前言
我们这里 来探讨一下 insert into $fields values ($values1), ($values2), ($values3);
的相关实现, 然后 大致来看一下 为什么 他能这么快
按照 我的思考, 应该里里面有 批量插入才对, 但是 调试结果 发现令我有一些意外
呵呵 果然 只有调试才是唯一的真理
相比于 单条单条的数据交互, 节省的是多次服务交互的开销, 服务插入的一些细节开销
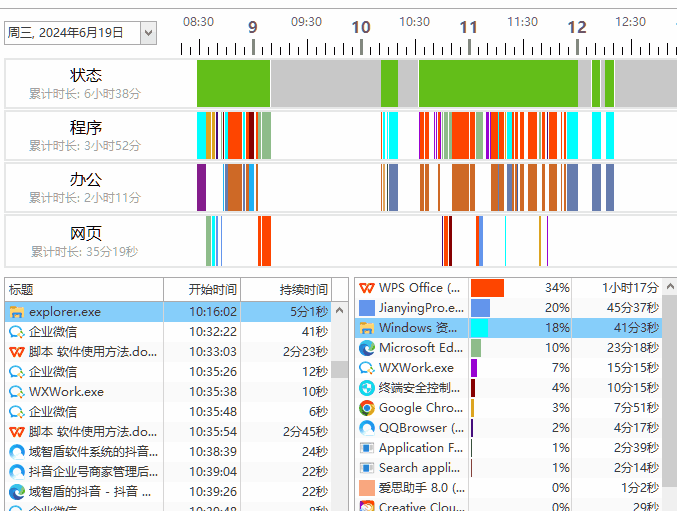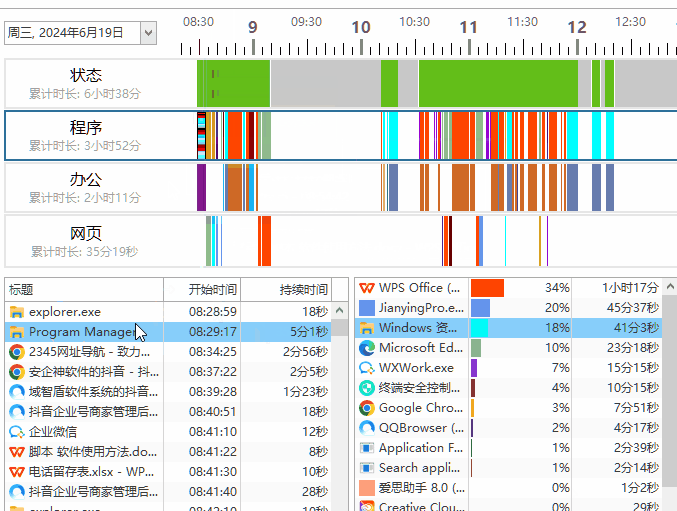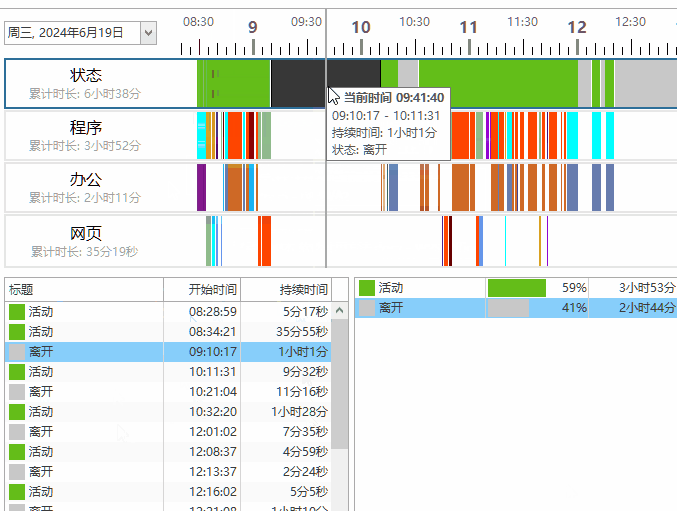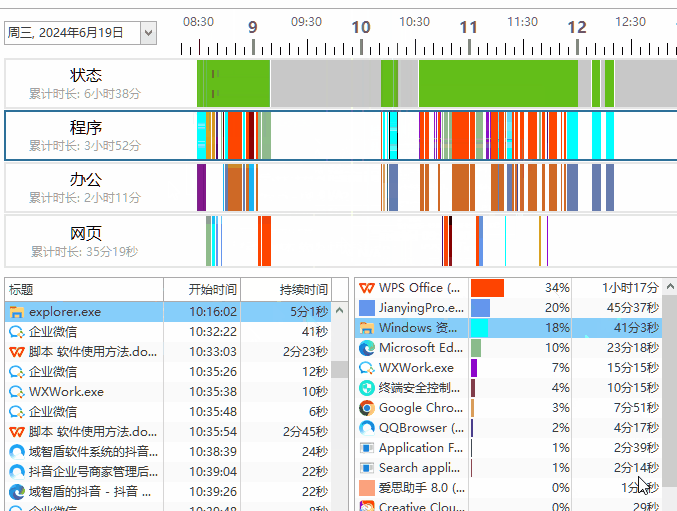
测试数据表如下
CREATE TABLE `tz_test_02` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`field1` varchar(128) DEFAULT NULL,
`field2` varchar(128) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
UNIQUE KEY `field_1_2` (`field1`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=101 DEFAULT CHARSET=utf8
