目录
一、 openpyxl库的由来
1、背景
2、起源
3、发展
4、特点
4-1、支持.xlsx格式
4-2、读写Excel文件
4-3、操作单元格
4-4、创建和修改工作表
4-5、样式设置
4-6、图表和公式
4-7、支持数字和日期格式
二、openpyxl库的优缺点
1、优点
1-1、支持现代Excel格式
1-2、功能丰富
1-3、易于使用
1-4、与Excel兼容性
1-5、性能良好
1-6、社区支持
1-7、跨平台
2、缺点
2-1、不支持旧版格式
2-2、某些特性支持有限
2-3、内存占用
2-4、文档和示例可能不足
2-5.、依赖关系
2-6、学习曲线
三、openpyxl库的用途
1、读取Excel文件
2、写入Excel文件
3、修改Excel文件
4、自动化
5、与Excel交互
6、数据迁移和转换
7、创建模板化的报告
四、如何学好openpyxl库?
1、获取openpyxl库的属性和方法
2、获取xlwt库的帮助信息
3、实战案例
3-141、引用输入了文本的全部单元格
3-142、引用输入了逻辑值的全部单元格
3-143、引用输入了批注的全部单元格
3-144、引用没有输入任何数据和公式的空单元格
3-145、引用所有可见的单元格
3-146、引用输入了日期的单元格
3-147、引用含有相同计算公式的所有单元格
3-148、引用合并单元格区域
3-149、引用定义名称所指定的单元格区域
3-150、引用输入了任何内容的最后一行单元格
3-151、引用多个非连续单元格区域集合(类似Union方法)
3-152、引用多个非连续单元格区域集合(循环处理)
3-153、引用多个单元格区域的交叉区域
3-154、获取计算公式的所有引用单元格
3-155、获取计算公式中引用的其他工作表单元格
3-156、获取某个单元格的从属单元格
3-157、引用某个单元格所在的整个行
3-158、引用某个单元格所在的整个列
3-159、引用单元格区域所在的行范围
3-160、引用单元格区域所在的列范围
五、推荐阅读
1、Python筑基之旅
2、Python函数之旅
3、Python算法之旅
4、Python魔法之旅
5、博客个人主页



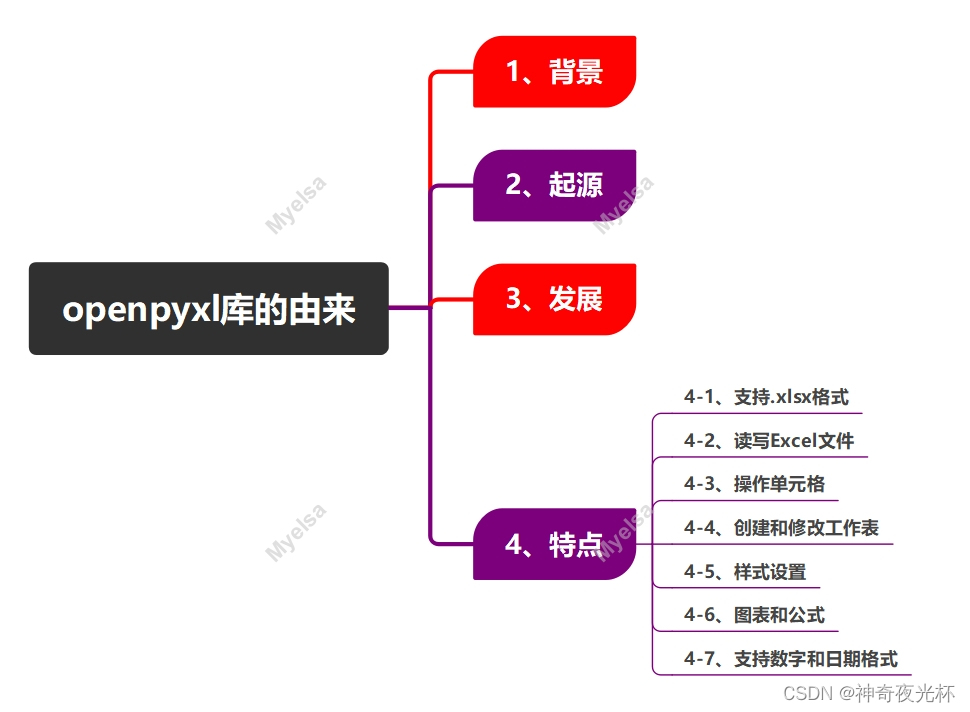
一、 openpyxl库的由来
openpyxl库的由来可以总结为以下几点:
1、背景
在openpyxl库诞生之前,Python中缺乏一个专门用于读取和编写Office Open XML格式(如Excel 2010及更高版本的.xlsx文件)的库。
2、起源
openpyxl库的创建是为了解决上述提到的Python在处理Excel文件时的不足,它的开发受到了PHPExcel团队的启发,因为openpyxl最初是基于PHPExcel的。
3、发展
