读AI新生:破解人机共存密码笔记15辅助博弈
news2026/2/14 0:02:16
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1875547.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
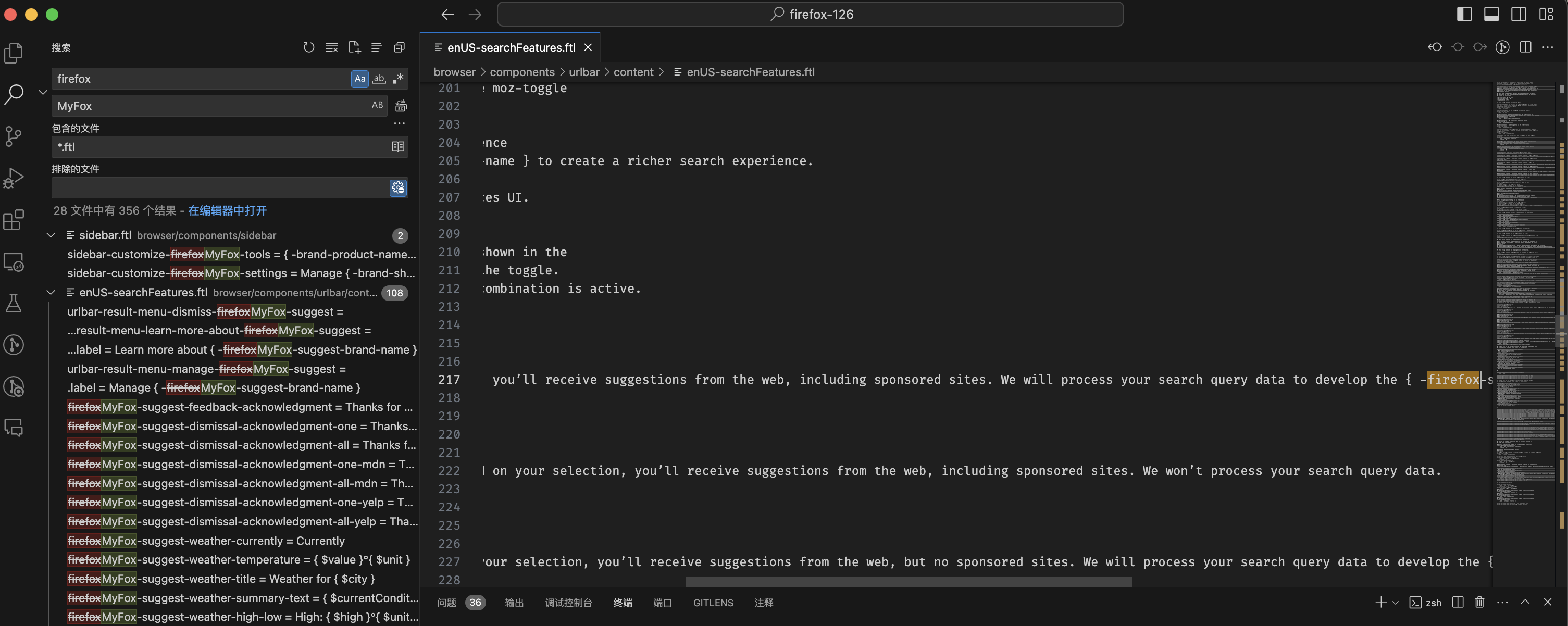
Firefox 编译指南2024 Windows10- 定制化您的Firefox(四)
1. 引言
定制化您的Firefox浏览器是一个充满乐趣且富有成就感的过程。在2024年,Mozilla进一步增强了Firefox的灵活性和可定制性,使得开发者和高级用户能够更深入地改造和优化浏览器以满足个人需求。从界面的微调到功能的增强,甚至是核心代码…

