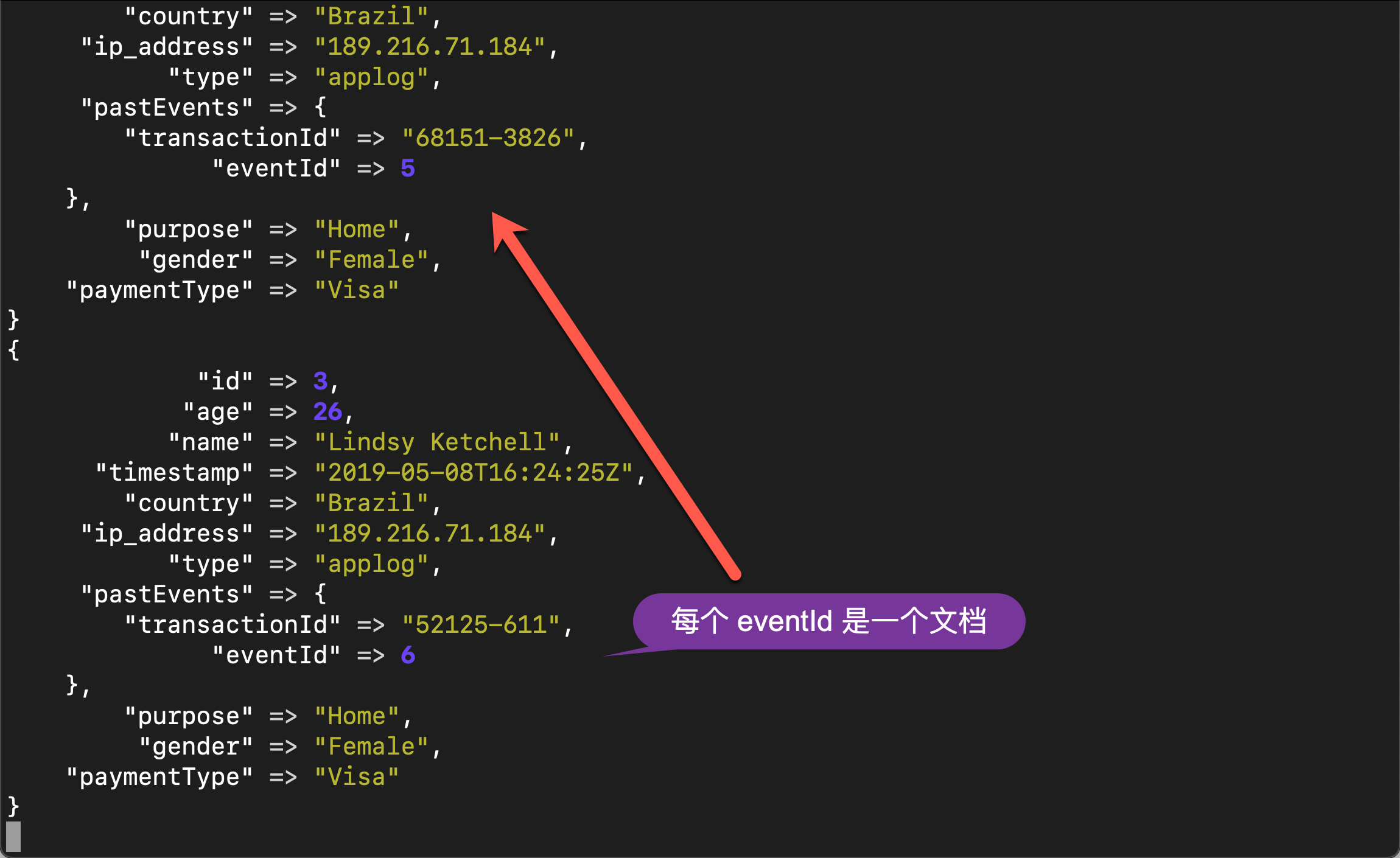
此处span表示的是匹配上的字符串的开始位置与结束位置,match表示匹配上的内容,后面其他函数的输出含义与此相同。
2 match
Python 中的 re.match() 函数用于判断字符串的起始位置是否与正则表达式匹配,它接受两个参数:第一个是正则表达式模式,第二个是要与该模式匹配的字符串。如果匹配成功,它会返回一个匹配对象,如果匹配失败,则返回 None。
import re
text = "Hello, world!"
pattern = re.compile("Hello")
match = pattern.match(text)
if match:
print(match)
else:
print("匹配失败")