随着时间的推移,openpyxl逐渐发展成为一个功能强大的Python库,专门用于处理Excel文件。它支持Excel 2010及更高版本的文件格式,并提供了丰富的API,用于读取、写入、修改Excel文件。
4、特点
4-1、支持.xlsx格式
openpyxl主要用于处理Excel 2010及更新版本的.xlsx文件。
4-2、读写Excel文件
使用openpyxl可以读取现有的Excel文件,获取数据,修改数据,并保存到新的文件中。
4-3、操作单元格
openpyxl允许用户按行、列或具体的单元格进行数据的读取和写入。
4-4、创建和修改工作表
用户可以创建新的工作表,复制和删除现有的工作表,设置工作表的属性等。
4-5、样式设置
openpyxl支持设置单元格的字体、颜色、边框等样式。
4-6、图表和公式
用户可以通过openpyxl创建图表、添加公式等。
4-7、支持数字和日期格式
openpyxl能够正确处理数字和日期格式,确保在Excel中显示正确的格式。
综上所述,openpyxl库的出现填补了Python在处理Excel文件时的空白,经过不断的发展和完善,成为了一个功能丰富、易于使用的Python库。
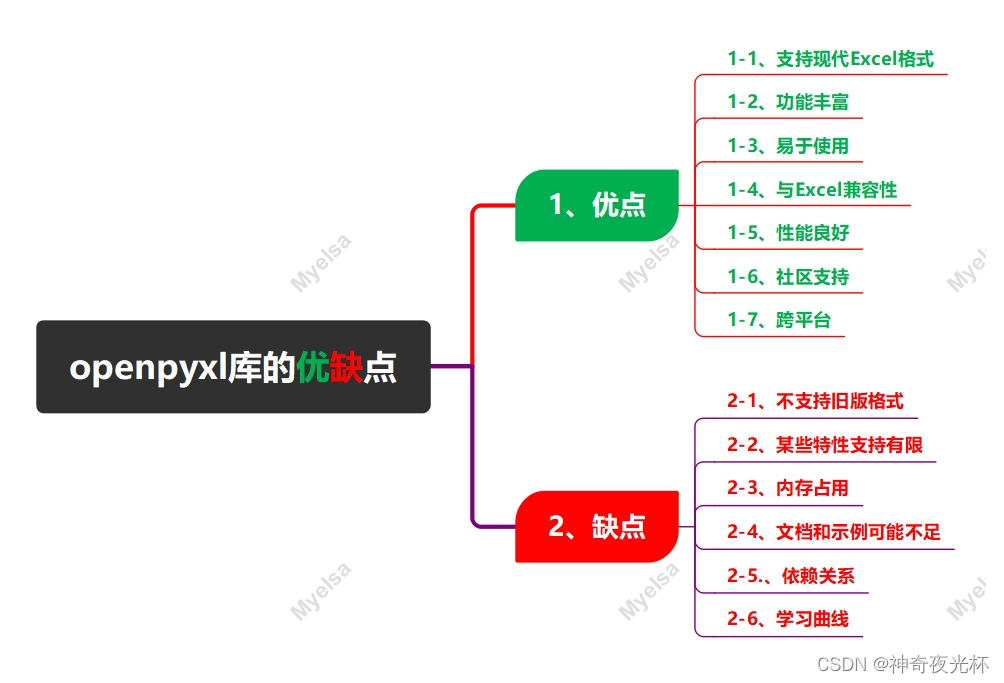
二、openpyxl库的优缺点
openpyxl库是一个用于读写Excel 2010 xlsx/xlsm/xltx/xltm文件的Python库,它基于Python,并且对于处理Excel文件提供了很多便利的功能,其主要优缺点有:
1、优点
1-1、支持现代Excel格式
openpyxl支持.xlsx格式的Excel文件,这是Excel 2010及更高版本使用的格式,也是目前广泛使用的格式。
1-2、功能丰富
openpyxl提供了创建、修改和保存Excel工作簿、工作表、单元格、图表、公式、图像等功能。
1-3、易于使用
openpyxl的API设计得相对直观,使得Python开发者能够很容易地掌握和使用。
1-4、与Excel兼容性
openpyxl能够处理Excel文件中的很多复杂特性,如公式、样式、条件格式等,这确保了与Excel的良好兼容性。
1-5、性能良好
在处理大型Excel文件时,openpyxl通常能够保持较好的性能。
1-6、社区支持
openpyxl是一个开源项目,拥有活跃的社区支持和维护,这意味着开发者可以获得帮助和修复错误的快速响应。
1-7、跨平台
openpyxl可以在不同的操作系统上运行,包括Windows、Linux和macOS等。
2、缺点
2-1、不支持旧版格式
openpyxl不支持较旧的.xls格式(Excel 97-2003)。如果需要处理这种格式的文件,需要使用其他库如xlrd和xlwt(尽管这些库也面临一些兼容性和维护问题)。
2-2、某些特性支持有限
