前言
在21年多少有使用过es 当时是在艺术赛道的一个教育公司,大概流程就是 将mysql中的各种课程数据通过logstash汇总到es 然后提供rest接口出去。由于在职时间较短(很不幸赶上了教育双减),所以对es的了解其实仅仅是些皮毛,当然elk在我的任职经历中基本上每家都有使用,不得不说elk真的是查询日志的好工具。不管是elk 还是当年的课程数据亦或者其他使用到es的场景,我们可以发现他们都有一个共同点就是数据量很大,并且搜索需求很高也比较复杂,而这类场景在实际开发中是很常见的,因此掌握Elasticsearch这门技术就成了程序员必不可少的一项技能,一言概之:学好es,可以让我们在面对 大数据+高频+复杂 的搜索场景时显得游刃有余。而不是让你的数据沉睡在数据库中!
一些说明: - Elasticsearch 版本: 7.17.5 , kibana版本:7.17.5 - 由于 Elasticsearch 这个词比较长为了方便我们在日常中一般都称为es,当然本文也不例外 - Elasticsearch 和 kibana 的安装不在本文,因为之前我写过一篇安装文章,见:Centos7安装Elasticsearch和Kibana 记录(无坑版)
核心概念
ps: 为了便于理解,我们会拿es中的索引(index),类型(type),文档(doc),字段(filed)去类比mysql(但其实本质上不那么合理,只能说我们初学es时为了方便而进行的一种思维映射,在深入理解es后,最好能抛弃此类比概念或者知晓其不一样的地方),由于es6开始,逐步移除了type的概念,所以类比时会有两个版本,如下是未移出type时的类比关系图: | ES |mysql || | --- | --- |---| | Index | Database|库 | Type | Table |表 | Document | Row |行 | Filed | Field |字段
移除type后,我更喜欢这么类比:
| ES |mysql || | --- | --- |---| | Index | Table |表 | Document | Row |行 | Filed | Field |字段
索引(index):
索引是一类相似文档的集合,当然了他也是es存储数据的地方。(这里我们要区别与mysql中的索引叫法虽一样但是作用却大不相同)。 - 如果是7.x以及之前 的ES,则可以类比为
关系型数据库中的 库 (database)。 - 如果是7.x以及之后 的ES,我愿将其类比为关系型数据库中的 表 (table)
类型(type)【7.x及之后版本将逐步废弃】:
从6.0开始官方将逐步移除type这个属性,计划如下: - type在6.x中只能有一个,可自定义。 - type在7.x中只能有一个,且只能是_doc。 - type在8.x(未来版本)彻底取消,API会大变,以前的
INDEX -> TYPE -> DOC的方式会变成INDEX -> DOC,如我们新增个文档时,将会从POST indextest/_doc/1变为POST indextest/1。以下是官方的说明:在7.x版本之前,type可以类比一个
关系型数据库的表(table)。但在ES 7.x以后,由于将逐步移除type这个概念,所以我们如果使用的是7.x版本的ES 那么无需关注此属性,也不再将其类比为表了,

文档(document):
Elasticsearch中的最小数据单元,一般以Json格式显示。一个document相当于关系型数据库中的一行(
row)数据。
字段(Field):
一条文档数据由一个或多个字段(Field)组成, 这里的字段类似mysql中表的字段(
filed)。当然es中字段也有类型的,下面是常用的字段类型: - 数值类型(包括: long、integer、short、byte、double、float) - text : 会分词,支持全文搜索 - keyword : 不会分词,将全部内容作为一个词条,不支持全文搜索。如:email、电话这些数据,作为一个整体进行匹配就可以,不需要分词处理。 - date : 日期类型 - boolean : 布尔类型 - 范围类型 : integerrange, floatrange, longrange, doublerange, date_range - 数组 []: 数组类型的json对象 - 对象 {}: 单个json对象
映射(mapping):
mapping定义了每个字段的类型、字段所使用的分词器等。相当于关系型数据库中的表结构定义
倒排索引:
