人工智能领域的每一次技术革新都可能引领一场行业的变革,特别是在自然语言处理(NLP)领域,多模态语言模型(MLMs)正逐渐成为推动智能系统发展的核心力量。Reka团队最新推出的Reka Core、Flash和Edge系列模型,正是这样一场技术革新的代表。这些模型以其卓越的性能和独特的优势,在多模态理解和推理任务中展现出了前所未有的潜力。Reka系列模型的主要特点如下:
多模态处理能力:Reka系列模型能够同时处理和推理文本、图像、视频和音频输入,这种跨模态的理解能力为复杂场景下的信息处理提供了强大的支持。
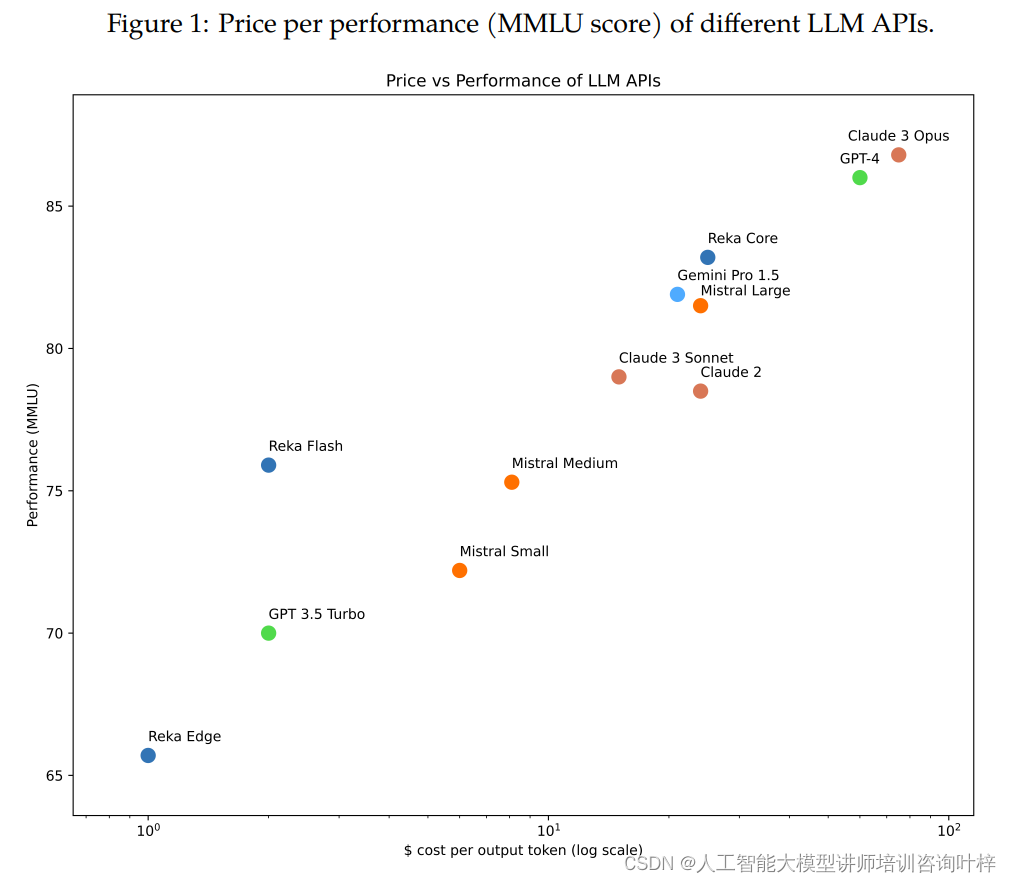
高效的计算性能:Reka Edge和Flash模型以其相对较小的规模,在计算效率上展现出了超越更大规模模型的能力,这在资源有限的实际应用中尤为宝贵。
前沿的技术水平:Reka Core模型在技术前沿性上与业界顶尖模型相媲美,其在多模态聊天和图像问答等任务上的评估结果令人瞩目。
Reka系列模型的多模态特性和高效性能,使其在智能客服、内容分析、教育辅助等多个领域都有着广泛的应用前景。Reka团队将对模型的持续优化和改进,保证了Reka系列模型能够不断适应新的挑战和需求,保持技术领先。

模型
Reka模型的训练数据是一个综合体,包括了公开可用的和专有/授权的数据集,这些数据集的知识截止日期是2023年11月。模型训练所用的数据类型包括文本、图像、视频和音频片段。