Kafka概述
Why is kafka fast?
思考一下,当我们在讨论Kafka快的时候我们是在谈论什么呢?What does it even mean that Kafka is fast?
我们是在谈论kafka的低延迟(low latency)还是在讨论吞吐量(throughput)呢?
It is fast compared to what?
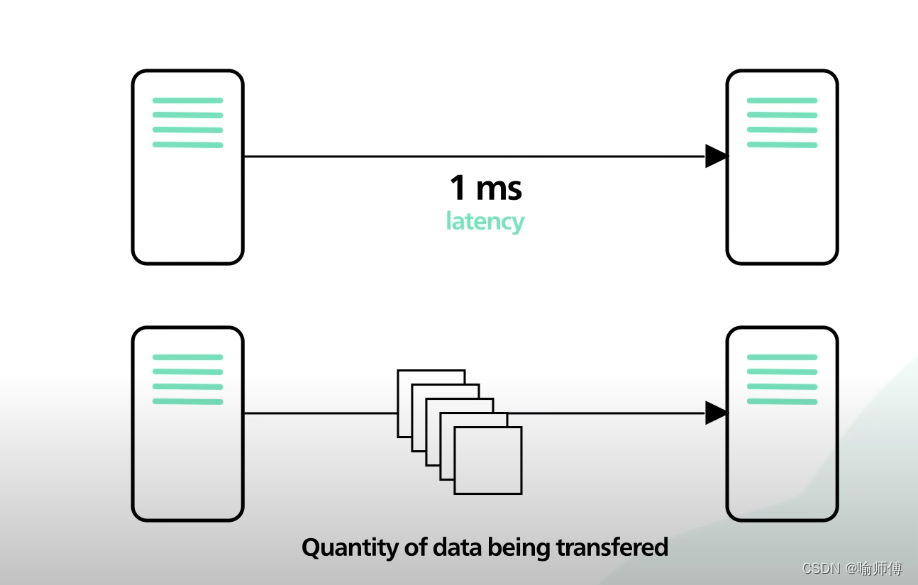
kafka is optimized for high throughput. lt is designed to move a large number of records in a short amount of time.
Kafka针对高吞吐量进行了优化。它的设计目的是在短时间内移动大量的记录。
Think of it as a very large pipe moving liquid.把Kafka想象成一个非常大的管道移动液体。

The bigger the diameter of the pipe, the largerthe volume of liquid that can move through it.
管道的直径越大,流经管道的液体体积就越大。
So when someone says Kafka is fast, they usually refer to Kafka’s ability to move a lot of data.
所以人们谈论Kafka很快的时候,他们通常指的是Kafka移动大量数据的能力。

What are some of the design decisions that help Kafka move a lot of data quickly?
那么Kafka哪些设计决策与设计细节可以实现快速移动大量数据呢?
There are many design decisions that contributed to Kafka’s performance.这里我们只关注两种最重要的设计。
1.Sequential I/O
The first one is Kafka’s reliance on sequential l/0.首先是Kafka对顺序l/0的依赖。

什么是sequential I/O呢?
这里我们有一个常见的误区,我们常常认为磁盘访问比内存访问慢,但是其实这在很大程度上取决于数据访问模式(access pattern)。
There are two types of disk access patterns —random and sequential.
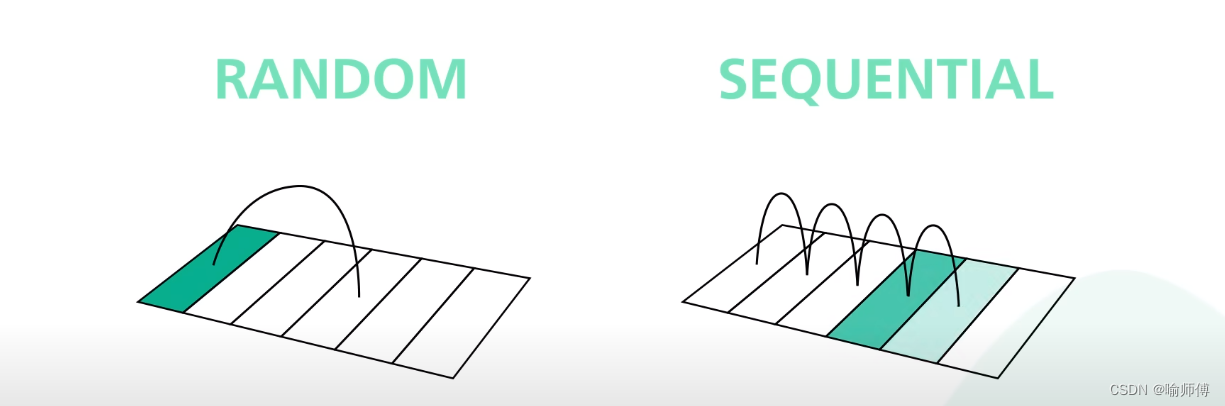
For hard drives it takes time to physically move the arm to different locations on the magnetic disks.This is what makes random access slow.
对于硬盘驱动器,它需要时间来物理移动磁头臂到磁盘上的不同位置。这就是随机访问缓慢的原因。
For sequential access, though, since your arm doesn’t need to jump around, it is much faster to read and write blocks of data oneafter the other.
对于顺序访问,由于磁头臂不需要跳转,因此依次读取和写入数据块的速度要快得多。
Kafka takes advantage of this by using an append-only log as its primary data structure.
Kafka使用仅追加日志作为其主要数据结构,即实现了顺序I/O模式。
An append-only log adds new data to the end of the file.This access pattern is sequential.
仅追加日志将新数据添加到文件的末尾,这种访问模式是顺序的。
On modern hardware with an array of these hard disks, sequential writes reach hundreds of megabytes per second, while random writes aremeasured in hundreds of kilobyte per second.
在拥有这些硬盘阵列的现代硬件上,顺序写入达到每秒数百Mb字节,而随机写入只能达到每秒数百Kb字节。
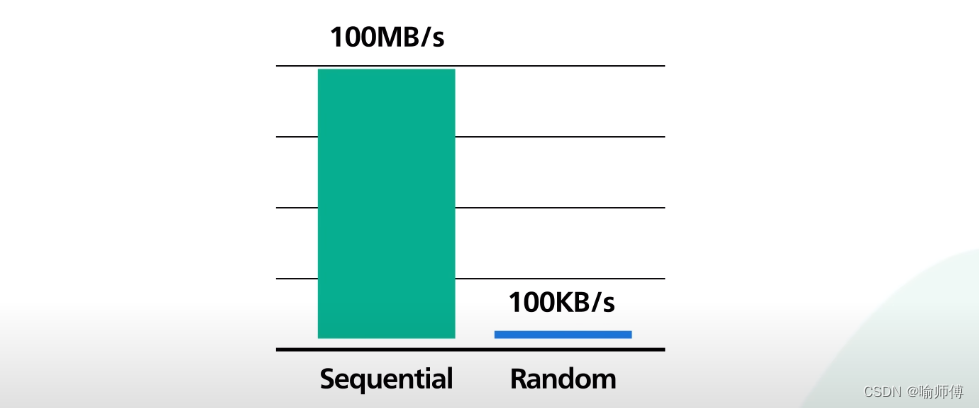
Sequential access is several order of magnitude faster. 顺序访问速度快几个数量级。
Using hard disks has its cost advantage, too. 使用硬盘也有其成本优势。