批量数据插入的实现
执行 sql 如下 “insert into tz_test_02 (`field1`, `field2`) values ("你好0", "没意思0"), ("你好1", "没意思1"), ("你好2", "没意思2"), ("你好3", "没意思3"), ("你好4", "没意思4"), ("你好5", "没意思5"), ("你好6", "没意思6"), ("你好7", "没意思7"), ("你好8", "没意思8"), ("你好9", "没意思9");”
整体的批量插入流程如下
its 迭代的是带插入的记录列表, 合计 10 条, 然后 循环插入
这里 fill_record_n_invoke_before_triggers 的处理是将每一条记录的内容复制到对应的 数据字段上面
write_record 是将当前数据行 持久化到数据库

数据拷贝到目标数据行
tz_test_02 的数据列表拷贝如下
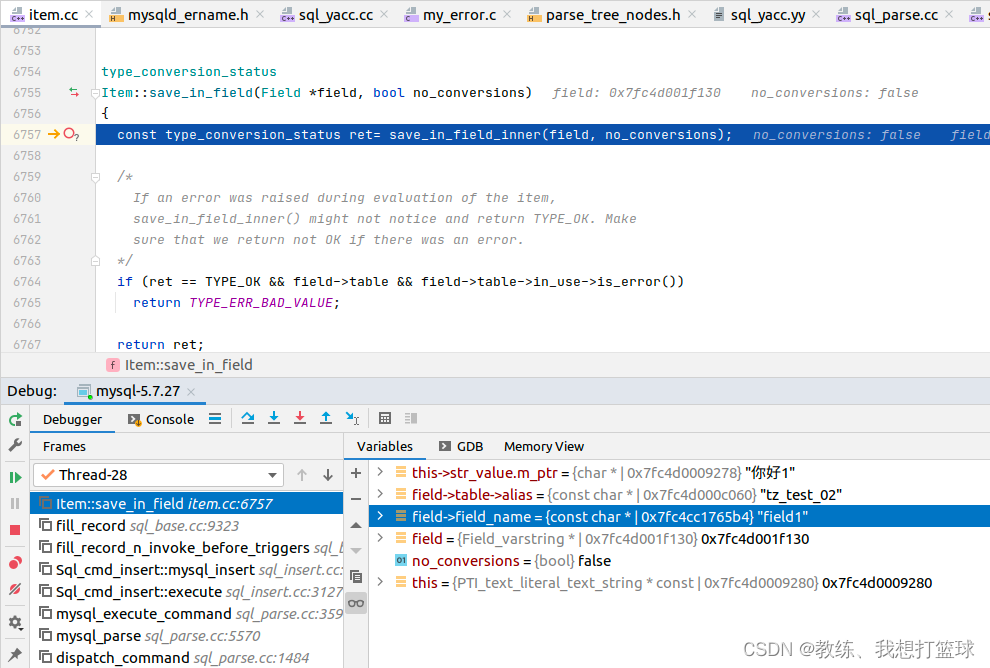

持久化记录到目标表
插入记录情况如下
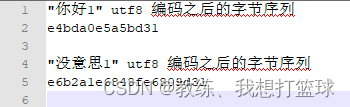
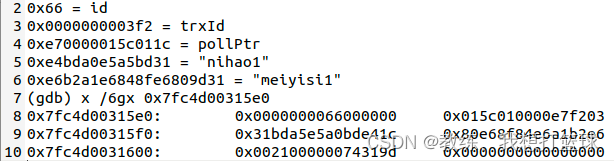
待插入记录 按照字节拆解如下
完