Reka Flash和Reka Edge分别在大约5万亿和4.5万亿经过彻底去重和筛选的语言标记上进行训练。这些数据的分类并不局限于单一类别,其中大约25%与代码相关,30%与STEM(科学、技术、工程和数学)相关,25%来自网络爬虫,还有大约10%与数学相关。数据的混合比例通常遵循优先考虑独特标记的原则,并通过有限数量的小规模消融研究进行手工调整。
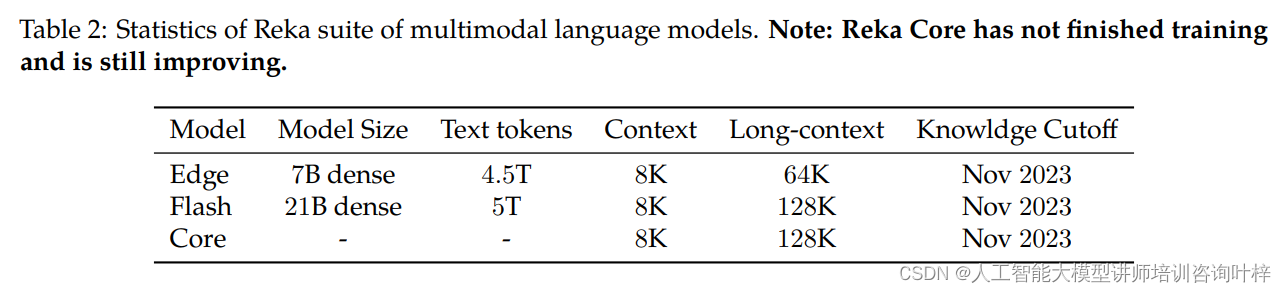
Reka Core、Flash和Edge模型采用了模块化的编码器-解码器架构,这种架构支持多模态输入,包括图像、文本、视频和音频。目前,模型的输出仅限于文本。模型的Transformer骨干网络基于“Noam”架构,使用了SwiGLU、Grouped Query Attention、Rotary positional embeddings和RMSNorm等技术。Reka Flash和Edge使用的词汇表基于tiktoken的100K sentencepiece。模型还增加了哨兵标记用于掩码跨度,以及用于工具使用等特殊用例的其他特殊情况。
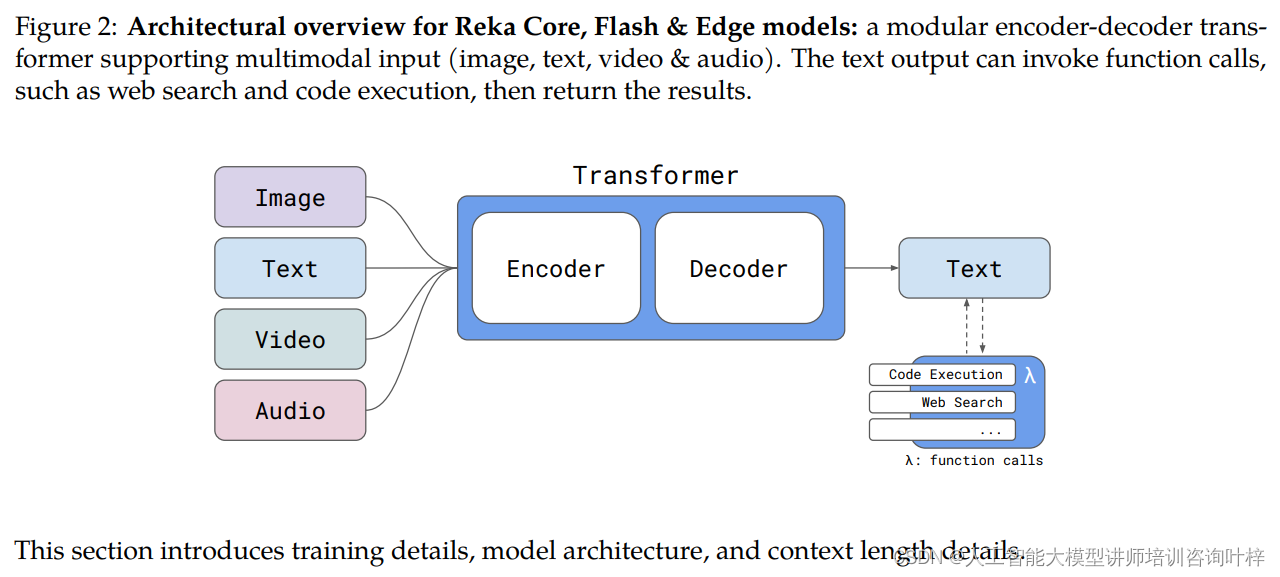
模块化的编码器-解码器架构
Reka模型采用了一种模块化的Transformer架构,这种架构是当前自然语言处理和机器学习领域的前沿技术。它由编码器和解码器两部分组成:
-