与SSD相比,硬盘的价格只有它的三分之一,但容量却是它的三倍。
Giving Kafka a large pool of cheap disk space without any performance penalty means that Kafka can cost effectively retain messages for a long period of time,a feature that was uncommon to messaging systems before Kafka.
为Kafka提供大量廉价的磁盘空间而没有任何性能损失,这意味着Kafka可以有效地长时间保留消息。
而这一点在Kafka之前的消息系统中,并不常见。

2.Zero copy principle
The second design choice that gives Kafka its performance advantage is its focus on efficiency.
Kafka moves a lot of data from network to disk, and from disk to network.
Kafka将大量数据从网络移动到磁盘,再从磁盘移动到网络。
It is critically important to eliminate excess copy when moving pages and pages of data between the disk and the network.
在磁盘和网络之间移动一页又一页的数据时,消除多余的拷贝是非常重要的。

这就是零复制原理发挥作用的地方。This is where zero copy principle comes into the picture.
现代unix操作系统经过高度优化,可以将数据从磁盘传输到网络,而不会过度复制数据。
Modern unix operating systems are highly optimized to transfer data from disk to network without copying data excessively.
首先,我们看一下Kafka是如何在零拷贝根本不使用的情况下将磁盘上的一页数据发送给消费者的。

-
1.数据从磁盘加载到操作系统缓存。
First the data is loaded from disk to the OS cache. -
2.数据从操作系统缓存复制到Kafka应用程序。
Second the data is copied from the OS cache into the Kafka application.
-
3.数据从Kafka复制到套接字缓冲区。Third the data is copied from Kafka to the socket buffer.
-
4 将数据从套接字缓冲区复制到网络接口卡缓冲区。
And fourth the data is copied from the socket buffer to the network interface card buffer. -
5.最后数据通过网络发送给消费者。And finally, the data is sent over the network to the consumer.
Now this is clearly inefficient. There are four copies and two system calls. 这显然是低效的。有四个副本和两个系统调用。
现在我们再来看一下使用零拷贝的Kafka。

第一步是一样的。数据页面从磁盘加载到操作系统缓存。
零拷贝时,Kafka应用程序使用一个名为sendfile()的系统调用来告诉操作系统直接将数据从操作系统缓存复制到网络接口卡缓冲区。
With zero copy, the Kafka application uses a system call called sendfile() to tell the operating system to directly copy the data from the OS cache to the network interface card buffer.
在这个优化的路径中,唯一的拷贝是从操作系统缓存到网卡缓冲区的。
With a modern network card, this copying is done with DMA.对于现代网卡,这种复制是通过DMA完成的。

DMA stands for direct memory access. When DMA is used the cpu is not involved, making it even more efficient.
DMA表示直接内存访问。当使用DMA时,不涉及cpu,使其更加高效。
To recap, sequential I/O and zero copy principle are the cornerstone to Kafka’s high performance.
顺序I/O和零拷贝原则是Kafka高性能的基石。
Kafka uses other techniques to squeeze every ounce of performance out of modern hardware, but
these two are the most important in our view.
Kafka使用其他技术从现代硬件中挤出每一丝性能,而在我们看来,顺序I/O、零拷贝原则这两个是最重要的。
Learned it from youtuber:ByteByteGo.