关于倒排索引我们这里费点笔墨来说说他,因为他是es底层 lucene的非常重要的一个数据结构也是es搜索之快的一个重要原因。当然关于倒排索引里边的东西实在太多了,我们这里只是简单介绍,后续有时间的话写个更详细点的倒排索引文章。
ps: 倒排索引这个名字其实有点不恰当,从实现上来说的话其实叫它反向索引更加生动形象。但是为了方便理解我们在下文还是叫它倒排索引,只是你应该知道,他叫反向索引更合适。别着急,理解了他的工作机制,就知道为什么说叫它反向索引更合适了。
说倒排索引前,我们先看下与之相反的,正向索引是什么。
常规的索引(也就是正向索引)是从文档中找关键词:
文档——>关键词,但是这样检索有个很大的弊端就是需要将所有文档(即行)遍历一遍,比如你在mysql中的查询就是根据给定条件来找匹配的行记录,如下:小提示:(注意上边我们假设就是全表遍历,如果索引类型是全文索引 fulltext index,那么mysql其实也是使用了倒排),看下官方的说明:
这个知道就好。
倒排索引简易图
区别于正向索引,倒排索引是根据关键词找文档: 关键词——>文档。也就是说es会在内部维护一个 词条索引,每一个词条都 有一个包含它的文档列表 ,如下【简易图】所示: 
下边我们来简单看下创建倒排索引与搜索的过程。注意:真实的es内部实现远比我下边说的要复杂的多,我只是介绍点皮毛主要我们理解他的大概思路就行,细节不去扣,扣的话得上源码了现在还不是时候。
创建倒排索引,分为以下几步:
- 创建文档列表:首先对原始文档数据进行编号(DocID),形成一个文档列表
- 创建倒排索引列表:然后对文档中数据进行分词,得到词条并对词条进行编号,以词条创建倒排索引。然后记录下包含该词条的所有文档编号(及其频率和位置信息)
第一步: :创建文档列表 | 文档编号 | 文档内容 | | :-: | --- | | 1| 你今天吃什么 | | 2| 什么都不想吃昨天吃多了|
第二步: 分词 & 创建倒排索引列表(注:下边分词可能不严谨不过没关系主要是体会这个意思)
step1:对 "你今天吃什么" 分词,得到如下词条:
| 词条: |你|今天|吃|什么| | :-: |:-:|:-:|:-:|:-:| | 下标: | 1 |2|3|4|
step2:对 "什么都不想吃昨天吃多了" 分词,得到如下结果:
|词条:|什么|都|不想|吃|昨天|吃|多了 |:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-: | 下标: | 1 |2|3|4|5|6|7|
step3:根据分词后得到的词条,创建 倒排索引列表
(注意:实际es内部会分为三个文件分别是 词典文件(Term Dictionary)、频率文件(frequencies)、位置文件 (positions)。其中词典文件不仅保存有每个关键词,还保留了指向频率文件和位置文件的指针,通过指针可以找到该关键字的频率信息(通过频率信息可以计算匹配度也就是分值)和位置信息)如下图所示:
| 词条 | 文档编号 | 出现频率 | 出现位置 | | :-: | :-: | :-: | --- | | 你 | 1 | 1|1| | 今天 | 1,2 |1|1| | 吃 | 1,2|1,2|3,[4,6] 说明:文档1的第3个和文档2的第4、第6个位置| | 什么 | 1,2 |1,1|4,1| | 都 | 2 |1|2| | 不想 | 2 |1|3| | 昨天 | 2 |1|5| | 多了 | 2 |1|6|
搜索过程
当用户输入的搜索条件为 "吃" 这个词条时,大致搜索逻辑如下: 1. 首先对用户输入的数据进行分词,得到用户要搜索的所有词条(吃分词后的词条也是 吃)。 2. 然后拿着吃这个词条去倒排索引列表中进行匹配。找到这些词条就能找到包含这些词条的所有文档的编号以及频率&位置信息。命中的倒排索引就是这个: 找到包含他的文档有:文档1和文档2,以及频率信息(在文档1出现了1次在文档2出现了2次以及位置信息)和位置信息。 4. 最后返回命中的文档信息以及分值(默认会根据分值倒序),如下:
找到包含他的文档有:文档1和文档2,以及频率信息(在文档1出现了1次在文档2出现了2次以及位置信息)和位置信息。 4. 最后返回命中的文档信息以及分值(默认会根据分值倒序),如下:
当然这只是精简后的过程概要,真正的搜索过程还是很复杂的尤其是涉及到集群、分词方式等等,我们暂时先不展开,主要是体会一下倒排的大致工作原理。
ps:由于此时我们只是介绍es的基本功能,集群暂时还未涉及,所以先不讲集群相关的概念,到后边我们对es熟练了之后再讲解&搭建es集群.