Elasticsearch初识与 index+mapping+document 基操
前言 在21年多少有使用过es 当时是在艺术赛道的一个教育公司,大概流程就是 将mysql中的各种课程数据通过logstash汇总到es 然后提供rest接口出去。由于在职时间较短(很不幸赶上了教育双减),所以对es的了解其实仅仅是些皮毛,当然elk在我的任职…
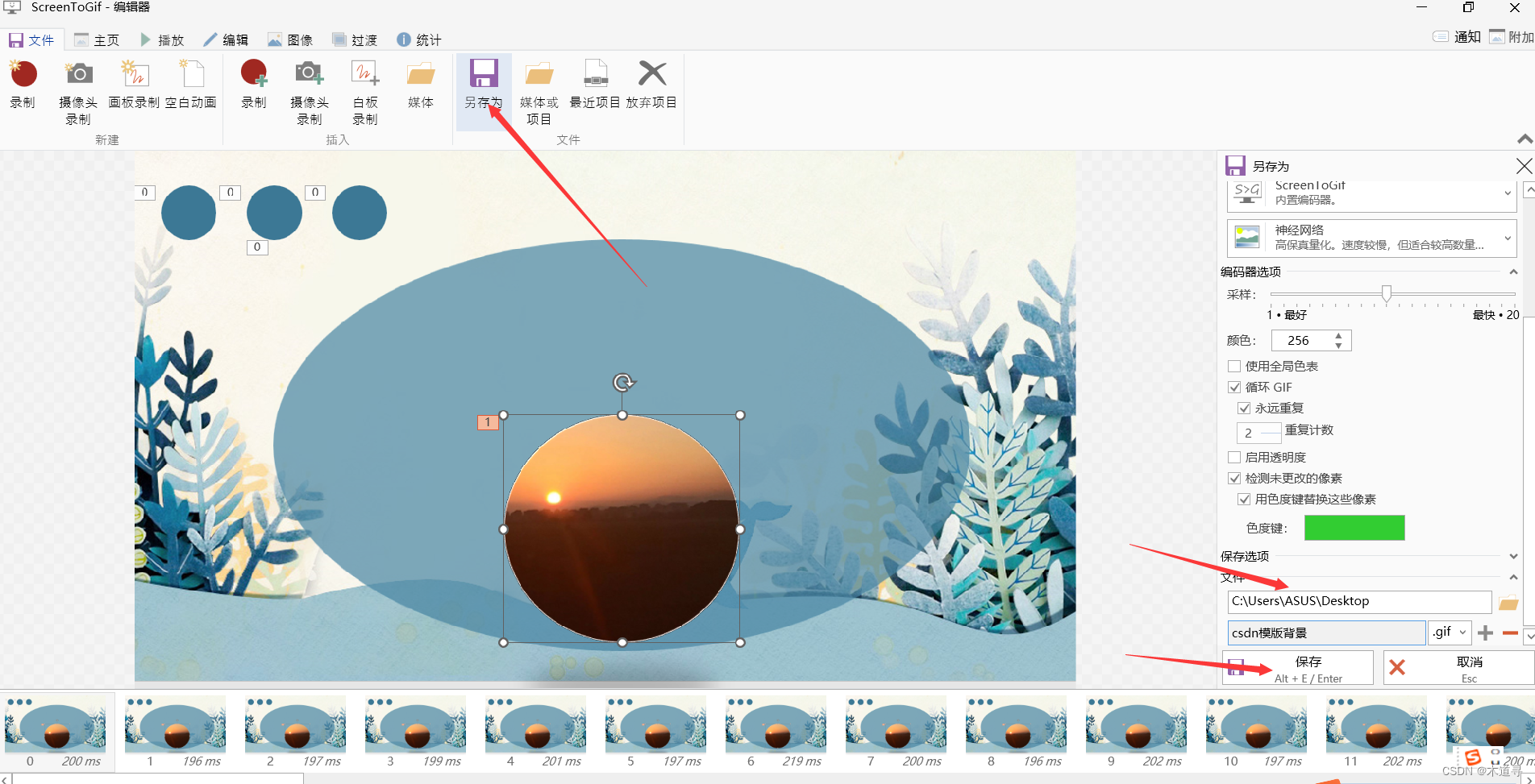
推荐一款免费的GIF编辑器——【ScreenToGif编辑器】
读者大大们好呀!!!☀️☀️☀️ 👀期待大大的关注哦❗️❗️❗️ 🚀欢迎收看我的主页文章➡️木道寻的主页 文章目录 🔥前言🚀素材准备🚀逐帧制作🚀保存图片⭐️⭐️⭐️总结 &#…