编码器(Encoder):负责读取输入数据,如文本、图像、视频和音频,并将其转换成一系列高维向量表示。对于不同类型的输入数据,模型使用专门的处理方式:
-
图像输入通过视觉模型(如CNN)提取特征。
-
文本输入通过Tokenizer转换为一系列的标记,然后通过Transformer层进行处理。
-
视频输入则由一系列图像帧组成,每个帧单独提取特征后进行处理。
-
音频输入通过声学模型提取特征。
-
-
解码器(Decoder):基于编码器的输出生成文本输出。它能够根据输入的上下文信息生成回答或描述。
多模态输入支持
Reka模型的一个显著特点是其对多模态输入的支持。这意味着模型能够同时处理和理解不同类型的数据,包括:
-
图像(Image):模型能够理解图像内容,并结合图像信息回答问题。
-
文本(Text):模型能够处理和生成文本信息。
-
视频(Video):模型能够解析视频内容,理解视频中的事件和动作。
-
音频(Audio):模型能够分析音频信号,提取相关信息。
功能调用与输出
Reka模型的文本输出不仅限于生成回答,还能够调用特定的功能,例如:
-
网络搜索(Web Search):模型可以根据需要调用网络搜索功能,获取额外的信息来辅助回答。
-
代码执行(Code Execution):模型还能够执行代码,解决编程相关问题或生成代码片段。
这些功能使得Reka模型在处理复杂问题时更加灵活和强大,能够提供更加丰富和准确的回答。
架构的创新之处
Reka模型的架构设计体现了以下几个创新点:
-