下边我们好好说说es的语法,先学会用在去探究原理。
索引+映射+文档 (管理)
索引管理:index
我们都知道在使用mysql时,想要管理数据,第一步得先有个库以及表,而对于es来说管理数据首先得有个索引吧?不过在新建索引前,我们使用以下命令先来看下当前都有哪些索引:
查看索引
dsl GET /_cat/indices?v  可以看到除了 hzztest以及invertedindex这俩索引是我之前建的之外其他几个索引都是以.开头的,这类一般是系统默认的我们暂时不用管它,接下来我们看看如何管理索引。
可以看到除了 hzztest以及invertedindex这俩索引是我之前建的之外其他几个索引都是以.开头的,这类一般是系统默认的我们暂时不用管它,接下来我们看看如何管理索引。
创建索引
Elasticsearch使用PUT方式来实现索引的新增,你可以在创建索引的时候不添加任何参数,当然你可以添加附加一些配置信息,如下:  查询刚刚创建的索引:
查询刚刚创建的索引:  这里返回的很多个字段,我们列个表解释一下:
这里返回的很多个字段,我们列个表解释一下:
| 字段 | 解释 | | --- | --- | | aliases | 别名 | | mappings | 映射,也就是这个索引的定义,我们只创建了索引没有定义所以上边返回是空的 | | settings | 此索引的一些配置,具体见下边 | settings.index.routing | 路由设置,不指定的话es会默认将索引分片自动分配给内容层:Content tier ,这个分层机制其实可以理解成冷热机制此设计在很多数据库中都有涉及目的就是为了更快的查询到热数据,只不过es分的更细分了4层分别是:Content tier内容层,Hot tier热层,Warm tier 温层,Cold tier 冷层| | settings.index.creationdate | 此索引的创建时间 | | settings.index.numberofshards | 数据分片数,索引要做多少个分片,只能在创建索引时指定,后期无法修改 | | settings.index.numberofreplicas | 数据备份数,每个分片有多少个副本,后期可以动态修改 | | settings.index.uuid | 此索引的唯一id | | settings.index.providedname | 此索引的名称 |
索引是否存在
使用 HEAD 索引名称 可以查看该索引是否存在,如下: 
关闭&打开 索引
在某些场景下,我们可能需要禁掉某些索引的访问功能(读+写),但是又不想删除这个索引,那么此时关闭索引就是一种方式,如下: dsl POST indexstudy/_close  当然关闭后你可以随时打开,打开后就用可以继续读写索引里的数据了,打开方式如下:
当然关闭后你可以随时打开,打开后就用可以继续读写索引里的数据了,打开方式如下: dsl POST indexstudy/_open  当你暂不需要那些数据,但是也不想删除它们。关闭索引将变得比较有意义。关闭它们会比较稳妥,因为随时可以重新打开被关闭的索引来重新读写,而不是删除
当你暂不需要那些数据,但是也不想删除它们。关闭索引将变得比较有意义。关闭它们会比较稳妥,因为随时可以重新打开被关闭的索引来重新读写,而不是删除
删除索引
当然确定某些索引确实不用了那么就删除他吧 不然留着他还干啥: dsl DELETE indexstudy 
映射管理:mapping
映射(mapping)的创建是基于索引的,你必须要先创建索引才能创建映射,es中的映射相当于传统数据库中的表结构,数据存储的格式就是通过映射来规定的。值的注意的是:es会自动根据数据格式识别它的类型,当然在一些情况下你可能对es给你生成的mapping类型不放心或者和你的期望不一致,那么这时就应该手动给他指定映射(mapping)啦!