虽然openpyxl支持许多Excel特性,但可能对于某些高级或特定的Excel功能支持有限或不支持。
2-3、内存占用
在处理大型Excel文件时,openpyxl可能会占用较多的内存。这是因为openpyxl会将整个工作簿加载到内存中。
2-4、文档和示例可能不足
尽管openpyxl的文档相对完整,但对于某些高级功能或特定用例,可能缺乏足够的示例或详细解释。
2-5.、依赖关系
openpyxl依赖于lxml和et_xmlfile这两个Python库来处理XML和Excel文件,在某些环境中,可能需要额外安装这些依赖项。
2-6、学习曲线
虽然openpyxl的API设计得相对直观,但对于初学者来说,可能需要一些时间来熟悉和掌握其用法。
三、openpyxl库的用途
openpyxl是一个用于读写Excel 2010 xlsx/xlsm/xltx/xltm文件的Python库。它是用Python编写的,不需要Microsoft Excel,并且支持多种Excel数据类型,包括图表、图像、公式等,其主要用途有:
1、读取Excel文件
你可以使用openpyxl来读取 Excel 文件中的数据,如单元格值、工作表名称、公式等,它支持多种数据类型,如字符串、数字、日期等。
2、写入Excel文件
使用openpyxl,你可以创建新的Excel文件或向现有文件添加数据,你可以设置单元格的字体、颜色、边框等样式,你还可以添加图表、图像和其他复杂的Excel功能。
3、修改Excel文件
你可以使用openpyxl来修改现有的Excel文件,如更改单元格值、添加或删除工作表等,这对于自动化数据处理和报告生成非常有用。
4、自动化
openpyxl可以与其他Python库和框架(如 pandas、numpy、matplotlib 等)结合使用,以自动化数据处理和分析任务。你可以编写脚本来从多个数据源收集数据,将数据整合到 Excel 文件中,并执行各种数据分析任务。
5、与Excel交互
如果你正在开发需要与Excel交互的应用程序或工具,openpyxl可以提供一个强大的API来处理Excel文件,它允许你读取和写入Excel文件,而无需依赖Microsoft Excel或其他第三方库。
6、数据迁移和转换
使用openpyxl,你可以轻松地将数据从Excel文件迁移到其他数据库或文件格式,或将其他数据源的数据导入到Excel文件中。
7、创建模板化的报告
你可以使用openpyxl来创建模板化的Excel报告,并在需要时填充数据,这对于需要定期生成具有一致格式和布局的报告的场景非常有用。
总之,openpyxl是一个功能强大的库,可用于在Python中处理Excel文件,它提供了灵活的API来读取、写入、修改和自动化Excel文件的各个方面。
四、如何学好openpyxl库?
