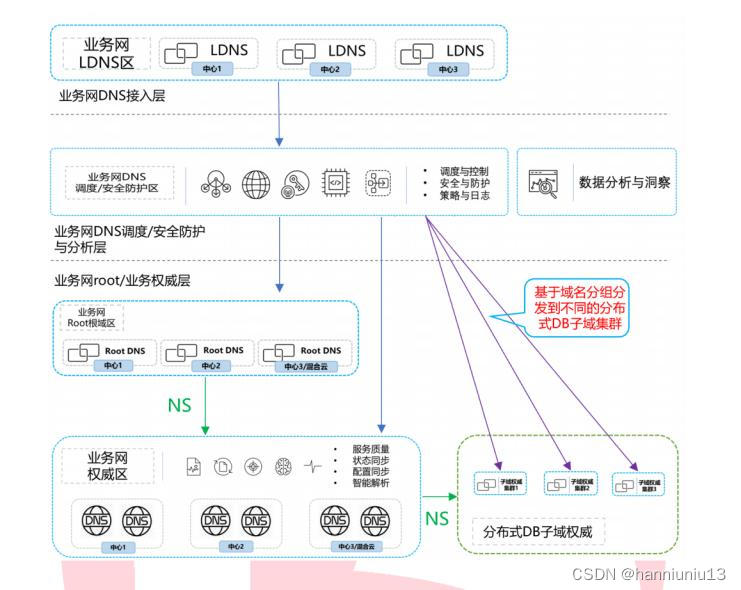
目录
1 特征二值化
1.1 特征二值化简介
1.2 实验数据集
2 阈值法
2.1 scikit-learn库实现阈值法二值化
2.2 pandas实现阈值法二值化
2.3 自定义函数实现阈值法二值化
3 其他方法实现二值化
3.1 中位数法
3.2 众数法
3.3 标准差法
1 特征二值化
1.1 特征二值化简介
特征二值化是一种数据预处理技术,特别是在处理分类问题时将特征值转换为二进制值,通常为0和1。这种转换可以简化模型的复杂性,提高计算效率,并在某些情况下提高模型的性能。
特征二值化常用方法有如下几种,中位数法、众数法、标准差法相当于是阈值法中阈值的特殊取值:
-
阈值法:选择一个阈值,将所有大于或等于阈值的特征值设置为1,小于阈值的设置为0。
-
中位数法:使用特征值的中位数作为分界点,将大于或等于中位数的值设置为1,小于中位数的值设置为0。
-
众数法:将特征值中出现次数最多的值作为1,其他值设置为0。
-
标准差法:如果特征值的绝对值大于其标准差的某个倍数,则将其设置为1,否则为0。
特征二值化的使用场景:特征二值化在某些算法中非常有用,比如决策树和随机森林,因为这些算法对于特征的数值大小不敏感,只关心特征值的分布。然而,在其他一些算法中,如线性回归或神经网络,特征的数值大小可能会影响模型的性能,因此在这些情况下可能不适合使用特征二值化。
1.2 实验数据集
背景描述:本数据集汇集了某个电商平台的用户基本信息、行为习惯和互动数据。它包括用户的年龄、性别、居住地区、收入水平等基本属性,以及他们的兴趣偏好、登录频率、购买行为和平台互动等动态指标。
数据说明:
| 字段 | 说明 |
|---|---|
| User_ID | 每个用户的唯一标识符,便于追踪和分析。 |
| Age | 用户的年龄,提供对人口统计偏好的洞察。 |
| Gender | 用户的性别,使能性别特定的推荐和定位。 |
| Location | 用户所在地区:郊区、农村、城市,影响偏好和购物习惯。 |
| Income | 用户的收入水平,表明购买力和支付能力。 |
| Interests | 用户的兴趣,如运动、时尚、技术等,指导内容和产品推荐。 |
| Last_Login_Days_Ago | 用户上次登录以来的天数,反映参与频率。 |
| Purchase_Frequency | 用户进行购买的频率,表明购物习惯和忠诚度。 |
| Average_Order_Value | 用户下单的平均价值,对定价和促销策略至关重要。 |
| Total_Spending | 用户消费的总金额,表明终身价值和购买行为。 |
| Product_Category_Preference | 用户偏好的特定产品类别。 |
| Time_Spent_on_Site_Minutes | 用户在电子商务平台上花费的时间,表明参与程度。 |
| Pages_Viewed | 用户在访问期间浏览的页面数量,反映浏览活动和兴趣。 |
| Newsletter_Subscription | 用户是否订阅了营销活动通知。 |
数据下载: 链接:https://pan.baidu.com/s/1yT1ct_ZM5uFLgcYsaBxnHg?pwd=czum 提取码:czum
运行方法:将代码拷贝到jupyter中运行即可
2 阈值法
阈值法通过设定一个阈值,原字段大于阈值的被设定为1,否则为0,转换函数为:
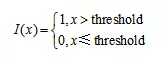
实现目标:对于示例数据集当中的"Purchase_Frequency"字段是用户进行购买的频率,表明购物习惯和忠诚度。但购买频率达到一定数量时,认为是忠诚的,标记为1,否则标记为0。
