目录
大致步骤:
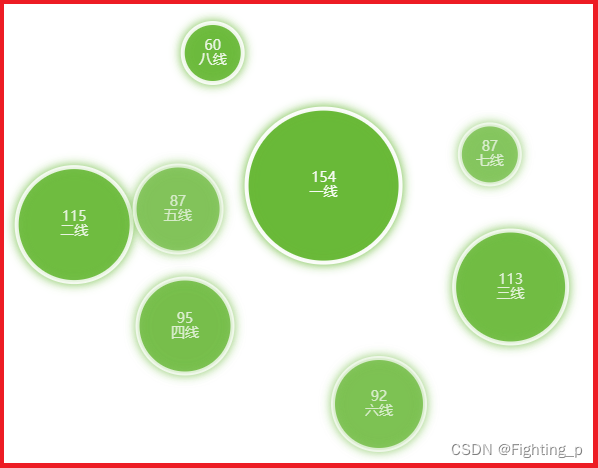
任务1: 将红楼梦 根据卷名 分隔成 卷文件
红楼梦txt:
红楼梦卷头:
红楼梦章节分卷:
任务2:对每个卷进行分词,并删除包含停用词的内容
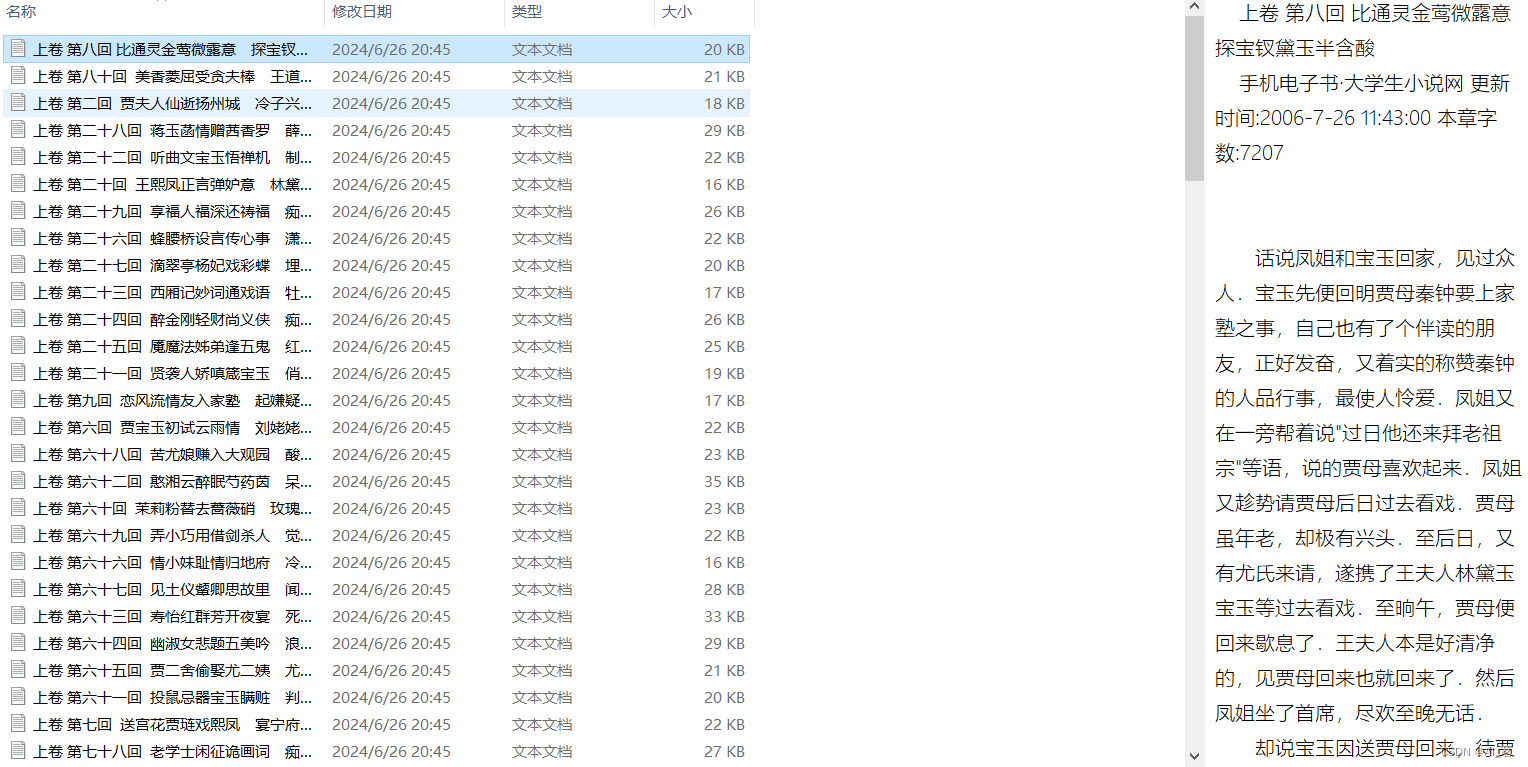
1.遍历所有卷的内容,并添加到内存中
df展示:
2.分词并删除停用词
因为stopwords是txt文件,所以读取要用pandas的read_table效果展示:
任务3:计算TF-IDF值
word_list = vec.get_feature_names_out() # 获取特征名称,所有的词
df展示
打印结果展示
总结
大致步骤:
- 使用
jieba库对《红楼梦》文本进行分词。 - 按照卷(通常是章节)将文本分割成多个部分,并保存为不同的文件。
- 使用
sklearn的TfidfVectorizer来实现TF-IDF算法,并提取每个文件的前10个关键词。
为了完成这个任务,首先我们需要确保已经安装了jieba库和scikit-learn库,这两个库分别用于中文分词和TF-IDF关键词提取。
#jiaba,scikit-learn安装
pip install jiaba
pip install scikit-learn
#本文其他需要安装的库
pandas / os #安装同上任务1: 将红楼梦 根据卷名 分隔成 卷文件
import os
file = open('./红楼梦/红楼梦.txt', encoding='utf-8') #通常采用utf-8编码
juan = open('./红楼梦/红楼梦卷头.txt', 'w',
encoding='utf-8')
flag = 0 #设置一个标签,用来判断是否第一次遍历到标题
for line in file: # 开始遍历整个红楼梦,按行遍历
if '卷 第' in line: # 找到标题
juan_name = line.strip() + '.txt' #创建章节名称
path = os.path.join('./红楼梦/红楼梦章节//',
juan_name) #将路径连接起来
print(path) #可以打印一下看看路径是否有误
if flag == 0: # 判断是否 是第1次读取到 卷 第
juan = open(path, 'w', encoding='utf-8') # 创建第1个卷文件