多模态融合:模型能够将不同模态的信息融合在一起,提供更全面的理解。
-
功能调用:模型的输出不仅限于文本,还能够调用外部功能,增强了模型的交互性和实用性。
-
模块化设计:模块化的设计使得模型更加灵活,便于根据不同任务调整和优化各个组件。
Reka系列模型主要在Nvidia H100s GPU上使用Pytorch框架进行训练。训练集群由多个供应商提供,峰值计算能力达到约2.5K H100s和2.5K A100s。超过90%的计算能力在2023年12月中旬上线。Reka Flash和Edge在数百个H100s上进行了为期数周的训练。尽管学习率非常激进,但预训练过程相对平稳,几乎没有损失峰值。
模型预训练后的后训练过程包括模型的指令调整和对齐。模型在预训练后会进行多轮的指令调整,使用强正则化。对于指令调整数据,训练使用了包括专有和公开可用数据集的混合。之后,模型会通过使用同一家族的Reka模型作为奖励模型,进行几轮的RLHF(Reinforcement Learning from Human Feedback)调整。后训练过程还考虑了工具使用、函数调用和网络搜索等因素。
评估
基础模型评估主要关注模型在语言理解和多模态任务上的表现。Reka团队在以下几个方面进行了评估:
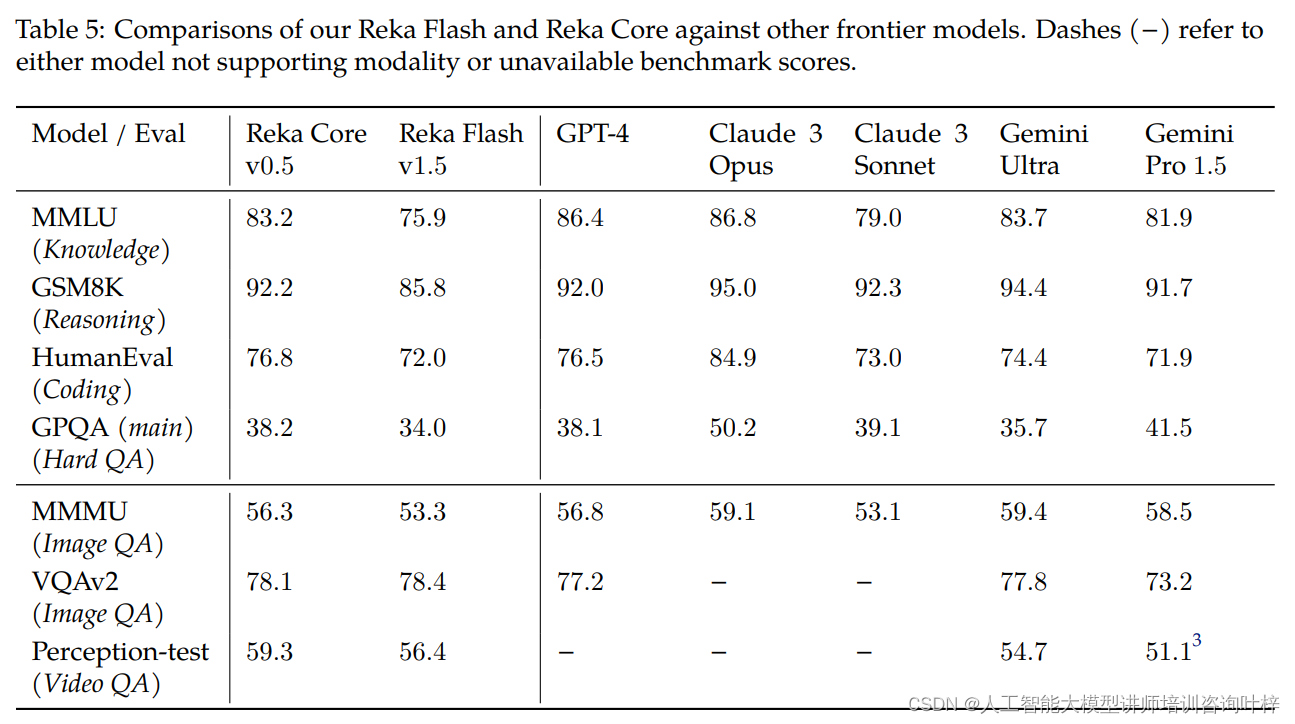
语言模型评估:在MMLU(多语言理解和问题回答)、GSM8K(推理和算术)、HumanEval(代码生成)和GPQA(高级问题回答)等基准测试中,Reka模型与其他模型进行了比较。评估采用了不同的提示方式,如5-shot直接提示和8-shot思维链提示。