创建映射
可以在创建索引时指定映射,其中 mappings.properties 为固定结构,使用映射可定义字段的类型,我们刚开始也说了,可以把他类比理解为关系型数据库的ddl -> 表结构定义;
下边我创建索引并设置映射,即:给 username(姓名)设置为keyword类型 ,age(年龄)设置为integer, introduction(简介) 设置为text类型。 dsl PUT mappingstudy { "mappings": { "properties": { "username": { "type": "keyword" }, "age": { "type": "integer" }, "introduction": { "type": "text" } } } } 创建索引+设置映射 成功后再次查询索引信息可以看到我们对该索引设置的映射信息 
查看映射
查看映射很简单你可以直接查询此索引也可以指定就只查映射信息,这样更清爽些,如下: ```dsl //索引全部信息都会返回 GET mappingstudy
or
//只返回映射信息 更清爽一些 GET mappingstudy/_mapping ``` 
修改映射(不能直接修改,需使用reindex方式)
如果你想修改某个字段的属性比如你想将 username 字段的类型从 keyword 改为 text 那对不起,不能(像mysql那样)直接修改。如果是mysql的可能你一个sql就搞定了,如下: sql alter table mappingstudy modify column username text NOT NULL; 但是在es中想直接修改字段的类型,会毫不留情给你报个错:  那我们确实就是有这个需要呢?其实es也不是那么轴非不让你修改,而是提供了一种新的方式,即使用: reindex,步骤大致如下: 1. 先新建个空的,你的目标索引,并将其mapping设置为我们最新需要的 3. 将数据从旧的索引中迁移到新的索引使用 reindex并指定 目标索引名称和来源索引名称
那我们确实就是有这个需要呢?其实es也不是那么轴非不让你修改,而是提供了一种新的方式,即使用: reindex,步骤大致如下: 1. 先新建个空的,你的目标索引,并将其mapping设置为我们最新需要的 3. 将数据从旧的索引中迁移到新的索引使用 reindex并指定 目标索引名称和来源索引名称 dsl //新建目标索引 PUT mapping_update_target { "mappings": { "properties": { "username": { "type": "text" }, "age": { "type": "integer"}, "introduction": {"type": "text" } } } } //执行迁移 POST _reindex { "source": { "index": "mappingstudy" }, "dest": { "index": "mapping_update_target" } }  看下效果:可以看到新的索引的username字段已经变为text并且数据也迁移过来了。
看下效果:可以看到新的索引的username字段已经变为text并且数据也迁移过来了。  reindex更多参见官网:reindex
reindex更多参见官网:reindex
文档管理:document
首先有必要说一下POST和PUT,这俩和ES没什么关系,他们属于HTTP请求方式,在http1.1中 一共有9种(GET、POST、HEAD、OPTIONS、PUT、PATCH、DELETE、TRACE、CONNECT),日常开发我一般都是使用post和get一把撸,当然如果遵循rest 规范的话最好还是在不同的动作下使用不同的请求方式, 我日常put用的不多,但是为了全面我们还是要讲一下:
第一:POST不用加具体的id,它是作用在一个集合资源之上的(/uri),而PUT操作是作用在一个具体资源之上的(/uri/xxx)。
第二:POST与PUT都可以用于更新和新增操作,但是新增时POST是不用指定ID的,会自动分配;而PUT是需要指定ID的,也就是说PUT是具有幂等性的,无论你操作多少次结果都是一样的。而POST是操作一遍就新增一条,如果你多次POST 新增同一条数据那么es将会将原数据删除再新增
创建文档
我们上边早就说过文档可以类比关系型数据库的一行数据,所以创建文档其实就是新增一条数据(但是格式是json),也就是说可以理解为一个insert语句。 创建文档时可以手动指定文档的唯一id, 也可以不指定这样的话es会帮我们生成一个唯一的文档id。