1、获取openpyxl库的属性和方法
用print()和dir()两个函数获取openpyxl库所有属性和方法的列表
# ['DEBUG', 'DEFUSEDXML', 'LXML', 'NUMPY', 'Workbook', '__author__', '__author_email__', '__builtins__', '__cached__',
# '__doc__', '__file__', '__license__', '__loader__', '__maintainer_email__', '__name__', '__package__', '__path__',
# '__spec__', '__url__', '__version__', '_constants', 'cell', 'chart', 'chartsheet', 'comments', 'compat', 'constants',
# 'descriptors', 'drawing', 'formatting', 'formula', 'load_workbook', 'open', 'packaging', 'pivot', 'reader', 'styles',
# 'utils', 'workbook', 'worksheet', 'writer', 'xml']2、获取xlwt库的帮助信息
用help()函数获取openpyxl库的帮助信息
Help on package openpyxl:
NAME
openpyxl - # Copyright (c) 2010-2024 openpyxl
PACKAGE CONTENTS
_constants
cell (package)
chart (package)
chartsheet (package)
comments (package)
compat (package)
descriptors (package)
drawing (package)
formatting (package)
formula (package)
packaging (package)
pivot (package)
reader (package)
styles (package)
utils (package)
workbook (package)
worksheet (package)
writer (package)
xml (package)
SUBMODULES
constants
DATA
DEBUG = False
DEFUSEDXML = False
LXML = True
NUMPY = True
__author_email__ = 'charlie.clark@clark-consulting.eu'
__license__ = 'MIT'
__maintainer_email__ = 'openpyxl-users@googlegroups.com'
__url__ = 'https://openpyxl.readthedocs.io'
VERSION
3.1.3
AUTHOR
See AUTHORS
FILE
e:\python_workspace\pythonproject\lib\site-packages\openpyxl\__init__.py3、实战案例
3-141、引用输入了文本的全部单元格
# 3-141、引用输入了文本的全部单元格
import openpyxl
# 打开 Excel 文件
workbook = openpyxl.load_workbook('example.xlsx')
# 获取所有工作表的名称
sheet_names = workbook.sheetnames
# 遍历每个工作表
for sheet_name in sheet_names:
sheet = workbook[sheet_name]
print(f"Processing sheet: {sheet_name}")
# 遍历每一行和每一列
for row in sheet.iter_rows():
for cell in row:
# 检查单元格是否包含文本
if cell.data_type == 's': # 's' 表示单元格包含字符串
print(f"Cell {cell.coordinate} contains text: {cell.value}")3-142、引用输入了逻辑值的全部单元格
略,openpyxl库暂不支持此功能,需要借助其他库实现3-143、引用输入了批注的全部单元格
# 3-143、引用输入了批注的全部单元格
import openpyxl
# 打开 Excel 文件
workbook = openpyxl.load_workbook('example.xlsx')
# 假设我们只对第一个工作表感兴趣
sheet = workbook.active # 或者使用 workbook['Sheet1'] 来指定工作表名称
# 遍历工作表中的每一行和每一列
for row in sheet.iter_rows(min_row=sheet.min_row, max_row=sheet.max_row, min_col=sheet.min_column,
max_col=sheet.max_column):
for cell in row:
# 检查单元格是否包含批注
if cell.comment is not None:
# 打印单元格的引用和批注的内容
print(f"Cell {cell.coordinate} contains a comment: {cell.comment.text}")3-144、引用没有输入任何数据和公式的空单元格
# 3-144、引用没有输入任何数据和公式的空单元格
import openpyxl
# 加载 Excel 文件
workbook = openpyxl.load_workbook('example.xlsx')
sheet = workbook.active # 或者使用 workbook[sheetname] 指定具体的工作表
# 存储空单元格的列表
empty_cells = []
# 遍历工作表中的每个单元格
for row in sheet.iter_rows():
for cell in row:
if cell.value is None and cell.data_type != 'f': # 检查单元格是否为空且没有公式
empty_cells.append(cell.coordinate) # 存储空单元格的坐标
# 输出所有空单元格的坐标
print("以下单元格为空且没有输入公式:")
for coord in empty_cells:
print(coord)3-145、引用所有可见的单元格
# 3-145、引用所有可见的单元格
import openpyxl
# 加载 Excel 文件
workbook = openpyxl.load_workbook('example.xlsx')
sheet = workbook.active # 或者使用 workbook[sheetname] 指定具体的工作表
# 存储可见单元格的列表
visible_cells = []