使用Jetpack Compose实现具有多选功能的图片网格
使用Jetpack Compose实现具有多选功能的图片网格
在现代应用中,多选功能是一项常见且重要的需求。例如,Google Photos允许用户轻松选择多个照片进行分享、添加到相册或删除。在本文中,我们将展示如何使用Jetpack Compose实现类似的多选行为,最终效果如下:
主要步骤 实现…

深度学习笔记: 最详尽解释R 平方 (R²)
欢迎收藏Star我的Machine Learning Blog:https://github.com/purepisces/Wenqing-Machine_Learning_Blog。如果收藏star, 有问题可以随时与我交流, 谢谢大家!
理解 R 平方 (R)
什么是相关性 R?
相关性测量两个定量变量(例如,重量和尺寸&a…

iOS shouldRecognizeSimultaneouslyWithGestureRecognizer 调用机制探索
shouldRecognizeSimultaneouslyWithGestureRecognizer 经常会看到,但是一直没有弄清楚其中的原理和运行机制,今天专门研究下 其运行规律
我们准备三个视图,如下,红色的是绿色视图的父视图,绿色视图 是蓝色视图的父视图…
layui在表格中嵌入上传按钮,并修改上传进度条
当需要在表格中添加上传文件按钮,并不需要弹出填写表单的框的时候,需要在layui中,用按钮触发文件选择 有一点需要说明的是,layui定义table并不是在定义的标签中渲染,而是在紧接着的标签中渲染,所以要获取实…

Unity WebGL项目问题记录
一、资源优化
可通过转换工具配套提供的资源优化工具,将游戏内纹理资源针对webgl导出做优化。
工具入口: 工具介绍
Texture 搜索规则介绍 已开启MipMap: 搜索已开启了MipMap的纹理。
NPOT: 搜索非POT图片。
isReadable: 搜索已开启readable纹理。
…

为什么有的手机卡没有语音功能呢?
大家好,今天这篇文章为大家介绍一下,无通话功能的手机卡, 在网上申请过手机卡的朋友应该都知道,现在有这么一种手机卡,虽然是运营商推出的正规号卡,但是却屏蔽了通话功能,你知道这是为什么吗&am…

第六节:如何解决@ComponentScan只能扫描当前包及子包(自学Spring boot 3.x的第一天)
大家好,我是网创有方,继上节咱们使用了Component和ComponentScan的方法实现了获取IOC容器中的Bean,但是存在一个问题,就是必须把AppConfig和要扫描的bean类放在同一个目录下,这样就导致了AppConfig类和bean类在同一个目…


Dahlia Hart: Stylized Casual Character(休闲角色模型)
此包包含两个发型和两个服装,每个都有多种颜色选择。每个发型都适合与物理资源一起使用,并包含各种表情和音素混合形状。
下载:Unity资源商店链接资源下载链接 效果图:
自适应IT互联网营销企业网站pbootcms模板
模板介绍
一款蓝色自适应IT互联网营销企业网站pbootcms模板,该模板采用响应式设计,可自适应手机端,适合一切网络技术公司、互联网IT行业,源码下载,为您提供了便捷哦。
模板截图 源码下载
自适应IT互联网营销企业网站…