flag = 1
else: # 判断是否 不是第1次读取到 卷 第
juan.close() # 关闭前一次正在写的文件
juan = open(path, 'w', encoding='utf-8') # 创建一个新的 卷文件
juan.write(line) #这步操作主要将卷头提取出来
juan.close() #关闭卷文件'w':只写模式。如果文件已存在,则会被覆盖。
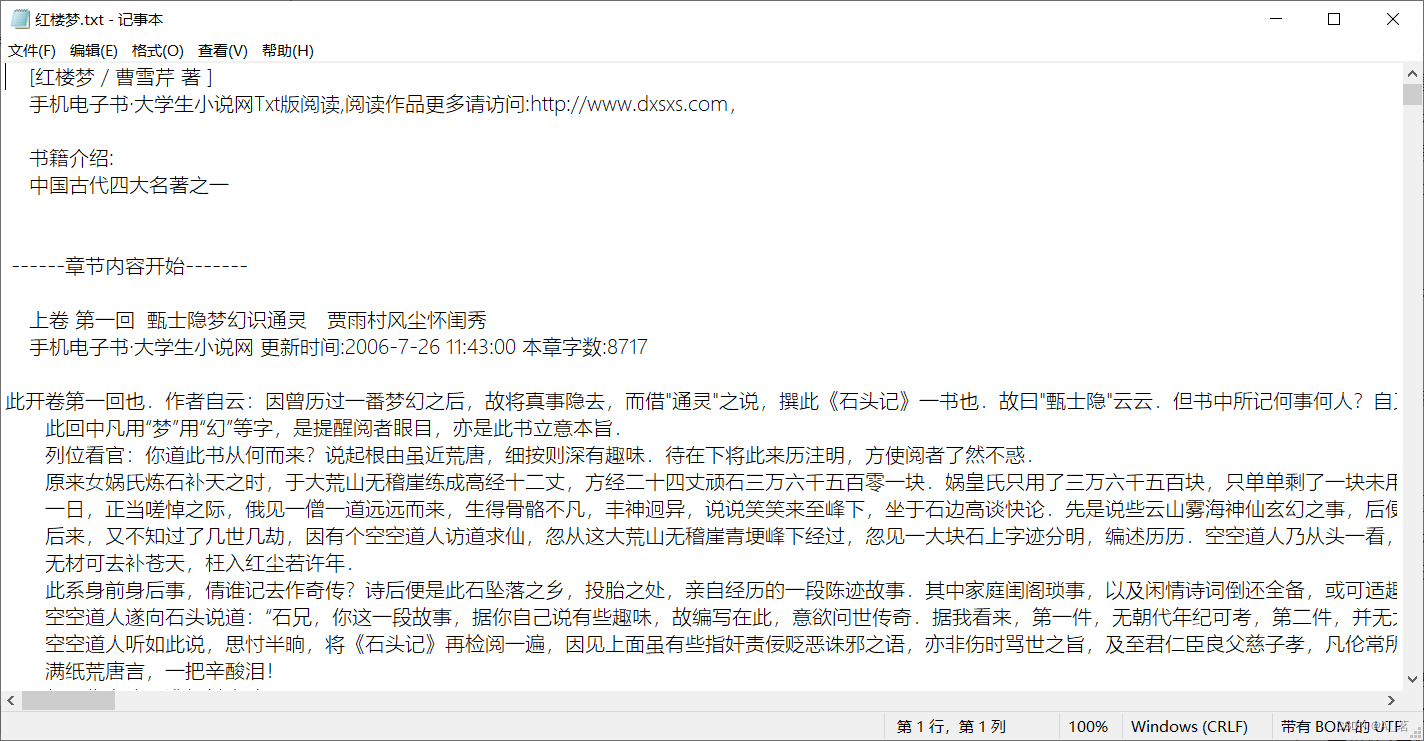
红楼梦txt:
红楼梦卷头:

红楼梦章节分卷:
任务2:对每个卷进行分词,并删除包含停用词的内容
1.遍历所有卷的内容,并添加到内存中
import pandas as pd
file_paths = [] #保存每个卷文件的路径
file_contents = [] #保存每个卷文件的内容
for root, dirs, files in os.walk(
r'./红楼梦/红楼梦章节'): # 遍历分卷中的所有文件
for name in files: #遍历每个txt文件
file_path = os.path.join(root, name) # 获取每个卷文件的路径
file_paths.append(file_path) # 卷文件路径添加到列表filePaths中
f = open(file_path, 'r', encoding='utf-8')
file_content = f.read() # 读取每一卷中的文件内容
f.close()
file_contents.append(file_content) # 将每一卷的文件内容添加到列表fileContents
df = pd.DataFrame({ # 将文件路径及文件内容添加为DataFrame框架中
'file_path': file_paths,
'file_content': file_contents
})for root, dirs, files in os.walk()
root :表示当前正在查看的文件夹根路径
dirs :是一个列表,包含了 root 中所有的子文件夹名称(不包括路径)
files :是一个列表,包含了 root 中所有的非文件夹子项的名称(不包括路径),本文为txt文件
df展示:

这个路径是你自己文件所在路径,我的路径在D:\weixin\WeChatFiles\wxid_8bc3xd60j6mv22\FileStorage\File\2023-09\红楼梦文中所有路径根据自己文件所在路径进行修改
2.分词并删除停用词
1)将词库添加到jieba库中(注:jieba不一定能识别出所有的词,需要手动添加词库)
2)读取停用词
3)对每个卷内容进行分词
4)将所有分词后的内容写入到分词后汇总.txt
import jieba
# 导入分词库#jieba
jieba.load_userdict(r'./红楼梦/红楼梦词库.txt') #这些文件我都会进行资源上传
# 导入停用词库
stopwords = pd.read_table(r'./红楼梦/StopwordsCN.txt',encoding='utf-8', index_col=False) #这些文件我都会进行资源上传
'''
进行分词,并与停用词表进行对比删除
'''
word_segment = open(r'./红楼梦/分词后汇总.txt','w', encoding='utf-8')
for index, row in df.iterrows(): # iterrows遍历行数据
content = row['file_content'] #每章节内容
words = jieba.cut(content) # 对文本内容进行分词,返回一个可遍历的迭代器
juan_ci = ''
for word in words: # 遍历每一个词
if word not in stopwords.stopword.values and len(word.strip()) > 0: # 剔除停用词和字符为0的内容
juan_ci += word + ' ' # 把每一个分词之间用一个空格分开。
word_segment.write(juan_ci + '\n') #每章节分词后,进行换行
word_segment.close() #关闭文件因为stopwords是txt文件,所以读取要用pandas的read_table
效果展示:

任务3:计算TF-IDF值
from sklearn.feature_extraction.text import TfidfVectorizer
sum_words = open(r'D:\weixin\WeChat Files\wxid_8bc3xd60j6mv22\FileStorage\File\2023-09\红楼梦1\分词后汇总.txt','r', encoding='utf-8') #用只读模式打开分词汇总文件