# 遍历工作表中的每个单元格
for row in sheet.iter_rows():
for cell in row:
if not cell.column_letter in sheet.column_dimensions or not sheet.column_dimensions[cell.column_letter].hidden:
if not cell.row in sheet.row_dimensions or not sheet.row_dimensions[cell.row].hidden:
visible_cells.append(cell.coordinate)
# 输出所有可见单元格的坐标
print("以下单元格是可见的:")
for coord in visible_cells:
print(coord)3-146、引用输入了日期的单元格
# 3-146、引用输入了日期的单元格
import openpyxl
# 注意:这里没有从openpyxl.utils导入datetime,因为我们直接使用内置的datetime模块
from datetime import datetime
# 加载Excel文件
workbook = openpyxl.load_workbook('example.xlsx')
# 如果需要检查所有工作表,可以使用workbook.sheetnames来迭代
sheet = workbook.active # 或者使用workbook[sheetname]指定具体的工作表
# 存储包含日期的单元格的列表
date_cells = []
# 遍历工作表中的每个单元格
for row in sheet.iter_rows():
for cell in row:
# 检查单元格的值是否是datetime类型
if isinstance(cell.value, datetime):
date_cells.append(cell.coordinate)
# 输出所有包含日期的单元格的坐标
print("以下单元格包含日期:")
for coord in date_cells:
print(coord)3-147、引用含有相同计算公式的所有单元格
# 3-147、引用含有相同计算公式的所有单元格
import openpyxl
# 加载Excel文件
workbook = openpyxl.load_workbook('example.xlsx', data_only=False)
sheet = workbook.active # 或者使用 workbook[sheetname] 指定具体的工作表
# 特定的公式
target_formula = '=SUM(C1:C2)' # 例如 '=SUM(C1:C2)'
# 存储包含相同公式的单元格的列表
formula_cells = []
# 遍历工作表中的每个单元格
for row in sheet.iter_rows():
for cell in row:
if cell.value and isinstance(cell.value, str) and cell.value.startswith('='):
if cell.value.strip().upper() == target_formula.strip().upper():
formula_cells.append(cell.coordinate)
# 输出所有包含相同公式的单元格的坐标
print("以下单元格包含相同公式:")
for coord in formula_cells:
print(coord)3-148、引用合并单元格区域
# 3-148、引用合并单元格区域
import openpyxl
# 加载Excel文件
workbook = openpyxl.load_workbook('example.xlsx')
sheet = workbook.active # 或者使用 workbook[sheetname] 指定具体的工作表
# 获取所有合并单元格的区域
merged_cells_ranges = sheet.merged_cells.ranges
# 遍历并输出所有合并单元格区域
print("以下是所有合并单元格的区域:")
for merged_range in merged_cells_ranges:
print(merged_range)
# 例如,可以获取合并单元格的起始单元格和结束单元格
start_cell = sheet[merged_range.coord.split(":")[0]]
end_cell = sheet[merged_range.coord.split(":")[1]]
print(f"起始单元格: {start_cell.coordinate}, 结束单元格: {end_cell.coordinate}")
# 示例:修改合并单元格的值
start_cell.value = "新值"
# 保存修改后的工作簿
workbook.save('修改后的文件.xlsx')3-149、引用定义名称所指定的单元格区域
略,openpyxl库暂不支持此功能,需要借助其他库实现3-150、引用输入了任何内容的最后一行单元格
# 3-150、引用输入了任何内容的最后一行单元格
import openpyxl
def find_last_filled_row(sheet):
# 初始化最后一行索引
last_row = 0
# 遍历每一行
for row in sheet.iter_rows():
for cell in row:
if cell.value is not None:
# 更新最后一行索引
last_row = max(last_row, cell.row)
return last_row
# 加载 Excel 文件
workbook = openpyxl.load_workbook('example.xlsx')
sheet = workbook.active # 或者使用 workbook[sheetname] 指定具体的工作表
# 找到最后一行有内容的单元格的行号
last_filled_row = find_last_filled_row(sheet)
# 输出最后一行有内容的单元格的行号
print(f"最后一行有内容的单元格的行号是: {last_filled_row}")
# 示例:引用最后一行的单元格
if last_filled_row > 0:
last_row_cells = sheet[last_filled_row]
for cell in last_row_cells:
print(f"单元格 {cell.coordinate} 的值: {cell.value}")
# 你可以在此处进行进一步的操作,例如修改最后一行的单元格的值
# 保存修改后的工作簿
workbook.save('修改后的文件.xlsx')3-151、引用多个非连续单元格区域集合(类似Union方法)
# 3-151、引用多个非连续单元格区域集合(类似Union方法)
import openpyxl
# 加载 Excel 文件
workbook = openpyxl.load_workbook('example.xlsx')