小提示:一般不推荐手动指定文档id,因为会对ES插入性能造成影响。如果手动指定id,es为了保证id不冲突,会先查询一次文档库,如果不存在则进行插入,手动插入多了一次查询操作,性能会有损失。而es自动生成的id是一个不会重复的随机数,使用GUID算法,可以保证在分布式环境下,不同节点同一时间创建的 _id 一定是不冲突的
创建文档一共有好几种方式,如下介绍:
使用Index API (_doc)来创建文档
语法:POST 目标索引名称/_doc/  语法:
语法:POST 目标索引名称/_doc/文档id  语法:
语法:PUT 目标索引名称/_doc/文档id 
使用Create API (_create)来创建文档
PUT /目标索引名称/_create/文档id 
POST /目标索引名称/_create/文档id 
错误的创建文档 示范
使用 POST 目标索引名称/_create/ 则报错 ”Invalid type: expecting doc but got _create" 原因很明确:使用了错误的操作类型,说白了 你不能使用 POST create 不指定id 的方式创建文档,想不指定id创建文档, 请使用上边介绍过的:POST 目标索引名称/_doc/ 方式 
使用 PUT 目标索引名称/_create/ 则报错405,原因我们上边也说了PUT操作是作用于具体的资源之上的,不指定具体的资源id,那肯定是不行。报错已经很明显了不指定资源id 让我们使用POST方式 
在上边不管哪种方式创建的文档,都会返回一堆数据,下边简单解释一下含义: dsl { "_index" : "document_study",#所属索引 "_type" : "_doc", #所属type "_id" : "1", #文档id "_version" : 1, #文档版本 "result" : "created", #创建结果 "_shards" : { "total" : 2, #所在分片有两个分片 "successful" : 1, #只有一个副本成功写入,因为我是部署的单机es "failed" : 0 #失败副本数 }, "_seq_no" : 0, #第几次操作该文档 "_primary_term" : 1 #词项数 } 更多关于创建文档的操作详见官网:创建文档
更新文档
在更新文档前,我们先看下现在的数据: //只查source和id字段,其他字段过滤掉 GET document_study/_search?filter_path=hits.hits._source,hits.hits._id 
更新文档使用POST 和put都行,不过都需要指定文档id了因为更新肯定是针对某一或多个资源的更新,另外值的注意的是如果通过 update(update Api) 则可以部分更新,也就是只更新某些字段其余不动,但是如果使用 _doc (Index Api)则会全部更新,即你想更新a字段,那么使用doc (Index Api)方式提交后则目标文档中只有a字段了其他字段被覆盖,造成这样的原因就是:此机制是先删除,再新增。而update才是真正的你更新a字段就指给你更新a字段,而不会影响其他的字段和数据。
使用 update api 更新文档(更新指定的字段)
POST 目标索引名称/_update/文档id ```json //只更新username为 ”小琴“ //注意,使用update方式更新时,需要外边报一个doc,doc是个对象,要修改的字段值必须放到doc对象中
POST documentstudy/update/3 { "doc": { "username": "小琴" } } `` 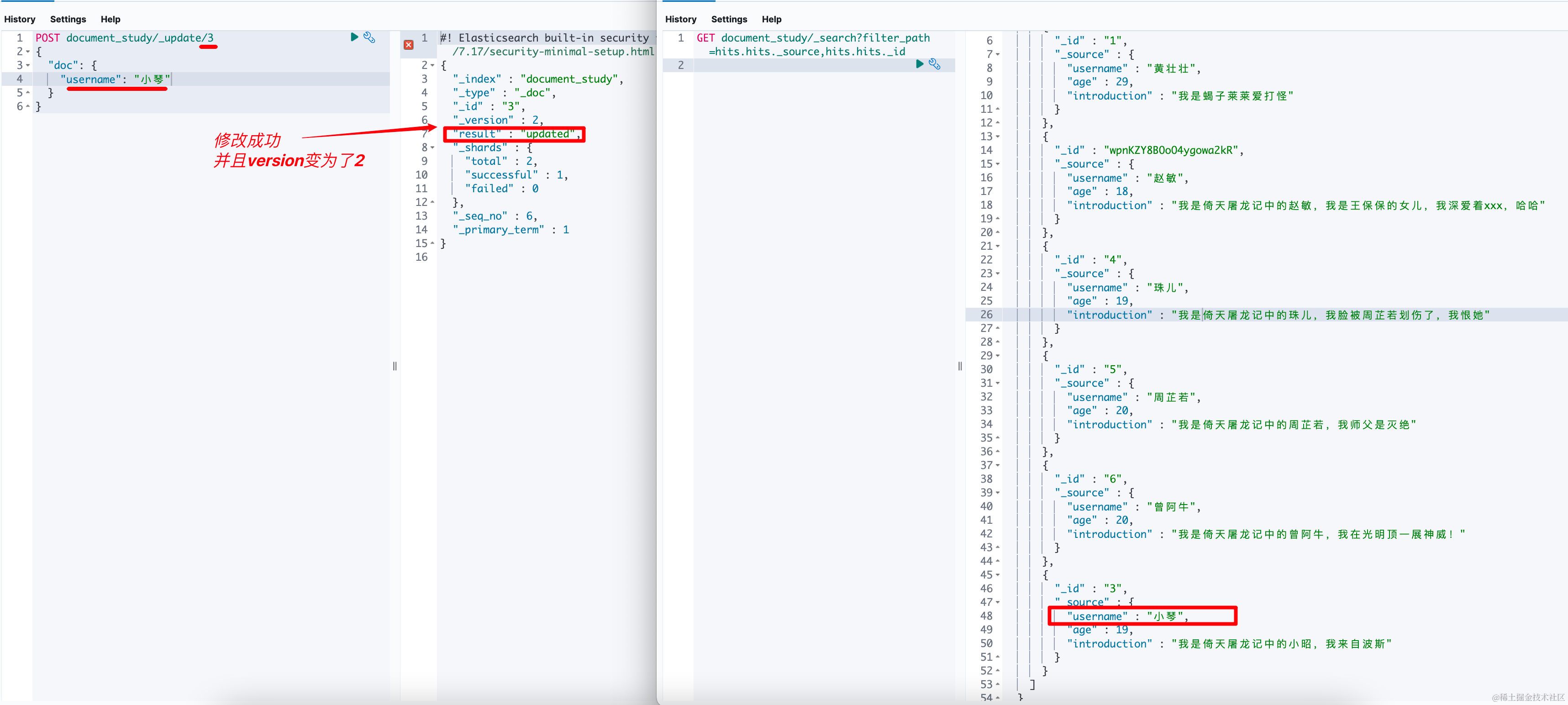 PUT documentstudy/update/3` 将报错405 ,也就是说不能使用put +update 方式更新。得使用post方式 
使用 index api 更新文档(先删除,再新增)
PUT 目标索引名称/_doc/文档id 
POST 目标索引名称/_doc/文档id 
使用脚本更新
脚本比较灵活,举例几个:
追加内容
给文档1中的字段introduction追加(使用+=代表追加) 内容,如下: dsl POST document_study/_update/1 { "script" : { "source": "ctx._source.introduction += params.introduction", "lang": "painless", "params" : { "introduction" : "-我的目标是寻找第3颗和平星" } } } 