3 search
扫描整个字符串,判断有无匹配的子串,如果匹配成功,将返回第一个匹配的字符串对象。可以看出:上面三种函数的匹配规则,其严格程度是依次下降的。
import re
text = "Hello, world! How are you?"
pattern = "world"
match = re.search(pattern, text)
if match:
print(match)
else:
print("匹配失败")
这段函数的输出结果为:

4 findall
findall与research的严格程度类似,均是寻找字符串中与正则表达式匹配的字符串片段。不同的是findall将会找到所有的匹配结果,并且将所有的匹配结果组成一个列表进行返回。
import re
text = "Hello, world! How are you? world"
pattern = "world"
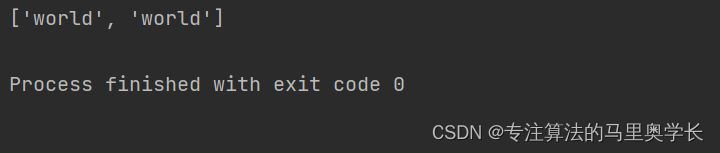
match = re.findall(pattern, text)
if match:
print(match)
else:
print("匹配失败")
5 finditer
finditeryufindall都是寻找字符串中与正则表达式匹配的字符串片段的所有结果。与findall()函数不同的是,finditer()函数返回的是一个迭代器,并可以获取更多的信息,如匹配字符串的起始和终止位置。
import re
text = "Hello, world! How are you? world"
pattern = "world"
match = re.finditer(pattern, text)
if match:
print(match)
else:
print("匹配失败")
此时的输出是:<callable_iterator object at 0x00000207930EDDC0>
如果我们对这个迭代器进行遍历
print([i for i in match])

就可以看到这个迭代器的详细信息,其每次都会返回一个object,与search等函数的返回格式类似。
6 split
re.split()是python中正则表达式库re中的一个函数,用于在字符串中按照指定的规则分割字符串。该函数接受两个参数:第一个是要分割的字符串,第二个是分割规则(正则表达式)。它返回一个字符串列表,每个字符串代表一个分割后的部分。
这个函数python内置的split函数很像,re.split()与split()的主要区别在于分割规则的不同。split()仅支持固定的分隔符,而re.split()支持使用正则表达式作为分割规则。这意味着,re.split()可以根据复杂的分割规则(例如以数字开头)来分割字符串,而split()不能。因此,在需要使用正则表达式进行分割时,应使用re.split()。
代码举例:
re_str = r'\d+'
str1 = 'qwer1tyui345osdfghj99876kl'
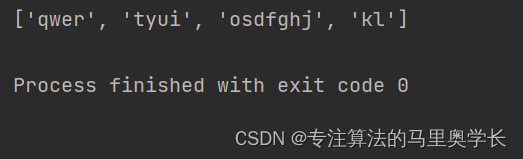
result = re.split(re_str,str1)
print(result)
这里\d+是一个正则表达式,代表的是一个或多个数字。分割的结果为:
7 sub
re.sub()是python中正则表达式库re中的一个函数,用于在字符串中替换与指定正则表达式匹配的部分。该函数接受三个参数:第一个是替换规则(正则表达式),第二个是要替换的字符串,第三个是要被替换的字符串。它返回一个替换后的字符串。
代码举例:
import re
re_str = r'\d+'
str1 = 'qwer1tyui345osdfghj99876kl'
str1 = re.sub(re_str, '一二三',str1) # 用'一二三'替换str1中所有匹配re_str的子串
print(str1)

8 compile
re.compile()是python中正则表达式库re中的一个函数,用于编译正则表达式,以便多次使用。编译后的正则表达式可以作为参数传递给其他正则表达式函数(例如re.search(),re.match(),re.findall()等)。
代码示例:
import re
re_pattern = re.compile(r'\d+')
str1 = 'qwer1tyui345osdfghj99876kl'
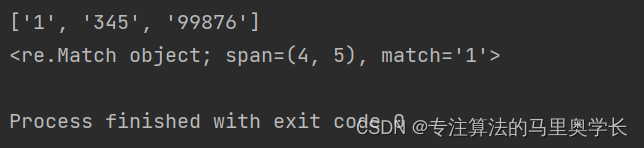
result1 = re_pattern.findall(str1)
result2 = re_pattern.search(str1)
print(result1)
print(result2)
这段代码的输出为
可以看到,当需要重复使用正则方法时,这个函数还是很有用的。