sheet = workbook.active # 或者使用 workbook[sheetname] 指定具体的工作表
# 定义多个非连续单元格区域
regions = ['A1:B2', 'D4:E5', 'G7:H8']
# 初始化一个字典来存储各区域的单元格
cells = {}
for region in regions:
cells[region] = sheet[region]
# 示例:遍历并打印各区域的单元格的值
for region, cell_range in cells.items():
print(f"Region: {region}")
for row in cell_range:
for cell in row:
print(f"单元格 {cell.coordinate} 的值: {cell.value}")
# 示例:修改各区域的单元格的值
for cell_range in cells.values():
for row in cell_range:
for cell in row:
cell.value = "修改后的值"
# 保存修改后的工作簿
workbook.save('修改后的文件.xlsx')3-152、引用多个非连续单元格区域集合(循环处理)
# 3-152、引用多个非连续单元格区域集合(循环处理)
import openpyxl
# 加载 Excel 文件
workbook = openpyxl.load_workbook('example.xlsx')
sheet = workbook.active # 或者使用 workbook[sheetname] 指定具体的工作表
# 定义多个非连续单元格区域
regions = ['A1:B2', 'D4:E5', 'G7:H8']
# 循环处理每个区域
for region in regions:
cell_range = sheet[region]
for row in cell_range:
for cell in row:
# 处理单元格的逻辑,例如打印单元格值
print(f"单元格 {cell.coordinate} 的值: {cell.value}")
# 示例:修改单元格的值
cell.value = "新的值"
# 保存修改后的工作簿
workbook.save('修改后的文件.xlsx')3-153、引用多个单元格区域的交叉区域
# 3-153、引用多个单元格区域的交叉区域
import openpyxl
def get_cells_from_range(sheet, cell_range):
"""Helper function to get all cells from a given range."""
cells = set()
for row in sheet[cell_range]:
for cell in row:
cells.add(cell.coordinate)
return cells
# 加载Excel文件
workbook = openpyxl.load_workbook('example.xlsx')
sheet = workbook.active # 或者使用 workbook[sheetname] 指定具体的工作表
# 定义多个单元格区域
regions = ['A1:C3', 'B2:D4']
# 获取每个区域的单元格集合
sets_of_cells = [get_cells_from_range(sheet, region) for region in regions]
# 找出交叉区域的单元格
intersection = set.intersection(*sets_of_cells)
# 循环处理交叉区域的每个单元格
for cell_coord in intersection:
cell = sheet[cell_coord]
print(f"单元格 {cell.coordinate} 的值: {cell.value}")
# 示例:修改单元格的值
cell.value = "交叉区域"
# 保存修改后的工作簿
workbook.save('修改后的文件.xlsx')3-154、获取计算公式的所有引用单元格
# 3-154、获取计算公式的所有引用单元格
import openpyxl
import re
def get_referenced_cells(formula):
"""Helper function to extract referenced cells from a formula."""
# Regular expression to match cell references like A1, B2, etc.
cell_ref_pattern = re.compile(r'(\$?[A-Z]+\$?\d+)')
return cell_ref_pattern.findall(formula)
# 加载 Excel 文件
workbook = openpyxl.load_workbook('example.xlsx')
sheet = workbook.active # 或者使用 workbook[sheetname] 指定具体的工作表
# 选择包含公式的单元格
cell_with_formula = sheet['C7'] # 假设C7单元格包含公式
# 获取单元格的公式
formula = cell_with_formula.value
if formula and formula.startswith('='):
# 提取公式中的所有引用单元格
referenced_cells = get_referenced_cells(formula)
print(f"公式 '{formula}' 引用了以下单元格: {referenced_cells}")
# 示例:遍历并打印每个引用单元格的值
for cell_ref in referenced_cells:
cell = sheet[cell_ref]
print(f"单元格 {cell.coordinate} 的值: {cell.value}")
else:
print(f"单元格 {cell_with_formula.coordinate} 不包含公式或公式无效")
# 如果需要,可以保存修改后的工作簿
# workbook.save('修改后的文件.xlsx')3-155、获取计算公式中引用的其他工作表单元格
略,openpyxl库暂不支持此功能,需要借助其他库实现3-156、获取某个单元格的从属单元格
# 3-156、获取某个单元格的从属单元格
from openpyxl import load_workbook
import re
def find_dependent_cells(file_path, target_sheet, target_cell):
wb = load_workbook(file_path, data_only=False)
dependent_cells = []
target_ref = f'{target_sheet}!{target_cell}'