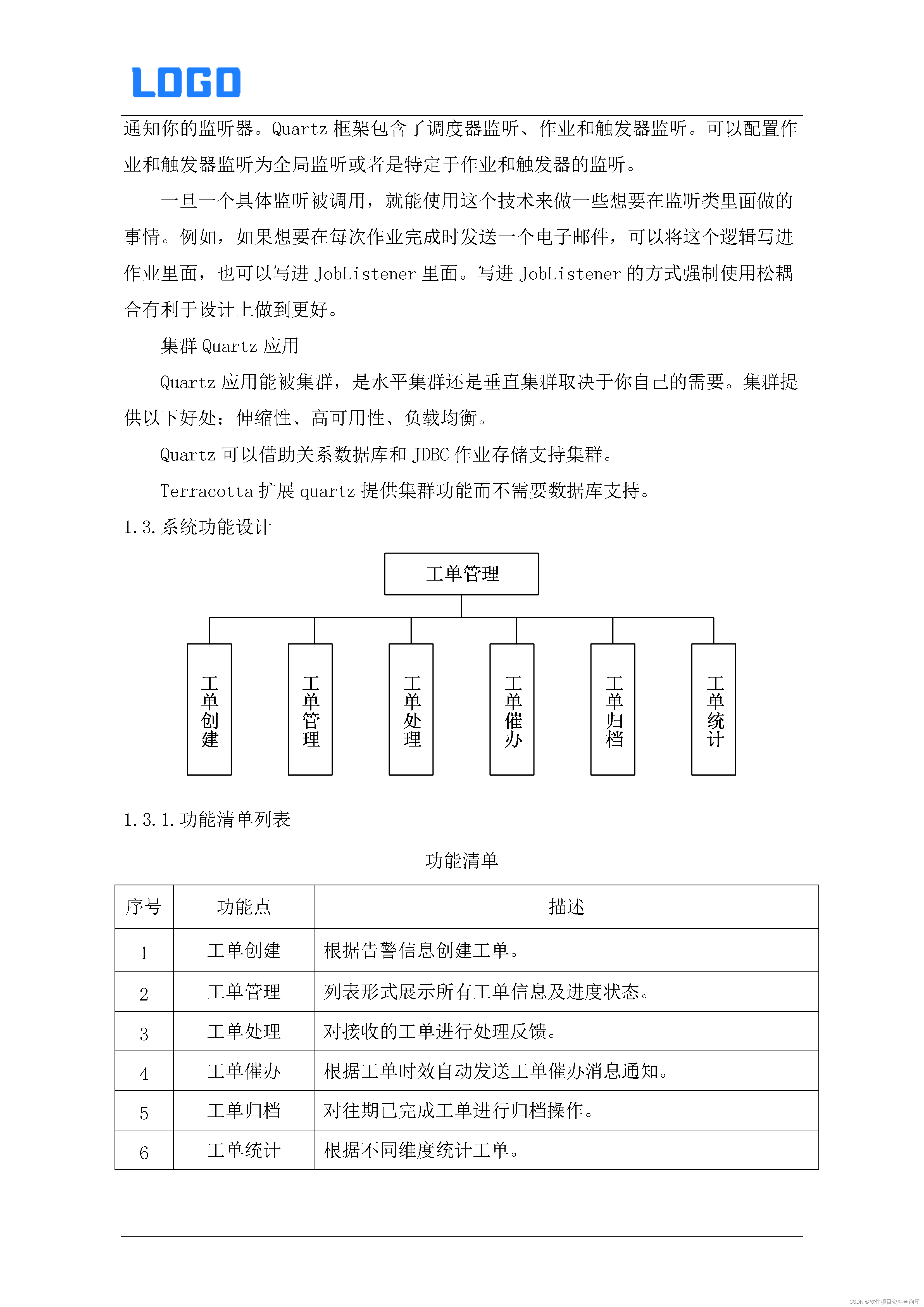
【建设方案】工单系统建设方案(Word原件)
工单管理系统解决方案 1、工单创建:根据告警信息创建工单。 2、工单管理:列表形式展示所有工单信息及进度状态。 3、工单处理:对接收的工单进行处理反馈。 4、工单催办:根据工单时效自动发送工单催办消息通知。 5、工单归档&#…
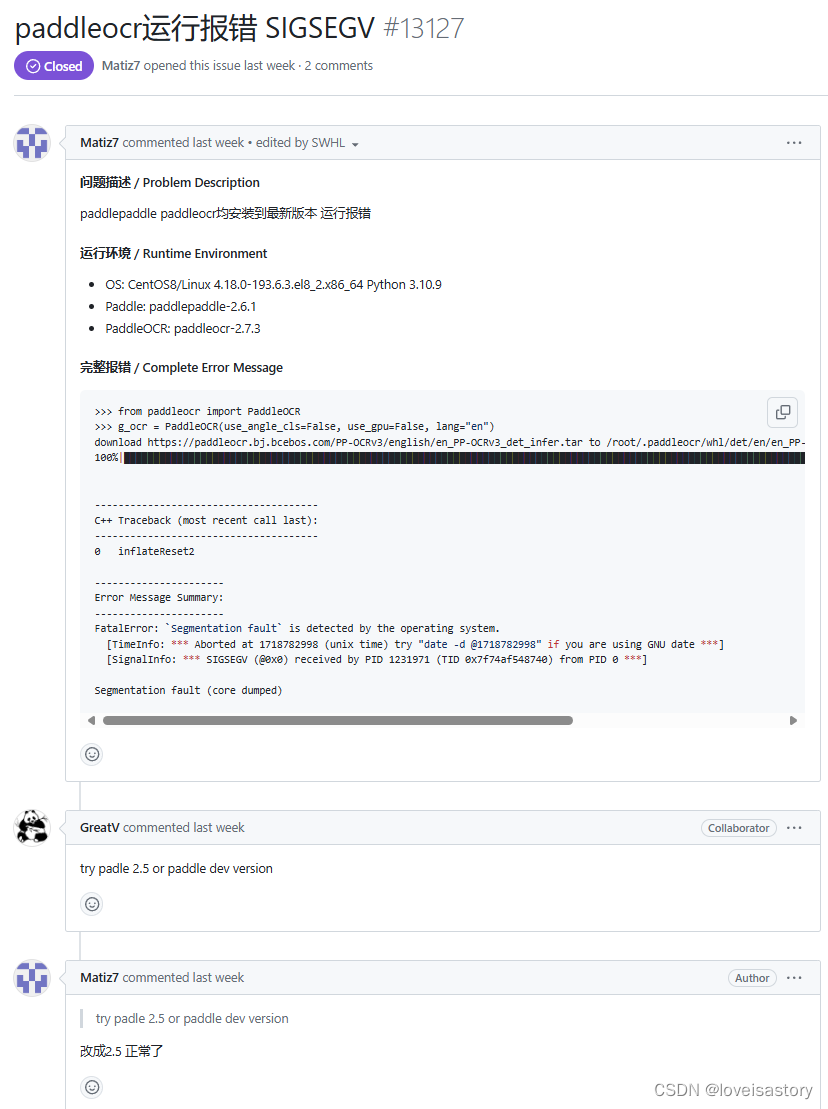
鲲鹏arm服务器部署paddleOCR
1. 部署环境信息查看
1.1 操作系统
$ cat /etc/os-release
PRETTY_NAME"UnionTech OS Server 20"
NAME"UnionTech OS Server 20"
VERSION_ID"20"
VERSION"20"
ID"uos"
PLATFORM_ID"platform:uel20"
HOME_URL&q…