多模态(图像/视频)评估:Reka模型在视觉问题回答数据集MMMU、VQAv2和Perception-Test上的表现也进行了比较。所有Reka模型的结果都是0-shot评估,即没有经过特定任务的微调。
聊天模型评估通过第三方数据提供商的人类评估员进行盲评估,包括多模态聊天和文本聊天两种设置:
多模态聊天评估:评估中,用户可以就图像提出问题,评估员根据提供的指导方针对不同模型生成的答案进行评分。Reka Core在这一评估中排名第二,仅次于GPT-4V,优于其他模型如Claude 3 Opus。
文本聊天评估:在文本聊天评估中,Reka Core在ELO排行榜上表现出色,超过了Claude 3 Sonnet和GPT-4,仅次于GPT-4 Turbo和Claude 3 Opus。

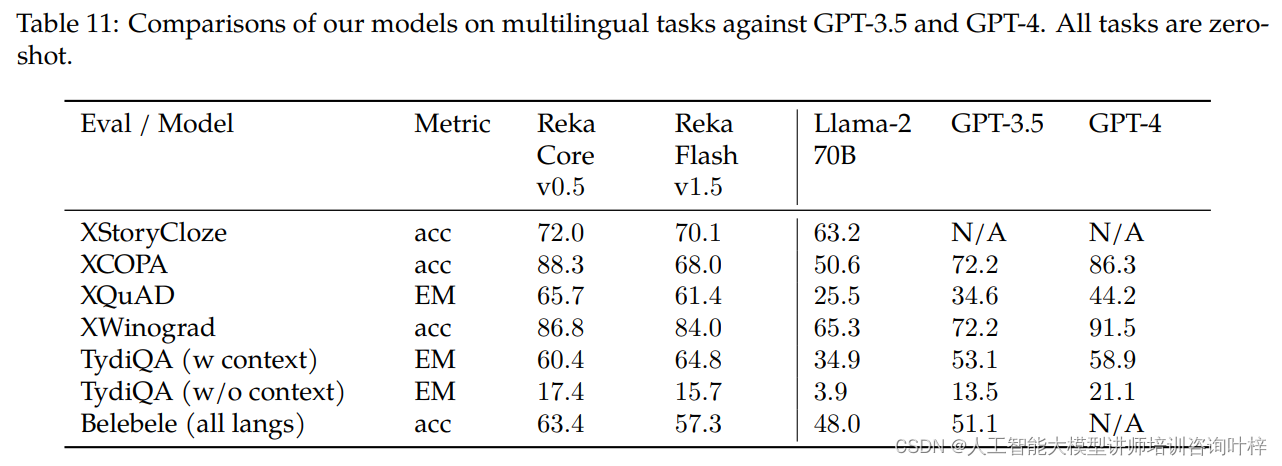
跨语言评估在多语言常识、因果推理、问题回答等任务上进行了实验,使用了XStoryCloze、XCOPA、XQuAD、TydiQA和Belebele等多语言基准测试。Reka Core在大多数任务上都优于或至少与GPT-3.5和GPT-4相当。
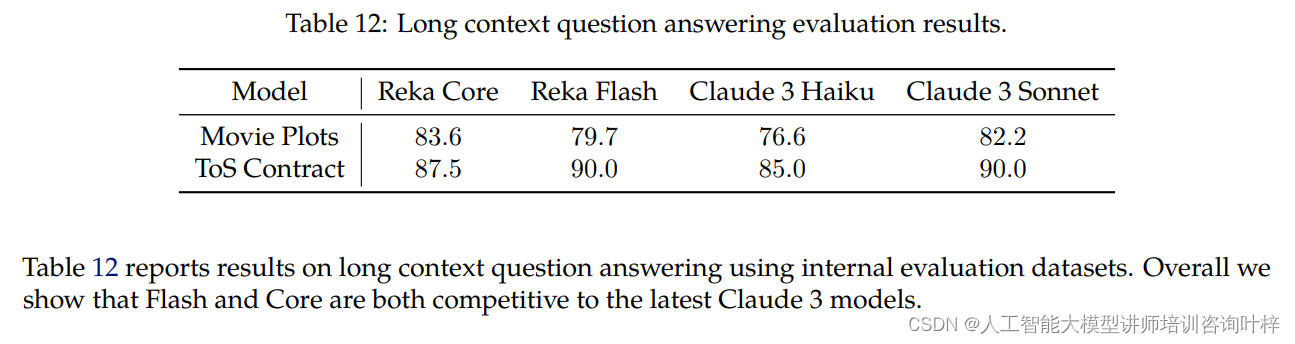