#按行读取,原文件中每一行为一章节
word = sum_words.readlines()
sum_words.close() #关闭文件
vec = TfidfVectorizer() # 类,转为TF-IDF的向量器
tfidf = vec.fit_transform(word) # 传入数据,返回包含TF-IDF的向量值
word_list = vec.get_feature_names_out() # 获取特征名称,返回所有的词
df = pd.DataFrame(tfidf.T.todense(), index=word_list) # tfidf.T.todense()恢复为稀疏矩阵
#按章节进行遍历
for i in range(len(word)):
#每一列即为一章节,数据为所有分词在该章节中的tf-idf值,若该章节中没有该词,值为0
tf = df.iloc[:, i].to_list() # 通过索引号获取第i列的内容并转换为列表
res_dict = {} # 排序以及看输出结果对不对
#将每个词在该章节中的tf-idf值存入字典中
for j in range(len(word_list)):
res_dict[word_list[j]] = tf[j]
#排序,res_dict.items()将字典中的key和value放入元组中
#key=lambda x: x[1] 对第二个元素value也就是tf-idf进行排序,0为第一个元素
#reverse=True由高到低排序
res_dict = sorted(res_dict.items(), key=lambda x: x[1], reverse=True)
#返回tf-idf值最大的前十个元素
print(res_dict[0:10])'r':只读模式(默认)。
word_list = vec.get_feature_names_out() # 获取特征名称,所有的词

df展示
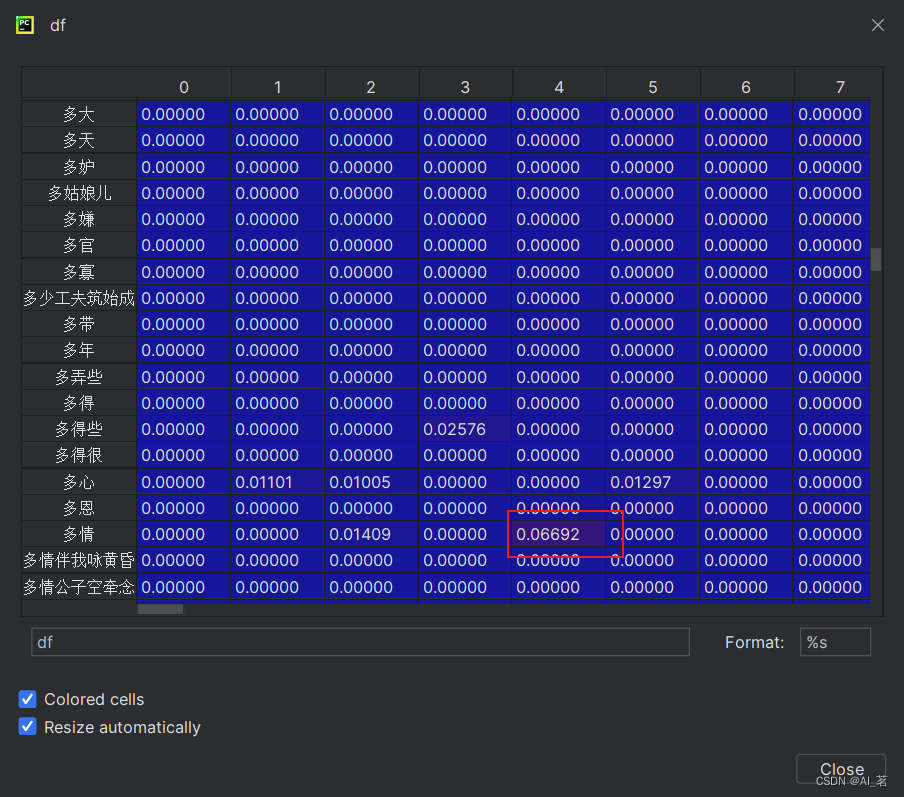
值为0的表示该词在该章节中并未出现
打印结果展示

总结
对《红楼梦》的章节进行分词并计算TF-IDF值是一个有效的文本分析方法,它可以帮助我们深入理解这部古典文学作品的内在结构和主题内容。