更新内容
修改文档1中的age为30(=则直接使用新值覆盖旧值) dsl POST document_study/_update/1 { "script" : { "source": "ctx._source.age = params.age", "lang": "painless", "params" : { "age" : "30" } } } 
添加字段
添加字段(该字段是数组类型) dsl POST document_study/_update/1 { "script": { "source": "ctx._source.hobby=params.hobby", "lang": "painless", "params": { "hobby": [ "java", "python", "linux", "es" ] } } } 
当然 添加字段你也可以不定义params直接这样加: dsl POST document_study/_update/1 { "script" : "ctx._source.address='北京市朝阳区百子湾'" } 
追加内容到数组
dsl POST document_study/_update/1 { "script": { "source": "ctx._source.hobby.add(params.tag)", "lang": "painless", "params": { "tag": "go" } } } 
从数组移除元素
脚本是支持条件的,比如下边我们在移除元素时,会判断hobby数组中是否包含 ”linux“这个元素,存在再移除,如下: dsl POST document_study/_update/1 { "script": { "source": "if (ctx._source.hobby.contains(params.tag)) { ctx._source.hobby.remove(ctx._source.hobby.indexOf(params.tag)) }", "lang": "painless", "params": { "tag": "linux" } } } 
移除文档中的字段
POST test/_update/1 { "script" : "ctx._source.remove('new_field')" }
删除文档如果符合条件
dsl POST document_study/_update/1 { "script": { "source": "if (ctx._source.hobby.contains(params.tag)) { ctx.op = 'delete' } else { ctx.op = 'noop' }", "lang": "painless", "params": { "tag": "go" } } }  如果username包含周芷若,则删除文档5:
如果username包含周芷若,则删除文档5: 
删除字段
dsl POST document_study/_update/6 { "script" : "ctx._source.remove('age')" } 
使用upsert
当你操作一个不存在的文档时(我这里准备操作文档id是7的文档这个文档目前不存在),则会报错,如下:  如果你使用upsert后,如果文档不存在则会新建,文档存在则会更新。如下文档不存在时(则新增):
如果你使用upsert后,如果文档不存在则会新建,文档存在则会更新。如下文档不存在时(则新增): dsl POST document_study/_update/7 { "script": { "source": "ctx._source.username = params.tag", "lang": "painless", "params": { "tag": "金毛狮王" } }, "upsert": { "username": "金花婆婆" } }  使用upsert时,文档存在(则更新):
使用upsert时,文档存在(则更新): 
根据查询条件更新
dsl POST document_study/_update_by_query { "query": { "match": { "username": "赵敏" } }, "script": { "source": "ctx._source.age = 20 ", "lang": "painless" } } 
