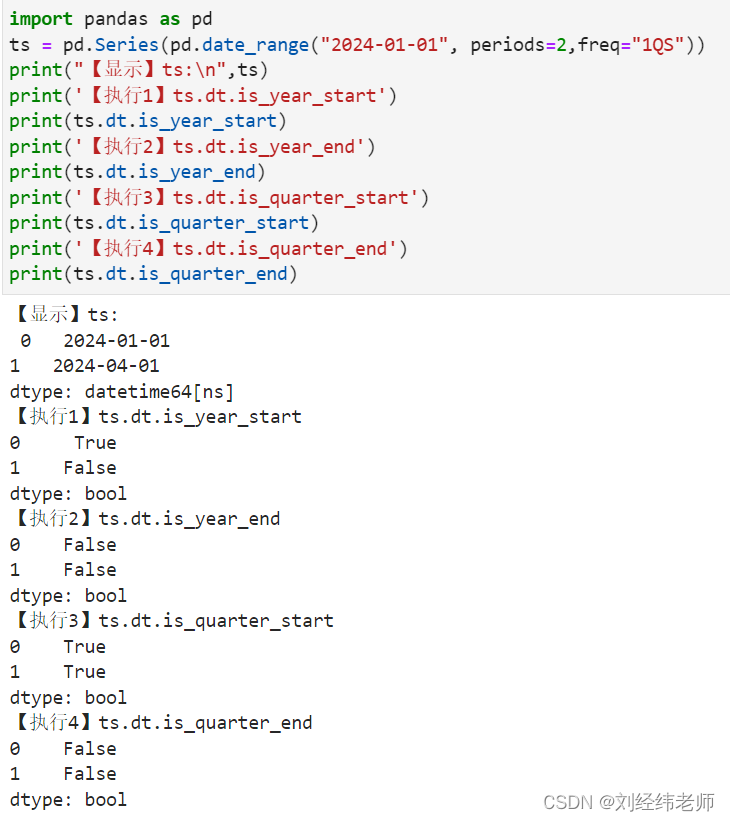
假如你有一本非常厚的书,每一章代表一个特征维度,而书中的故事(数据点)在每个章节(维度)都有详细的描述。但是,读者(模型)发现很难理解和记忆这个复杂的故事,因为细节太多。这时,你可以通过摘要(降维)来保留故事的核心线索,丢弃一些不那么重要的细节,这样读者就能更快地理解故事的主要情节。
一、数据降维
在机器学习中,降维任务的主要目标是简化数据的复杂度,同时保留数据的关键信息和结构。这通常是为了处理所谓的“维数灾难”,即随着特征数量的增加,数据会变得稀疏,导致模型训练变得更加困难,且容易过拟合。降维可以提高算法的运行效率,减少存储需求,同时也可能提升模型的泛化能力。
二、实现降维的方法概述
(1)主成分分析(PCA)
PCA是一种无监督的线性降维技术,目标是将数据投影到一个低维空间,同时尽可能保留原始数据的方差。PCA通过找到数据中方差最大的方向(主成分),然后将数据投影到这些方向上来实现降维。主要用于减少数据集的维度,数据去噪,以及发现数据中的模式。
假如有一堆彩色的珠子,每颗珠子的颜色代表不同的特征。如果你想要用最少的线条来描绘出珠子分布的大致形状,你会找到那些穿过珠子群中心并且能最大程度展示珠子分布方向的线。PCA就是这样一种方法,它找到数据的最大方差方向,也就是数据的“主轴”,并沿这些轴进行投影,以降低维度。
【机器学习300问】134、什么是主成分分析(PCA)?![]() https://blog.csdn.net/qq_39780701/article/details/140025002
https://blog.csdn.net/qq_39780701/article/details/140025002
(2)线性判别分析(LDA)
LDA是一种监督学习的降维技术,它不仅希望数据在降维后仍保持最大方差,也希望不同类别的数据最大程度地分开。LDA关注类间可分性,它的投影方向旨在最大化类间距离和最小化类内距离。通常用于特征提取、模式识别和机器学习中的分类任务。
LDA就像一位侦探在寻找罪犯,他通过观察不同群体(类别)的差异性特征来确定哪些线索(特征)对区分不同群体最有价值。
(3)自动编码器(Autoencoder)
自动编码器是一种使用神经网络实现的降维技术,其中包含一个编码器部分将输入数据编码成一个低维表示,以及一个解码器部分将这个低维表示重构回原始数据。自动编码器可以是非线性的,提供比线性方法更复杂的数据编码。它们常用于数据去噪、生成模型和特征学习。
【机器学习300问】56、什么是自编码器?![]() https://blog.csdn.net/qq_39780701/article/details/137156117
https://blog.csdn.net/qq_39780701/article/details/137156117
自动编码器就像是一个高效的信息压缩与解压系统。它接收一张图片(高维数据),将其压缩成一个更小的文件(低维表示),然后再从这个文件中恢复出原图。虽然恢复的图可能不是完全相同,但它能捕捉到原图的主要特征。
(4)奇异值分解(SVD)
SVD是一种数学方法,用于分解矩阵为奇异向量和奇异值,这可以用于矩阵近似和降维。SVD通常被用在PCA的计算过程中,因为通过SVD可以找到主成分。广泛应用于信号处理、统计学、语义索引(如潜在语义分析)等领域。
SVD可以想象成一个图书管理员的工作,他需要整理图书馆里大量的书籍,但空间有限。他决定将书按照主题和受欢迎程度排序,然后只保留最前面的一部分书籍,这样既节省了空间,又保留了图书馆的主要资源。SVD通过分解矩阵,找到最重要的向量(奇异向量)和值(奇异值),然后只保留这些向量和值,实现降维。





![【2024最新华为OD-C/D卷试题汇总】[支持在线评测] 数字排列游戏(200分) - 三语言AC题解(Python/Java/Cpp)](https://i-blog.csdnimg.cn/direct/32042c370ca64534b8347252bf707ac2.png)