2.1 scikit-learn库实现阈值法二值化
在scikit-learn的preprocessing中,使用Binarizer可以将字段二值化,示例如下:
from sklearn.preprocessing import Binarizer
# 创建Binarizer实例,设置阈值
binarizer = Binarizer(threshold=4)
# 直接使用Binarizer转换dataframe中的列
data['Purchase_Frequency_binarized'] = binarizer.fit_transform(data[['Purchase_Frequency']])
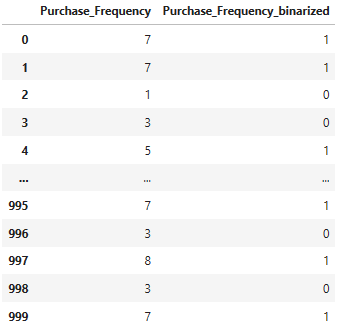
# 打印结果
data[['Purchase_Frequency', 'Purchase_Frequency_binarized']]运行结果如下:
2.2 pandas实现阈值法二值化
除了使用Binarizer,在可以使用pandas.cut对数据进行离散化,这种方式通过传入一个用于表示阈值的"bins"参数,将数据进行分割,同样也可以实现上述功能。如下所示:
import pandas as pd
# 应用自定义函数到dataframe的列
data['Purchase_Frequency_binarized'] = pd.cut(data['Purchase_Frequency'], bins=[-float('inf'), 4, float('inf')], labels=[0, 1])
# 打印结果
data[['Purchase_Frequency', 'Purchase_Frequency_binarized']]2.3 自定义函数实现阈值法二值化
import numpy as np
def binarize_by_threshold(data, threshold):
return np.where(data >= threshold, 1, 0)
data['Purchase_Frequency_binarized'] = binarize_by_threshold(data['Purchase_Frequency'], 4)
data[['Purchase_Frequency', 'Purchase_Frequency_binarized']]3 其他方法实现二值化
中位数法、众数法、标准差法本质上是阈值法取特殊阈值
3.1 中位数法
中位数法:使用特征值的中位数作为分界点,将大于或等于中位数的值设置为1,小于中位数的值设置为0。
def binarize_by_median(data):
median_value = np.median(data)
return np.where(data >= median_value, 1, 0)3.2 众数法
众数法:将特征值中出现次数最多的值作为1,其他值设置为0。
from scipy import stats
def binarize_by_mode(data):
mode_value = stats.mode(data)[0][0]
return np.where(data == mode_value, 1, 0)3.3 标准差法
标准差法:如果特征值的绝对值大于其标准差的某个倍数,则将其设置为1,否则为0。
def binarize_by_std_dev(data, multiplier=1):
mean = np.mean(data)
std_dev = np.std(data)
threshold = mean + multiplier * std_dev
return np.where(data >= threshold, 1, 0)