根据条件更新,可能在实际场景中比较实用至少我个人感觉是这样,但是有个问题就是可能符合条件的数据很多,那么这个请求就可能超时错误,合理的解决方案就是使用异步方式,告诉es 这个更新操作你异步来处理,这样的话我们发出的更新请求就会秒返回了。es内部会有个异步任务,来处理这个更新请求,当然我们也可以查看这个异步任务的状态,如下演示:
ps:updatebyquery 后边可以跟的参数很多,具体见 docsupdatebyquery ```dsl POST documentstudy/updatebyquery?waitforcompletion=false { "query": { "match": { "username": "赵敏" } }, "script": { "source": "ctx.source.age = 21 ", "lang": "painless" } }
//查询任务状态 GET /_tasks/任务id
//当然在某些任务执行过程中,可能我们不想更新了, //那么也可以取消某任务 POST tasks/任务id/cancel ``` 
查询文档
查询文档是否存在:HEAD 索引id/_doc/文档id 
查询文档
查某索引下的全部文档数据: GET document_study/_search
GET document_study/_doc/3 指定返回字段:
GET document_study/_search?filter_path=hits.hits._source,hits.hits._id

删除文档
删除文档很简单
DELETE 索引名/_doc/文档id  当然你也可以根据条件删除,如下:
当然你也可以根据条件删除,如下: dsl POST document_study/_delete_by_query { "query":{ "match":{ "username":"阿牛" } } }  当然和根据条件更新一样,当符合的条件的数据很多时,你也可以设置为异步。当然有很多参数
当然和根据条件更新一样,当符合的条件的数据很多时,你也可以设置为异步。当然有很多参数
批量操作 _bulk
批量操作的话使用 _bulk,他支持4种类型的操作: - create,delete,index(新增),和 update,如下描述: 
即允许一批操作中有不同类型(新增 删除 修改) 不同索引的操作,但是他这个对写法比较严格,必须使用换行符来分割JSON结构(我们不能格式化json串了),第一行指定操作类型和元数据(索引、文档id等),紧接着的一行是这个操作的内容(如果有的话你比如新增修改就有 删除就不存在),批量操作示例如下: dsl POST _bulk {"index":{"_index":"document_study_2","_id":"1"}} {"username": "黄壮壮","age":29,"introduction" : "我是蝎子莱莱爱打怪"} {"create":{"_index":"document_study_3","_id":"2"}} {"username": "赵奕欢","age":17,"introduction" : "我是奕欢姐姐"} {"update":{"_index":"document_study_2","_id":"1"}} {"doc":{"age":30}} {"delete":{"_index":"document_study","_id":"7"}}  上边这个批操作我是新建了索引 documentstudy2,documentstudy3 并且插入了数据,之后修改了documentstudy2索引中的文档1的age值为30 ,并且删除了索引 document_study中id=7的文档。这个功能在我们造测试数据时其实比较好用。不用多次请求了。只要脚本写好请求一次就完事了,也挺爽的。
上边这个批操作我是新建了索引 documentstudy2,documentstudy3 并且插入了数据,之后修改了documentstudy2索引中的文档1的age值为30 ,并且删除了索引 document_study中id=7的文档。这个功能在我们造测试数据时其实比较好用。不用多次请求了。只要脚本写好请求一次就完事了,也挺爽的。
说明:
本来我是准备将es的索引 映射 文档以及查询语法、聚合语法和Java Api 以及es集群都放一篇搞定,但是遇到了几个问题
- 首先 时间和精力不够且放到一起估计文章会超长。
- 最近在忙其他事情,es先放一放,后续的事情可能和es有深度的交互 ,到时候再说查询、聚合以及Java Api和集群和es原理这些事情吧。
上边的问题导致这篇文章在草稿箱挂了好久,为了不一口吃个胖子,所以 先将此文发表出来,后续有时间,会一点点更新Elasticsearch相关的文章。
es,未完待续。