数据结构与算法笔记:高级篇 - 搜索:如何用 A* 搜索算法实现游戏中的寻路功能?
概述
魔兽世界、仙剑奇侠传这类 MMRPG 游戏,不知道你玩过没有?在这些游戏中,有一个非常重要的功能,那就是任务角色自动寻路。当任务处于游戏地图中的某个位置时,我们用鼠标点击另外一个相对较远的位置,任务…
Java学习 - 布隆过滤器
前置需求
需求 已经有50亿个电话号码,现在给出10万个电话号码,如何快速准确地判断这些电话号码是否已经存在? 参考方案 通过数据库查询:比如MySQL,性能不行,速度太慢将数据先放进内存:50亿*8字…

用pycharm进行python爬虫的步骤
使用 pycharm 进行 python 爬虫的步骤:下载并安装 pycharm。创建一个新项目。安装 requests 和 beautifulsoup 库。编写爬虫脚本,包括获取页面内容、解析 html 和提取数据的代码。运行爬虫脚本。保存和处理提取到的数据。 用 PyCharm 进行 Python 爬虫的…

机器人控制系列教程之Simulink中模型搭建(1)
机器人模型获取
接上期:机器人控制系列教程之控制理论概述,文中详细讲解了如何通过Solidworks软件导出URDF格式的文件。文末提到了若需要将其导入到Simulink中可在命令行中输入smimport(urdf/S_Robot_urdf.urdf),MATLAB将自动打开Simulink以…