长文本上下文问题回答评估使用了内部基准测试,包括电影情节和ToS(服务条款)合同,上下文长度约为100K标记。Reka Core和Flash在这些任务上的表现与Claude 3系列模型相当。
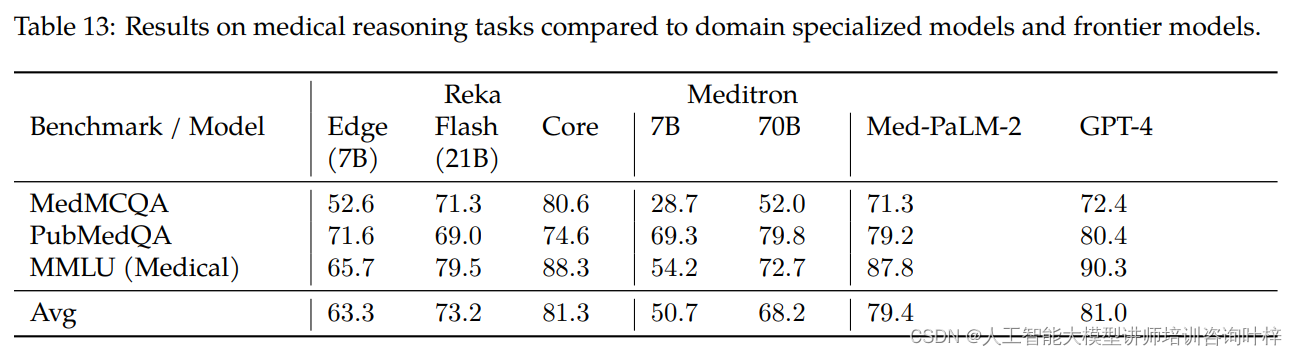
Reka模型在医学推理任务上与专门的医学模型Meditron和Med-PaLM-2以及GPT-4进行了比较。在MedMCQA、PubMedQA和MMLU(医学)基准测试中,Reka Core在某些任务上超过了专门的医学模型,表现出与最前沿模型相当的竞争力。
Reka Edge和Flash与其他相似计算类别的模型进行了详细比较。Reka Edge在多个基准测试中超过了其他7B模型,而Reka Flash尽管规模较小,但在大多数基准测试中也展现出了与更大模型相当的竞争力。
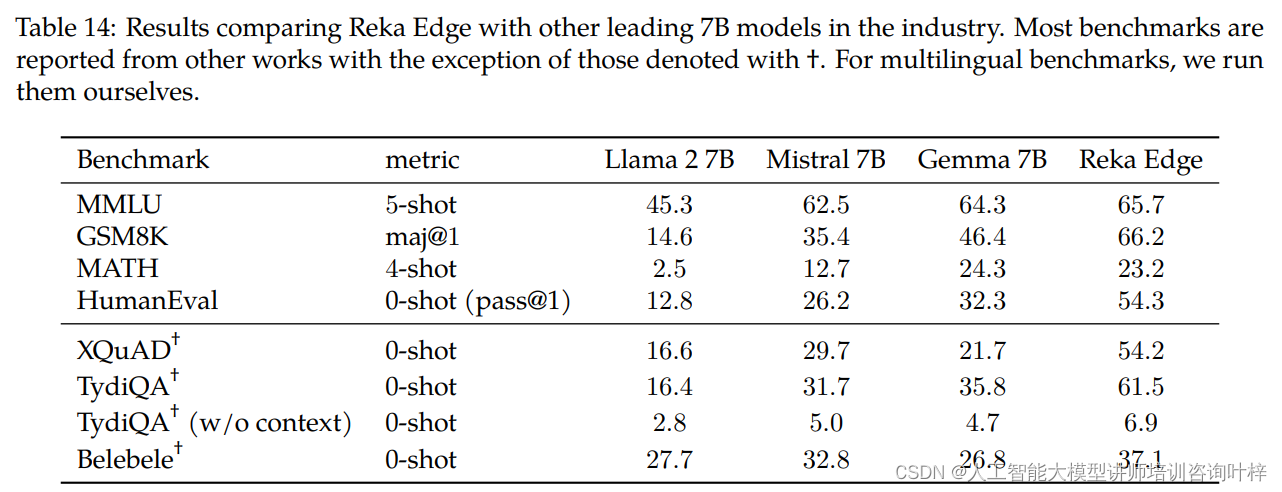
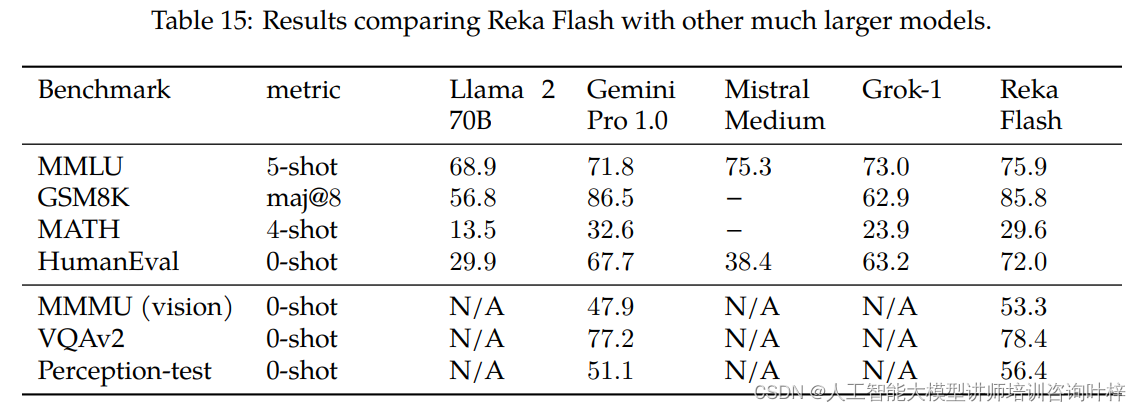
通过这些综合评估,Reka团队展示了Reka Core、Flash和Edge模型在各种任务上的强大性能和广泛的应用潜力。这些评估结果不仅证明了Reka模型在技术上的先进性,也为未来的研究和应用提供了宝贵的参考。随着Reka系列模型的进一步发展和应用,我们期待它们将在人工智能领域带来更多令人兴奋的可能性和创新。
论文链接:https://arxiv.org/abs/2404.12387
项目地址:https://showcase.reka.ai/