# 正则表达式匹配单元格引用,例如:A1
pattern = re.compile(r"([A-Z]+[0-9]+)")
for sheet in wb.sheetnames:
ws = wb[sheet]
for row in ws.iter_rows():
for cell in row:
if cell.data_type == 'f': # 仅处理包含公式的单元格
formula = cell.value
matches = pattern.findall(formula)
cell_references = [f'{sheet}!{match}' for match in matches]
if target_ref in cell_references:
dependent_cells.append(f'{sheet}!{cell.coordinate}')
return dependent_cells
if __name__ == '__main__':
file_path = 'example.xlsx' # 替换为你的Excel文件路径
target_sheet = 'Sheet' # 替换为目标单元格所在的工作表
target_cell = 'A1' # 替换为目标单元格
dependent_cells = find_dependent_cells(file_path, target_sheet, target_cell)
print(f'单元格 {target_sheet}!{target_cell} 的从属单元格: {dependent_cells}')3-157、引用某个单元格所在的整个行
# 3-157、引用某个单元格所在的整个行
from openpyxl import load_workbook
import re
def find_dependent_rows(file_path, target_sheet, target_cell):
wb = load_workbook(file_path, data_only=False)
ws = wb[target_sheet]
# 获取目标单元格所在的行号
target_row = ws[target_cell].row
# 构建目标行的单元格引用列表
target_row_cells = [f'{target_sheet}!{ws.cell(row=target_row, column=col).coordinate}'
for col in range(1, ws.max_column + 1)]
# 正则表达式匹配单元格引用,例如:A1
pattern = re.compile(r"([A-Z]+[0-9]+)")
dependent_cells = []
for sheet in wb.sheetnames:
ws = wb[sheet]
for row in ws.iter_rows():
for cell in row:
if cell.data_type == 'f': # 仅处理包含公式的单元格
formula = cell.value
matches = pattern.findall(formula)
cell_references = [f'{sheet}!{match}' for match in matches]
if any(ref in cell_references for ref in target_row_cells):
dependent_cells.append(f'{sheet}!{cell.coordinate}')
return dependent_cells
if __name__ == '__main__':
file_path = 'example.xlsx' # 替换为你的Excel文件路径
target_sheet = 'Sheet' # 替换为目标单元格所在的工作表
target_cell = 'A1' # 替换为目标单元格
dependent_cells = find_dependent_rows(file_path, target_sheet, target_cell)
print(f'单元格 {target_sheet}!{target_cell} 所在行的从属单元格: {dependent_cells}')3-158、引用某个单元格所在的整个列
# 3-158、引用某个单元格所在的整个列
from openpyxl import load_workbook
import re
def find_dependent_columns(file_path, target_sheet, target_cell):
wb = load_workbook(file_path, data_only=False)
ws = wb[target_sheet]
# 获取目标单元格所在的列号
target_col = ws[target_cell].column
# 构建目标列的单元格引用列表
target_col_cells = [f'{target_sheet}!{ws.cell(row=row, column=target_col).coordinate}'
for row in range(1, ws.max_row + 1)]
# 正则表达式匹配单元格引用,例如:A1
pattern = re.compile(r"([A-Z]+[0-9]+)")
dependent_cells = []
for sheet in wb.sheetnames:
ws = wb[sheet]
for row in ws.iter_rows():
for cell in row:
if cell.data_type == 'f': # 仅处理包含公式的单元格
formula = cell.value
matches = pattern.findall(formula)
cell_references = [f'{sheet}!{match}' for match in matches]
if any(ref in cell_references for ref in target_col_cells):
dependent_cells.append(f'{sheet}!{cell.coordinate}')
return dependent_cells
if __name__ == '__main__':
file_path = 'example.xlsx' # 替换为你的Excel文件路径
target_sheet = 'Sheet' # 替换为目标单元格所在的工作表
target_cell = 'D10' # 替换为目标单元格
dependent_cells = find_dependent_columns(file_path, target_sheet, target_cell)
print(f'单元格 {target_sheet}!{target_cell} 所在列的从属单元格: {dependent_cells}')3-159、引用单元格区域所在的行范围
略,openpyxl库暂不支持此功能,需要借助其他库实现3-160、引用单元格区域所在的列范围
略,openpyxl库暂不支持此功能,需要借助其他库实现